In mijn laatste bericht heb ik een aantal efficiënte benaderingen van gegroepeerde aaneenschakeling laten zien. Deze keer wilde ik het hebben over een paar extra facetten van dit probleem die we gemakkelijk kunnen bereiken met de FOR XML PATH aanpak:de lijst ordenen en duplicaten verwijderen.
Er zijn een paar manieren waarop ik heb gezien dat mensen de door komma's gescheiden lijst willen bestellen. Soms willen ze dat het item in de lijst alfabetisch wordt gerangschikt; Dat liet ik al zien in mijn vorige post. Maar soms willen ze dat het wordt gesorteerd op een ander kenmerk dat eigenlijk niet in de uitvoer wordt geïntroduceerd; bijvoorbeeld, misschien wil ik de lijst eerst op meest recente item sorteren. Laten we een eenvoudig voorbeeld nemen, waar we een Employees-tabel en een CoffeeOrders-tabel hebben. Laten we de bestellingen van één persoon voor een paar dagen invullen:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Als we de bestaande aanpak gebruiken zonder een ORDER BY . op te geven , krijgen we een willekeurige volgorde (in dit geval is het zeer waarschijnlijk dat u de rijen ziet in de volgorde waarin ze zijn ingevoegd, maar vertrouw daar niet op met grotere datasets, meer indexen, enz.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultaten (onthoud dat u *andere* resultaten kunt krijgen, tenzij u een ORDER BY opgeeft ):
Jack | Groot dubbel dubbel, Medium dubbel dubbel, Large Vanilla Latte, Medium dubbel dubbel
Als we de lijst alfabetisch willen ordenen, is dat eenvoudig; we voegen gewoon ORDER BY c.OrderDetails . toe :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultaten:
Naam | BestellingenJack | Groot dubbel dubbel, Large Vanilla Latte, Medium dubbel dubbel, Medium dubbel dubbel
We kunnen ook sorteren op een kolom die niet in de resultatenset voorkomt; we kunnen bijvoorbeeld de meest recente koffiebestelling eerst bestellen:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultaten:
Naam | BestellingenJack | Medium dubbel dubbel, Large Vanilla Latte, Medium dubbel dubbel, Groot dubbel dubbel
Een ander ding dat we vaak willen doen, is het verwijderen van duplicaten; er is immers weinig reden om "Medium double double" twee keer te zien. We kunnen dat elimineren door GROUP BY te gebruiken :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Nu gebeurt dit *toevallig* om de uitvoer alfabetisch te ordenen, maar nogmaals, u kunt hier niet op vertrouwen:
Naam | BestellingenJack | Groot dubbel dubbel, Large Vanilla Latte, Medium dubbel dubbel
Als je die bestelling op deze manier wilt garanderen, kun je gewoon opnieuw een ORDER BY toevoegen:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
De resultaten zijn hetzelfde (maar ik herhaal, dit is in dit geval gewoon toeval; als je deze volgorde wilt, zeg dat dan altijd):
Naam | BestellingenJack | Groot dubbel dubbel, Large Vanilla Latte, Medium dubbel dubbel
Maar wat als we duplicaten willen elimineren * en * de lijst eerst op de meest recente koffiebestelling willen sorteren? Uw eerste neiging zou kunnen zijn om de GROUP BY . te behouden en verander gewoon de ORDER BY , zoals dit:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Dat zal niet werken, aangezien de OrderDate is niet gegroepeerd of geaggregeerd als onderdeel van de zoekopdracht:
Kolom "dbo.CoffeeOrders.OrderDate" is ongeldig in de ORDER BY-clausule omdat deze niet is opgenomen in een aggregatiefunctie of de GROUP BY-clausule.
Een tijdelijke oplossing, die de vraag weliswaar een beetje lelijker maakt, is om de bestellingen eerst apart te groeperen en dan alleen de rijen met de maximale datum voor die koffiebestelling per medewerker te nemen:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultaten:
Naam | BestellingenJack | Medium dubbel dubbel, Large Vanilla Latte, Large dubbel dubbel
Hiermee bereiken we onze beide doelen:we hebben duplicaten geëlimineerd en we hebben de lijst gerangschikt op iets dat niet echt in de lijst staat.
Prestaties
U vraagt zich misschien af hoe slecht deze methoden presteren ten opzichte van een robuustere dataset. Ik ga onze tabel vullen met 100.000 rijen, kijken hoe ze het doen zonder extra indexen en dan dezelfde zoekopdrachten opnieuw uitvoeren met een beetje indexafstemming om onze zoekopdrachten te ondersteunen. Dus eerst 100.000 rijen krijgen verspreid over 1.000 medewerkers:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Laten we nu elk van onze query's twee keer uitvoeren en kijken hoe de timing is bij de tweede poging (we zullen hier een sprong in het diepe wagen en aannemen dat we - in een ideale wereld - zullen werken met een geprepareerde cache ). Ik heb deze uitgevoerd in SQL Sentry Plan Explorer, omdat dit de gemakkelijkste manier is die ik ken om een aantal individuele vragen te vergelijken:
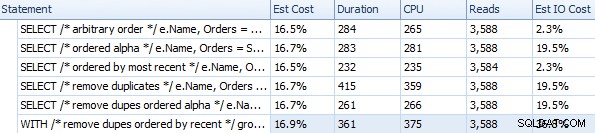 Duur en andere runtime-statistieken voor verschillende FOR XML PATH-benaderingen
Duur en andere runtime-statistieken voor verschillende FOR XML PATH-benaderingen
Deze timings (duur is in milliseconden) zijn echt niet zo slecht IMHO, als je bedenkt wat hier eigenlijk wordt gedaan. Het meest gecompliceerde plan, in ieder geval visueel, leek het plan te zijn waarbij we duplicaten verwijderden en sorteerden op meest recente volgorde:
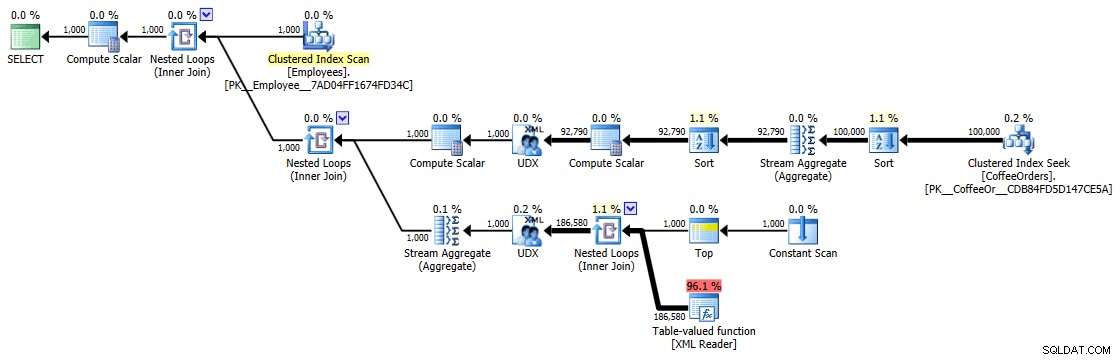 Uitvoeringsplan voor gegroepeerde en gesorteerde zoekopdracht
Uitvoeringsplan voor gegroepeerde en gesorteerde zoekopdracht
Maar zelfs de duurste operator hier - de XML-tabelwaardefunctie - lijkt allemaal CPU te zijn (hoewel ik vrijelijk zal toegeven dat ik niet zeker weet hoeveel van het daadwerkelijke werk wordt weergegeven in de details van het queryplan):
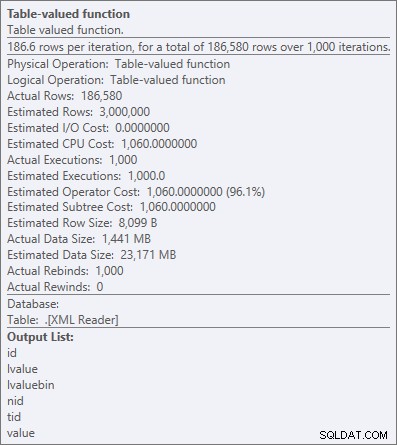 Operatoreigenschappen voor de XML-tabelwaardefunctie
Operatoreigenschappen voor de XML-tabelwaardefunctie
"Alle CPU's" is meestal oké, aangezien de meeste systemen I/O-gebonden en/of geheugengebonden zijn, niet CPU-gebonden. Zoals ik vaak zeg, in de meeste systemen ruil ik elke dag van de week een deel van mijn CPU-ruimte in voor geheugen of schijf (een van de redenen waarom ik OPTION (RECOMPILE) leuk vind als een oplossing voor alomtegenwoordige problemen met het snuiven van parameters).
Dat gezegd hebbende, raad ik je ten zeerste aan om deze benaderingen te testen tegen vergelijkbare resultaten die je kunt krijgen van de GROUP_CONCAT CLR-benadering op CodePlex, en om de aggregatie en sortering op de presentatielaag uit te voeren (vooral als je de genormaliseerde gegevens op een of andere manier bewaart van caching-laag).