SQL Server 2014 bracht veel nieuwe functies die DBA's en ontwikkelaars graag wilden testen en gebruiken in hun omgevingen, zoals de updatebare geclusterde Columnstore-index, Delayed Durability en Buffer Pool Extensions. Een functie die niet vaak wordt besproken, zijn incrementele statistieken. Tenzij u partitionering gebruikt, is dit geen functie die u kunt implementeren. Maar als je wel gepartitioneerde tabellen in je database hebt, waren incrementele statistieken misschien iets waar je reikhalzend naar uitkeek.
Opmerking:Benjamin Nevarez behandelde enkele basisprincipes met betrekking tot incrementele statistieken in zijn bericht van februari 2014, SQL Server 2014 Incremental Statistics. En hoewel er niet veel is veranderd in hoe deze functie werkt sinds zijn post en de release van april 2014, leek het een goed moment om te onderzoeken hoe het inschakelen van incrementele statistieken kan helpen bij de onderhoudsprestaties.
Incrementele statistieken worden soms statistieken op partitieniveau genoemd, en dit is omdat SQL Server voor het eerst automatisch statistieken kan maken die specifiek zijn voor een partitie. Een van de vorige uitdagingen met partitionering was dat, ook al kon je 1 tot n partities voor een tabel, was er slechts één (1) statistiek die de gegevensdistributie over al die partities vertegenwoordigde. U kunt gefilterde statistieken maken voor de gepartitioneerde tabel - één statistiek voor elke partitie - om de query-optimizer te voorzien van betere informatie over de distributie van gegevens. Maar dit was een handmatig proces en er was een script voor nodig om ze automatisch te maken voor elke nieuwe partitie.
In SQL Server 2014 gebruikt u de STATISTICS_INCREMENTAL optie om SQL Server die statistieken op partitieniveau automatisch te laten maken. Deze statistieken worden echter niet gebruikt zoals je zou denken.
Ik heb eerder vermeld dat u vóór 2014 gefilterde statistieken kon maken om de optimalisatieprogramma betere informatie over de partities te geven. Die incrementele statistieken? Ze worden momenteel niet gebruikt door de optimizer. De query-optimizer gebruikt nog steeds alleen het hoofdhistogram dat de hele tabel vertegenwoordigt. (Post volgt die dit zal demonstreren!)
Dus wat is het nut van incrementele statistieken? Als u ervan uitgaat dat alleen gegevens in de meest recente partitie veranderen, dan werkt u idealiter alleen de statistieken voor die partitie bij. U kunt dit nu doen met incrementele statistieken - en wat er gebeurt, is dat informatie vervolgens weer wordt samengevoegd in het hoofdhistogram. Het histogram voor de hele tabel wordt bijgewerkt zonder dat u de hele tabel hoeft te lezen om de statistieken bij te werken, en dit kan helpen bij het uitvoeren van uw onderhoudstaken.
Instellen
We beginnen met het maken van een partitiefunctie en -schema en vervolgens een nieuwe tabel die we zullen partitioneren. Merk op dat ik een bestandsgroep heb gemaakt voor elke partitiefunctie, zoals je zou kunnen doen in een productieomgeving. U kunt het partitieschema maken op dezelfde bestandsgroep (bijv. PRIMARY ) als u uw testdatabase niet gemakkelijk kunt laten vallen. Elke bestandsgroep is ook een paar GB groot, aangezien we bijna 400 miljoen rijen gaan toevoegen.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Voordat we de gegevens toevoegen, maken we de geclusterde index en merken we op dat de syntaxis de WITH (STATISTICS_INCREMENTAL = ON) bevat optie:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Wat hier interessant is om op te merken, is dat als je kijkt naar de ALTER TABLE invoer in MSDN, bevat deze optie niet. Je vindt het alleen in de ALTER INDEX invoer ... maar dit werkt. Als u de documentatie tot op de letter wilt volgen, voert u het volgende uit:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Zodra de geclusterde index voor het partitieschema is gemaakt, laden we onze gegevens in en controleren we hoeveel rijen er per partitie bestaan (let op:dit duurt meer dan 7 minuten op mijn laptop wil je misschien minder rijen toevoegen, afhankelijk van hoeveel opslagruimte (en tijd) je beschikbaar hebt):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
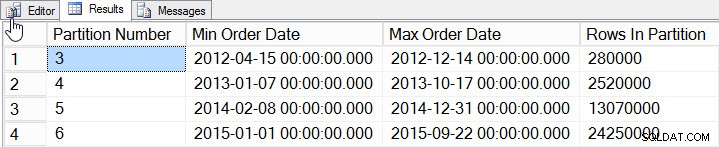 Gegevens per partitie
Gegevens per partitie
We hebben gegevens toegevoegd voor 2012 tot en met 2015, met aanzienlijk meer gegevens in 2014 en 2015. Laten we eens kijken hoe onze statistieken eruit zien:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
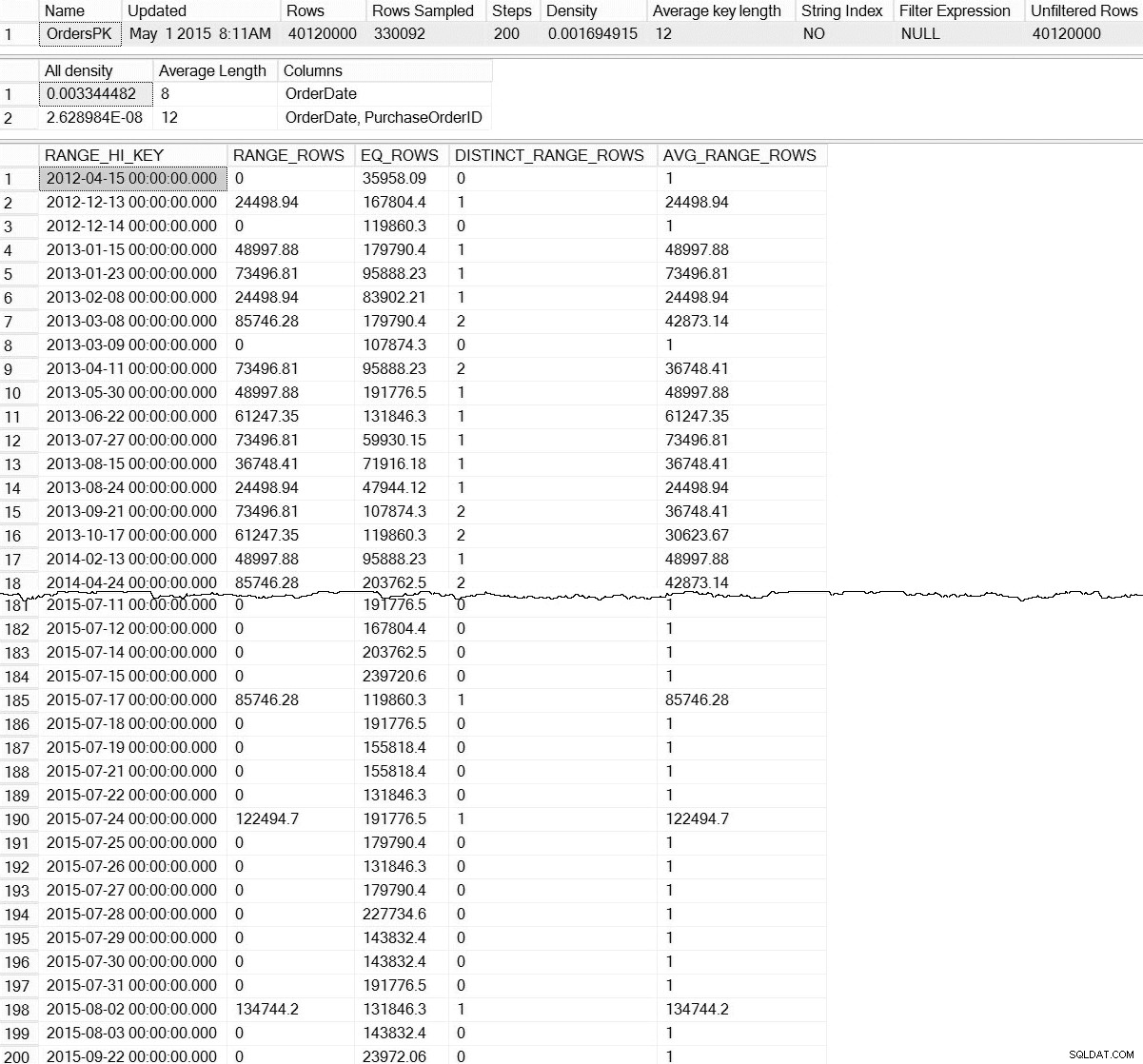 DBCC SHOW_STATISTICS-uitvoer voor dbo.Orders (klik om te vergroten)
DBCC SHOW_STATISTICS-uitvoer voor dbo.Orders (klik om te vergroten)
Met de standaard DBCC SHOW_STATISTICS commando hebben we geen informatie over statistieken op partitieniveau. Wees niet bang; we zijn niet volledig gedoemd - er is een ongedocumenteerde dynamische beheerfunctie, sys.dm_db_stats_properties_internal . Onthoud dat ongedocumenteerd betekent dat het niet wordt ondersteund (er is geen MSDN-vermelding voor de DMF) en dat het op elk moment kan worden gewijzigd zonder enige waarschuwing van Microsoft. Dat gezegd hebbende, het is een goede start om een idee te krijgen van wat er bestaat voor onze incrementele statistieken:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Histograminformatie van dm_db_stats_properties_internal (klik om te vergroten)
Histograminformatie van dm_db_stats_properties_internal (klik om te vergroten)
Dit is een stuk interessanter. Hier kunnen we het bewijs zien dat statistieken op partitieniveau (en meer) bestaan. Omdat deze DMF niet is gedocumenteerd, moeten we enige interpretatie geven. Voor vandaag concentreren we ons op de eerste zeven rijen in de uitvoer, waarbij de eerste rij het histogram voor de hele tabel vertegenwoordigt (let op de rows waarde van 40 miljoen), en de volgende rijen vertegenwoordigen de histogrammen voor elke partitie. Helaas is het partition_number waarde in dit histogram komt niet overeen met het partitienummer van sys.dm_db_index_physical_stats voor op rechts gebaseerde partitionering (het correleert correct voor op links gebaseerde partitionering). Merk ook op dat deze uitvoer ook de last_updated . bevat en modification_counter kolommen, die handig zijn bij het oplossen van problemen, en het kan worden gebruikt om onderhoudsscripts te ontwikkelen die op intelligente wijze statistieken bijwerken op basis van leeftijd of rijwijzigingen.
Benodigd onderhoud minimaliseren
De belangrijkste waarde van incrementele statistieken op dit moment is de mogelijkheid om statistieken voor een partitie bij te werken en deze te laten samenvoegen in het histogram op tabelniveau, zonder de statistiek voor de hele tabel bij te werken (en dus de hele tabel door te lezen). Laten we, om dit in actie te zien, eerst de statistieken bijwerken voor de partitie die de 2015-gegevens bevat, partitie 5, en we zullen de tijd vastleggen en een momentopname maken van de sys.dm_io_virtual_file_stats DMF voor en na om te zien hoeveel I/O optreedt:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Uitgang:
Uitvoeringstijden SQL Server:CPU-tijd =203 ms, verstreken tijd =240 ms.
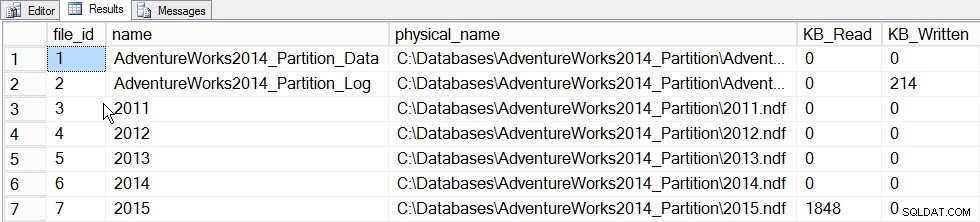 File_stats-gegevens na het bijwerken van één partitie
File_stats-gegevens na het bijwerken van één partitie
Als we kijken naar de sys.dm_db_stats_properties_internal output zien we dat last_updated gewijzigd voor zowel het histogram van 2015 als het histogram op tabelniveau (evenals een paar andere knooppunten, die voor later onderzoek zijn):
 Histogramgegevens bijgewerkt van dm_db_stats_properties_internal
Histogramgegevens bijgewerkt van dm_db_stats_properties_internal
Nu werken we de statistieken bij met een FULLSCAN voor de tabel, en we zullen voor en na opnieuw snapshots maken van file_stats:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Uitgang:
Uitvoeringstijden SQL Server:CPU-tijd =12720 ms, verstreken tijd =13646 ms
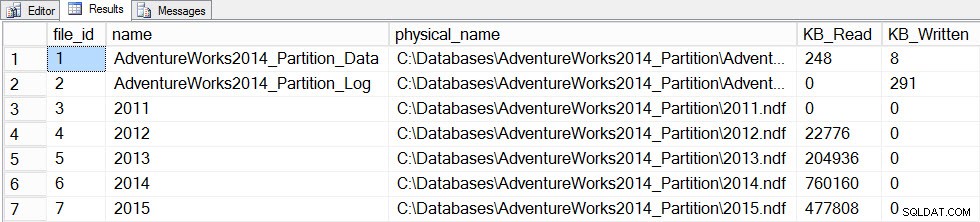 Bestandsstatistieken na updaten met een volledige scan
Bestandsstatistieken na updaten met een volledige scan
De update duurde aanzienlijk langer (13 seconden versus een paar honderd milliseconden) en genereerde veel meer I/O. Als we sys.dm_db_stats_properties_internal . controleren nogmaals, we vinden dat last_updated gewijzigd voor alle histogrammen:
 Histograminformatie van dm_db_stats_properties_internal na een volledige scan
Histograminformatie van dm_db_stats_properties_internal na een volledige scan
Samenvatting
Hoewel incrementele statistieken nog niet door de query-optimizer worden gebruikt om informatie over elke partitie te verstrekken, bieden ze wel een prestatievoordeel bij het beheren van statistieken voor gepartitioneerde tabellen. Als statistieken alleen voor bepaalde partities moeten worden bijgewerkt, kunnen alleen die worden bijgewerkt. De nieuwe informatie wordt vervolgens samengevoegd in het histogram op tabelniveau, waardoor de optimizer meer actuele informatie krijgt, zonder de kosten van het lezen van de hele tabel. In de toekomst hopen we dat die statistieken op partitieniveau zullen worden gebruikt door de optimizer. Blijf op de hoogte…