In mijn laatste bericht heb ik aangetoond dat een voor geheugen geoptimaliseerd TVP bij kleine volumes aanzienlijke prestatievoordelen kan opleveren voor typische querypatronen.
Om op iets hogere schaal te testen, heb ik een kopie gemaakt van de SalesOrderDetailEnlarged tabel, die ik had uitgebreid tot ongeveer 5.000.000 rijen dankzij dit script van Jonathan Kehayias (blog | @SQLPoolBoy)).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Ik heb ook drie in-memory versies van deze tabel gemaakt, elk met een ander aantal emmers (vissen naar een "sweet spot") - 16.384, 131.072 en 1.048.576. (Je kunt rondere getallen gebruiken, maar ze worden toch afgerond naar de volgende macht van 2.) Voorbeeld:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Merk op dat ik de maat van de emmer heb gewijzigd ten opzichte van het vorige voorbeeld (256). Bij het samenstellen van de tabel wilt u de "sweet spot" voor de grootte van de bucket kiezen - u wilt de hash-index optimaliseren voor het opzoeken van punten, wat betekent dat u zoveel mogelijk buckets wilt met zo min mogelijk rijen in elke bucket. Als u ~5 miljoen buckets maakt (aangezien in dit geval, misschien niet zo'n goed voorbeeld, er ~5 miljoen unieke combinaties van waarden zijn), zult u natuurlijk wat afwegingen moeten maken tussen geheugengebruik en garbagecollection. Als u echter ~ 5 miljoen unieke waarden in 256 buckets probeert te proppen, zult u ook enkele problemen ondervinden. In ieder geval gaat deze discussie veel verder dan mijn tests voor dit bericht.
Om te testen met de standaardtabel, heb ik soortgelijke opgeslagen procedures gemaakt als in de vorige tests:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Dus eerst kijken naar de plannen voor bijvoorbeeld 1.000 rijen die in de tabelvariabelen worden ingevoegd en vervolgens de procedures uitvoeren:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Deze keer zien we dat in beide gevallen de optimizer heeft gekozen voor een geclusterde index-zoekopdracht tegen de basistabel en een geneste lus-join tegen de TVP. Sommige kostenstatistieken zijn anders, maar verder zijn de plannen vrij gelijkaardig:
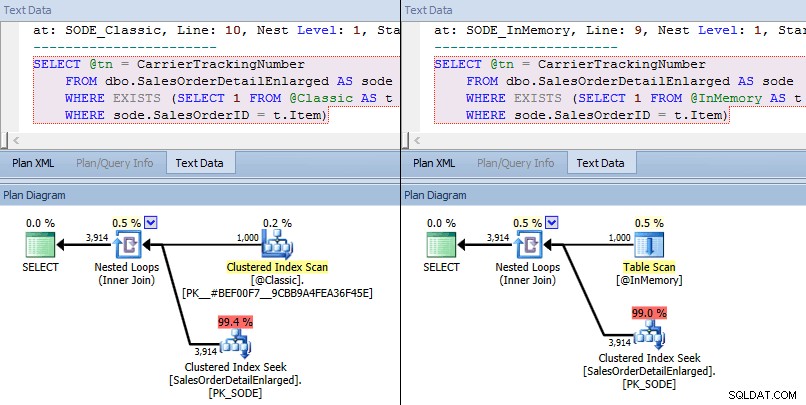 Vergelijkbare plannen voor in-memory TVP versus klassieke TVP op grotere schaal
Vergelijkbare plannen voor in-memory TVP versus klassieke TVP op grotere schaal
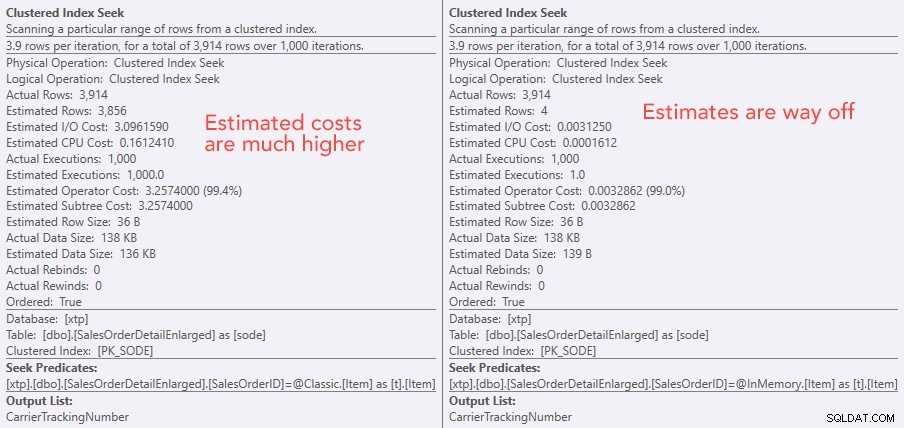 Zoek operatorkosten vergelijken – Klassiek aan de linkerkant, In-Memory aan de rechterkant
Zoek operatorkosten vergelijken – Klassiek aan de linkerkant, In-Memory aan de rechterkant
Door de absolute waarde van de kosten lijkt het alsof de klassieke TVP een stuk minder efficiënt zou zijn dan de In-Memory TVP. Maar ik vroeg me af of dit in de praktijk waar zou zijn (vooral omdat het geschatte aantal executies aan de rechterkant verdacht leek), dus deed ik natuurlijk wat tests. Ik besloot te controleren op 100, 1.000 en 2.000 waarden die naar de procedure moesten worden gestuurd.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
De prestatieresultaten laten zien dat, bij grotere aantallen point lookups, het gebruik van een In-Memory TVP leidt tot een licht afnemend rendement, dat elke keer iets langzamer is:
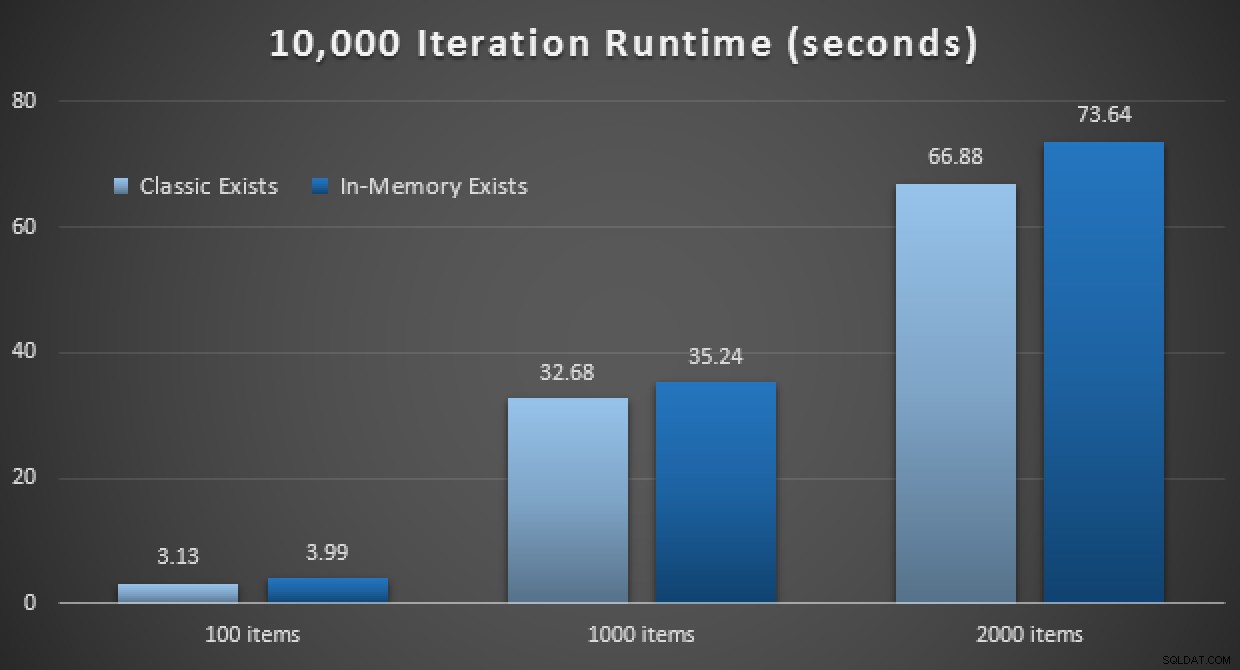
Resultaten van 10.000 uitvoeringen met klassieke en in-memory TVP's
Dus, in tegenstelling tot de indruk die je uit mijn vorige bericht hebt gekregen, is het gebruik van een in-memory TVP niet in alle gevallen noodzakelijk voordelig.
Eerder keek ik ook naar native gecompileerde opgeslagen procedures en in-memory tabellen, in combinatie met in-memory TVP's. Zou dit hier het verschil kunnen maken? Spoiler:absoluut niet. Ik heb drie procedures als volgt gemaakt:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Nog een spoiler:ik kon deze 9 tests niet uitvoeren met een iteratietelling van 10.000 - het duurde veel te lang. In plaats daarvan heb ik elke procedure 10 keer doorlopen en uitgevoerd, die reeks tests 10 keer uitgevoerd en het gemiddelde genomen. Dit zijn de resultaten:
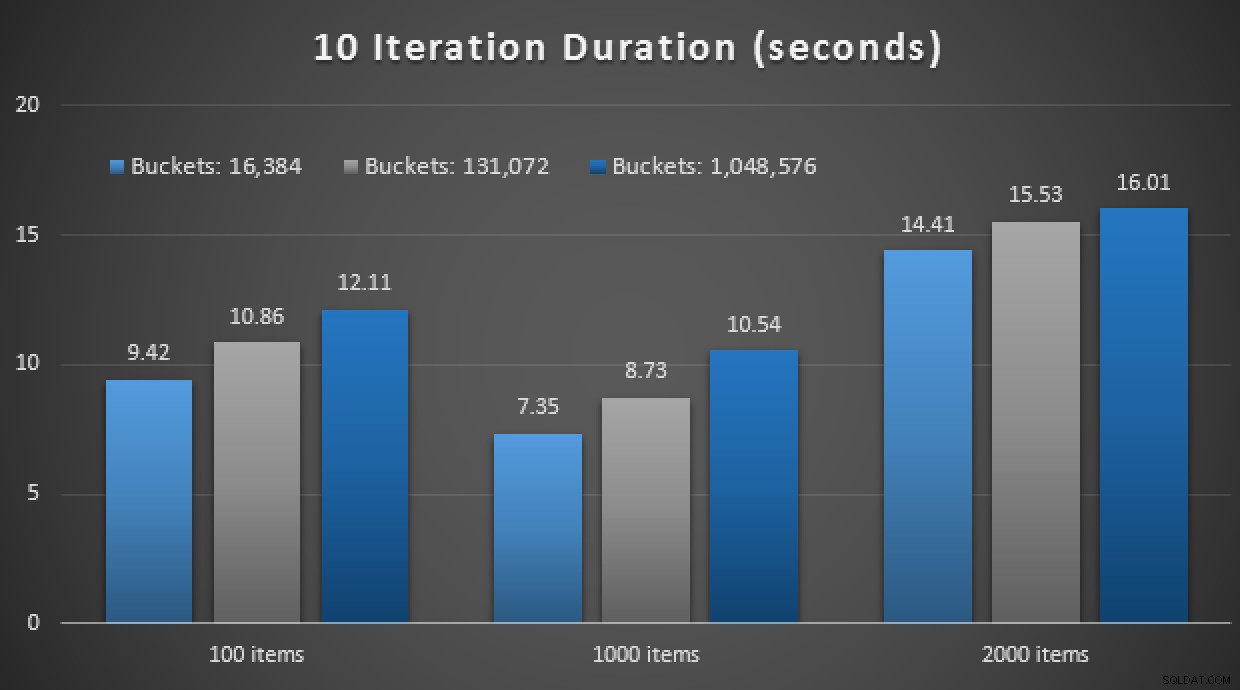
Resultaten van 10 uitvoeringen met in-memory TVP's en native gecompileerde opgeslagen procedures
Over het algemeen was dit experiment nogal teleurstellend. Alleen al kijkend naar de enorme omvang van het verschil, met een tabel op de schijf, werd de gemiddelde opgeslagen procedure-aanroep voltooid in gemiddeld 0,0036 seconden. Toen alles echter in-memory-technologieën gebruikte, was de gemiddelde opgeslagen procedure-aanroep 1,1662 seconden. Auw . Het is zeer waarschijnlijk dat ik zojuist een slechte use-case heb gekozen om in het algemeen te demonstreren, maar het leek op dat moment een intuïtieve "eerste poging".
Conclusie
Er valt nog veel meer te testen rond dit scenario en ik heb nog meer blogposts te volgen. Ik heb nog niet de optimale use-case voor in-memory TVP's op grotere schaal geïdentificeerd, maar ik hoop dat dit bericht een herinnering is dat, hoewel een oplossing in één geval optimaal lijkt, het nooit veilig is om aan te nemen dat deze even toepasbaar is naar verschillende scenario's. Dit is precies hoe In-Memory OLTP moet worden benaderd:als een oplossing met een beperkt aantal use-cases die absoluut moeten worden gevalideerd voordat ze in productie worden geïmplementeerd.