Inleiding
Prestatiespoelen zijn luie spoelen toegevoegd door de optimizer om de geschatte kosten van de binnenkant te verlagen van geneste loops joins . Ze zijn er in drie varianten:Lazy Table Spool , Luie indexspoel , en Lazy Row Count Spool . Een voorbeeld van een planvorm met een luie tafelprestatiespoel staat hieronder:
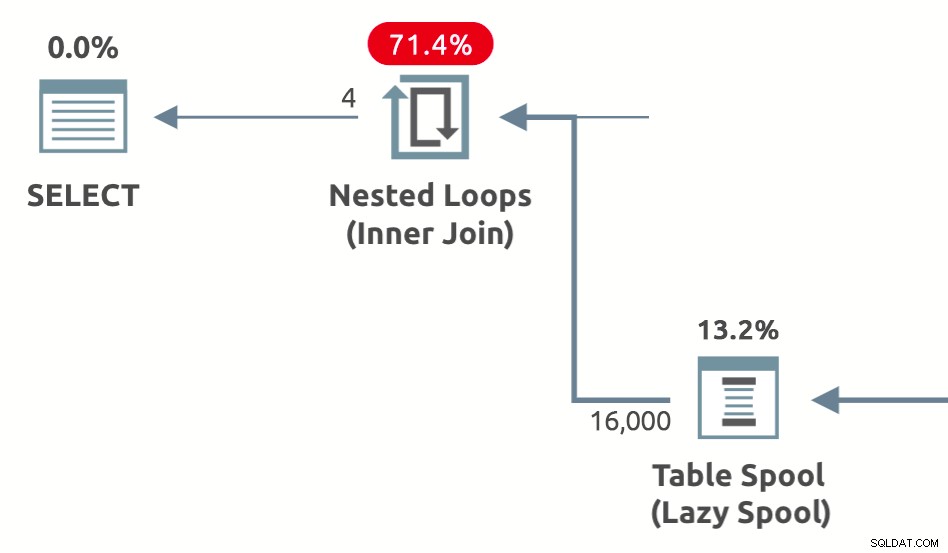
De vragen die ik in dit artikel wilde beantwoorden, zijn waarom, hoe en wanneer de query-optimizer elk type prestatie-spool introduceert.
Net voordat we beginnen, wil ik een belangrijk punt benadrukken:er zijn twee verschillende soorten geneste loop-joins in uitvoeringsplannen. Ik zal verwijzen naar de variëteit met buitenste referenties als een solliciteer , en het type met een join predikaat op de join-operator zelf als een geneste loops-join . Voor alle duidelijkheid:dit verschil gaat over operators van het uitvoeringsplan , niet T-SQL-querysyntaxis. Zie mijn gelinkte artikel voor meer details.
Prestatiespoelen
De afbeelding hieronder toont de prestatiespoel uitvoeringsplan-operators zoals weergegeven in Plan Explorer (bovenste rij) en SSMS 18.3 (onderste rij):
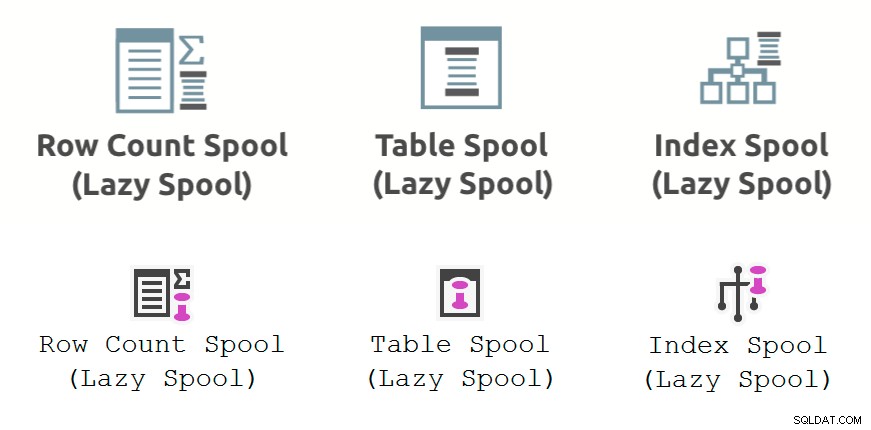
Algemene opmerkingen
Alle prestatiespoelen zijn lui . De werktafel van de spoel wordt geleidelijk gevuld, rij voor rij, terwijl rijen door de spoel stromen. (Eager spools verbruiken daarentegen alle invoer van hun onderliggende operator voordat ze rijen teruggeven aan hun ouder).
Prestatiespoelen verschijnen altijd aan de binnenkant (de onderste invoer in grafische uitvoeringsplannen) van een geneste loops join of apply-operator. Het algemene idee is om resultaten in de cache op te slaan en opnieuw af te spelen, waarbij waar mogelijk herhaalde uitvoeringen van interne operators worden opgeslagen.
Wanneer een spool in staat is om gecachte resultaten opnieuw af te spelen, staat dit bekend als een terugspoelen . Wanneer de spool zijn onderliggende operatoren moet uitvoeren om correcte gegevens te verkrijgen, wordt een rebind gebeurt.
Misschien vindt u het handig om te denken aan een spoel opnieuw binden als een cache-miss, en een terugspoelen als cache-hit.
Lazy Table Spool
Dit type prestatiespoel kan worden gebruikt met zowel apply en geneste loops komen samen .
Toepassen
Een opnieuw binden (cachemisser) treedt op wanneer een buitenste referentie waarde verandert. Een luie tafelspoel wordt opnieuw gebonden door af te kappen zijn werktabel en deze volledig herbevolken vanuit de onderliggende operatoren.
Een terugspoelen (cache hit) treedt op wanneer de binnenkant wordt uitgevoerd met de dezelfde buitenste referentiewaarden als de onmiddellijk voorafgaande lus iteratie. Door terug te spoelen worden de in de cache opgeslagen resultaten van de werktabel van de spoel opnieuw afgespeeld, waardoor de kosten voor het opnieuw uitvoeren van de planoperators onder de spoel worden bespaard.
Opmerking:een luie tabelspoel slaat alleen resultaten op voor één set apply buitenste referentie waarden tegelijk.
Nested Loops Doe mee
De luie tabelspoel wordt eenmaal gevuld tijdens de eerste lusiteratie. De spoel spoelt de inhoud terug voor elke volgende iteratie van de join. Bij geneste lussen join is de binnenkant van de join een statische reeks rijen omdat het join-predikaat zich op de join zelf bevindt. De statische rijenset aan de binnenkant kan daarom via de spoel meerdere keren in de cache worden opgeslagen en opnieuw worden gebruikt. Een geneste loops join performance spool wordt nooit opnieuw gebonden.
Lazy Row Count Spool
Een spoel voor het tellen van rijen is niet veel meer dan een tabelspoel zonder kolommen. Het slaat het bestaan van een rij op in de cache, maar projecteert geen kolomgegevens. Afgezien van het feit dat het bestaat en vermeldt dat het kan een indicatie zijn van een fout in de bronquery, zal ik niets meer te zeggen hebben over spoelen met rijtellingen.
Vanaf dit punt, wanneer u "table spool" in de tekst ziet, lees het dan alstublieft als "table (of row count) spool" omdat ze zo op elkaar lijken.
Luie indexspoel
De Lazy Index Spool operator is alleen beschikbaar met toepassen .
De indexspoel houdt een werktabel bij die niet wordt afgekapt wanneer buitenste referentie waarden veranderen. In plaats daarvan worden nieuwe gegevens toegevoegd aan de bestaande cache, geïndexeerd door de buitenste referentiewaarden. Een luie indexspoel verschilt van een luie tafelspoel doordat deze resultaten van elke opnieuw kan afspelen eerdere herhaling van de lus, niet alleen de meest recente.
De volgende stap om te begrijpen wanneer prestatie-spools verschijnen in uitvoeringsplannen, vereist een beetje begrip van hoe de optimizer werkt.
Optimizer-achtergrond
Een bronquery wordt omgezet in een logische boomweergave door ontleden, algebrisatie, vereenvoudiging en normalisatie. Wanneer de resulterende boom niet in aanmerking komt voor een triviaal plan, zoekt de op kosten gebaseerde optimizer naar logische alternatieven die gegarandeerd dezelfde resultaten opleveren, maar tegen lagere geschatte kosten.
Zodra de optimizer mogelijke alternatieven heeft gegenereerd, implementeert hij elk met behulp van geschikte fysieke operators en berekent het geschatte kosten. Het uiteindelijke uitvoeringsplan is gebaseerd op de goedkoopste optie die voor elke operatorgroep is gevonden. U kunt meer details over het proces lezen in mijn Query Optimizer Deep Dive-serie.
De algemene voorwaarden die nodig zijn om een prestatiespoel in het definitieve plan van de optimizer te laten verschijnen, zijn:
- De optimizer moet verkennen een logisch alternatief met een logische spoel in een gegenereerde vervanger. Dit is ingewikkelder dan het klinkt, dus ik zal de details uitpakken in het volgende hoofdgedeelte.
- De logische spoel moet implementeerbaar zijn als een fysieke spoel operator in de executiemotor. Voor moderne versies van SQL Server betekent dit in wezen dat alle sleutelkolommen in een index-spool van een vergelijkbare moeten zijn type, niet meer dan 900 bytes* in totaal, met 64 sleutelkolommen of minder.
- De beste volledig plan na op kosten gebaseerde optimalisatie moet een van de spoolalternatieven bevatten. Met andere woorden, alle op kosten gebaseerde keuzes die worden gemaakt tussen spoel- en niet-spoelopties moeten in het voordeel van de spoel uitkomen.
* Deze waarde is hard gecodeerd in SQL Server en is niet gewijzigd na de verhoging tot 1700 bytes voor niet-geclusterd indexsleutels vanaf SQL Server 2016. Dit komt omdat de spoolindex een geclusterd is index, geen niet-geclusterde index.
Optimizer-regels
We kunnen geen spool specificeren met behulp van T-SQL, dus als u er een in een uitvoeringsplan opneemt, moet de optimizer ervoor kiezen om deze toe te voegen. Als eerste stap betekent dit dat de optimizer een logische spoel moet opnemen in een van de alternatieven die hij verkiest te verkennen.
Het optimalisatieprogramma past niet alle logische equivalentieregels die het kent uitputtend toe op elke zoekboom. Dit zou verspilling zijn, gezien het doel van de optimizer om snel een redelijk plan te produceren. Hier zitten meerdere aspecten aan. Ten eerste gaat de optimizer in fasen te werk, waarbij eerst goedkopere en vaker toepasselijke regels worden geprobeerd. Als er in een vroeg stadium een redelijk plan wordt gevonden, of als de zoekopdracht niet in aanmerking komt voor latere stadia, kan de optimalisatie-inspanning voortijdig worden beëindigd met het goedkoopste plan dat tot nu toe is gevonden. Deze strategie helpt voorkomen dat er meer tijd wordt besteed aan optimalisatie dan wordt bespaard door stapsgewijze kostenverbeteringen.
Regelovereenkomst
Elke logische operator in de zoekstructuur wordt snel gecontroleerd op een patroonovereenkomst met de regels die beschikbaar zijn in de huidige optimalisatiefase. Elke regel komt bijvoorbeeld alleen overeen met een subset van logische operators en vereist mogelijk ook specifieke eigenschappen, zoals gegarandeerde gesorteerde invoer. Een regel kan overeenkomen met een individuele logische bewerking (een enkele groep) of meerdere aaneengesloten groepen (een subsectie van het plan).
Eenmaal gematcht, wordt een kandidaatregel gevraagd om een beloftewaarde te genereren . Dit is een getal dat aangeeft hoe waarschijnlijk het is dat de huidige regel een bruikbaar resultaat oplevert, gegeven de lokale context. Een regel kan bijvoorbeeld een hogere beloftewaarde genereren wanneer het doel veel dubbele invoer heeft, een groot geschat aantal rijen, gegarandeerd gesorteerde invoer of een andere gewenste eigenschap.
Zodra veelbelovende verkenningsregels zijn geïdentificeerd, sorteert de optimizer ze in de volgorde van de beloftewaarde en begint ze te vragen om nieuwe logische vervangingen te genereren. Elke regel kan een of meer vervangingen genereren die later zullen worden geïmplementeerd met behulp van fysieke operators. Als onderdeel van dat proces worden geschatte kosten berekend.
Het punt van dit alles, aangezien het van toepassing is op prestatiespoelen, is dat de logische vorm en eigenschappen van het plan bevorderlijk moeten zijn voor het matchen van spool-compatibele regels, en de lokale context moet een voldoende hoge beloftewaarde produceren die de optimizer ervoor kiest om substituten te genereren met behulp van de regel .
Spoolregels
Er zijn een aantal regels die logische geneste loops join onderzoeken of solliciteer alternatieven. Sommige van deze regels kunnen een of meer vervangingen produceren met een bepaald type prestatiespoel. Andere regels die overeenkomen met geneste lussen, worden samengevoegd of worden nooit een spoolalternatief gegenereerd.
Bijvoorbeeld de regel ApplyToNL implementeert een logische apply als een fysieke lus die samenkomt met externe referenties. Deze regel kan verschillende alternatieven genereren elke keer dat het draait. Naast de fysieke join-operator kan elke vervanger een luie tabelspoel, een luie indexspoel of helemaal geen spoel bevatten. De logische spoolsubstituten worden later afzonderlijk geïmplementeerd en gekost als de correct getypeerde fysieke spools, door een andere regel genaamd BuildSpool .
Als tweede voorbeeld, de regel JNtoIdxLookup implementeert een logische join als een fysieke apply , met een index zoek direct aan de binnenkant. Deze regel nooit genereert een alternatief met een spoelcomponent. JNtoIdxLookup wordt vroeg geëvalueerd en retourneert een hoge beloftewaarde wanneer deze overeenkomt, zodat eenvoudige index-lookup-plannen snel worden gevonden.
Wanneer de optimizer in een vroeg stadium een goedkoop alternatief vindt, kunnen complexere alternatieven agressief worden weggesnoeid of volledig worden overgeslagen. De redenering is dat het geen zin heeft om opties na te streven die waarschijnlijk niet zullen verbeteren ten opzichte van een al gevonden goedkoop alternatief. Evenzo is het niet de moeite waard om verder te onderzoeken als het huidige beste volledige plan de totale kosten al laag genoeg heeft.
Een derde regelvoorbeeld:De regel JNtoNL lijkt op ApplyToNL , maar het implementeert alleen fysieke geneste loop join , met een luie tafelspoel of helemaal geen spoel. Deze regel nooit genereert een indexspoel omdat voor dat type spoel een toepassing vereist is.
Spoolgeneratie en kostprijsberekening
Een regel die in staat is van het genereren van een logische spoel zal dit niet noodzakelijk elke keer doen wanneer deze wordt aangeroepen. Het zou zonde zijn om logische alternatieven te bedenken die zo goed als geen kans maken om als goedkoopste te worden gekozen. Er zijn ook kosten verbonden aan het genereren van nieuwe alternatieven, die op hun beurt nog meer alternatieven kunnen opleveren - die allemaal mogelijk moeten worden geïmplementeerd en gekost.
Om dit te beheren, implementeert de optimizer gemeenschappelijke logica voor alle spool-compatibele regels om te bepalen welk(e) type(s) spoolalternatieven moeten worden gegenereerd op basis van lokale planvoorwaarden.
Nested Loops Doe mee
Voor een geneste loops join , de kans op een luie tafelspoel neemt toe in lijn met:
- Het geschatte aantal rijen op de buitenste invoer van de join.
- De geschatte kosten van binnenzijde plan operators.
De kosten van de spoel worden terugbetaald door besparingen die zijn gemaakt door het vermijden van uitvoeringen aan de binnenkant van de operator. De besparingen nemen toe met meer interne iteraties en hogere interne kosten. Dit is met name het geval omdat het kostenmodel relatief lage I/O- en CPU-kosten toekent aan het terugspoelen van de table spool (cachehits). Onthoud dat een table spool op een geneste loops join alleen terugspoelen ervaart, omdat het ontbreken van parameters betekent dat de binnenste dataset statisch is.
Een spoel kan gegevens dichter opslaan dan de operators die het voeden. Een geclusterde index van een basistabel kan bijvoorbeeld gemiddeld 100 rijen per pagina bevatten. Stel dat een query slechts één geheeltallige kolomwaarde nodig heeft van elke brede geclusterde indexrij. Door alleen de integerwaarde in de spoelwerktabel op te slaan, kunnen ruim 800 van dergelijke rijen per pagina worden opgeslagen. Dit is belangrijk omdat de optimizer de kosten van de tabelspoel gedeeltelijk beoordeelt op basis van een schatting van het aantal werktafelpagina's nodig zijn. Andere kostenfactoren zijn de CPU-kosten per rij die gemoeid zijn met het schrijven en lezen van de spool, over het geschatte aantal lusiteraties.
De optimizer is misschien een beetje te enthousiast om luie tafelspoelen toe te voegen aan de binnenkant van een geneste lusverbinding. Desalniettemin is de beslissing van de optimizer altijd logisch in termen van geschatte kosten. Persoonlijk beschouw ik geneste loops join als hoog risico , omdat ze snel traag kunnen worden als de schatting van de invoerkardinaliteit van een van beide te laag is.
Een tafelspoel mag helpen de kosten te verlagen, maar het kan de slechtste prestatie van een naïeve geneste lus-join niet volledig verbergen. Een geïndexeerde toepassingsjoin heeft normaal gesproken de voorkeur en is beter bestand tegen schattingsfouten. Het is ook een goed idee om queries te schrijven die de optimizer kan implementeren met hash of merge join, indien van toepassing.
Lazy Table Spool toepassen
Voor een solliciteer , de kans op een luie tafelspoel toenemen met het geschatte aantal duplicaat voeg sleutelwaarden toe aan de buitenste invoer van de toepassing. Met meer duplicaten is er een statistisch grotere kans dat de spoel de momenteel opgeslagen resultaten bij elke iteratie terugspoelt. Een luie tafelspoel met lagere geschatte kosten maakt een grotere kans om in het uiteindelijke uitvoeringsplan te worden opgenomen.
Wanneer de rijen die binnenkomen op de buitenste invoer toepassen geen specifieke volgorde hebben, maakt de optimizer een statistische beoordeling hoe waarschijnlijk het is dat elke iteratie resulteert in een goedkope rewind of een dure rebind. Deze beoordeling maakt gebruik van gegevens uit histogramstappen, indien beschikbaar, maar zelfs dit beste scenario is meer een gefundeerde gok. Zonder garantie is de volgorde van de rijen die binnenkomen op de buitenste invoerinvoer onvoorspelbaar.
Dezelfde optimalisatieregels die logische spoolalternatieven genereren, kunnen ook specificeer dat de operator Apply vereist gesorteerde rijen op zijn buitenste ingang. Dit maximaliseert luie spoel terugspoelen omdat alle duplicaten gegarandeerd in een blok worden aangetroffen. Wanneer de sorteervolgorde van de buitenste invoer is gegarandeerd, hetzij door een bewaarde volgorde of een expliciete Sorteren , zijn de kosten van de spoel veel lager. De optimalisatiefactor is van invloed op de impact van de sorteervolgorde op het aantal terugspoelen en opnieuw binden van de spool.
Plannen met een Sorteer op de buitenste invoer toepassen, en een Lazy Table Spool op de innerlijke ingang zijn heel gewoon. De optimalisatie van de sortering aan de buitenkant kan nog steeds contraproductief zijn. Dit kan bijvoorbeeld gebeuren wanneer de schatting van de kardinaliteit aan de buitenkant zo laag is dat de sortering naar tempdb gaat. .
Lazy Index Spool toepassen
Voor een solliciteer , krijg een luie indexspoel alternatief hangt af van de vorm van het plan en van de kosten.
De optimizer vereist:
- Sommige duplicaat voeg waarden toe aan de buitenste invoer.
- Een gelijkheid join predikaat (of een logisch equivalent dat de optimizer begrijpt, zoals
x <= y AND x >= y). - Een garantie dat de buitenste referenties uniek zijn onder de voorgestelde luie indexspoel.
In uitvoeringsplannen wordt de vereiste uniciteit vaak geleverd door een geaggregeerde groepering door de buitenste referenties, of een scalaire aggregaat (een zonder group by). Uniciteit kan ook op andere manieren worden geboden, bijvoorbeeld door het bestaan van een unieke index of beperking.
Een speelgoedvoorbeeld dat de vorm van het plan laat zien, staat hieronder:
CREATE TABLE #T1
(
c1 integer NOT NULL
);
GO
INSERT #T1 (c1)
VALUES
-- Duplicate outer rows
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6),
(1), (2), (3), (4), (5), (6);
GO
SELECT *
FROM #T1 AS T1
CROSS APPLY
(
SELECT COUNT_BIG(*)
FROM (SELECT T1.c1 UNION SELECT NULL) AS U
) AS CA (c);
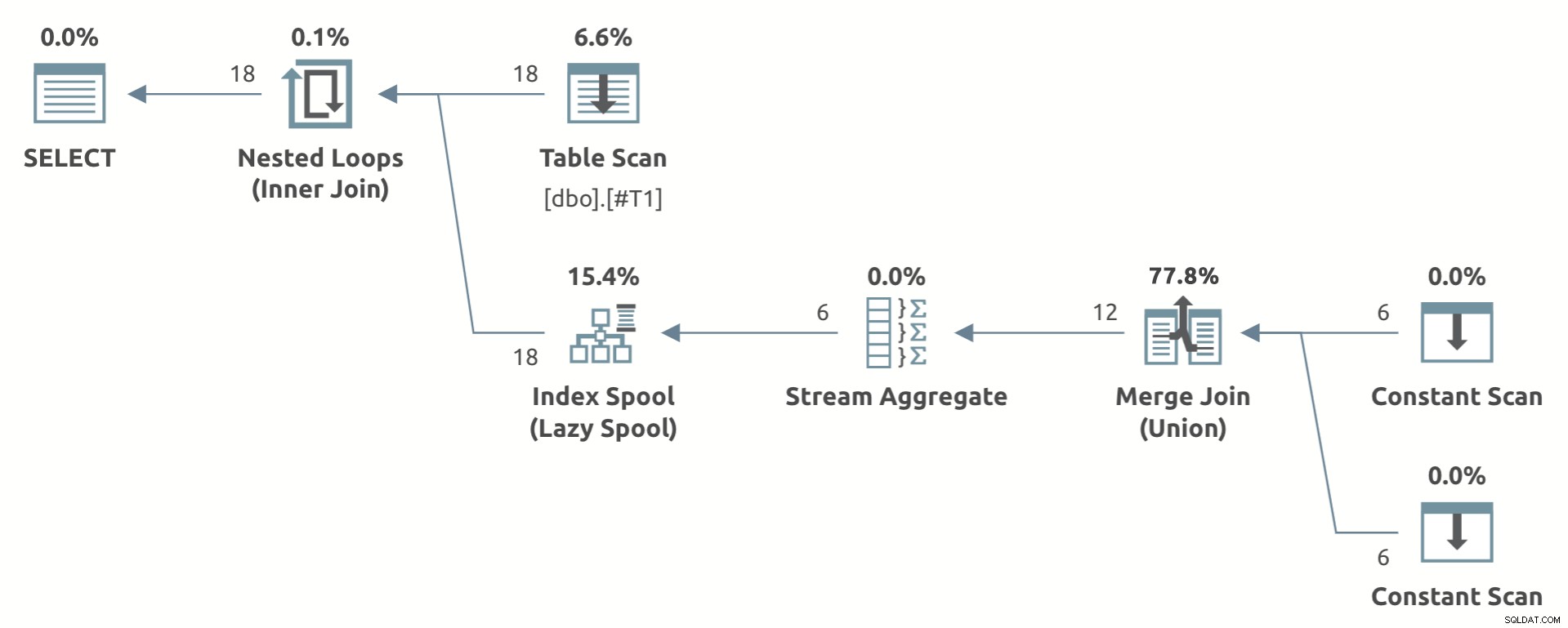
Let op de Stream Aggregate onder de Lazy Index Spool .
Als aan de vormvereisten van het plan wordt voldaan, genereert de optimizer vaak een luie indexalternatief (onder voorbehoud van de eerder genoemde kanttekeningen). Of het uiteindelijke plan een luie indexspoel bevat of niet, hangt af van de kosten.
Index Spool versus Table Spool
Het aantal geschatte terugspoelen en herbindt voor een luie indexspoel is hetzelfde wat betreft een luie tafelspoel zonder gesorteerd externe invoer toepassen.
Dit lijkt misschien een nogal ongelukkige gang van zaken. Het belangrijkste voordeel van een index-spool is dat deze alle eerder geziene resultaten in de cache opslaat. Dit zou de index spool terugspoelen moeten maken waarschijnlijker dan voor een table spool (zonder sorteren op de buitenste invoer) in dezelfde omstandigheden. Ik heb begrepen dat deze eigenaardigheid bestaat, want zonder deze zou de optimizer veel te vaak een indexspoel kiezen.
Hoe dan ook, het kostenmodel past het bovenstaande tot op zekere hoogte aan door verschillende I/O- en CPU-kostennummers voor de eerste en volgende rij te gebruiken voor index- en tabelspoelen. Het netto-effect is dat een indexspoel gewoonlijk lager kost dan een tafelspoel zonder gesorteerde externe invoer, maar onthoud de beperkende vereisten voor de planvorm, die luie indexspoelen relatief maken zeldzaam.
Toch is de belangrijkste kostenconcurrent van een luie spoolindex een tafelspoel met gesorteerde buitenste invoer. De intuïtie hiervoor is vrij eenvoudig:Gesorteerde buitenste invoer betekent dat de tabelspoel gegarandeerd alle dubbele buitenste referenties opeenvolgend ziet. Dit betekent dat het opnieuw bindt slechts één keer per afzonderlijke waarde, en terugspoelen voor alle duplicaten. Dit is hetzelfde als het verwachte gedrag van een indexspoel (logisch gezien tenminste).
In de praktijk is de kans groter dat een indexspoel de voorkeur heeft boven een voor sorteren geoptimaliseerde tabelspoel voor minder dubbele toepassingssleutelwaarden. Het hebben van minder dubbele sleutels vermindert het terugspoelen voordeel van de voor sorteren geoptimaliseerde tabelspoel, vergeleken met de eerder genoemde "ongelukkige" schattingen van de indexspoel.
De indexspoeloptie profiteert ook van de geschatte kosten van een buitenzijde van een tafelspoel Sorteren neemt toe. Dit wordt meestal geassocieerd met meer (of bredere) rijen op dat punt in het plan.
Vlaggen en hints traceren
-
Prestatiespoelen kunnen worden uitgeschakeld met licht gedocumenteerde traceringsvlag 8690 , of de gedocumenteerde vraaghint
NO_PERFORMANCE_SPOOLop SQL Server 2016 of later. -
Ongedocumenteerde traceervlag 8691 kan worden gebruikt (op een testsysteem) om altijd een prestatiespoel toe te voegen wanneer mogelijk. Het type van luie spool die je krijgt (rijtelling, tabel of index) kan niet worden geforceerd; het hangt nog steeds af van de kostenraming.
-
Ongedocumenteerde traceervlag 2363 kan worden gebruikt met het nieuwe kardinaliteitsschattingsmodel om de afleiding van de verschillende schatting te zien op de buitenste invoer voor een toepassing en kardinaliteitsschatting in het algemeen.
-
Ongedocumenteerde traceervlag 9198 kan worden gebruikt om luie indexprestatiespoelen uit te schakelen specifiek. Mogelijk krijgt u in plaats daarvan nog steeds een luie tabel of rij-telspoel (met of zonder sorteeroptimalisatie), afhankelijk van de kosten.
-
Ongedocumenteerde traceervlag 2387 kan worden gebruikt om de CPU-kosten te verlagen van het lezen van rijen van een luie indexspoel . Deze vlag is van invloed op algemene schattingen van de CPU-kosten voor het lezen van een reeks rijen uit een b-tree. Deze vlag heeft de neiging om de selectie van de indexspoel waarschijnlijker te maken, om kostenredenen.
Andere traceringsvlaggen en -methoden om te bepalen welke optimalisatieregels zijn geactiveerd tijdens het compileren van query's, vindt u in mijn Query Optimizer Deep Dive-serie.
Laatste gedachten
Er zijn een groot aantal interne details die van invloed zijn op het al dan niet gebruiken van een prestatiespoel in het uiteindelijke uitvoeringsplan. Ik heb geprobeerd de belangrijkste overwegingen in dit artikel te behandelen, zonder te ver in te gaan op de uiterst ingewikkelde details van formules voor de kosten van spooloperatoren. Hopelijk vindt u hier voldoende algemeen advies om u te helpen bij het bepalen van mogelijke redenen voor een bepaald type prestatiespoel in een uitvoeringsplan (of het ontbreken daarvan).
Performance spools krijgen vaak een slechte rap, ik denk dat het eerlijk is om te zeggen. Een deel hiervan is ongetwijfeld verdiend. Velen van jullie zullen een demo hebben gezien waarbij een plan sneller wordt uitgevoerd zonder een "prestatiespoel" dan met. Tot op zekere hoogte is dat niet onverwacht. Er zijn randgevallen, het kostenmodel is niet perfect en demo's bevatten ongetwijfeld vaak plannen met slechte kardinaliteitsschattingen of andere optimalisatiebeperkende problemen.
Dat gezegd hebbende, zou ik soms willen dat SQL Server een soort waarschuwing of andere feedback zou geven wanneer het zijn toevlucht neemt tot het toevoegen van een luie tabelspoel aan een geneste loops-join (of een toepassing zonder een gebruikte ondersteunende index aan de binnenkant). Zoals vermeld in het hoofdgedeelte, zijn dit de situaties die volgens mij het vaakst verkeerd gaan, wanneer de kardinaliteitsschattingen verschrikkelijk laag blijken te zijn.
Misschien zal de query-optimizer op een dag rekening houden met een of ander risicoconcept om keuzes te plannen, of meer "adaptieve" mogelijkheden bieden. In de tussentijd loont het de moeite om uw geneste loops-joins te ondersteunen met nuttige indexen en om te voorkomen dat u query's schrijft die waar mogelijk alleen kunnen worden geïmplementeerd met behulp van geneste loops. Ik generaliseer natuurlijk, maar de optimizer heeft de neiging om het beter te doen als hij meer keuzes, een redelijk schema, goede metadata en beheersbare T-SQL-statements heeft om mee te werken. Ik ook, nu ik erover nadenk.
Andere spoelartikelen
Non-performance spools worden voor veel doeleinden gebruikt binnen SQL Server, waaronder:
- Halloween-bescherming
- Sommige vensterfuncties in rijmodus
- Meerdere aggregaten berekenen
- Optimaliseren van uitspraken die gegevens wijzigen