Paginering is overal in client- en webapplicaties een veelvoorkomend gebruik. Google toont u 10 resultaten tegelijk, uw online bank kan 20 rekeningen per pagina tonen en software voor het opsporen van fouten en broncontrole kan 50 items op het scherm weergeven.
Ik wilde kijken naar de algemene pagineringbenadering op SQL Server 2012 - OFFSET / FETCH (een standaardequivalent van MySQL's prioprietary LIMIT-clausule) - en een variatie voorstellen die zal leiden tot meer lineaire pagingprestaties over de hele set, in plaats van alleen optimaal te zijn in het begin. Wat helaas het enige is dat veel winkels zullen testen.
Wat is paginering in SQL Server?
Op basis van de indexering van de tabel, de benodigde kolommen en de gekozen sorteermethode, kan paginering relatief pijnloos zijn. Als u op zoek bent naar de "eerste" 20 klanten en de geclusterde index ondersteunt die sortering (bijvoorbeeld een geclusterde index op een IDENTITY-kolom of DateCreated-kolom), dan zal de zoekopdracht relatief efficiënt zijn. Als u sortering moet ondersteunen waarvoor niet-geclusterde indexen vereist zijn, en vooral als u kolommen hebt die nodig zijn voor uitvoer die niet door de index worden gedekt (laat staan als er geen ondersteunende index is), kunnen de query's duurder worden. En zelfs dezelfde zoekopdracht (met een andere @PageNumber-parameter) kan veel duurder worden naarmate het @PageNumber hoger wordt - omdat er mogelijk meer leesbewerkingen nodig zijn om bij dat "deel" van de gegevens te komen.
Sommigen zullen zeggen dat vooruitgang naar het einde van de set iets is dat je kunt oplossen door meer geheugen op het probleem te gooien (zodat je fysieke I/O elimineert) en/of caching op applicatieniveau te gebruiken (je gaat dus niet de database helemaal niet). Laten we voor de doeleinden van dit bericht aannemen dat meer geheugen niet altijd mogelijk is, aangezien niet elke klant RAM kan toevoegen aan een server die geen geheugenslots meer heeft of niet onder controle is, of gewoon met zijn vingers knippen en nieuwere, grotere servers klaar hebben staan gaan. Vooral omdat sommige klanten de Standard Edition gebruiken, dus beperkt zijn tot 64 GB (SQL Server 2012) of 128 GB (SQL Server 2014), of zelfs nog beperktere edities gebruiken, zoals Express (1 GB) of een van de vele cloudaanbiedingen.
Dus ik wilde kijken naar de algemene paging-aanpak op SQL Server 2012 - OFFSET / FETCH - en een variatie voorstellen die zal leiden tot meer lineaire paging-prestaties over de hele set, in plaats van alleen in het begin optimaal te zijn. Wat helaas het enige is dat veel winkels zullen testen.
Paginatiegegevens instellen / voorbeeld
Ik ga lenen uit een ander bericht, Slechte gewoonten:alleen focussen op schijfruimte bij het kiezen van sleutels, waarbij ik de volgende tabel vulde met 1.000.000 rijen met willekeurige (maar niet helemaal realistische) klantgegevens:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Omdat ik wist dat ik hier I/O zou testen, en zowel vanuit een warme als een koude cache zou testen, heb ik de test op zijn minst een beetje eerlijker gemaakt door alle indexen opnieuw op te bouwen om fragmentatie te minimaliseren (zoals zou worden gedaan met minder storend, maar regelmatig, op de meest drukke systemen die elk type indexonderhoud uitvoeren):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Na het opnieuw opbouwen is de fragmentatie nu 0,05% – 0,17% voor alle indexen (indexniveau =0), pagina's zijn meer dan 99% gevuld en het aantal rijen / pagina's voor de indexen is als volgt:
| Index | Paginatelling | Aantal rijen |
|---|---|---|
| C_PK_Customers_I (geclusterde index) | 19.210 | 1.000.000 |
| C_Email_Customers_I | 7.344 | 1.000.000 |
| C_Active_Customers_I (gefilterde index) | 13.648 | 815.235 |
| C_Name_Customers_I | 16.824 | 1.000.000 |
Indexen, paginatellingen, rijtellingen
Dit is duidelijk geen superbrede tabel en ik heb compressie deze keer buiten beeld gelaten. Misschien zal ik in een toekomstige test meer configuraties onderzoeken.
Een SQL-query effectief pagineren
Het concept van paginering - waarbij de gebruiker alleen rijen tegelijk laat zien - is gemakkelijker te visualiseren dan uit te leggen. Denk aan de index van een fysiek boek, die meerdere pagina's met verwijzingen naar punten in het boek kan hebben, maar alfabetisch is geordend. Laten we voor de eenvoud zeggen dat er tien items op elke pagina van de index passen. Dit kan er als volgt uitzien:
Nu, als ik pagina's 1 en 2 van de index al heb gelezen, weet ik dat om naar pagina 3 te gaan, ik 2 pagina's moet overslaan. Maar aangezien ik weet dat er op elke pagina 10 items staan, kan ik dit ook zien als 2 x 10 items overslaan en beginnen bij het 21e item. Of, om het anders te zeggen, ik moet de eerste (10*(3-1)) items overslaan. Om dit algemener te maken, kan ik zeggen dat ik, om op pagina n te beginnen, de eerste (10 * (n-1)) items moet overslaan. Om naar de eerste pagina te gaan, sla ik 10*(1-1) items over, om te eindigen op item 1. Om naar de tweede pagina te gaan, sla ik 10*(2-1) items over, om te eindigen op item 11. En zo aan.
Met die informatie zullen gebruikers een paging-query als deze formuleren, aangezien de OFFSET / FETCH-clausules die zijn toegevoegd in SQL Server 2012 specifiek zijn ontworpen om zoveel rijen over te slaan:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Zoals ik hierboven al zei, werkt dit prima als er een index is die de ORDER BY ondersteunt en die alle kolommen in de SELECT-clausule dekt (en, voor complexere zoekopdrachten, de WHERE- en JOIN-clausules). De sorteerkosten kunnen echter overweldigend zijn zonder ondersteunende index, en als de uitvoerkolommen niet worden gedekt, krijgt u ofwel een hele reeks sleutelzoekopdrachten, of u krijgt in sommige scenario's zelfs een tabelscan.
Best practices voor het sorteren van SQL-paginering
Gezien de bovenstaande tabel en indexen, wilde ik deze scenario's testen, waarbij we 100 rijen per pagina willen weergeven en alle kolommen in de tabel willen uitvoeren:
- Standaard –
ORDER BY CustomerID(geclusterde index). Dit is de handigste volgorde voor de databasemensen, omdat er geen extra sortering nodig is en alle gegevens uit deze tabel die mogelijk nodig kunnen zijn voor weergave, zijn inbegrepen. Aan de andere kant is dit misschien niet de meest efficiënte index om te gebruiken als u een subset van de tabel weergeeft. De bestelling is misschien ook niet logisch voor eindgebruikers, vooral als CustomerID een surrogaat-ID is zonder externe betekenis. - Telefoonboek –
ORDER BY LastName, FirstName(ondersteunt niet-geclusterde index). Dit is de meest intuïtieve volgorde voor gebruikers, maar er is een niet-geclusterde index nodig om zowel sortering als dekking te ondersteunen. Zonder een ondersteunende index zou de hele tabel moeten worden gescand. - Door gebruiker gedefinieerd –
ORDER BY FirstName DESC, EMail(geen ondersteunende index). Dit vertegenwoordigt de mogelijkheid voor de gebruiker om elke gewenste sorteervolgorde te kiezen, een patroon waarvoor Michael J. Swart waarschuwt in "UI-ontwerppatronen die niet worden geschaald".
Ik wilde deze methoden testen en plannen en metrische gegevens vergelijken wanneer - zowel in warme cache- als koude cache-scenario's - ik keek naar pagina 1, pagina 500, pagina 5.000 en pagina 9.999. Ik heb deze procedures gemaakt (die alleen verschillen door de ORDER BY-clausule):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail In werkelijkheid heb je waarschijnlijk maar één procedure die ofwel dynamische SQL gebruikt (zoals in mijn voorbeeld 'aanrecht') of een CASE-expressie om de volgorde te dicteren.
In beide gevallen ziet u mogelijk de beste resultaten door OPTION (RECOMPILE) op de query te gebruiken om hergebruik te voorkomen van plannen die optimaal zijn voor één sorteeroptie, maar niet voor alle. Ik heb hier afzonderlijke procedures gemaakt om die variabelen weg te nemen; Ik heb OPTIE (RECOMPILE) toegevoegd voor deze tests om weg te blijven van parametersnuiven en andere optimalisatieproblemen zonder de hele plancache herhaaldelijk te wissen.
Een alternatieve benadering van SQL Server-paginering voor betere prestaties
Een iets andere benadering, die ik niet vaak zie geïmplementeerd, is om de "pagina" waar we ons op bevinden te lokaliseren met alleen de clustersleutel, en daar vervolgens aan mee te doen:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Het is natuurlijk meer uitgebreide code, maar hopelijk is het duidelijk waartoe SQL Server kan worden gedwongen:het vermijden van een scan, of op zijn minst het uitstellen van zoekopdrachten totdat een veel kleinere resultatenset is verminderd. Paul White (@SQL_Kiwi) onderzocht een soortgelijke aanpak in 2010, voordat OFFSET/FETCH werd geïntroduceerd in de vroege bèta's van SQL Server 2012 (ik blogde er later dat jaar voor het eerst over).
Gezien de bovenstaande scenario's heb ik nog drie procedures gemaakt, met het enige verschil tussen de kolom(men) gespecificeerd in de ORDER BY-clausules (we hebben er nu twee nodig, één voor de pagina zelf en één voor het bestellen van het resultaat):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Opmerking:dit werkt misschien niet zo goed als je primaire sleutel niet geclusterd is - een deel van de truc die dit beter laat werken, wanneer een ondersteunende index kan worden gebruikt, is dat de clustersleutel al in de index zit, dus een opzoeken wordt vaak vermeden.
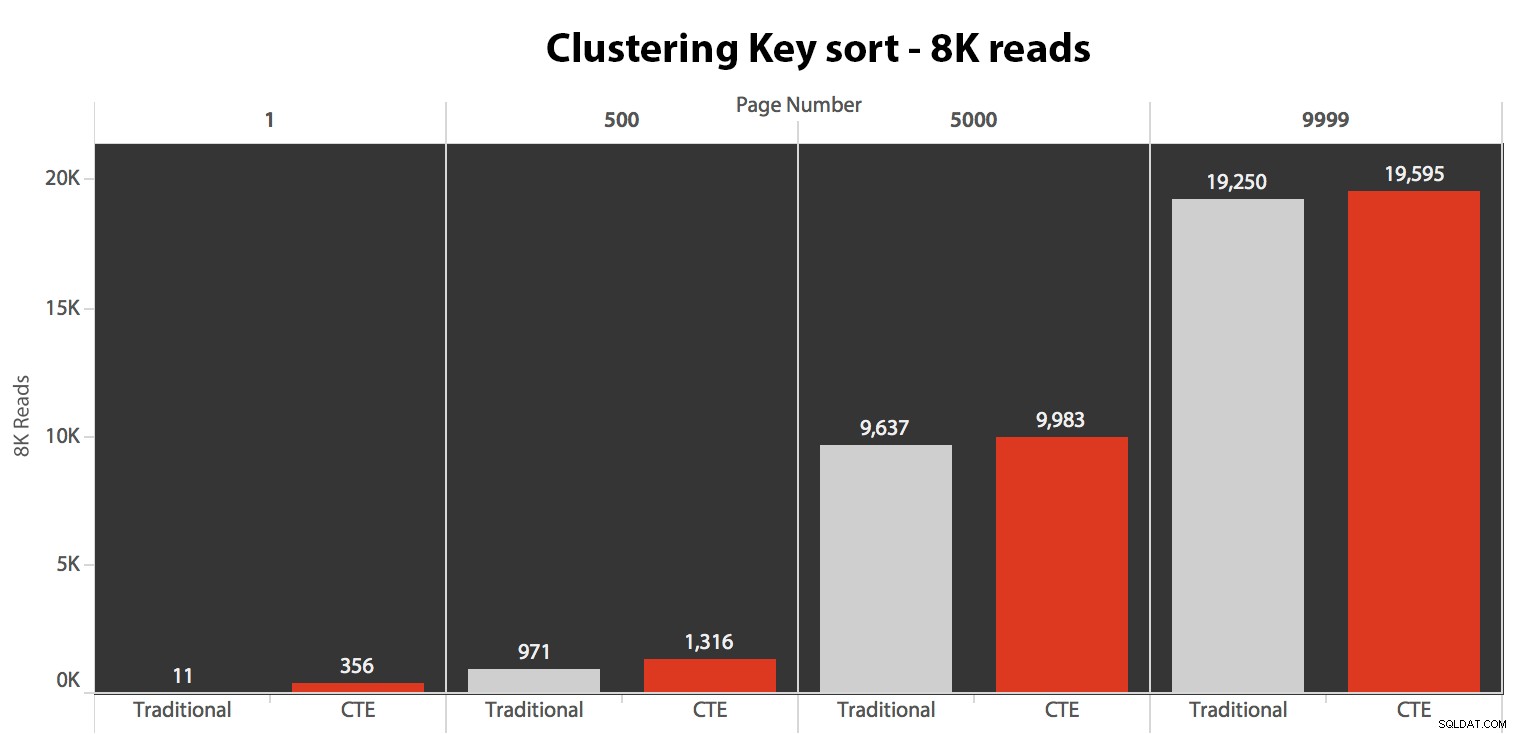
De sortering van clustersleutels testen
Eerst testte ik het geval waarin ik niet veel verschil verwachtte tussen de twee methoden - sorteren op de clustersleutel. Ik heb deze instructies in een batch uitgevoerd in SQL Sentry Plan Explorer en heb de duur, het lezen en de grafische plannen geobserveerd, om ervoor te zorgen dat elke query begon vanuit een volledig koude cache:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
De resultaten waren hier niet verbluffend. Meer dan 5 uitvoeringen wordt hier het gemiddelde aantal leesbewerkingen weergegeven, met verwaarloosbare verschillen tussen de twee zoekopdrachten, over alle paginanummers, bij het sorteren op de clustersleutel:
Het plan voor de standaardmethode (zoals weergegeven in Plan Explorer) was in alle gevallen als volgt:
Terwijl het plan voor de op CTE gebaseerde methode er als volgt uitzag:
Nu, terwijl I/O hetzelfde was, ongeacht caching (alleen veel meer read-ahead reads in het koude cache-scenario), heb ik de duur gemeten met een koude cache en ook met een warme cache (waar ik commentaar gaf op de DROPCLEANBUFFERS-commando's en voerde de query's meerdere keren uit voordat ze werden gemeten). Deze duur zag er als volgt uit:
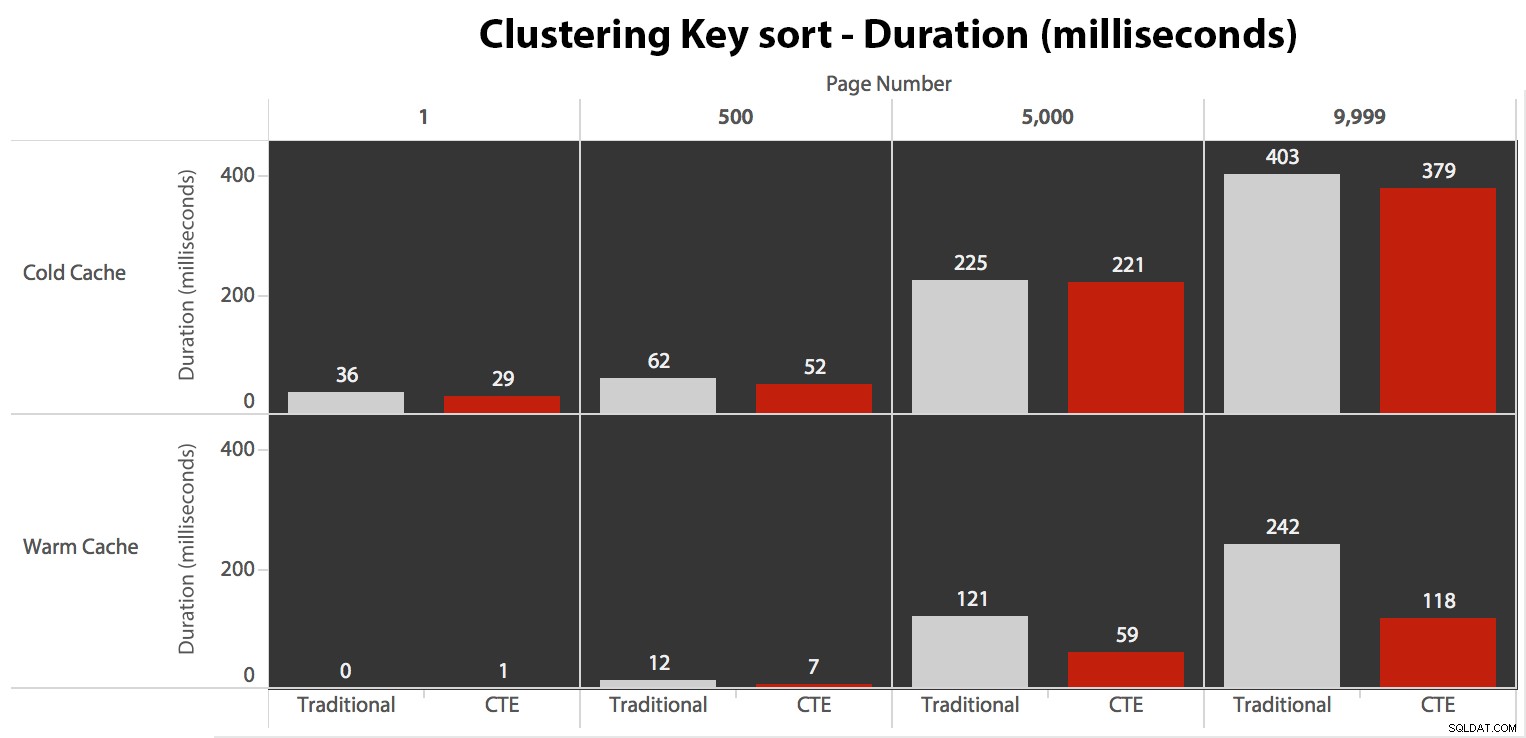
Hoewel je een patroon kunt zien dat de duur laat toenemen naarmate het paginanummer hoger wordt, moet je de schaal in gedachten houden:om de rijen 999.801 -> 999.900 te raken, hebben we het over een halve seconde in het slechtste geval en 118 milliseconden in het beste geval. De CTE-aanpak wint, maar niet veel.
De telefoonboeksortering testen
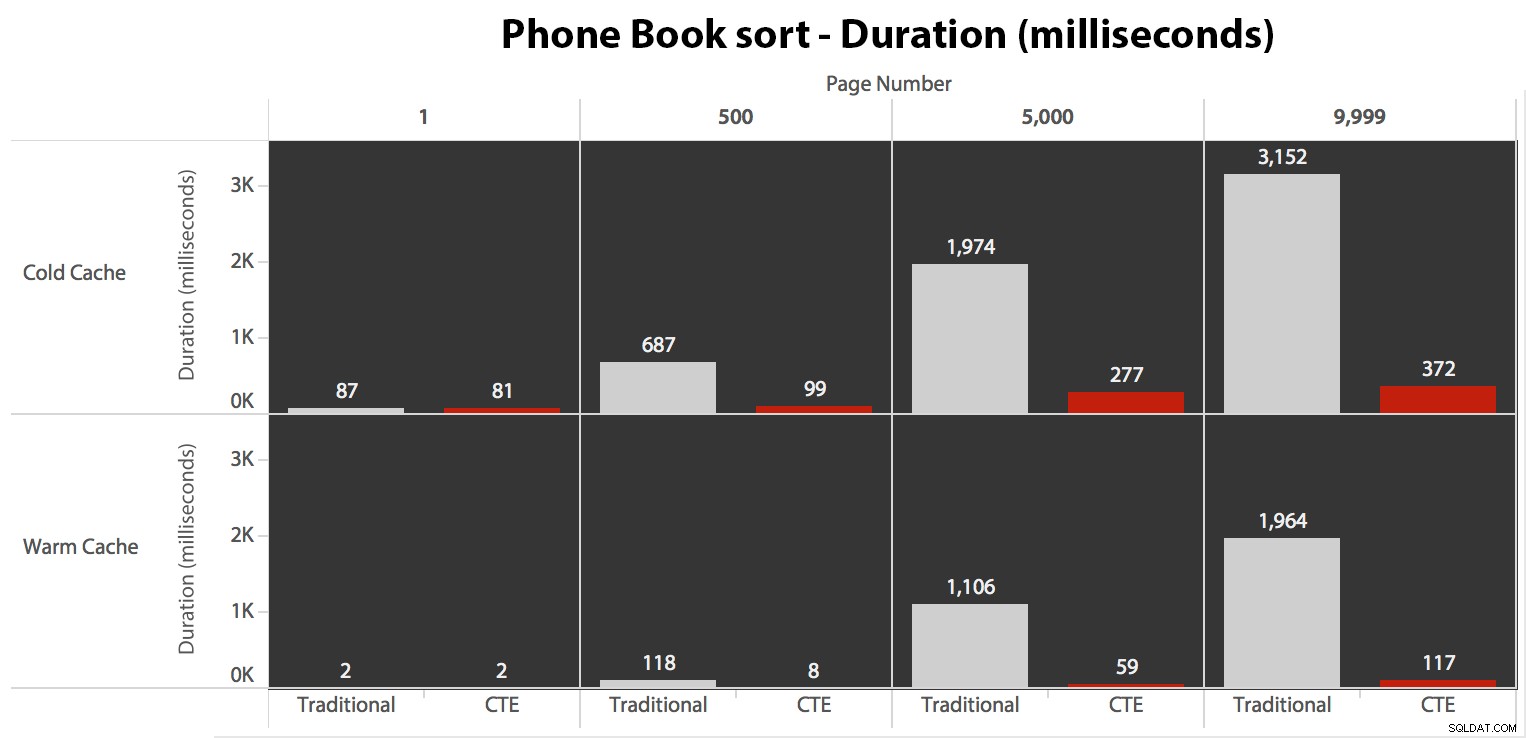
Vervolgens heb ik het tweede geval getest, waarbij de sortering werd ondersteund door een niet-bedekkende index op LastName, FirstName. De bovenstaande zoekopdracht heeft zojuist alle instanties van Test_1 . gewijzigd naar Test_2 . Dit waren de uitlezingen met behulp van een koude cache:
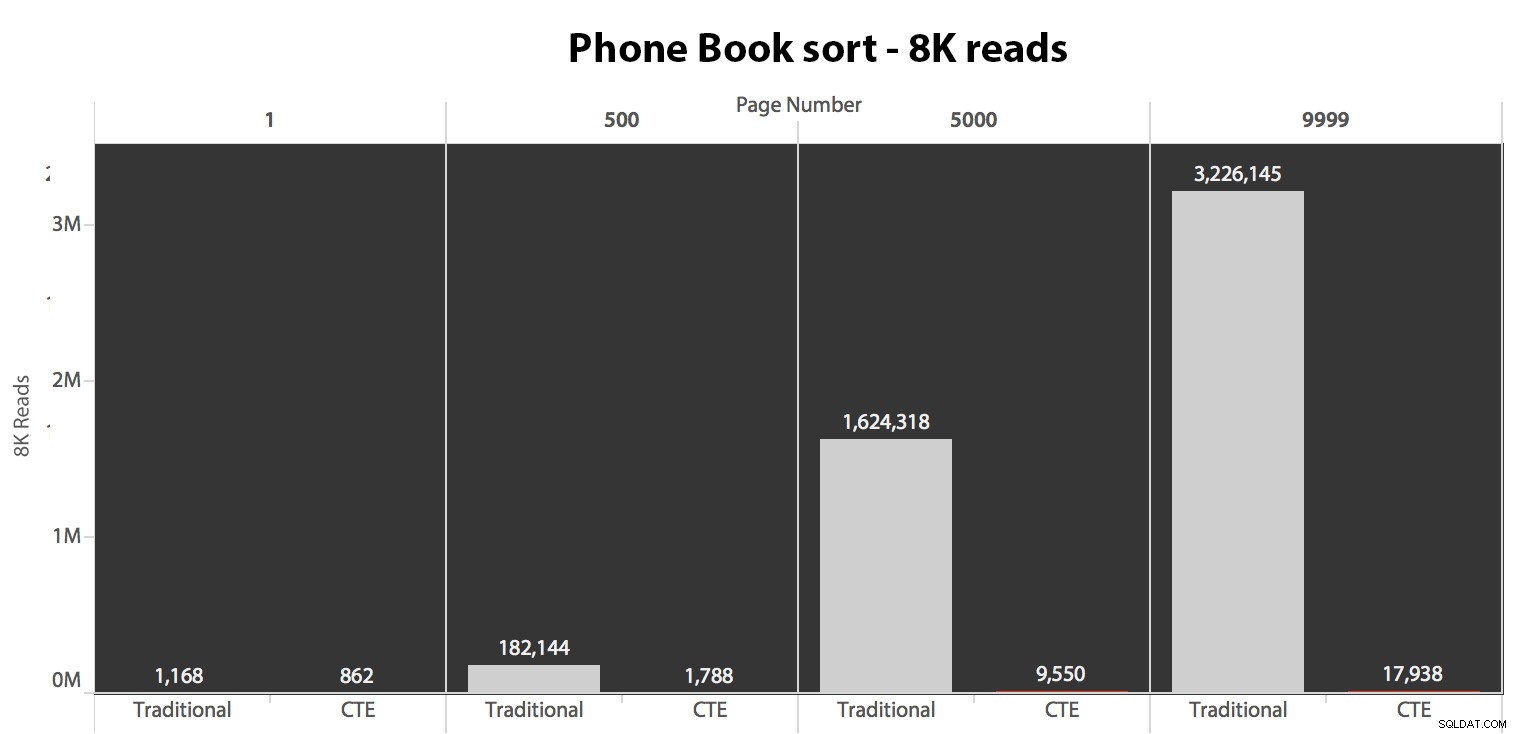
(De uitlezingen onder een warme cache volgden hetzelfde patroon - de werkelijke aantallen verschilden enigszins, maar niet genoeg om een aparte grafiek te rechtvaardigen.)
Als we de geclusterde index niet gebruiken om te sorteren, is het duidelijk dat de I/O-kosten die gepaard gaan met de traditionele methode van OFFSET/FETCH veel slechter zijn dan wanneer we eerst de sleutels in een CTE identificeren en de rest van de kolommen trekken alleen voor die subset.
Hier is het plan voor de traditionele zoekaanpak:
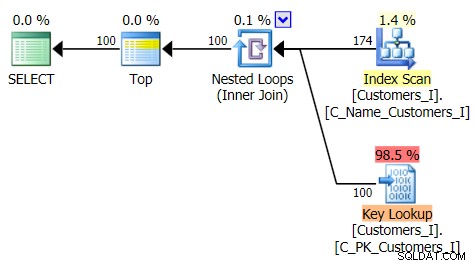
En het plan voor mijn alternatieve, CTE-aanpak:
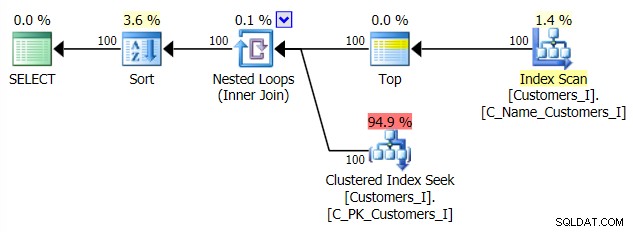
Tot slot de duur:
De traditionele benadering vertoont een zeer duidelijke stijging in duur als je naar het einde van de paginering marcheert. De CTE-benadering vertoont ook een niet-lineair patroon, maar het is veel minder uitgesproken en levert een betere timing op bij elk paginanummer. We zien 117 milliseconden voor de voorlaatste pagina, terwijl de traditionele benadering bijna twee seconden duurt.
De door de gebruiker gedefinieerde sortering testen
Ten slotte heb ik de query gewijzigd om de Test_3 . te gebruiken opgeslagen procedures, waarbij het geval werd getest waarin de sortering door de gebruiker was gedefinieerd en geen ondersteunende index had. De I/O was consistent in elke reeks tests; de grafiek is zo oninteressant, ik ga er gewoon naar linken. Om een lang verhaal kort te maken:er waren iets meer dan 19.000 reads in alle tests. De reden is dat elke afzonderlijke variant een volledige scan moest uitvoeren vanwege het ontbreken van een index om de bestelling te ondersteunen. Hier is het plan voor de traditionele aanpak:
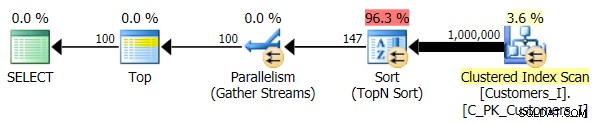
En hoewel het plan voor de CTE-versie van de query er alarmerend complexer uitziet...
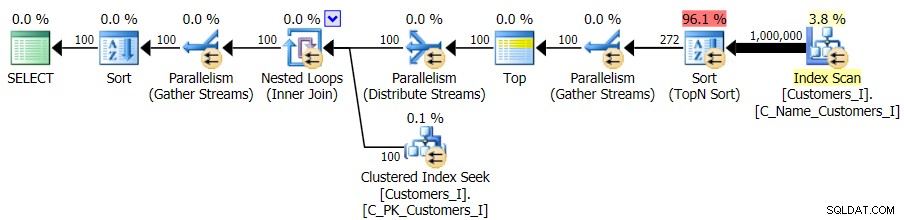
…het leidt in alle gevallen tot een kortere looptijd. Dit zijn de duur:
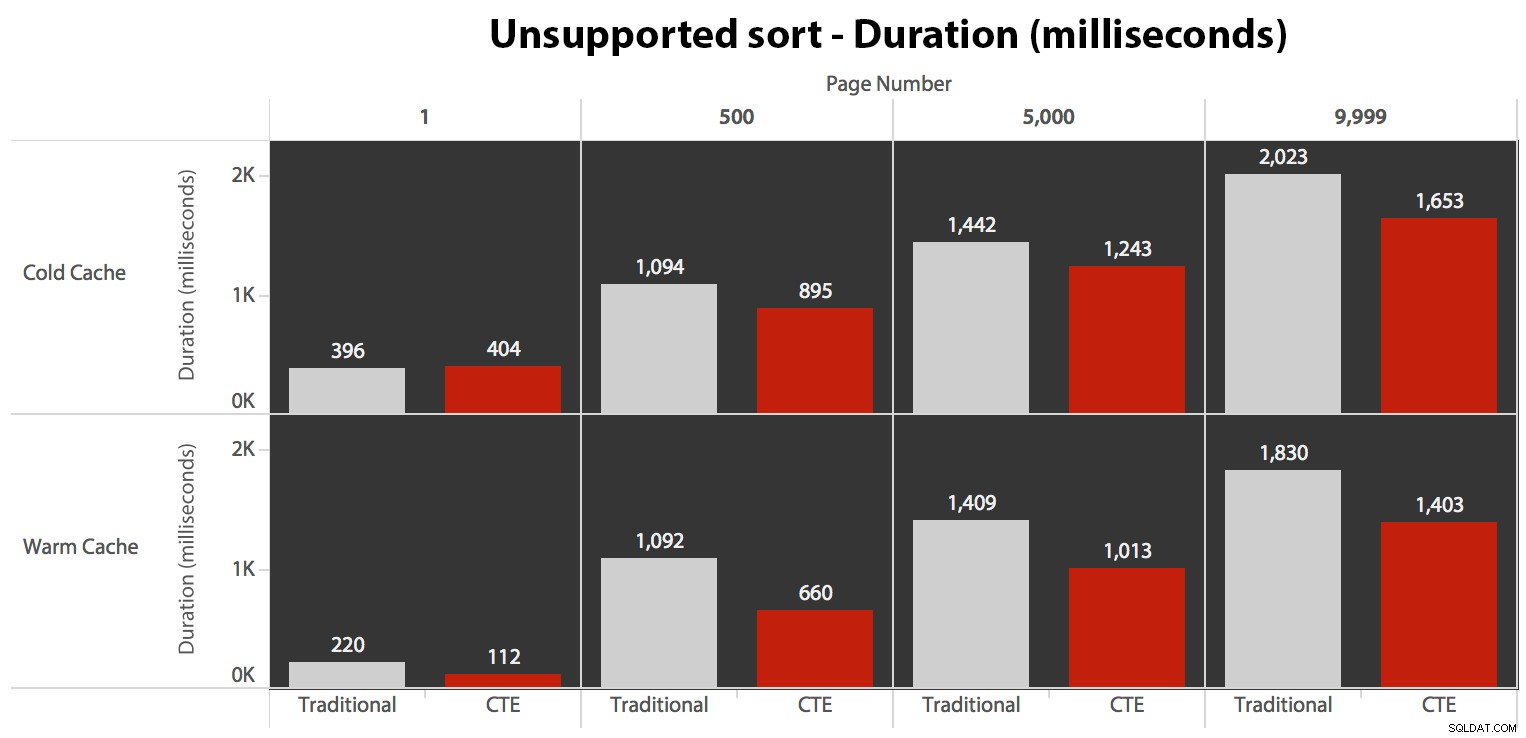
Je kunt zien dat we hier met geen van beide methoden lineaire prestaties kunnen krijgen, maar de CTE komt in elk geval met een goede marge (ergens van 16% tot 65% beter) als beste uit de bus, behalve de koude cache-query tegen de eerste pagina (waar het maar liefst 8 milliseconden verloren ging). Ook interessant om op te merken dat de traditionele methode niet veel geholpen wordt door een warme cache in het "midden" (pagina's 500 en 5000); pas tegen het einde van de set is enige efficiëntie het vermelden waard.
Hoger volume
Na het individueel testen van een paar uitvoeringen en het nemen van gemiddelden, dacht ik dat het ook zinvol zou zijn om een groot aantal transacties te testen die het echte verkeer op een druk systeem enigszins zouden simuleren. Dus ik heb een taak gemaakt met 6 stappen, één voor elke combinatie van querymethode (traditionele paging versus CTE) en sorteertype (clustersleutel, telefoonboek en niet-ondersteund), met een reeks van 100 stappen van het raken van de vier paginanummers hierboven , 10 keer elk en 60 andere willekeurig gekozen paginanummers (maar hetzelfde voor elke stap). Hier is hoe ik het script voor het maken van banen heb gegenereerd:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Hier is de resulterende lijst met taakstappen en een van de eigenschappen van de stap:
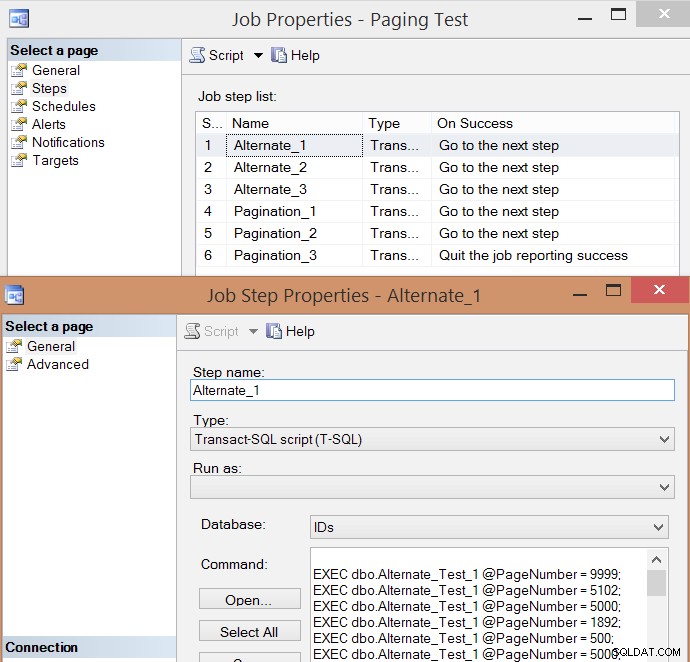
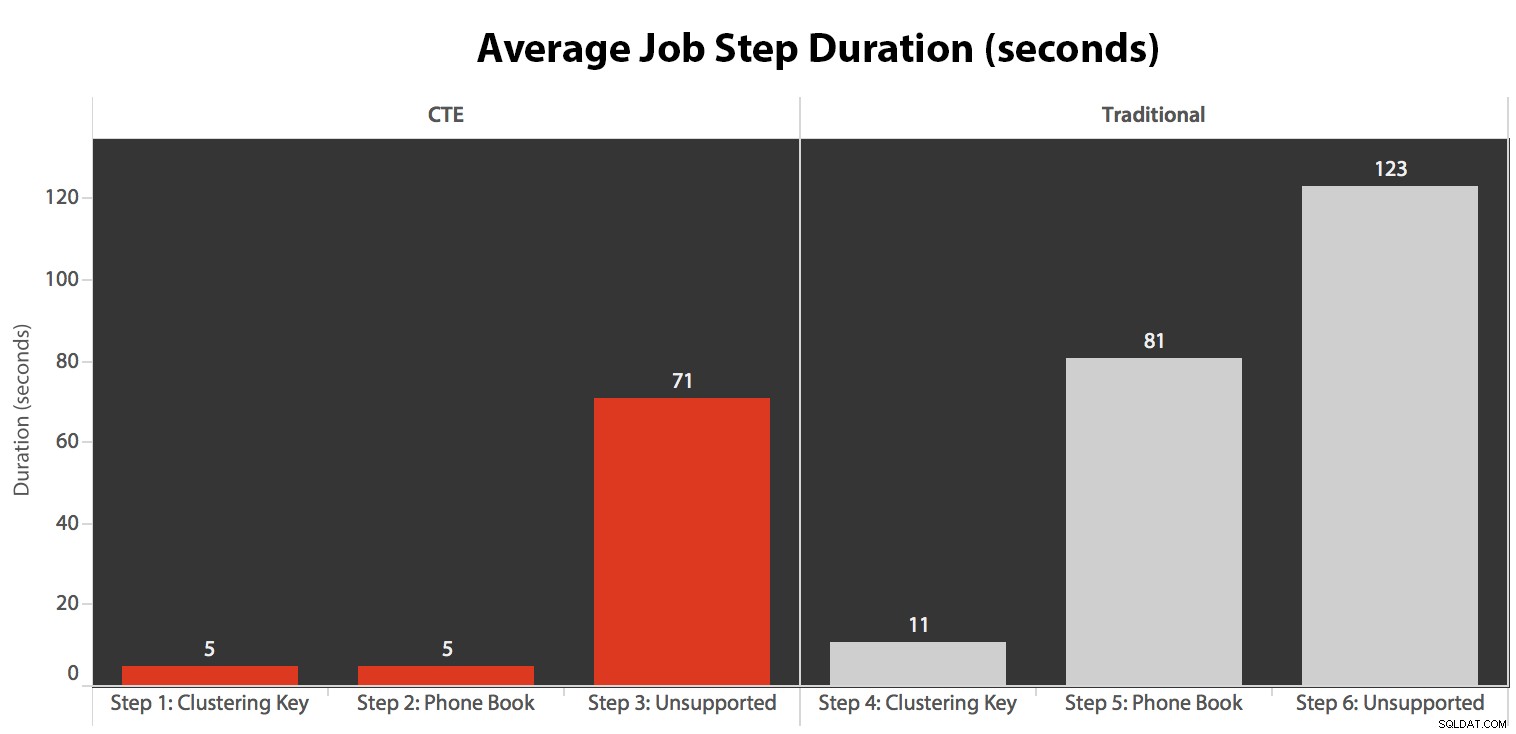
Ik heb de taak vijf keer uitgevoerd, daarna de taakgeschiedenis bekeken en dit waren de gemiddelde looptijden van elke stap:
Ik heb ook een van de uitvoeringen op de SQL Sentry Event Manager-kalender gecorreleerd...
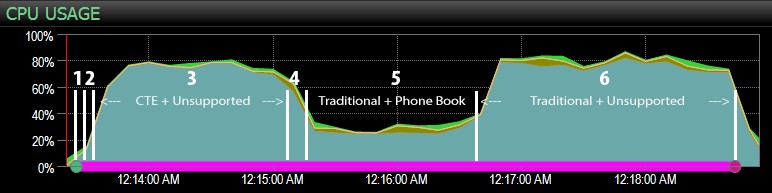
... met het SQL Sentry-dashboard en handmatig grofweg gemarkeerd waar elk van de zes stappen liep. Hier is de grafiek van het CPU-gebruik vanaf de Windows-kant van het dashboard:
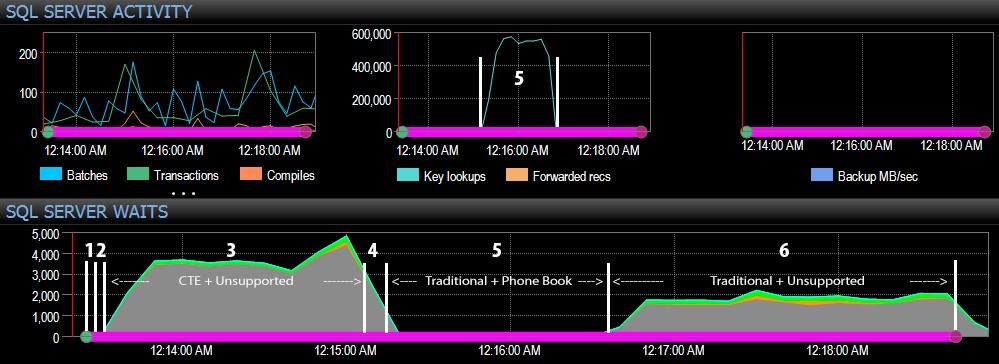
En vanaf de SQL Server-kant van het dashboard waren de interessante statistieken in de grafieken Key Lookups en Waits:
De meest interessante observaties alleen vanuit een puur visueel perspectief:
- CPU is behoorlijk heet, rond de 80%, tijdens stap 3 (CTE + geen ondersteunende index) en stap 6 (traditioneel + geen ondersteunende index);
- De CXPACKET-wachttijden zijn relatief hoog tijdens stap 3 en in mindere mate tijdens stap 6;
- je kunt de enorme sprong in het aantal zoekopdrachten zien, tot bijna 600.000, in een tijdsbestek van ongeveer één minuut (correlerend met stap 5 – de traditionele benadering met een index in telefoonboekstijl).
In een toekomstige test - zoals bij mijn vorige post over GUID's - zou ik dit willen testen op een systeem waar de gegevens niet in het geheugen passen (gemakkelijk te simuleren) en waar de schijven traag zijn (niet zo gemakkelijk te simuleren) , aangezien sommige van deze resultaten waarschijnlijk profiteren van dingen die niet elk productiesysteem heeft:snelle schijven en voldoende RAM. Ik zou de tests ook moeten uitbreiden om meer variaties op te nemen (met dunne en brede kolommen, dunne en brede indexen, een telefoonboekindex die eigenlijk alle uitvoerkolommen dekt, en sorteren in beide richtingen). Scope creep beperkte zeker de omvang van mijn testen voor deze eerste reeks tests.
Hoe de paginering van SQL Server te verbeteren
Paginering hoeft niet altijd pijnlijk te zijn; SQL Server 2012 maakt de syntaxis zeker eenvoudiger, maar als u gewoon de native syntaxis aansluit, ziet u misschien niet altijd een groot voordeel. Hier heb ik aangetoond dat een iets uitgebreidere syntaxis met behulp van een CTE in het beste geval tot veel betere prestaties kan leiden, en in het slechtste geval tot verwaarloosbare prestatieverschillen. Door de gegevenslocatie en het ophalen van gegevens in twee verschillende stappen te scheiden, kunnen we in sommige scenario's een enorm voordeel zien, buiten hogere CXPACKET-wachttijden in één geval (en zelfs dan waren de parallelle query's sneller klaar dan de andere query's die weinig of geen wachttijden vertoonden, dus het was onwaarschijnlijk dat ze de "slechte" CXPACKET waren waar iedereen je voor waarschuwt).
Toch is zelfs de snellere methode traag als er geen ondersteunende index is. Hoewel u misschien in de verleiding komt om een index te implementeren voor elk mogelijk sorteeralgoritme dat een gebruiker zou kunnen kiezen, kunt u overwegen om minder opties aan te bieden (aangezien we allemaal weten dat indexen niet gratis zijn). Moet uw toepassing bijvoorbeeld absoluut sorteren op Achternaam oplopend *en* Achternaam aflopend ondersteunen? Als ze rechtstreeks naar de klanten willen gaan waarvan de achternaam met Z begint, kunnen ze dan niet naar de *laatste* pagina gaan en achteruit werken? Dat is meer een zakelijke en bruikbaarheidsbeslissing dan een technische. Houd het gewoon als een optie voordat u indexen op elke sorteerkolom in beide richtingen slaat om de beste prestaties te krijgen voor zelfs de meest obscure sorteeropties.