Wanneer gebruikers gegevens van een systeem opvragen, zien ze deze meestal graag in een specifieke volgorde... zelfs als ze duizenden rijen retourneren. Zoals veel DBA's en ontwikkelaars weten, kan ORDER BY ravage aanrichten in een queryplan, omdat het vereist dat de gegevens worden gesorteerd. Dit kan soms een SORT-operator vereisen als onderdeel van het uitvoeren van query's, wat een kostbare operatie kan zijn, vooral als schattingen niet kloppen en het naar de schijf gaat. In een ideale wereld zijn de gegevens al gesorteerd dankzij een index (indexen en sorteringen zijn zeer complementair). We hebben het vaak over het maken van een dekkende index om aan een zoekopdracht te voldoen, zodat de optimizer niet terug hoeft te gaan naar de basistabel of geclusterde index om extra kolommen te krijgen. En je hebt misschien mensen horen zeggen dat de volgorde van de kolommen in de index er toe doet. Heeft u er ooit over nagedacht hoe dit uw SORT-bewerkingen beïnvloedt?
Order BY en sorteringen onderzoeken
We beginnen met een nieuwe kopie van de AdventureWorks2014-database op een SQL Server 2014-instantie (versie 12.0.2000). Als we een eenvoudige SELECT-query uitvoeren op Sales.SalesOrderHeader zonder ORDER BY, zien we een gewone oude Clustered Index Scan (met behulp van SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Query zonder ORDER BY, geclusterde indexscan
Query zonder ORDER BY, geclusterde indexscan
Laten we nu een ORDER BY toevoegen om te zien hoe het plan verandert:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
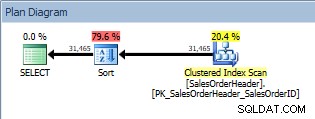 Query met een ORDER BY, geclusterde indexscan en een sortering
Query met een ORDER BY, geclusterde indexscan en een sortering
Naast de geclusterde indexscan hebben we nu een sortering geïntroduceerd door de optimizer, waarvan de geschatte kosten aanzienlijk hoger zijn dan die van de scan. Nu zijn de geschatte kosten slechts een schatting en we kunnen hier niet met absolute zekerheid zeggen dat de Sort 79,6% van de kosten van de zoekopdracht op zich nam. Om echt te begrijpen hoe duur de Sort is, zouden we ook naar IO STATISTICS moeten kijken, wat het doel van vandaag te boven gaat.
Als dit een query was die vaak in uw omgeving werd uitgevoerd, zou u waarschijnlijk overwegen een index toe te voegen om dit te ondersteunen. In dit geval is er geen WHERE-clausule, we halen gewoon vier kolommen op en bestellen op een van hen. Een logische eerste poging tot een index zou zijn:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
We zullen onze query opnieuw uitvoeren nadat we de index hebben toegevoegd die alle gewenste kolommen heeft, en onthoud dat de index het werk heeft gedaan om de gegevens te sorteren. We zien nu een Index Scan tegen onze nieuwe niet-geclusterde index:
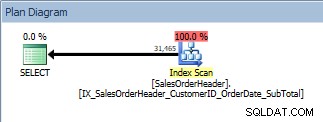 Query met een ORDER BY, de nieuwe, niet-geclusterde index wordt gescand
Query met een ORDER BY, de nieuwe, niet-geclusterde index wordt gescand
Dit is goed nieuws. Maar wat gebeurt er als iemand die zoekopdracht wijzigt - ofwel omdat gebruikers kunnen specificeren op welke kolommen ze willen bestellen, ofwel omdat er een wijziging is aangevraagd bij een ontwikkelaar? Misschien willen gebruikers bijvoorbeeld de klant-ID's en verkooporder-ID's in aflopende volgorde zien:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
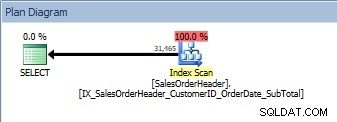 Query met twee kolommen in ORDER BY, de nieuwe, niet-geclusterde index wordt gescand
Query met twee kolommen in ORDER BY, de nieuwe, niet-geclusterde index wordt gescand
We hebben hetzelfde plan; er is geen sorteeroperator toegevoegd. Als we naar de index kijken met behulp van Kimberly Tripp's sp_helpindex (sommige kolommen zijn samengevouwen om ruimte te besparen), kunnen we zien waarom het plan niet is gewijzigd:
 Uitvoer van sp_helpindex
Uitvoer van sp_helpindex
De sleutelkolom voor de index is CustomerID, maar aangezien SalesOrderID de sleutelkolom is voor de geclusterde index, maakt deze ook deel uit van de indexsleutel, dus worden de gegevens gesorteerd op CustomerID en vervolgens op SalesOrderID. De query vroeg om de gegevens gesorteerd op die twee kolommen, in aflopende volgorde. De index is gemaakt met beide kolommen oplopend, maar omdat het een dubbel gekoppelde lijst is, kan de index achterstevoren worden gelezen. U kunt dit zien in het deelvenster Eigenschappen in Management Studio voor de operator voor niet-geclusterde indexscan:
 Eigenschappenvenster van de niet-geclusterde indexscan, waaruit blijkt dat het achterstevoren was
Eigenschappenvenster van de niet-geclusterde indexscan, waaruit blijkt dat het achterstevoren was
Geweldig, geen problemen met die zoekopdracht ... maar hoe zit het met deze:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
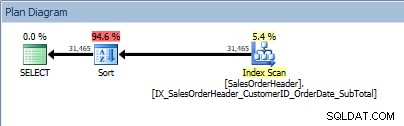 Query met twee kolommen in de ORDER BY, en een sortering is toegevoegd
Query met twee kolommen in de ORDER BY, en een sortering is toegevoegd
Onze SORT-operator verschijnt opnieuw, omdat de gegevens uit de index niet in de gevraagde volgorde zijn gesorteerd. We zullen hetzelfde gedrag zien als we sorteren op een van de opgenomen kolommen:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
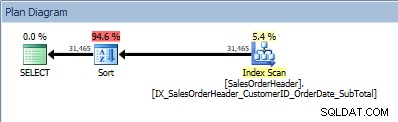 Query met twee kolommen in de ORDER BY, en een sortering is toegevoegd
Query met twee kolommen in de ORDER BY, en een sortering is toegevoegd
Wat gebeurt er als we (eindelijk) een predikaat toevoegen en onze ORDER BY iets wijzigen?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
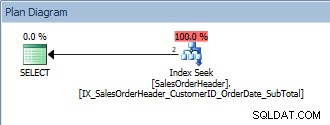 Query met een enkel predikaat en een ORDER BY
Query met een enkel predikaat en een ORDER BY
Deze query is ok, want nogmaals, de SalesOrderID maakt deel uit van de indexsleutel. Voor deze ene CustomerID zijn de gegevens al besteld door SalesOrderID. Wat als we zoeken naar een reeks klant-ID's, gesorteerd op SalesOrder-ID's?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
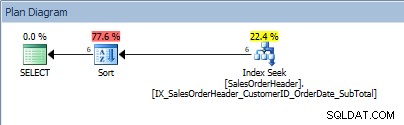 Query met een reeks waarden in het predikaat en een ORDER BY
Query met een reeks waarden in het predikaat en een ORDER BY
Ratten, onze SORT is terug. Het feit dat de gegevens zijn geordend op CustomerID helpt alleen bij het zoeken naar de index om dat bereik van waarden te vinden; voor de ORDER BY SalesOrderID moet de optimizer de Sort tussenvoegen om de gegevens in de gevraagde volgorde te plaatsen.
Nu vraag je je misschien af waarom ik gefixeerd ben op de sorteeroperator die in queryplannen voorkomt. Het is omdat het duur is. Het kan duur zijn in termen van middelen (geheugen, IO) en/of duur.
De duur van de query kan worden beïnvloed door een sortering, omdat het een stop-and-go-bewerking is. De hele set gegevens moet worden gesorteerd voordat de volgende bewerking in het plan kan plaatsvinden. Als er maar een paar rijen gegevens moeten worden besteld, is dat niet zo erg. Als het duizenden of miljoenen rijen zijn? Nu wachten we.
Naast de totale duur van de zoekopdracht, moeten we ook nadenken over het gebruik van bronnen. Laten we de 31.465 rijen nemen waarmee we hebben gewerkt en deze in een tabelvariabele plaatsen, en dan die eerste query uitvoeren met de ORDER BY op CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
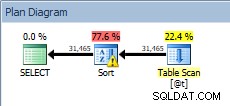 Query op de tabelvariabele, met de sortering
Query op de tabelvariabele, met de sortering
Onze SORT is terug, en deze keer heeft het een waarschuwing (let op de gele driehoek met het uitroepteken). Waarschuwingen zijn niet goed. Als we naar de eigenschappen van de soort kijken, kunnen we de waarschuwing zien:"Operator gebruikte tempdb om gegevens te morsen tijdens uitvoering met lekniveau 1":
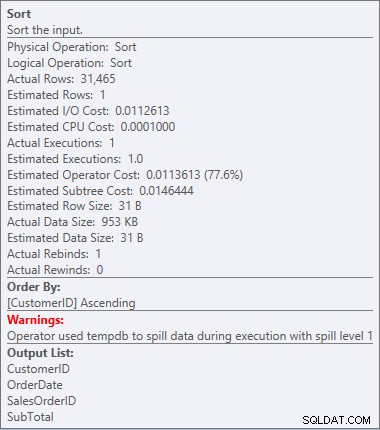 Sorteerwaarschuwing
Sorteerwaarschuwing
Dit is niet iets dat ik in een plan wil zien. De optimizer maakte een schatting van hoeveel geheugenruimte hij nodig zou hebben om de gegevens te sorteren, en vroeg om dat geheugen. Maar toen het eigenlijk alle gegevens had en het ging sorteren, realiseerde de engine zich dat er niet genoeg geheugen was (de optimizer vroeg te weinig!), dus de sorteerbewerking liep uit de hand. In sommige gevallen kan dit op de schijf terechtkomen, wat betekent dat lezen en schrijven traag is. We wachten niet alleen om de gegevens op orde te krijgen, het is zelfs nog langzamer omdat we het niet allemaal in het geheugen kunnen doen. Waarom vroeg de optimizer niet om voldoende geheugen? Het had een slechte schatting van de gegevens die nodig waren om te sorteren:
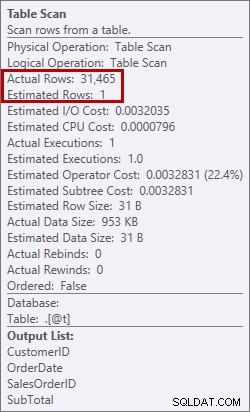 Geschatte van 1 rij versus werkelijke van 31.465 rijen
Geschatte van 1 rij versus werkelijke van 31.465 rijen
In dit geval heb ik een slechte schatting afgedwongen door een tabelvariabele te gebruiken. Er zijn bekende problemen met statistische schattingen en tabelvariabelen (Aaron Bertrand heeft een geweldige post over opties om dit aan te pakken), en hier geloofde de optimizer dat er maar 1 rij zou worden geretourneerd uit de tabelscan, niet 31.465.
Opties
Dus wat kunt u als DBA of ontwikkelaar doen om SORTINGEN in uw queryplannen te vermijden? Het snelle antwoord is:"Bestel uw gegevens niet." Maar dat is niet altijd realistisch. In sommige gevallen kunt u die sortering overdragen aan de client of aan een applicatielaag, maar gebruikers moeten nog steeds wachten om de gegevens te sorteren op die laag. In de situaties waarin u de werking van de applicatie niet kunt wijzigen, kunt u beginnen door naar uw indexen te kijken.
Als u een toepassing ondersteunt waarmee gebruikers ad-hocquery's kunnen uitvoeren, of de sorteervolgorde kunnen wijzigen zodat ze de gegevens kunnen zien zoals ze willen... stop nog niet met lezen!). U kunt niet voor elke optie indexeren. Het is inefficiënt en je creëert meer problemen dan je oplost. Je kunt hier het beste met de gebruikers praten (ik weet het, het is soms eng om je hoek van het bos te verlaten, maar probeer het eens). Voor de zoekopdrachten die de gebruikers het vaakst uitvoeren, moet u weten hoe ze de gegevens doorgaans graag zien. Ja, u kunt dit ook uit de plancache halen - u kunt vragen en plannen naar hartenlust ophalen om te zien wat ze aan het doen zijn. Maar het is sneller om met de gebruikers te praten. Het extra voordeel is dat je kunt uitleggen waarom je het vraagt, en waarom dat idee om "op alle kolommen te sorteren omdat ik het kan" niet zo'n goed idee is. Weten is het halve werk. Als u wat tijd kunt besteden aan het opleiden van uw hoofdgebruikers en de gebruikers die nieuwe mensen opleiden, kunt u misschien iets goeds doen.
Als u een toepassing ondersteunt met beperkte ORDER BY-opties, kunt u een echte analyse uitvoeren. Bekijk welke ORDER BY-varianten er zijn, bepaal welke combinaties het vaakst worden uitgevoerd en indexeer om die zoekopdrachten te ondersteunen. Je zult waarschijnlijk niet iedereen raken, maar je kunt nog steeds een impact maken. U kunt nog een stap verder gaan door met uw ontwikkelaars te praten en hen te informeren over het probleem en hoe u het kunt aanpakken.
Als u ten slotte naar queryplannen kijkt met SORT-bewerkingen, richt u dan niet alleen op het verwijderen van de Sortering. Kijk naar waar de Sort komt voor in het plan. Als het helemaal links van het plan gebeurt, en meestal . is een paar rijen, kunnen er andere gebieden zijn met een grotere verbeteringsfactor om op te focussen. De sortering aan de linkerkant is het patroon waar we ons vandaag op hebben gericht, maar een sortering vindt niet altijd plaats vanwege een ORDER BY. Als je een sortering helemaal rechts van het plan ziet en er lopen veel rijen door dat deel van het plan, dan weet je dat je een goede plek hebt gevonden om te beginnen met afstemmen.