Terwijl Jeff Atwood en Joe Celko lijken te denken dat de kosten van GUID's niet zo'n groot probleem zijn (zie Jeff's blogpost, "Primary Keys:IDs versus GUIDs," en deze nieuwsgroepthread, getiteld "Identity vs. Uniqueidentifier"), andere experts - meer specifiek index- en architectuurexperts die zich richten op de SQL Server-ruimte - zijn het daar meestal niet mee eens. Kimberly Tripp bespreekt bijvoorbeeld enkele details in haar bericht, "Schijfruimte is goedkoop - DAT IS NIET HET PUNT!", waar ze uitlegt dat de impact niet alleen op schijfruimte en fragmentatie is, maar vooral op indexgrootte en geheugen voetafdruk.
Wat Kimberly zegt is echt waar - ik kom de hele tijd de rechtvaardiging "schijfruimte is goedkoop" voor GUID's tegen (voorbeeld van vorige week). Er zijn andere rechtvaardigingen voor GUID's, waaronder de noodzaak om unieke id's buiten de database te genereren (en soms voordat de rij daadwerkelijk wordt gemaakt), en de behoefte aan unieke id's voor afzonderlijke gedistribueerde systemen (en waar identiteitsbereiken niet praktisch zijn). Maar ik wil echt de mythe ontkrachten dat GUID's niet zo veel kosten, omdat ze dat wel doen, en je moet deze kosten meewegen in je beslissing.
Ik begon aan deze missie om de prestaties van verschillende sleutelgroottes te testen, gegeven dezelfde gegevens over hetzelfde aantal rijen, met dezelfde indexen en ongeveer dezelfde werklast (het opnieuw afspelen van de *exacte* dezelfde werklast kan behoorlijk uitdagend zijn). Ik wilde niet alleen de basiszaken zoals indexgrootte en indexfragmentatie meten, maar ook de effecten die deze hebben, zoals:
- impact op het gebruik van de bufferpool
- frequentie van "slechte" paginasplitsingen
- algemene impact op realistische werklastduur
- impact op de gemiddelde looptijden van afzonderlijke zoekopdrachten
- impact op runtime-duur van na triggers
- impact op tempdb-gebruik
Ik zal verschillende technieken gebruiken om deze gegevens te onderzoeken, waaronder Extended Events, de standaardtracering, tempdb-gerelateerde DMV's en SQL Sentry Performance Advisor.
Instellen
Eerst heb ik een miljoen klanten gemaakt om in een seed-tabel te plaatsen met behulp van enkele ingebouwde SQL Server-metadata; dit zou ervoor zorgen dat de "willekeurige" klanten tijdens elke test uit dezelfde natuurlijke gegevens zouden bestaan.
TABEL MAKEN dbo.CustomerSeeds(rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIEK, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Actief])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FROM ( SELECT fn, ln, em, a, r =ROW_NUMBER() OVER (VERDELING DOOR em ORDER DOOR em) FROM ( SELECT TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. naam, LEN(o.naam)%5+2) + '@' + RIGHT(c.naam, LEN(o.naam+c.naam)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) AS y WAAR r =1 GROEP OP fn, ln, em BESTEL OP n) AS z BESTEL OP rn;GO SELECTEER TOP (10) * VANAF dbo.CustomerSeeds BESTEL OP rn;GO
Uw kilometerstand kan variëren, maar op mijn systeem duurde deze populatie 86 seconden. Tien representatieve rijen (klik om te vergroten):
 Voorbeeld van klanten
Voorbeeld van klanten
Vervolgens had ik tabellen nodig om de seed-gegevens voor elke use-case te huisvesten, met een paar extra indexen om een soort realiteit te simuleren, en ik bedacht korte achtervoegsels om allerlei soorten diagnostiek later gemakkelijker te maken:
| gegevenstype | standaard | compressie | achtervoegsel gebruiken |
|---|---|---|---|
| INT | IDENTITEIT | geen | Ik |
| INT | IDENTITEIT | pagina + rij | Ic |
| BIGINT | IDENTITEIT | geen | B |
| BIGINT | IDENTITEIT | pagina + rij | Bc |
| UNIEK IDENTIFICEERDER | NIEUWID() | geen | G |
| UNIEK IDENTIFICEERDER | NIEUWID() | pagina + rij | Gc |
| UNIEK IDENTIFICEERDER | NEWSEQUENTIALID() | geen | S |
| UNIEK IDENTIFICEERDER | NEWSEQUENTIALID() | pagina + rij | Sc |
Tabel 1:Gebruiksgevallen, gegevenstypen en achtervoegsels
Acht tabellen bij elkaar, allemaal gebaseerd op hetzelfde sjabloon (ik zou de opmerkingen gewoon veranderen om ze aan te passen aan de use case, en $use_case$ vervangen met het juiste achtervoegsel uit de bovenstaande tabel):
TABEL MAKEN dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NIET NULL STANDAARD NEWID(), --CustomerID UNIQUEIDENTIFIER NIET NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, e-mail NVARCHAR(320) NOT NULL, Active BIT NOT NULL STANDAARD 1, gemaakt DATETIME NOT NULL STANDAARD SYSDATETIME(), bijgewerkt DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --MET (DATA_COMPRESSION =PAGE)GO;CREATE UNIEKE INDEX C_Email_caseCustomers_$use_use. Customers_$use_case$(EMail) --MET (DATA_COMPRESSION =PAGINA);GOCREATE INDEX C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Active =1 --MET (DATA_COMPRESSION =PAGINA);GOCREATE INDEX C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(Achternaam, Voornaam) INCLUSIEF (EMail) --MET (DATA_COMPRESSION =PAGINA);GONadat de tabellen waren gemaakt, ging ik verder met het vullen van de tabellen en het meten van veel van de statistieken waarnaar ik hierboven verwees. Ik herstartte de SQL Server-service tussen elke test om er zeker van te zijn dat ze allemaal met dezelfde baseline begonnen, dat DMV's opnieuw zouden worden ingesteld, enz.
Onbetwiste Bijlagen
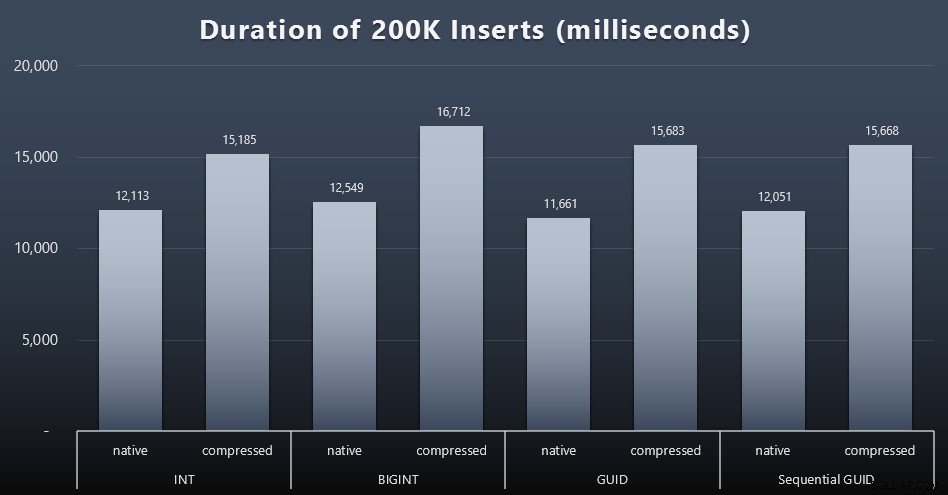
Mijn uiteindelijke doel was om de tabel te vullen met 1.000.000 rijen, maar eerst wilde ik de impact zien van het gegevenstype en de compressie op onbewerkte invoegingen zonder enige discussie. Ik genereerde de volgende query - die de tabel zou vullen met de eerste 200.000 contacten, 2000 rijen tegelijk - en voerde deze uit voor elke tabel:
DECLARE @i INT =1;WHILE @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) SELECT FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) RIJEN ALLEEN VOLGENDE 2000 RIJEN OPHALEN; SET @i +=1;ENDResultaten (klik om te vergroten):
Elk geval duurde ongeveer 12 seconden (zonder compressie) en 16 seconden (met compressie), zonder duidelijke winnaar in beide opslagmodi. Het effect van compressie (voornamelijk op CPU-overhead) is redelijk consistent, maar aangezien dit op een snelle SSD draait, is de I/O-impact van de verschillende datatypes verwaarloosbaar. In feite leek de compressie tegen BIGINT de grootste impact te hebben (en dit is logisch, aangezien elke afzonderlijke waarde van minder dan 2 miljard zou worden gecomprimeerd).
Meer controversiële werklast
Vervolgens wilde ik zien hoe een gemengde werklast zou strijden om bronnen en in het algemeen zou presteren tegen elk gegevenstype. Dus ik heb deze procedures gemaakt (ter vervanging van
$use_case$en$data_type$geschikt voor elke test):-- willekeurige singleton-updates van gegevens in meer dan één indexCREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN STEL NOCOUNT IN; UPDATE dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- leest ("paginering") - ondersteunt meerdere sorteert-- gebruik dynamische SQL om querystatistieken afzonderlijk bij te houdenCREATE PROCEDURE [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN STEL NOCOUNT IN; VERKLAREN @sql NVARCHAR(MAX) =N'SELECT Klant-ID, Voornaam, Achternaam, E-mail, Actief, Gemaakt, Bijgewerkt VANAF dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) RIJEN FETCH VOLGENDE @ps ALLEEN RIJEN;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOVervolgens heb ik banen gecreëerd die die procedures herhaaldelijk zouden oproepen, met kleine vertragingen, en tegelijkertijd ook de resterende 800.000 contacten zouden vullen. Dit script maakt alle 32 taken aan en drukt ook uitvoer af die later kan worden gebruikt om alle taken voor een specifieke test asynchroon aan te roepen:
GEBRUIK msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(name SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES( N'Random update workload', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN SELECTEER TOP (1) @CustomerID =CustomerID VAN dbo.Customers_$use_case$ BESTEL DOOR NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; WACHTVOORVERTRAGING ''00:00 :01''; SET @i +=1; END'),( N'Populate customers', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Voornaam, Achternaam, E-mail, Actief) SELECTEER Voornaam, Achternaam, E-mail, Actief VAN dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) RIJEN ALLEEN VOLGENDE 2000 RIJEN OPHALEN; WACHTVERTRAGING ''00:00:01''; SET @i +=1; END'),( N'Paging-werklast 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sorteer op Klant-ID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WACHTVERTRAGING ''00:00:01''; SET @i +=2; END'),( N'Paging-werkbelasting 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sorteer op achternaam, voornaam SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''Achternaam, Voornaam'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i WACHTVERTRAGING ''00:00:01''; SET @i +=2; END'); VERKLAREN @n SYSNAME, @c NVARCHAR(MAX); DECLARE c CURSOR LOKAAL FAST_FORWARD FORSELECT naam =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) VAN @typ AS t CROSS JOIN @jobs AS j; OPENEN c; FETCH c IN @n, @c; TERWIJL @@FETCH_STATUS <> -1BEGIN INDIEN BESTAAT (SELECTEER 1 UIT msdb.dbo.sysjobs WAAR naam =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(lokaal)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c INTO @n, @c;ENDHet meten van de taaktijden was in elk geval triviaal - ik kon de start- en einddatums controleren in
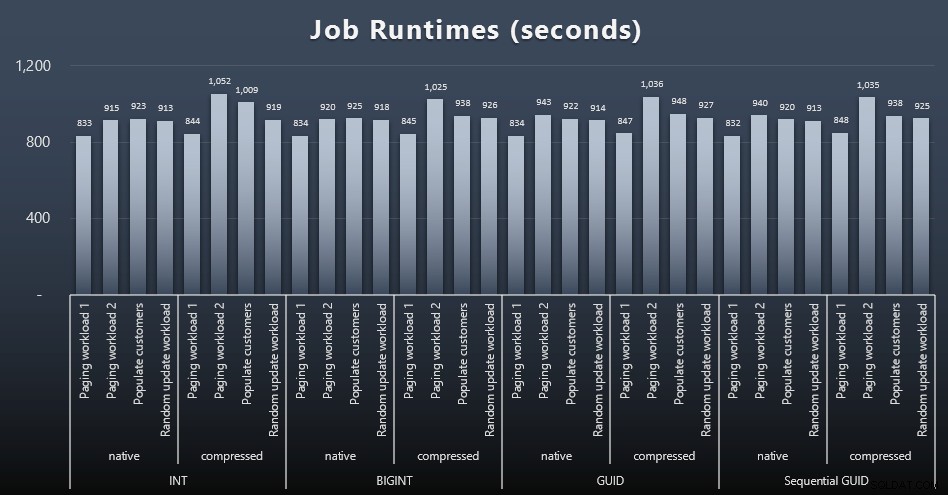
msdb.dbo.sysjobhistoryof haal ze uit SQL Sentry Event Manager. Hier zijn de resultaten (klik om te vergroten):
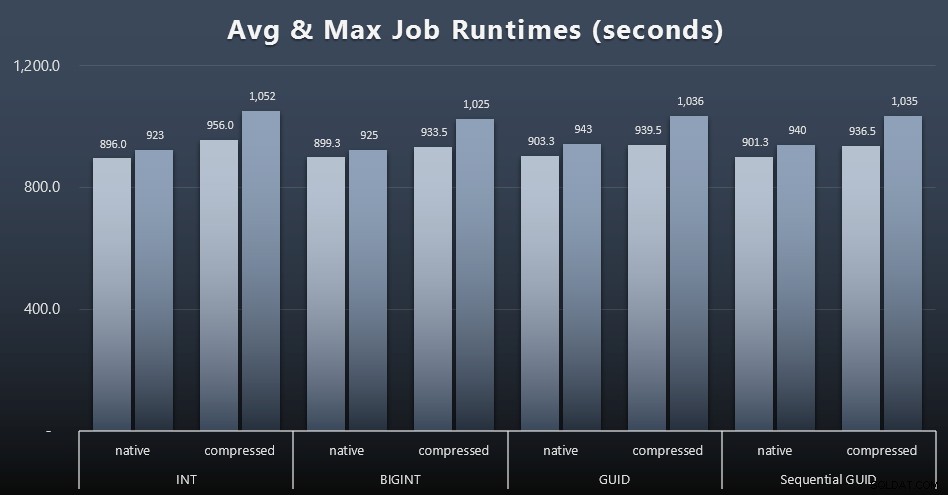
En als je wat minder te verteren wilt hebben, kijk dan eens naar de gemiddelde en maximale looptijden voor de vier jobs (klik om te vergroten):
Maar zelfs in deze tweede grafiek is er niet echt genoeg variantie om een overtuigend argument voor of tegen een van de benaderingen te maken.
Runtimes voor zoekopdrachten
Ik heb een aantal statistieken overgenomen van
sys.dm_exec_query_statsensys.dm_exec_trigger_statsom te bepalen hoe lang individuele zoekopdrachten gemiddeld duurden.
Bevolking
De eerste 200.000 klanten werden vrij snel geladen - minder dan 20 seconden - omdat er geen concurrerende werkbelastingen waren. Toen de vier taken tegelijkertijd werden uitgevoerd, was er echter een aanzienlijke impact op de schrijfduur vanwege gelijktijdigheid. De overige 800.000 rijen hadden gemiddeld minstens een orde van grootte meer tijd nodig om te voltooien. Hier zijn de resultaten van het gemiddelde van elke 2.000 klantenbijlage (klik om te vergroten):
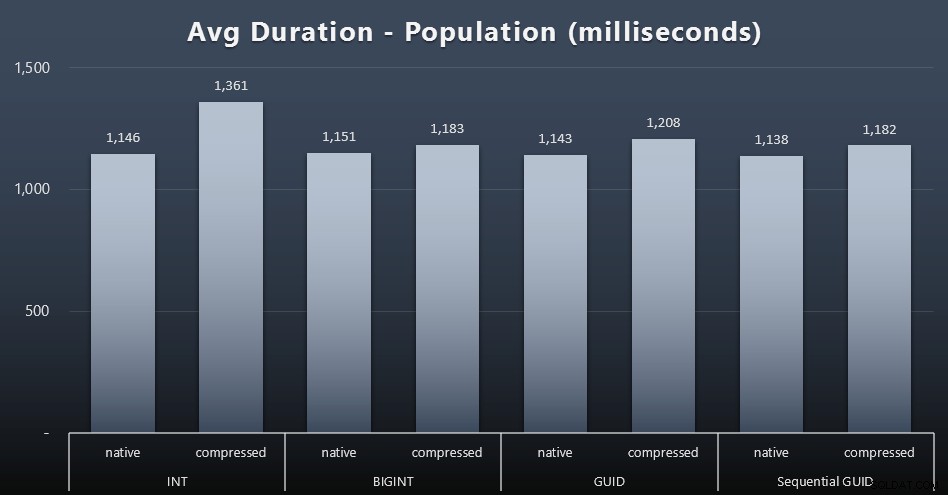
We zien hier dat het comprimeren van een INT de enige echte uitbijter was - ik heb daar enkele theorieën over, maar nog niets overtuigend.
Paging-workloads
De gemiddelde looptijden van de paging-query's lijken ook aanzienlijk te zijn beïnvloed door gelijktijdigheid in vergelijking met mijn geïsoleerde testruns. Hier zijn de resultaten (klik om te vergroten):
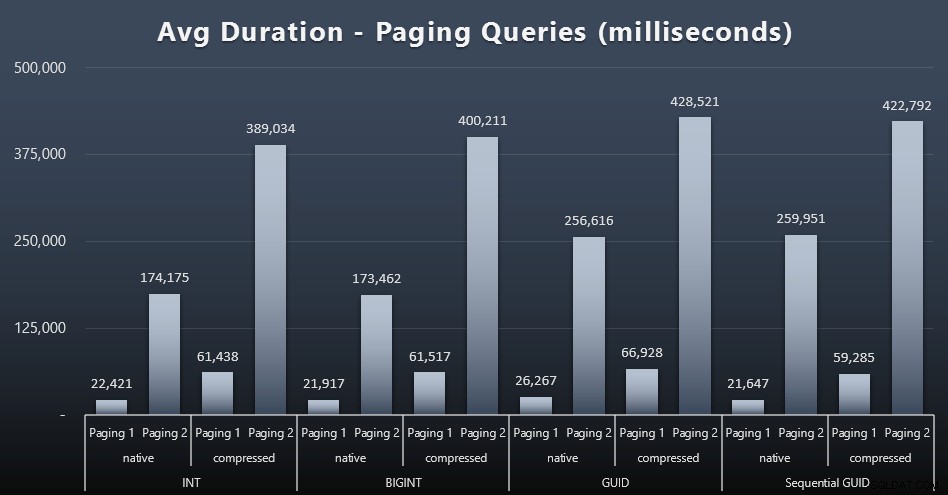
(Pagina 1 =bestellen op klant-ID, oproepen 2 =bestellen op achternaam, voornaam.)
We zien dat er voor zowel Paging 1 (volgorde op klant-ID) als Paging 2 (volgorde op naam) een significante impact is op de runtime door compressie (tot ~700%). Beide GUID's lijken de langzaamste paarden in deze race te zijn, waarbij NEWID() het slechtst presteert.
Werkbelasting bijwerken
De singleton-updates waren behoorlijk snel, zelfs onder zware gelijktijdigheid, maar er waren nog steeds enkele merkbare verschillen als gevolg van compressie, en zelfs enkele verrassende verschillen tussen gegevenstypen (klik om te vergroten):
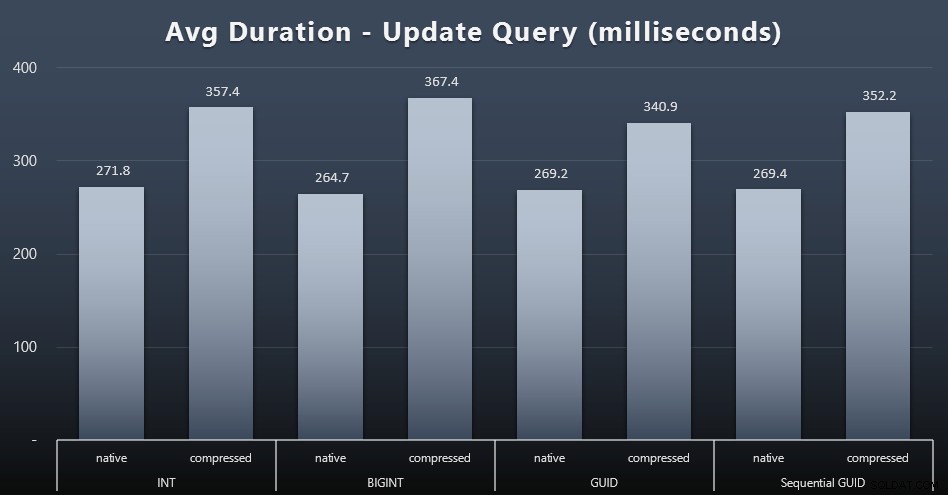
Het meest opvallende was dat de updates van de rijen met GUID-waarden eigenlijk sneller . waren dan de updates die INT/BIGINT bevatten, toen compressie in gebruik was. Met native storage waren de verschillen minder opvallend (maar INT was daar nog steeds een verliezer).
Triggerstatistieken
Hier zijn de gemiddelde en maximale looptijden voor de eenvoudige trigger in elk geval (klik om te vergroten):
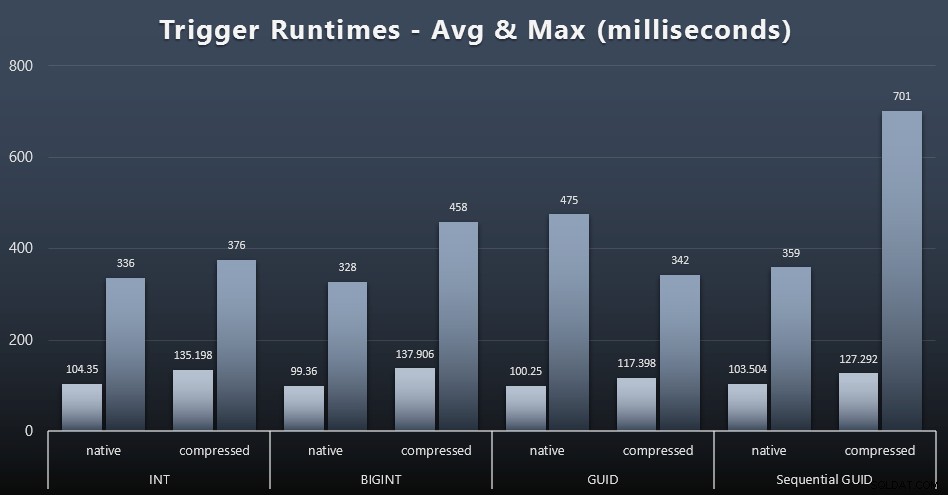
Compressie lijkt hier een veel grotere impact te hebben dan de keuze van het gegevenstype (hoewel dit waarschijnlijk meer uitgesproken zou zijn als een deel van mijn update-workload veel rijen had bijgewerkt in plaats van alleen uit één rij te bestaan). Het maximum voor sequentiële GUID is duidelijk een uitschieter van een soort die ik niet heb onderzocht (je kunt zien dat het onbeduidend is op basis van het gemiddelde dat nog steeds in lijn is over de hele linie).
Waar wachtten deze vragen op?
Na elke werkbelasting keek ik ook naar de hoogste wachttijden op het systeem, waarbij ik de voor de hand liggende wachtrijen/timerwachten (zoals beschreven door Paul Randal) en irrelevante activiteit van monitoringsoftware (zoals TRACEWRITE) weggooide. ). Dit waren de top 3 wachttijden in elk geval (klik om te vergroten):
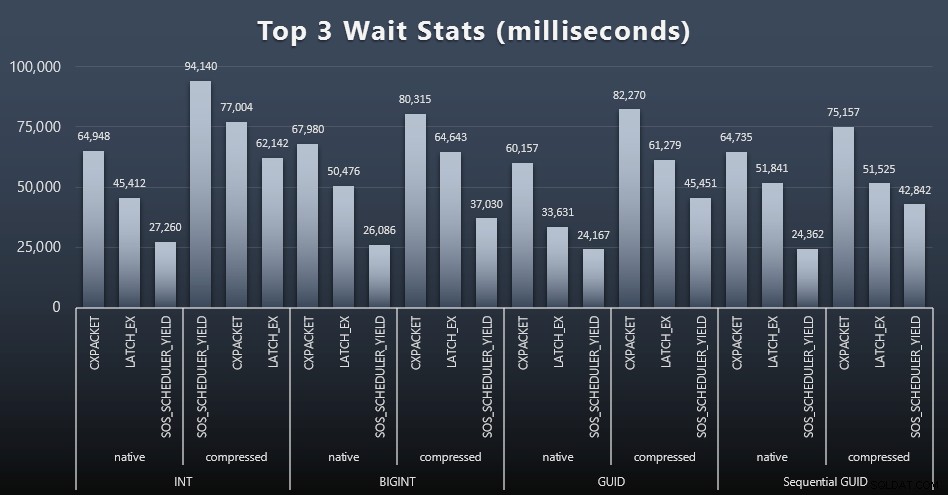
In de meeste gevallen waren de wachttijden CXPACKET, vervolgens LATCH_EX en vervolgens SOS_SCHEDULER_YIELD. In het geval van gebruik van gehele getallen en compressie nam SOS_SCHEDULER_YIELD het echter over, wat voor mij enige inefficiëntie in het algoritme voor het comprimeren van gehele getallen impliceert (wat misschien helemaal niet gerelateerd is aan het algoritme dat wordt gebruikt om BIGINT's in INT's te persen). Ik heb dit niet verder onderzocht en ook geen rechtvaardiging gevonden voor het bijhouden van wachttijden per individuele zoekopdracht.
Schijfruimte / fragmentatie
Hoewel ik het ermee eens ben dat het niet om de schijfruimte gaat, is het toch een statistiek die het waard is om te presenteren. Zelfs in dit zeer simplistische geval waarin er slechts één tabel is en de sleutel niet aanwezig is in alle andere gerelateerde tabellen (wat zeker zou bestaan in een echte toepassing), is het verschil significant. Laten we eerst eens kijken naar de reserved kolom van sp_spaceused (klik om te vergroten):
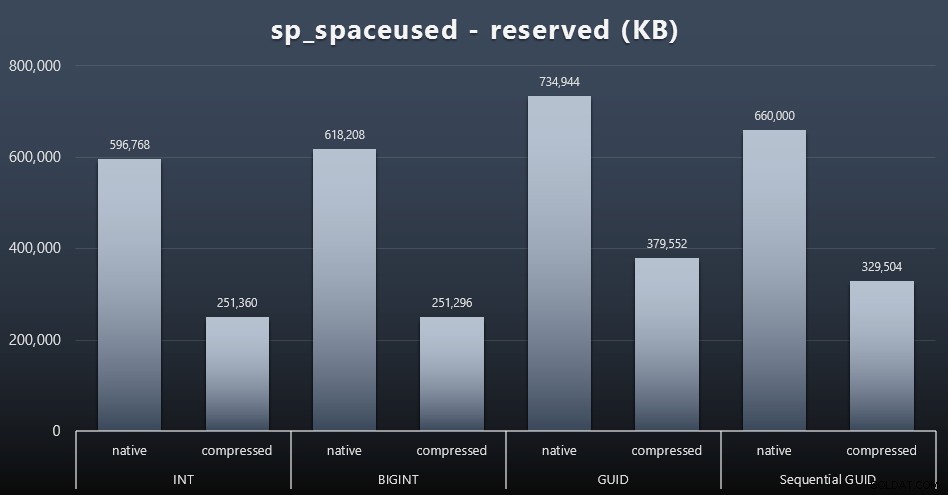
Hier nam BIGINT slechts iets meer ruimte in beslag dan INT, en GUID (zoals verwacht) had een grotere sprong. Sequentiële GUID had een minder significante toename van de gebruikte ruimte en was ook veel beter gecomprimeerd dan traditionele GUID. Nogmaals, geen verrassingen hier - een GUID is groter dan een getal, punt. Voorstanders van GUID zouden kunnen beweren dat de prijs die u betaalt in termen van schijfruimte niet zo veel is (18% meer dan BIGINT zonder compressie, ongeveer 50% met compressie). Maar onthoud dat dit een enkele tabel is van 1 miljoen rijen. Stel je voor hoe dat extrapoleert als je 10 miljoen klanten hebt en velen van hen hebben 10, 30 of 500 bestellingen - die toetsen kunnen worden herhaald in een dozijn andere tabellen en dezelfde extra ruimte innemen in elke rij.
Toen ik keek naar fragmentatie na elke werkbelasting (onthoud dat er geen indexonderhoud wordt uitgevoerd) met deze query:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); De resultaten zorgden voor veel minder interessante beelden; alle niet-geclusterde indexen waren meer dan 99% gefragmenteerd. De geclusterde indexen waren echter ofwel zeer sterk gefragmenteerd of helemaal niet gefragmenteerd (klik om te vergroten):
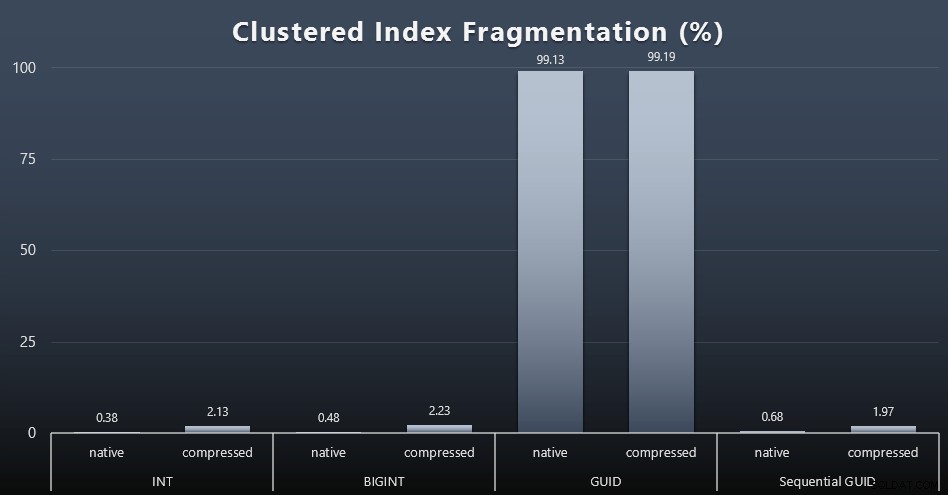
Fragmentatie is een andere maatstaf die vaak veel minder betekent als we het over SSD's hebben, maar het is toch belangrijk om op te merken, aangezien niet alle systemen het zich kunnen veroorloven zich niet bewust te zijn van de impact die fragmentatie kan hebben op I/O-patronen. Ik geloof dat het gebruik van niet-sequentiële GUID's op een meer I/O-gebonden systeem de impact van deze fragmentatie alleen al drastisch zou worden vergroot op de meeste andere meetwaarden in deze test.
Gebruik bufferpool
Dit is waar het zijn vruchten afwerpt om de hoeveelheid schijfruimte die door uw tafels wordt gebruikt, te beoordelen - hoe groter uw tafels zijn, hoe meer ruimte ze innemen in de bufferpool. Het verplaatsen van gegevens in en uit de bufferpool is duur, en nogmaals, dit is een zeer simplistisch geval waarbij de tests afzonderlijk werden uitgevoerd en er geen andere toepassingen en databases op de instantie waren die streden om kostbaar geheugen.
Dit is een eenvoudige meting van de volgende vraag aan het einde van elke werkbelasting:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool';
Resultaten (klik om te vergroten):
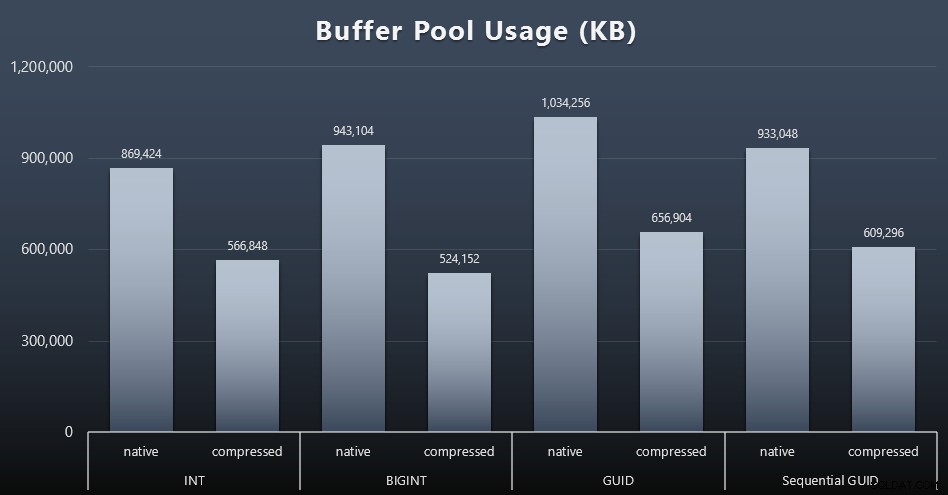
Hoewel het grootste deel van deze grafiek helemaal niet verrassend is - GUID neemt meer ruimte in beslag dan BIGINT, BIGINT meer dan INT - vond ik het interessant dat een sequentiële GUID minder ruimte in beslag nam dan een BIGINT, zelfs zonder compressie. Ik heb een aantekening gemaakt om wat forensisch onderzoek op paginaniveau uit te voeren om te bepalen wat voor soort efficiëntie hier onder de dekens plaatsvindt.
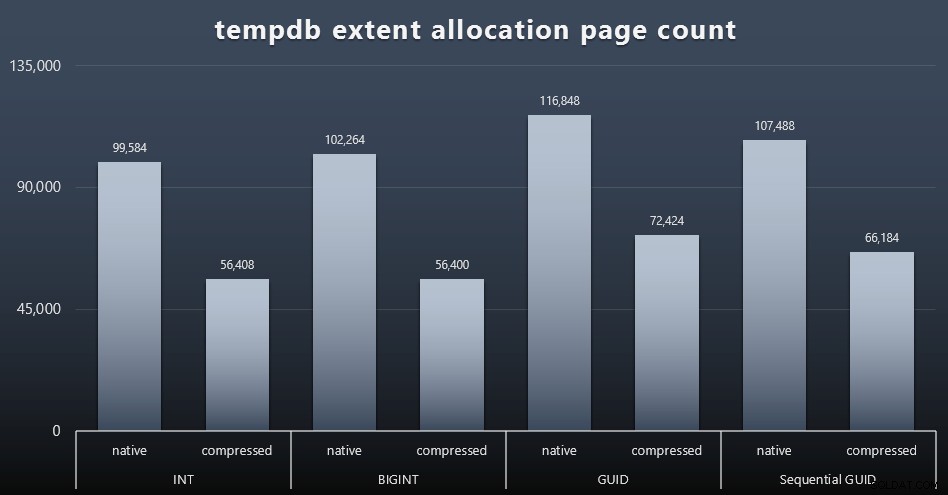
tempdb-gebruik
Ik weet niet zeker wat ik hier verwachtte, maar na elke werkbelasting verzamelde ik de inhoud van de drie tempdb-gerelateerde ruimtegebruik-DMV's, sys.dm_db_file|session|task_space_usage . De enige die enige volatiliteit leek te vertonen op basis van het gegevenstype was sys.dm_db_file_space_usage 's extent_allocation_page_count . Dit toont aan dat - althans in mijn configuratie en deze specifieke werklast - GUID's tempdb een iets grondiger training zullen geven (klik om te vergroten):
'Slechte' paginasplitsingen
Een van de dingen die ik wilde meten, was de impact op pagina-splitsingen - niet normale pagina-splitsingen (wanneer je een nieuwe pagina toevoegt), maar wanneer je daadwerkelijk gegevens tussen pagina's moet verplaatsen om ruimte te maken voor meer rijen. Jonathan Kehayias gaat hier dieper op in in zijn blogpost, "Tracking Problematic Pages Splits in SQL Server 2012 Extended Events - No Really This Time!", dat ook de basis vormt voor de Extended Events-sessie die ik gebruikte om de gegevens vast te leggen:
GEBEURTENISSESSIE MAKEN [BadPageSplits] OP SERVER GEBEURTENIS TOEVOEGEN sqlserver.transaction_log (WHERE operatie =11 EN database_id =10) VOEG TARGET pakket0.histogram toe ( SET filtering_event_name ='sqlserver.transaction_log', source_typeloc =0_unit source ='al );GOALTER EVENT SESSIE [BadPageSplits] OP SERVER STATE =START;GO
En de query die ik heb gebruikt om het te plotten:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM (SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='s. ='histogram' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER WORD LID VAN sys.tables AS t ON p.object_id =t.[object_id]GROEP OP t.name; En hier zijn de resultaten (klik om te vergroten):
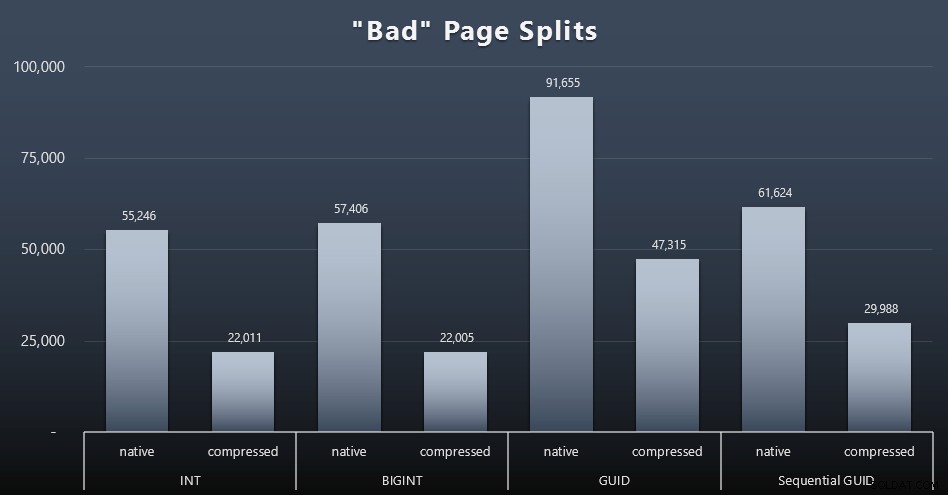
Hoewel ik al heb opgemerkt dat in mijn scenario (waar ik op snelle SSD's werk) het onbetwistbare verschil in I/O-activiteit niet direct van invloed is op de algehele runtime, is dit nog steeds een statistiek die u in overweging wilt nemen, vooral als u geen SSD's hebt of als uw werklast al I/O-gebonden is.
Conclusie
Hoewel deze tests mijn ogen een beetje breder hebben geopend over hoe langlopende percepties die ik heb gehad, zijn veranderd door modernere hardware, ben ik nog steeds vrij stellig tegen het verspillen van ruimte op schijf of in het geheugen. Hoewel ik probeerde wat evenwicht aan te tonen en GUID's te laten schitteren, is er hier vanuit prestatieperspectief heel weinig om het overschakelen van INT/BIGINT naar een van beide vormen van UNIQUEIDENTIFIER te ondersteunen - tenzij je het om andere, minder tastbare redenen nodig hebt (zoals het maken van de sleutel in de toepassing of het behouden van unieke sleutelwaarden in verschillende systemen). Een korte samenvatting, waaruit blijkt dat NEWID() de slechtste keuze is voor veel van de statistieken waar er een substantieel verschil was (en in de meeste van die gevallen was NEWSEQUENTIALID() een goede tweede)):
| Metriek | Verliezer(s) wissen? |
|---|---|
| Onbetwiste bijlagen | – gelijkspel – |
| Gelijktijdige werklast | – gelijkspel – |
| Individuele zoekopdrachten – Bevolking | INT (gecomprimeerd) |
| Individuele zoekopdrachten – Paging | NEWID() / NEWSEQUENTIALID() |
| Individuele vragen – Update | INT (native) / BIGINT (gecomprimeerd) |
| Individuele zoekopdrachten – NA trigger | – gelijkspel – |
| Schijfruimte | NIEUWID() |
| Geclusterde indexfragmentatie | NIEUWID() |
| Gebruik bufferpool | NIEUWID() |
| tempdb-gebruik | NIEUWID() |
| 'Slechte' paginasplitsingen | NIEUWID() |
Tabel 2:Grootste verliezers
Test deze dingen gerust zelf uit; Ik kan mijn volledige set scripts samenstellen als u ze in uw eigen omgeving wilt uitvoeren. Het beknopte doel van dit hele bericht is vrij eenvoudig:er zijn veel belangrijke statistieken waarmee rekening moet worden gehouden, afgezien van de voorspelbare impact op de schijfruimte, dus het mag niet alleen als argument in beide richtingen worden gebruikt.
Ik wil niet dat deze manier van denken per se beperkt blijft tot sleutels. Er moet echt over worden nagedacht wanneer er een keuze voor een gegevenstype wordt gemaakt. Ik zie datetime vaak gekozen worden, bijvoorbeeld wanneer alleen een date of smalldatetime is nodig. Op transactietabellen kan dit ook leiden tot veel verspilde schijfruimte, en dit sijpelt ook door naar sommige van deze andere bronnen.
In een toekomstige test wil ik de resultaten vergelijken voor een veel grotere tabel (> 2 miljard rijen). Ik kan dit met INT simuleren door het identiteitszaad in te stellen op -2 miljard, waardoor ~4 miljard rijen mogelijk zijn. En ik zou graag zien dat de vergelijkingen van werkbelasting en schijfruimte/geheugen meer dan een enkele tabel omvatten, aangezien een van de voordelen van een skinny key is dat die sleutel wordt weergegeven in tientallen gerelateerde tabellen. Ik hield toezicht op autogrow-gebeurtenissen, maar die waren er niet, omdat de database groot genoeg was om de groei op te vangen, en ik dacht er niet aan om het werkelijke loggebruik in het bestaande logbestand te meten, dus ik zou graag willen testen opnieuw met de standaardwaarden voor loggrootte en autogrowth, en deze keer meten DBCC SQLPERF(LOGSPACE); . Het zou ook interessant zijn om het opnieuw opbouwen te timen en het loggebruik als resultaat van die operaties ook te meten. Ten slotte zou ik I/O een relevantere factor willen maken door een server met mechanische harde schijven te zoeken - ik weet dat er genoeg zijn, maar in sommige winkels zijn ze vrij schaars.