In mijn vorige bericht over incrementele statistieken, een nieuwe functie in SQL Server 2014, heb ik laten zien hoe ze de duur van onderhoudstaken kunnen verminderen. Dit komt omdat statistieken op partitieniveau kunnen worden bijgewerkt en de wijzigingen kunnen worden samengevoegd in het hoofdhistogram voor de tabel. Ik merkte ook op dat de Query Optimizer die statistieken op partitieniveau niet gebruikt bij het genereren van queryplannen, wat misschien iets is dat mensen verwachtten. Er bestaat geen documentatie die aangeeft dat incrementele statistieken wel of niet zullen worden gebruikt door de Query Optimizer. Dus hoe weet je dat? Je moet het testen. :-)
De installatie
De opzet voor deze test is vergelijkbaar met die in het laatste bericht, maar met minder gegevens. Houd er rekening mee dat de standaardgrootte voor de gegevensbestanden kleiner is en dat het script slechts in een paar miljoen rijen gegevens wordt geladen:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Wanneer we de geclusterde index voor dbo.Orders maken, maken we deze zonder de STATISTICS_INCREMENTAL optie ingeschakeld, dus we beginnen met een traditionele gepartitioneerde tabel zonder incrementele statistieken:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Vervolgens laden we in ongeveer 4 miljoen rijen, wat iets minder dan een minuut duurt op mijn machine:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Na het laden van de gegevens werken we de statistieken bij met een FULLSCAN (zodat we een zo consistent mogelijk histogram voor tests kunnen maken) en verifiëren we welke gegevens we in elke partitie hebben:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Gegevens in elke partitie na het laden van gegevens
Gegevens in elke partitie na het laden van gegevens
De meeste gegevens bevinden zich in de 2015-partitie, maar er zijn ook gegevens voor 2012, 2013 en 2014. En als we de uitvoer van de ongedocumenteerde DMV sys.dm_db_stats_properties_internal controleren , kunnen we zien dat er geen statistieken op partitieniveau bestaan:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal uitvoer met slechts één statistiek voor dbo.Orders
sys.dm_db_stats_properties_internal uitvoer met slechts één statistiek voor dbo.Orders
De Test
Testen vereist een eenvoudige query die we kunnen gebruiken om te verifiëren dat partitieverwijdering plaatsvindt, en ook om schattingen te controleren op basis van statistieken. De zoekopdracht levert geen gegevens op, maar dat maakt niet uit, we zijn geïnteresseerd in wat de optimizer dacht het zou terugkeren, gebaseerd op statistieken:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
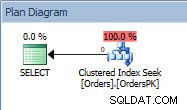 Queryplan voor de SELECT-instructie
Queryplan voor de SELECT-instructie
Het plan heeft een Clustered Index Seek en als we de eigenschappen controleren, zien we dat het 4000 rijen schat en toegang heeft tot partitie 5, die gegevens uit 2014 bevat.
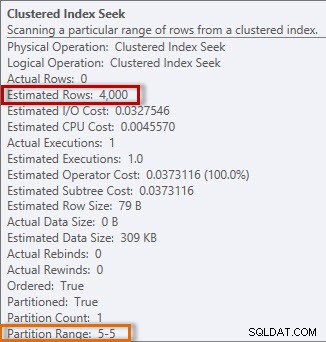 Geschatte en actuele informatie uit de Clustered Index Seek
Geschatte en actuele informatie uit de Clustered Index Seek
Als we kijken naar het histogram voor de dbo.Orders-tabel, met name in het gebied van de gegevens van april 2014, zien we dat er geen stap is voor 2014-04-01, dus de optimizer schat het aantal rijen voor die datum met behulp van de stap voor 2014-04-24, waarbij de AVG_RANGE_ROWS is 4000 (voor elke waarde tussen 2014-02-14 en 2014-04-23 inclusief, schat de optimizer dat er 4000 rijen worden geretourneerd).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
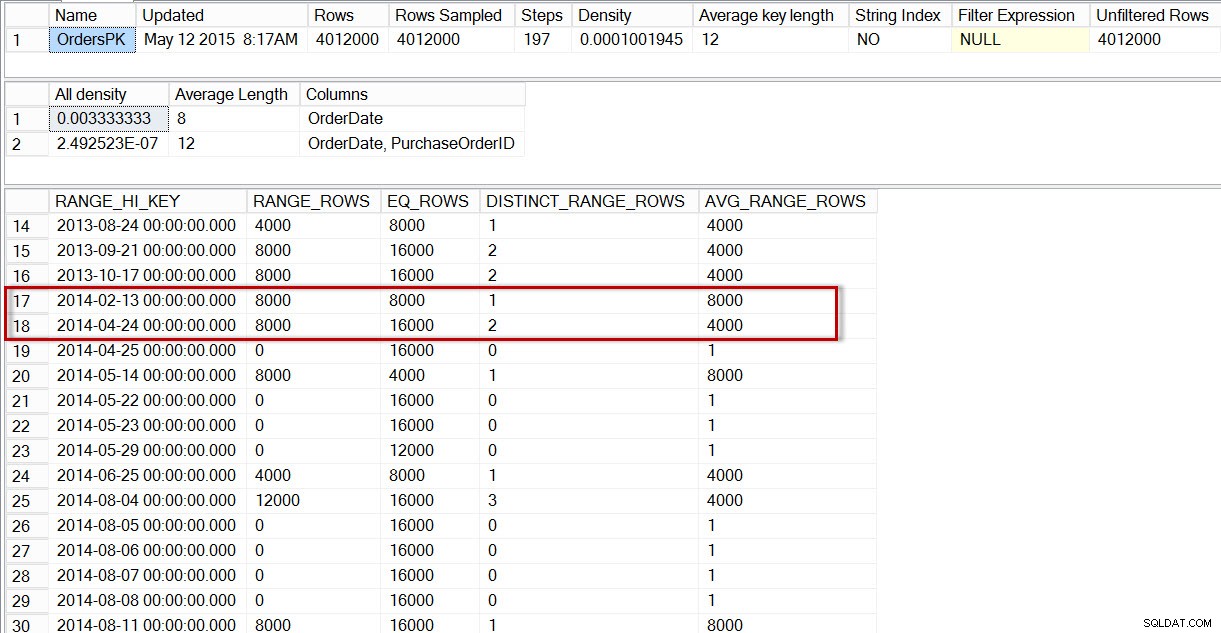 Distributie in het dbo.Orders-histogram
Distributie in het dbo.Orders-histogram
De raming en het plan zijn volledig naar verwachting. Laten we incrementele statistieken inschakelen en kijken wat we krijgen.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Als we onze query opnieuw uitvoeren op sys.dm_db_stats_properties_internal , kunnen we de incrementele statistieken zien:
 sys.dm_db_stats_properties_internal toont incrementele statistische informatie
sys.dm_db_stats_properties_internal toont incrementele statistische informatie
Laten we nu onze query opnieuw uitvoeren dbo.Orders, en we zullen DBCC FREEPROCCACHE uitvoeren eerst om ervoor te zorgen dat het plan niet opnieuw wordt gebruikt:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
We krijgen hetzelfde plan en dezelfde schatting:
Queryplan voor de SELECT-instructie
Geschatte en actuele informatie uit de Clustered Index Seek
Als we het hoofdhistogram voor dbo.Orders controleren, zien we bijna hetzelfde histogram als voorheen:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Histogram voor dbo.Orders, na inschakelen van incrementele statistieken
Histogram voor dbo.Orders, na inschakelen van incrementele statistieken
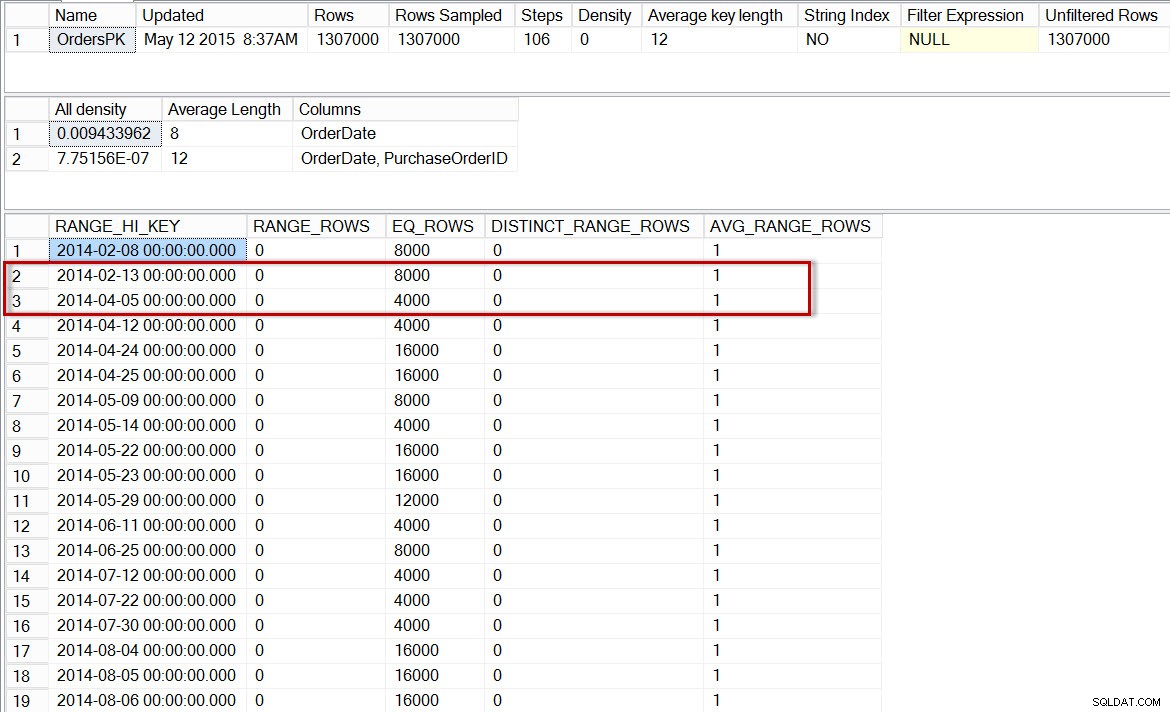
Laten we nu het histogram voor de partitie met 2014-gegevens controleren (we kunnen dit doen met behulp van ongedocumenteerde traceringsvlag 2309, waarmee een partitienummer kan worden opgegeven als een extra argument voor DBCC SHOW_STATISTICS ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histogram voor de 2014-partitie van dbo.Orders, na inschakelen van incrementele statistieken
Hier zien we dat, nogmaals, er geen stap is voor 2014-04-01, maar er zijn 0 RANGE_ROWS tussen 2014-02-13 en 2014-04-05, met een AVG_RANGE_ROWS van 1. Als de optimizer het histogram zou gebruiken voor de partitieniveaustatistieken, dan zou de schatting voor het aantal rijen voor 2014-04-01 1 zijn.
Opmerking:de partitie die is geïdentificeerd als gebruikt in het queryplan is 5, maar u zult merken dat de DBCC SHOW_STATISTICS instructieverwijzingen partitie 6. De veronderstelling is een inconsistentie in de metagegevens van statistische gegevens (een veelvoorkomende fout bij één fout, waarschijnlijk als gevolg van op 0 gebaseerde versus op 1 gebaseerde telling), die in de toekomst al dan niet kan worden verholpen. Begrijp dat de traceringsvlag op dit moment niet is gedocumenteerd en dat het niet wordt aanbevolen om deze in een productieomgeving te gebruiken.
Samenvatting
De toevoeging van incrementele statistieken in de release van SQL Server 2014 is een stap in de goede richting voor verbeterde kardinaliteitsschattingen voor gepartitioneerde tabellen. Zoals we echter hebben aangetoond, is de huidige waarde van incrementele statistieken beperkt tot kortere onderhoudsduur, aangezien deze incrementele statistieken nog niet worden gebruikt door de Query Optimizer.