Een belangrijk onderdeel van het afstemmen van query's is het begrijpen van de algoritmen die beschikbaar zijn voor de optimizer om verschillende queryconstructies af te handelen, zoals filteren, samenvoegen, groeperen en aggregeren, en hoe deze worden geschaald. Deze kennis helpt je om een optimale fysieke omgeving voor je queries voor te bereiden, zoals het maken van de juiste indexen. Het helpt u ook om intuïtief aan te voelen welk algoritme u onder bepaalde omstandigheden in het plan zou verwachten, op basis van uw bekendheid met de drempels waar de optimizer van het ene algoritme naar het andere moet overschakelen. Wanneer u vervolgens slecht presterende zoekopdrachten afstemt, kunt u gemakkelijker gebieden in het zoekopdrachtplan vinden waar de optimalisatieprogramma suboptimale keuzes heeft gemaakt, bijvoorbeeld vanwege onnauwkeurige kardinaliteitsschattingen, en actie ondernemen om deze te corrigeren.
Een ander belangrijk onderdeel van het afstemmen van zoekopdrachten is out-of-the-box denken - verder dan de algoritmen die beschikbaar zijn voor de optimizer bij het gebruik van de voor de hand liggende tools. Wees creatief. Stel dat u een zoekopdracht heeft die slecht presteert, ook al heeft u de optimale fysieke omgeving geregeld. Voor de queryconstructies die u hebt gebruikt, zijn de algoritmen die beschikbaar zijn voor de optimizer x, y en z, en de optimizer heeft het beste gekozen dat onder de omstandigheden kon. Toch presteert de query slecht. Kun je je een theoretisch plan voorstellen met een algoritme dat een veel beter presterende query kan opleveren? Als je het je kunt voorstellen, is de kans groot dat je het kunt bereiken met wat herschrijving van de query, misschien met minder voor de hand liggende query-constructies voor de taak.
In deze serie artikelen richt ik me op het groeperen en aggregeren van gegevens. Ik zal beginnen met het doornemen van de algoritmen die beschikbaar zijn voor de optimizer bij het gebruik van gegroepeerde zoekopdrachten. Vervolgens zal ik scenario's beschrijven waarin geen van de bestaande algoritmen het goed doet en herschrijvingen van query's laten zien die leiden tot uitstekende prestaties en schaalbaarheid.
Ik wil Craig Freedman, Vassilis Papadimos en Joe Sack, leden van de kruising van de slimste mensen ter wereld en de groep SQL Server-ontwikkelaars, bedanken voor het beantwoorden van mijn vragen over query-optimalisatie!
Voor voorbeeldgegevens gebruik ik een database met de naam PerformanceV3. U kunt hier een script downloaden om de database te maken en te vullen. Ik gebruik een tabel met de naam dbo.Orders, die is gevuld met 1.000.000 rijen. Deze tabel heeft een aantal indexen die niet nodig zijn en die mijn voorbeelden kunnen verstoren, dus voer de volgende code uit om die onnodige indexen te verwijderen:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
De enige twee indexen die overblijven in deze tabel zijn een geclusterde index genaamd idx_cl_od in de orderdate-kolom en een niet-geclusterde unieke index genaamd PK_Orders in de orderid-kolom, waardoor de primaire sleutelbeperking wordt gehandhaafd.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Bestaande algoritmen
SQL Server ondersteunt twee hoofdalgoritmen voor het samenvoegen van gegevens:Stream Aggregate en Hash Aggregate. Bij gegroepeerde query's vereist het Stream Aggregate-algoritme dat de gegevens worden geordend op de gegroepeerde kolommen, dus u moet onderscheid maken tussen twee gevallen. Een daarvan is een vooraf besteld Stream Aggregate, bijvoorbeeld wanneer gegevens worden verkregen die vooraf zijn besteld uit een index. Een andere is een niet-vooraf bestelde Stream Aggregate, waarbij een extra stap nodig is om de invoer expliciet te sorteren. Deze twee gevallen schalen heel verschillend, dus je kunt ze net zo goed als twee verschillende algoritmen beschouwen.
Het Hash Aggregate-algoritme organiseert de groepen en hun aggregaten in een hashtabel. De invoer hoeft niet te worden besteld.
Met voldoende gegevens overweegt de optimizer het werk te parallelliseren door een zogenaamd lokaal-wereldwijd aggregaat toe te passen. In een dergelijk geval wordt de invoer opgesplitst in meerdere threads en past elke thread een van de bovengenoemde algoritmen toe om de subset van rijen lokaal te aggregeren. Een globaal aggregaat gebruikt vervolgens een van de bovengenoemde algoritmen om de resultaten van de lokale aggregaten te aggregeren.
In dit artikel concentreer ik me op het vooraf bestelde Stream Aggregate-algoritme en de schaal ervan. In toekomstige delen van deze serie zal ik andere algoritmen behandelen en de drempels beschrijven waar de optimizer van de ene naar de andere overschakelt, en wanneer u herschrijvingen van query's moet overwegen.
Gereserveerd Stream Aggregate
Gegeven een gegroepeerde query met een niet-lege groeperingsset (de set expressies waarop u groepeert), vereist het Stream Aggregate-algoritme dat de invoerrijen worden geordend op de expressies die de groeperingsset vormen. Wanneer het algoritme de eerste rij in een groep verwerkt, initialiseert het een lid met de tussenliggende totaalwaarde met de relevante waarde (bijv. de waarde van de eerste rij voor een MAX-aggregaat). Wanneer het een niet-eerste rij in de groep verwerkt, wijst het dat lid toe met het resultaat van een berekening waarbij de tussenliggende aggregatiewaarde en de nieuwe rijwaarde (bijvoorbeeld het maximum tussen de tussenliggende aggregatiewaarde en de nieuwe waarde) betrokken zijn. Zodra een van de leden van de groeperingsset van waarde verandert of de invoer is verbruikt, wordt de huidige totale waarde beschouwd als het eindresultaat voor de laatste groep.
Een manier om de gegevens te ordenen zoals het Stream Aggregate-algoritme nodig heeft, is door ze vooraf te bestellen via een index. U moet de index definiëren met de kolommen van de groeperingsset als de sleutels, in willekeurige volgorde. U wilt ook dat de index dekt. Beschouw bijvoorbeeld de volgende vraag (we noemen het vraag 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Een optimale rowstore-index om deze zoekopdracht te ondersteunen, zou er een zijn die is gedefinieerd met shipperid als de leidende sleutelkolom en de besteldatum als een opgenomen kolom of als een tweede sleutelkolom:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
Met deze index op zijn plaats, krijgt u het geschatte plan weergegeven in Afbeelding 1 (met behulp van SentryOne Plan Explorer).

Figuur 1:Plan voor Query 1
Merk op dat de Index Scan-operator een Ordered:True-eigenschap heeft die aangeeft dat het vereist is om de rijen te leveren die zijn geordend met de indexsleutel. De Stream Aggregate-operator neemt vervolgens de geordende rijen op zoals nodig is. Wat betreft hoe de kosten van de operator worden berekend; voordat we daartoe komen, eerst een kort voorwoord…
Zoals u wellicht al weet, evalueert SQL Server, wanneer een query wordt geoptimaliseerd, meerdere kandidaatplannen en kiest uiteindelijk degene met de laagste geschatte kosten. De geschatte plankosten zijn de som van alle geschatte kosten van de operators. De geschatte kosten van elke operator zijn op hun beurt de som van de geschatte I/O-kosten en de geschatte CPU-kosten. De kosteneenheid is op zich nietszeggend. De relevantie ervan zit in de vergelijking die de optimizer maakt tussen kandidaatplannen. Dat wil zeggen, de kostenformules zijn ontworpen met het doel dat, tussen kandidaatplannen, degene met de laagste kosten (hopelijk) degene is die sneller klaar is. Een vreselijk complexe taak om nauwkeurig uit te voeren!
Hoe meer de kostenformules voldoende rekening houden met de factoren die echt van invloed zijn op de prestaties en schaling van het algoritme, hoe nauwkeuriger ze zijn, en hoe waarschijnlijker het is dat de optimizer, gegeven nauwkeurige kardinaliteitsschattingen, het optimale plan zal kiezen. Als je wilt begrijpen waarom de optimizer het ene algoritme kiest ten opzichte van het andere, moet je in ieder geval twee hoofdzaken begrijpen:één is hoe de algoritmen werken en schalen, en een andere is het kostenmodel van SQL Server.
Dus terug naar het plan in figuur 1; laten we proberen te begrijpen hoe de kosten worden berekend. Als beleid zal Microsoft de interne kostenformules die ze gebruiken niet onthullen. Als kind was ik gefascineerd door dingen uit elkaar te halen. Horloges, radio's, cassettebandjes (ja, zo oud ben ik), noem maar op. Ik wilde weten hoe dingen gemaakt werden. Evenzo zie ik waarde in het reverse-engineeren van de formules, want als ik erin slaag om de kosten redelijk nauwkeurig te voorspellen, betekent dit waarschijnlijk dat ik het algoritme goed begrijp. Tijdens het proces leer je veel.
Onze query neemt 1.000.000 rijen op. Zelfs met dit aantal rijen lijken de I/O-kosten te verwaarlozen in vergelijking met de CPU-kosten, dus het is waarschijnlijk veilig om deze te negeren.
Wat betreft de CPU-kosten, u wilt proberen erachter te komen welke factoren hierop van invloed zijn en op welke manier. Theoretisch kunnen er een aantal factoren zijn:het aantal invoerrijen, het aantal groepen, de kardinaliteit van de groeperingsset, het gegevenstype en de grootte van de leden van de groeperingsset. Dus om te proberen het effect van een van deze factoren te meten, wilt u de geschatte kosten van twee zoekopdrachten vergelijken die alleen verschillen in de factor die u wilt meten. Om bijvoorbeeld de impact van het aantal rijen op de kosten te meten, moet u twee query's hebben met een verschillend aantal invoerrijen, maar met alle andere aspecten hetzelfde (aantal groepen, kardinaliteit van groeperingsset, enz.). Het is ook belangrijk om te controleren of de geschatte aantallen - niet de werkelijke - de gewenste zijn, aangezien de optimizer vertrouwt op de geschatte aantallen om de kosten te berekenen.
Bij het maken van dergelijke vergelijkingen is het goed om technieken te hebben waarmee u de geschatte aantallen volledig kunt controleren. Een eenvoudige manier om het geschatte aantal invoerrijen te bepalen, is bijvoorbeeld een query uit te voeren op een tabelexpressie die is gebaseerd op een TOP-query en de aggregatiefunctie in de buitenste query toe te passen. Als u zich zorgen maakt dat door uw gebruik van de TOP-operator de optimizer rijdoelen toepast en dat deze zullen leiden tot aanpassing van de oorspronkelijke kosten, is dit alleen van toepassing op operators die voorkomen in het plan onder de Top-operator (voor de rechts), niet boven (naar links). De Stream Aggregate-operator verschijnt natuurlijk boven de Top-operator in het plan, omdat deze de gefilterde rijen opneemt.
Wat betreft het regelen van het geschatte aantal uitvoergroepen, u kunt dit doen door de groeperingsexpressie
Om ervoor te zorgen dat u het Stream Aggregate-algoritme en een serieel plan krijgt, kunt u dit forceren met de query-hints:OPTION(ORDER GROUP, MAXDOP 1).
U wilt ook weten of er opstartkosten zijn voor de operator, zodat u hiermee rekening kunt houden in uw reverse-engineering-formule.
Laten we beginnen met het uitzoeken van de manier waarop het aantal invoerrijen de geschatte CPU-kosten van de operator beïnvloedt. Het is duidelijk dat deze factor relevant moet zijn voor de kosten van de exploitant. Je zou ook verwachten dat de kosten per rij constant zijn. Hier zijn een paar vergelijkingsvragen die alleen verschillen in het geschatte aantal invoerrijen (noem ze respectievelijk Query 2 en Query 3):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Afbeelding 2 bevat de relevante delen van de geschatte plannen voor deze vragen:

Figuur 2:Plannen voor Query 2 en Query 3
Ervan uitgaande dat de kosten per rij constant zijn, kunt u deze berekenen als het verschil tussen de operatorkosten gedeeld door het verschil tussen de invoerkardinaliteiten van de operator:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
Om te controleren of het aantal dat u hebt gekregen inderdaad constant en correct is, kunt u proberen de geschatte kosten te voorspellen in zoekopdrachten met andere aantallen invoerrijen. De voorspelde kosten met 500.000 invoerrijen zijn bijvoorbeeld:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Gebruik de volgende query om te controleren of uw voorspelling juist is (noem het Query 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Het relevante deel van het plan voor deze vraag wordt getoond in figuur 3.
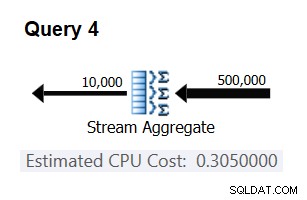
Figuur 3:Plan voor Query 4
Bingo. Het is natuurlijk een goed idee om meerdere extra invoerkardinaliteiten te controleren. Met al degenen die ik heb gecontroleerd, was de stelling dat er een constante kost per invoerrij van 0,0000006 is correct.
Laten we vervolgens proberen te achterhalen hoe het geschatte aantal groepen de CPU-kosten van de operator beïnvloedt. Je zou verwachten dat er wat CPU-werk nodig is om elke groep te verwerken, en het is ook redelijk om te verwachten dat het per groep constant is. Om dit proefschrift te testen en de kosten per groep te berekenen, kun je de volgende twee queries gebruiken, die alleen verschillen in het aantal resultaatgroepen (noem ze respectievelijk Query 5 en Query 6):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
De relevante delen van de geschatte zoekplannen worden weergegeven in figuur 4.
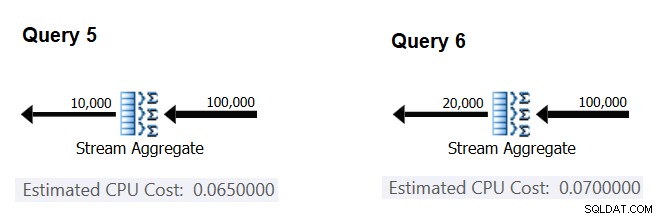
Figuur 4:Plannen voor Query 5 en Query 6
Net zoals u de vaste kosten per invoerregel hebt berekend, kunt u de vaste kosten per uitvoergroep berekenen als het verschil tussen de operatorkosten gedeeld door het verschil tussen de uitvoerkardinaliteiten van de operator:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
En net zoals ik eerder heb aangetoond, kunt u uw bevindingen verifiëren door de kosten te voorspellen met andere aantallen outputgroepen en uw voorspelde aantallen te vergelijken met die van de optimizer. Met alle aantallen groepen die ik heb geprobeerd, waren de voorspelde kosten juist.
Met behulp van vergelijkbare technieken kunt u controleren of andere factoren van invloed zijn op de kosten van de operator. Uit mijn tests blijkt dat de kardinaliteit van de groeperingsset (aantal uitdrukkingen waarop u groepeert), de gegevenstypen en -groottes van de gegroepeerde uitdrukkingen geen invloed hebben op de geschatte kosten.
Wat overblijft is om te controleren of er zinvolle opstartkosten worden verondersteld voor de operator. Als die er is, zou de volledige (hopelijk) formule voor het berekenen van de CPU-kosten van de operator moeten zijn:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
U kunt dus de opstartkosten afleiden van de rest:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
U kunt hiervoor elk zoekplan uit dit artikel gebruiken. Als u bijvoorbeeld de cijfers gebruikt van het plan voor Query 5 dat eerder in Afbeelding 4 is weergegeven, krijgt u:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Zoals het lijkt, heeft de Stream Aggregate-operator geen CPU-gerelateerde opstartkosten, of zijn deze zo laag dat deze niet worden weergegeven met de precisie van de kostenmaatstaf.
Samenvattend, de reverse-engineering formule voor de kosten van de Stream Aggregate-operator is:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Afbeelding 5 toont de schaal van de kosten van de Stream Aggregate-operator met betrekking tot zowel het aantal rijen als het aantal groepen.
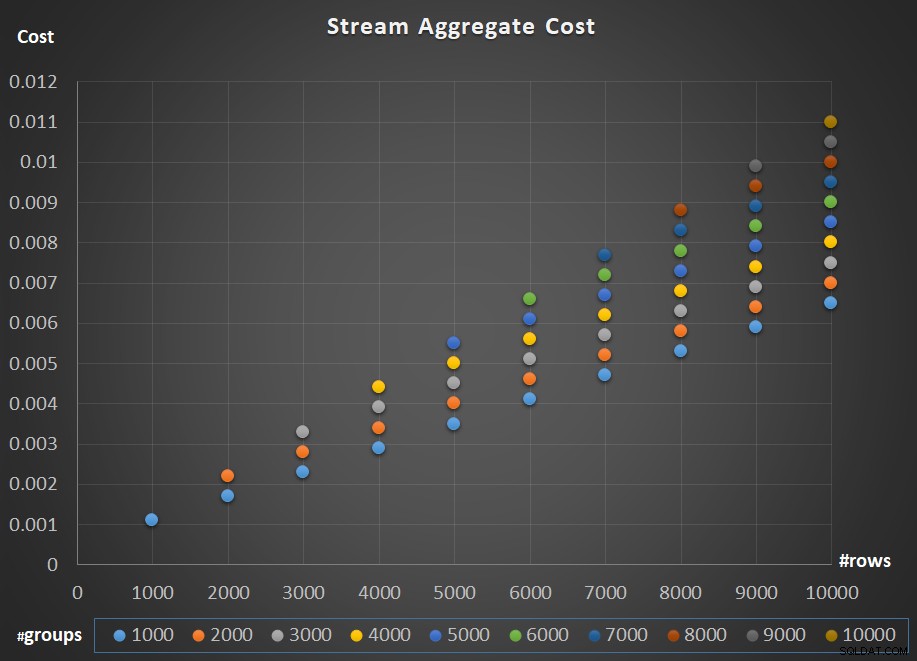
Figuur 5:Stroomaggregaat algoritme schaaldiagram
Wat betreft de schaalverdeling van de operator; het is lineair. In gevallen waarin het aantal groepen meestal evenredig is met het aantal rijen, stijgen de kosten van de hele operator met dezelfde factor als het aantal rijen en groepen. Dit betekent dat een verdubbeling van het aantal invoerrijen en invoergroepen resulteert in een verdubbeling van de totale kosten van de operator. Om te zien waarom, stel dat we de kosten van de operator weergeven als:
r * 0.0000006 + g * 0.0000005
Als u zowel het aantal rijen als het aantal groepen met dezelfde factor p verhoogt, krijgt u:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Dus als, voor een gegeven aantal rijen en groepen, de kosten van de stroomaggregaat-operator C zijn, resulteert het verhogen van zowel het aantal rijen als groepen met dezelfde factor p in een operatorkosten van pC. Kijk of u dit kunt verifiëren door voorbeelden te vinden in de tabel in figuur 5.
In gevallen waarin het aantal groepen redelijk stabiel blijft, zelfs als het aantal invoerrijen groeit, krijg je nog steeds lineaire schaling. U beschouwt de kosten die aan het aantal groepen zijn verbonden gewoon als een constante. Dat wil zeggen, als voor een bepaald aantal rijen en groepen de kosten van de operator C =G (kosten in verband met aantal groepen) plus R (kosten in verband met aantal rijen) zijn, waarbij alleen het aantal rijen met een factor wordt verhoogd p resulteert in G + pR. In een dergelijk geval zijn de kosten van de hele operator natuurlijk lager dan pc. Dat wil zeggen, een verdubbeling van het aantal rijen resulteert in minder dan een verdubbeling van de totale kosten van de operator.
In de praktijk is bij het groeperen van gegevens in veel gevallen het aantal invoerrijen aanzienlijk groter dan het aantal uitvoergroepen. Dit feit, gecombineerd met het feit dat de toegewezen kosten per rij en kosten per groep bijna hetzelfde zijn, maakt het deel van de kosten van de exploitant dat wordt toegeschreven aan het aantal groepen verwaarloosbaar. Zie als voorbeeld het plan voor Query 1 dat eerder in afbeelding 1 is weergegeven. In dergelijke gevallen is het veilig om de kosten van de operator gewoon te beschouwen als lineair schalen met betrekking tot het aantal invoerrijen.
Speciale gevallen
Er zijn speciale gevallen waarin de Stream Aggregate-operator de gegevens helemaal niet hoeft te sorteren. Als je erover nadenkt, heeft het Stream Aggregate-algoritme een meer ontspannen bestelvereiste van de invoer in vergelijking met wanneer je de gegevens nodig hebt die zijn besteld voor presentatiedoeleinden, bijvoorbeeld wanneer de query een buitenste ORDER BY-component voor de presentatie heeft. Het Stream Aggregate-algoritme hoeft alleen maar alle rijen van dezelfde groep samen te bestellen. Neem de invoerverzameling {5, 1, 5, 2, 1, 2}. Voor het bestellen van presentaties moet deze set als volgt worden geordend:1, 1, 2, 2, 5, 5. Voor aggregatiedoeleinden zou het Stream Aggregate-algoritme nog steeds goed werken als de gegevens in de volgende volgorde waren gerangschikt:5, 5, 1, 1, 2, 2. Met dit in gedachten, wanneer u een scalaire aggregatie berekent (query met een aggregatiefunctie en geen GROUP BY-component), of de gegevens groepeert op een lege groeperingsset, is er nooit meer dan één groep . Ongeacht de volgorde van de invoerrijen kan het Stream Aggregate-algoritme worden toegepast. Het Hash Aggregate-algoritme hasht de gegevens op basis van de expressies van de groeperingsset als de invoer, en zowel met scalaire aggregaten als met een lege groeperingsset zijn er geen invoergegevens om door te hashen. Dus, zowel met scalaire aggregaten als met aggregaten die worden toegepast op een lege groeperingsset, gebruikt de optimizer altijd het Stream Aggregate-algoritme, zonder dat de gegevens vooraf moeten worden besteld. Dat is in ieder geval het geval in de rij-uitvoeringsmodus, aangezien de batchmodus momenteel (vanaf SQL Server 2017 CU4) alleen beschikbaar is met het Hash Aggregate-algoritme. Ik zal de volgende twee queries gebruiken om dit aan te tonen (noem ze Query 7 en Query 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
De plannen voor deze zoekopdrachten worden weergegeven in figuur 6.
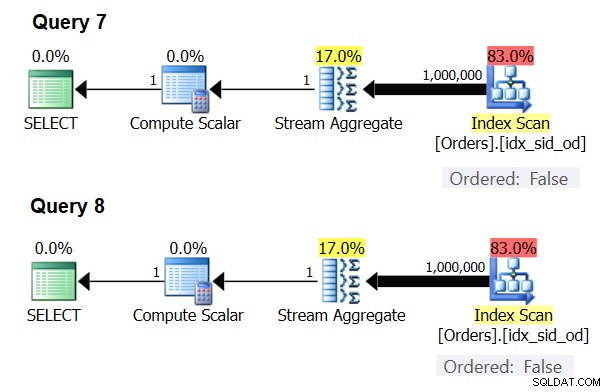
Figuur 6:Plannen voor Query 7 en Query 8
Probeer in beide gevallen een Hash Aggregate-algoritme te forceren:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
De optimizer negeert uw verzoek en produceert dezelfde plannen als weergegeven in Afbeelding 6.
Snelle quiz:wat is het verschil tussen een scalair aggregaat en een aggregaat toegepast op een lege groeperingsset?
Antwoord:met een lege invoerset retourneert een scalaire aggregatie een resultaat met één rij, terwijl een aggregatie in een query met een lege groeperingsset een lege resultaatset retourneert. Probeer het:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Als je klaar bent, voer je de volgende code uit om op te schonen:
DROP INDEX idx_sid_od ON dbo.Orders;
Samenvatting en uitdaging
Reverse-engineering van de kostprijsformule voor het Stream Aggregate-algoritme is kinderspel. Ik had je net kunnen vertellen dat de kostprijsformule voor een vooraf besteld Stream Aggregate-algoritme @numrows * 0.0000006 + @numgroups * 0.0000005 is in plaats van een heel artikel om uit te leggen hoe je dit uitzoekt. Het punt was echter om het proces en de principes van reverse-engineering te beschrijven, voordat we verder gingen met de meer complexe algoritmen en de drempels waar het ene algoritme optimaal wordt dan het andere. Je leren vissen in plaats van je vis te geven. Ik heb zoveel geleerd en dingen ontdekt waar ik nog niet eens aan heb gedacht, terwijl ik probeerde om kostprijsformules voor verschillende algoritmen te reverse-engineeren.
Klaar om je vaardigheden te testen? Je missie, als je ervoor kiest om het te accepteren, is een stuk moeilijker dan het reverse-engineeren van de Stream Aggregate-operator. Reverse-engineering van de kostprijsformule van een seriële sorteeroperator. Dit is belangrijk voor ons onderzoek, aangezien een Stream Aggregate-algoritme dat wordt toegepast voor een zoekopdracht met een niet-lege groeperingsset, waarbij de invoergegevens niet vooraf zijn geordend, expliciete sortering vereist. In een dergelijk geval hangen de kosten en schaalvergroting van de geaggregeerde operatie af van de kosten en schaalbaarheid van de Sort en de Stream Aggregate-operators samen.
Als het je lukt om behoorlijk dichtbij te komen met het voorspellen van de kosten van de Sort-operator, heb je het gevoel dat je het recht hebt verdiend om aan je handtekening "Reverse Engineer" toe te voegen. Er zijn veel software-engineers; maar je ziet zeker niet veel reverse engineers! Zorg ervoor dat u uw formule test met zowel kleine als grote getallen; je zult misschien verrast zijn door wat je vindt.