Inleiding
Ongeacht de databasetechnologie is het noodzakelijk om een bewakingsinstallatie te hebben, zowel om problemen op te sporen en actie te ondernemen, als om gewoon de huidige status van onze systemen te kennen.
Hiervoor zijn er verschillende tools, betaald en gratis. In deze blog richten we ons op één in het bijzonder:Nagios Core.
Wat is Nagios Core?
Nagios Core is een Open Source systeem voor het monitoren van hosts, netwerken en diensten. Het maakt het mogelijk om waarschuwingen te configureren en heeft verschillende statussen voor hen. Het maakt de implementatie van plug-ins mogelijk, ontwikkeld door de gemeenschap, of stelt ons zelfs in staat om onze eigen monitoringscripts te configureren.
Hoe installeer ik Nagios?
De officiële documentatie laat ons zien hoe u Nagios Core op CentOS- of Ubuntu-systemen kunt installeren.
Laten we een voorbeeld bekijken van de noodzakelijke stappen voor de installatie op CentOS 7.
Pakketten vereist
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipDownload Nagios Core, Nagios Plugins en NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzNagios-gebruiker en groep toevoegen
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheNagios-installatie
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgNagios-plug-in en NRPE-installatie
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginWe voegen de volgende regel toe aan het einde van ons bestand /usr/local/nagios/etc/objects/command.cfg om NRPE te gebruiken bij het controleren van onze servers:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios begint
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdWebtoegang
We maken de gebruiker aan om toegang te krijgen tot de webinterface en we kunnen de site betreden.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://IP_Address/nagios/
 Nagios-webtoegang
Nagios-webtoegang Hoe Nagios configureren?
Nu we onze Nagios hebben geïnstalleerd, kunnen we doorgaan met de configuratie. Hiervoor moeten we naar de locatie gaan die overeenkomt met onze installatie, in ons voorbeeld /usr/local/nagios/etc.
Er zijn verschillende configuratiebestanden die u moet maken of bewerken voordat u iets gaat controleren.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: Het CGI-configuratiebestand bevat een aantal richtlijnen die van invloed zijn op de werking van de CGI's. Het bevat ook een verwijzing naar het hoofdconfiguratiebestand, zodat de CGI's weten hoe u Nagios hebt geconfigureerd en waar uw objectdefinities zijn opgeslagen.
- htpasswd.users: Dit bestand bevat de gebruikers die zijn gemaakt voor toegang tot de Nagios-webinterface.
- nagios.cfg: Het hoofdconfiguratiebestand bevat een aantal richtlijnen die van invloed zijn op hoe de Nagios Core-daemon werkt.
- objecten: Wanneer u Nagios installeert, worden hier verschillende voorbeeldobjectconfiguratiebestanden geplaatst. U kunt deze voorbeeldbestanden gebruiken om te zien hoe objectovererving werkt en om te leren hoe u uw eigen objectdefinities definieert. Objecten zijn alle elementen die betrokken zijn bij de monitoring- en meldingslogica.
- resource.cfg: Dit wordt gebruikt om een optioneel bronbestand op te geven dat macrodefinities kan bevatten. Met macro's kunt u in uw opdrachten verwijzen naar de informatie van hosts, services en andere bronnen.
Binnen objecten kunnen we sjablonen vinden die kunnen worden gebruikt bij het maken van nieuwe objecten. We kunnen bijvoorbeeld zien dat er in ons bestand /usr/local/nagios/etc/objects/templates.cfg een sjabloon is met de naam linux-server, die zal worden gebruikt om onze servers toe te voegen.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Met behulp van deze sjabloon nemen onze hosts de configuratie over zonder ze één voor één te hoeven specificeren op elke server die we toevoegen.
We hebben ook voorgedefinieerde commando's, contacten en tijdsperioden.
De commando's zullen door Nagios worden gebruikt voor zijn controles, en dat is wat we toevoegen aan het configuratiebestand van elke server om het te controleren. PING bijvoorbeeld:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}We hebben de mogelijkheid om contacten of groepen aan te maken en te specificeren welke meldingen ik welke persoon of groep wil bereiken.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}Voor onze checks en alerts kunnen we configureren op welke uren en dagen we ze willen ontvangen. Als we een service hebben die niet kritiek is, willen we waarschijnlijk niet 's ochtends wakker worden, dus het zou goed zijn om alleen tijdens werkuren te waarschuwen om dit te voorkomen.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Laten we nu kijken hoe we waarschuwingen aan onze Nagios kunnen toevoegen.
We gaan onze PostgreSQL-servers monitoren, dus we voegen ze eerst toe als hosts in onze objectdirectory. We zullen 3 nieuwe bestanden maken:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Dan moeten we ze toevoegen aan het bestand nagios.cfg en hier hebben we 2 opties.
Voeg onze hosts (cfg-bestanden) één voor één toe met behulp van de variabele cfg_file (standaardoptie) of voeg alle cfg-bestanden toe die we in een map hebben met behulp van de variabele cfg_dir.
We zullen de bestanden één voor één toevoegen volgens de standaardstrategie.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgHiermee laten we onze hosts in de gaten houden. Nu moeten we alleen nog toevoegen welke diensten we willen monitoren. Hiervoor zullen we enkele reeds gedefinieerde controles gebruiken (check_ssh en check_ping), en we zullen enkele basiscontroles van het besturingssysteem toevoegen, zoals onder andere belasting en schijfruimte, met behulp van NRPE.
Download de whitepaper vandaag PostgreSQL-beheer en -automatisering met ClusterControlLees wat u moet weten om PostgreSQL te implementeren, bewaken, beheren en schalenDownload de whitepaperWat is NRPE?
Nagios externe plug-in uitvoerder. Met deze tool kunnen we Nagios-plug-ins op een externe host op een zo transparant mogelijke manier uitvoeren.
Om het te gebruiken, moeten we de server installeren in elk knooppunt dat we willen controleren, en onze Nagios zal als client verbinding maken met elk van hen en de bijbehorende plug-in (s) uitvoeren.
Hoe NRPE installeren?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpeVervolgens bewerken we het configuratiebestand /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>En we herstarten de NRPE-service:
[example@sqldat.com ~]# systemctl restart nrpeWe kunnen de verbinding testen door het volgende uit te voeren vanaf onze Nagios-server:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Hoe controleer ik PostgreSQL?
Bij het bewaken van PostgreSQL zijn er twee hoofdgebieden waarmee u rekening moet houden:besturingssysteem en databases.
Voor het besturingssysteem heeft NRPE enkele basiscontroles geconfigureerd, zoals schijfruimte en belasting, onder andere. Deze controles kunnen op de volgende manier heel eenvoudig worden ingeschakeld.
In onze nodes bewerken we het bestand /usr/local/nagios/etc/nrpe.cfg en gaan we naar de volgende regels:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200De namen tussen vierkante haken zijn de namen die we in onze Nagios-server zullen gebruiken om deze controles in te schakelen.
In onze Nagios bewerken we de bestanden van de 3 knooppunten:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgWe voegen deze controles toe die we eerder zagen en laten onze bestanden als volgt achter:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}En we herstarten de nagios-service:
[example@sqldat.com ~]# systemctl start nagiosAls we nu naar het gedeelte Services in de webinterface van onze Nagios gaan, zouden we zoiets als het volgende moeten hebben:
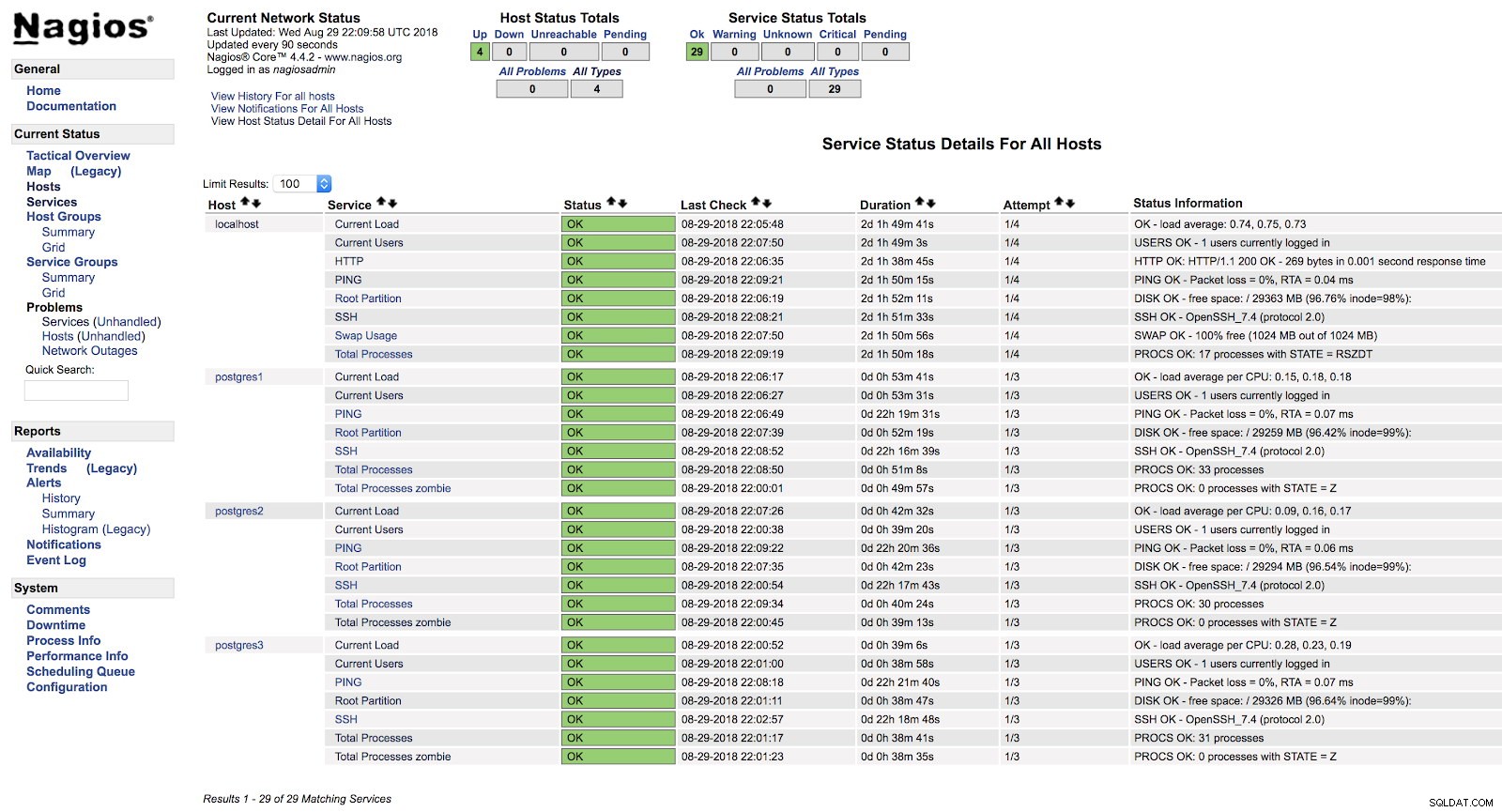 Nagios Host-waarschuwingen
Nagios Host-waarschuwingen Op deze manier behandelen we de basiscontroles van onze server op het niveau van het besturingssysteem.
We hebben nog veel meer controles die we kunnen toevoegen en we kunnen zelfs onze eigen controles maken (we zullen later een voorbeeld zien).
Laten we nu eens kijken hoe we onze PostgreSQL-database-engine kunnen controleren met behulp van twee van de belangrijkste plug-ins die voor deze taak zijn ontworpen.
Check_postgres
Een van de meest populaire plug-ins voor het controleren van PostgreSQL is check_postgres van Bucardo.
Laten we eens kijken hoe we het kunnen installeren en gebruiken met onze PostgreSQL-database.
Pakketten vereist
[example@sqldat.com ~]# yum install perl-develInstallatie
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksDit laatste commando creëert de links om alle functies van deze controle te gebruiken, zoals check_postgres_connection, check_postgres_last_vacuum of check_postgres_replication_slots onder andere.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…We voegen in ons NRPE-configuratiebestand (/usr/local/nagios/etc/nrpe.cfg) de regel toe om de controle uit te voeren die we willen gebruiken:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100In ons voorbeeld hebben we 4 basiscontroles voor PostgreSQL toegevoegd. We zullen Locks, Bloat, Connection en Backends monitoren.
In het bestand dat overeenkomt met onze database op de Nagios-server (/usr/local/nagios/etc/objects/postgres1.cfg), voegen we de volgende vermeldingen toe:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}En nadat we beide services (NRPE en Nagios) op beide servers opnieuw hebben opgestart, kunnen we zien dat onze waarschuwingen zijn geconfigureerd.
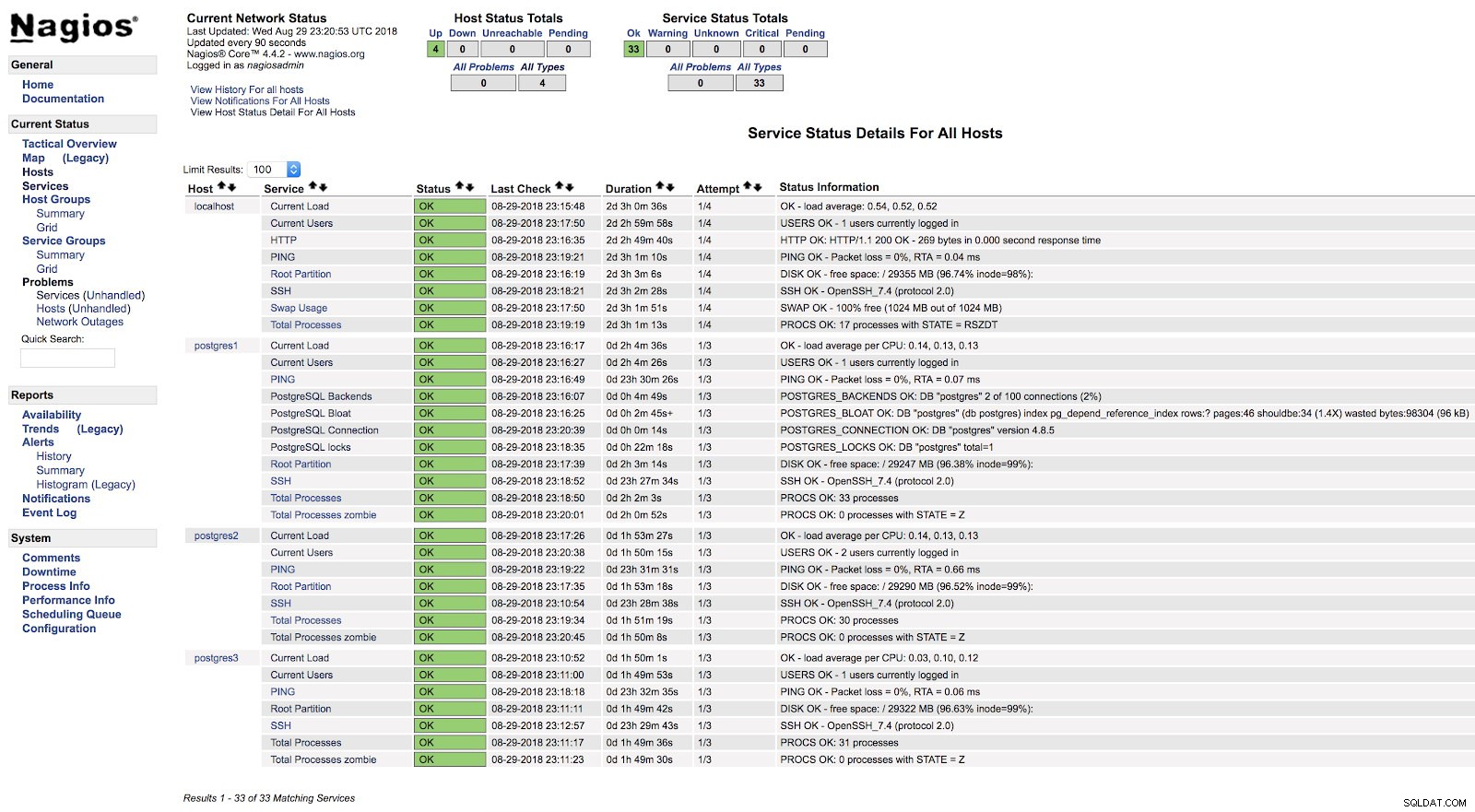 Nagios check_postgres-waarschuwingen
Nagios check_postgres-waarschuwingen In de officiële documentatie van de check_postgres-plug-in vindt u informatie over wat u nog meer moet controleren en hoe u dit moet doen.
Check_pgactivity
Nu is het de beurt aan check_pgactivity, ook populair voor het monitoren van onze PostgreSQL-database.
Installatie
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityWe voegen in ons NRPE-configuratiebestand (/usr/local/nagios/etc/nrpe.cfg) de regel toe om de controle uit te voeren die we willen gebruiken:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10In ons voorbeeld zullen we 4 basiscontroles voor PostgreSQL toevoegen. We zullen backends, verbinding, ongeldige indexen en vergrendelingen controleren.
In het bestand dat overeenkomt met onze database op de Nagios-server (/usr/local/nagios/etc/objects/postgres2.cfg), voegen we de volgende vermeldingen toe:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}En nadat we beide services (NRPE en Nagios) op beide servers opnieuw hebben opgestart, kunnen we zien dat onze waarschuwingen zijn geconfigureerd.
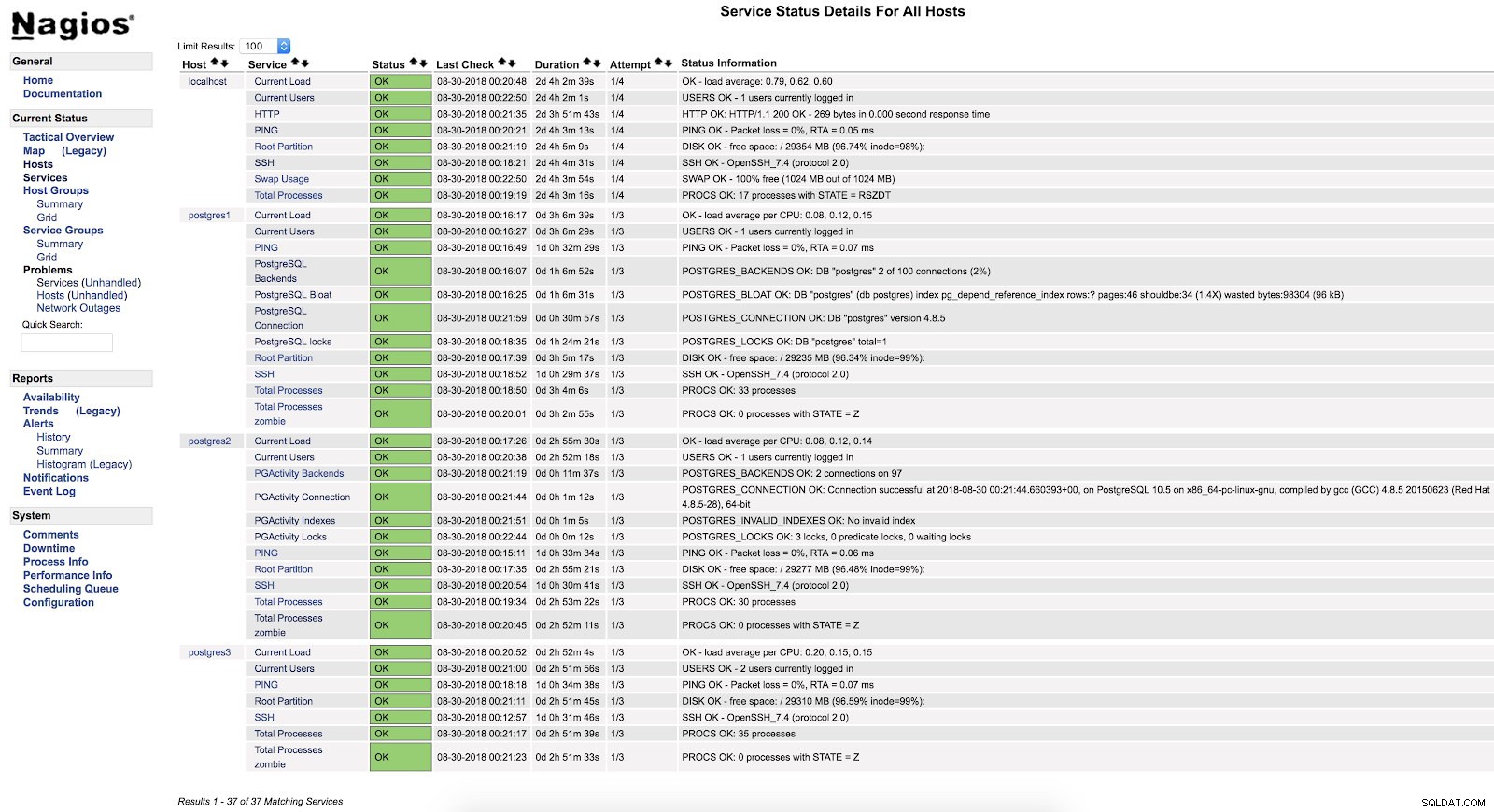 Nagios check_pgactivity-waarschuwingen
Nagios check_pgactivity-waarschuwingen Controleer foutenlogboek
Een van de belangrijkste controles, of de belangrijkste, is het controleren van ons foutenlogboek.
Hier kunnen we verschillende soorten fouten vinden, zoals FATAL of deadlock, en het is een goed startpunt om elk probleem in onze database te analyseren.
Om ons foutenlogboek te controleren, zullen we ons eigen monitoringscript maken en dit integreren in onze Nagios (dit is slechts een voorbeeld, dit script is eenvoudig en heeft veel ruimte voor verbetering).
Script
We zullen het bestand /usr/local/nagios/libexec/check_postgres_log.sh maken op onze PostgreSQL3-server.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiHet belangrijkste van het script is om de uitvoer correct te maken die overeenkomt met elke status. Deze uitgangen worden gelezen door Nagios en elk nummer komt overeen met een status:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNIn ons voorbeeld zullen we slechts 2 toestanden gebruiken, OK en CRITICAL, omdat we alleen geïnteresseerd zijn om te weten of er fouten van het type FATAL in ons foutenlogboek zijn in het huidige uur.
De tekst die we gebruiken voor onze exit wordt getoond door de webinterface van onze Nagios, dus het moet zo duidelijk mogelijk zijn om dit als een gids voor het probleem te gebruiken.
Zodra we ons monitoringscript hebben voltooid, zullen we het uitvoeringsmachtigingen geven, het toewijzen aan de gebruikersnagios en het toevoegen aan onze databaseserver NRPE en aan onze Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Start NRPE en Nagios opnieuw. Dan kunnen we onze cheque zien in de Nagios-interface:
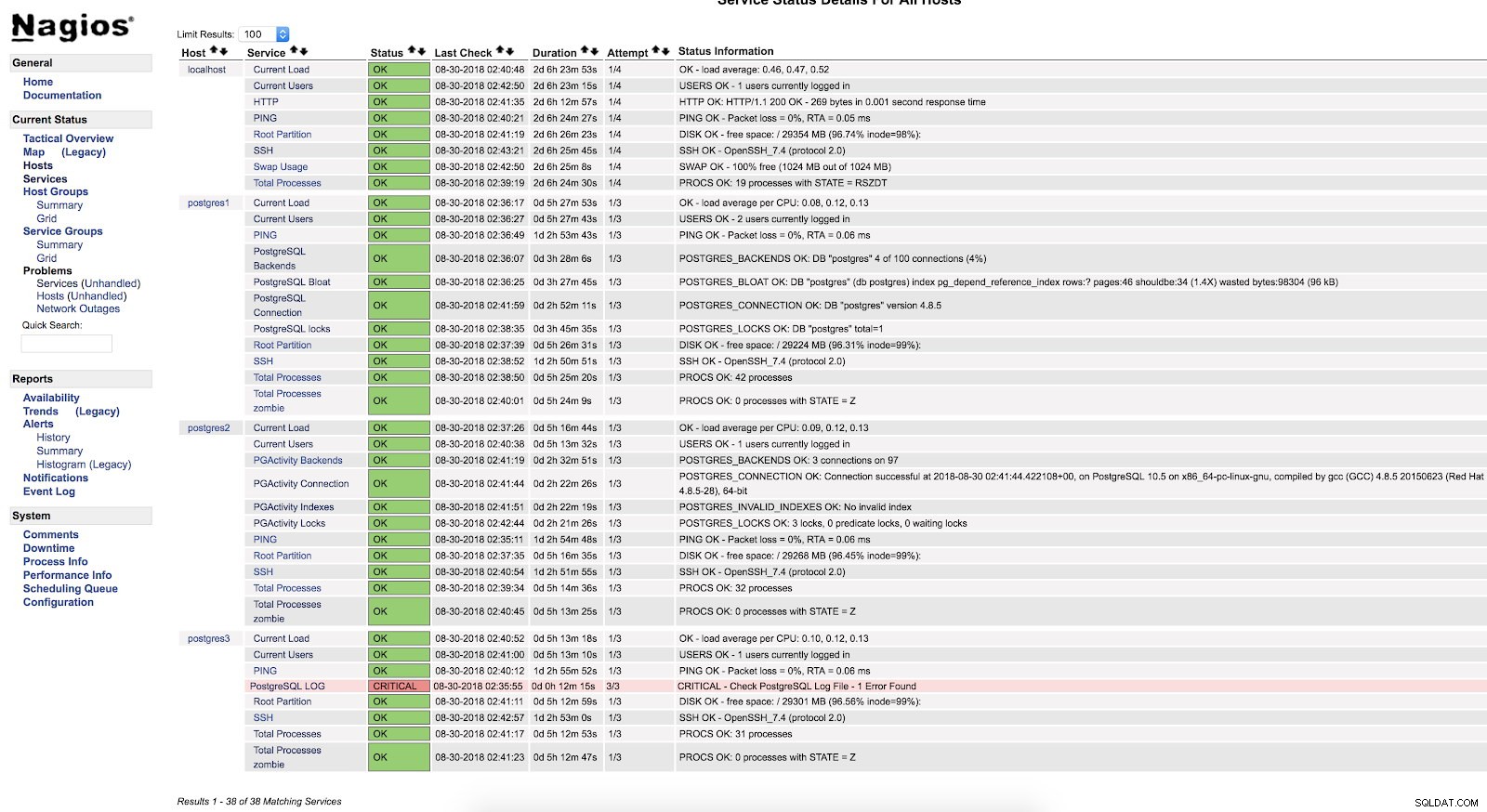 Nagios-scriptwaarschuwingen
Nagios-scriptwaarschuwingen Zoals we kunnen zien, bevindt het zich in een KRITIEKE staat, dus als we naar het logboek gaan, kunnen we het volgende zien:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Voor meer informatie over wat we kunnen monitoren in onze PostgreSQL-database, raad ik je aan onze blogs over prestaties en monitoring of dit Postgres Performance-webinar te bekijken.
Veiligheid en prestaties
Bij het configureren van monitoring, met behulp van plug-ins of ons eigen script, moeten we heel voorzichtig zijn met 2 zeer belangrijke dingen:veiligheid en prestaties.
Wanneer we de benodigde machtigingen voor monitoring toewijzen, moeten we zo beperkend mogelijk zijn, de toegang alleen lokaal of vanaf onze monitoringserver beperken, beveiligde sleutels gebruiken, verkeer versleutelen, zodat de verbinding tot het minimum wordt beperkt dat nodig is om de monitoring te laten werken.
Met betrekking tot de prestaties is monitoring noodzakelijk, maar het is ook noodzakelijk om het veilig te gebruiken voor onze systemen.
We moeten oppassen dat we geen onredelijk hoge schijftoegang genereren of query's uitvoeren die de prestaties van onze database negatief beïnvloeden.
Als we veel transacties per seconde hebben die gigabytes aan logboeken genereren en we blijven continu op zoek naar fouten, is dit waarschijnlijk niet het beste voor onze database. We moeten dus een evenwicht bewaren tussen wat we monitoren, hoe vaak en de impact op de prestaties.
Conclusie
Er zijn meerdere manieren om monitoring te implementeren of te configureren. We kunnen het zo complex of zo eenvoudig doen als we willen. Het doel van deze blog was om u kennis te laten maken met het monitoren van PostgreSQL met behulp van een van de meest gebruikte open source tools. We hebben ook gezien dat de configuratie zeer flexibel is en kan worden aangepast aan verschillende behoeften.
En vergeet niet dat we altijd op de community kunnen vertrouwen, dus ik laat enkele links achter die van grote hulp kunnen zijn.
Ondersteuningsforum:https://support.nagios.com/forum/
Bekende problemen:https://github.com/NagiosEnterprises/nagioscore/issues
Nagios-plug-ins:https://exchange.nagios.org/directory/Plugins
Nagios-plug-in voor ClusterControl:https://severalnines.com/blog/nagios-plugin-clustercontrol