In een perfecte wereld zou het niet uitmaken welke specifieke T-SQL-syntaxis we kozen om een vraag uit te drukken. Elke semantisch identieke constructie zou leiden tot exact hetzelfde fysieke uitvoeringsplan, met exact dezelfde prestatiekenmerken.
Om dat te bereiken, zou de SQL Server-query-optimizer alle mogelijke logische equivalenten moeten kennen (ervan uitgaande dat we ze ooit allemaal zouden kunnen kennen), en de tijd en middelen krijgen om alle opties te verkennen. Gezien het enorme aantal mogelijke manieren waarop we dezelfde eis in T-SQL kunnen uitdrukken, en het enorme aantal mogelijke transformaties, worden de combinaties snel onhandelbaar voor alle, behalve de allereenvoudigste gevallen.
Een "perfecte wereld" met volledige syntaxis-onafhankelijkheid lijkt misschien niet zo perfect voor gebruikers die dagen, weken of zelfs jaren moeten wachten op het compileren van een bescheiden complexe query. Dus de query-optimizer compromitteert:het verkent enkele veelvoorkomende equivalenten en doet zijn best om te voorkomen dat het meer tijd besteedt aan compilatie en optimalisatie dan het bespaart in uitvoeringstijd. Het doel kan worden samengevat als proberen om binnen een redelijke tijd een redelijk uitvoeringsplan te vinden en daarbij redelijke middelen te verbruiken.
Een gevolg van dit alles is dat uitvoeringsplannen vaak gevoelig zijn voor de geschreven vorm van de query. De optimizer heeft enige logica om een aantal veelgebruikte equivalente constructies snel om te zetten in een algemene vorm, maar deze mogelijkheden zijn niet goed gedocumenteerd en ook niet (in de buurt van) uitgebreid.
We kunnen onze kansen op een goed uitvoeringsplan zeker maximaliseren door eenvoudigere zoekopdrachten te schrijven, bruikbare indexen te bieden, goede statistieken bij te houden en ons te beperken tot meer relationele concepten (bijvoorbeeld door cursors, expliciete lussen en niet-inline-functies te vermijden), maar dit is geen volledige oplossing. Het is evenmin mogelijk om te zeggen dat één T-SQL-constructie altijd een beter uitvoeringsplan produceren dan een semantisch identiek alternatief.
Mijn gebruikelijke advies is om te beginnen met het eenvoudigste relationele zoekformulier dat aan uw behoeften voldoet, met behulp van de T-SQL-syntaxis die u de voorkeur geeft. Als de zoekopdracht na fysieke optimalisatie (bijv. indexering) niet aan de vereisten voldoet, kan het de moeite waard zijn om de zoekopdracht op een iets andere manier uit te drukken, terwijl de oorspronkelijke semantiek behouden blijft. Dit is het lastige deel. Welk deel van de query moet je proberen te herschrijven? Welke herschrijving moet je proberen? Op deze vragen is geen simpel pasklaar antwoord te geven. Een deel daarvan komt neer op ervaring, maar een beetje kennis over het optimaliseren van zoekopdrachten en de interne onderdelen van de uitvoeringsengine kan ook een nuttige gids zijn.
Voorbeeld
In dit voorbeeld wordt de tabel AdventureWorks TransactionHistory gebruikt. Het onderstaande script maakt een kopie van de tabel en maakt een geclusterde en niet-geclusterde index. We zullen de gegevens helemaal niet wijzigen; deze stap is alleen om de indexering duidelijk te maken (en om de tabel een kortere naam te geven):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
De taak is om een lijst met product- en geschiedenis-ID's voor zes specifieke producten te maken. Een manier om de vraag uit te drukken is:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Deze query retourneert 764 rijen met behulp van het volgende uitvoeringsplan (getoond in SentryOne Plan Explorer):

Deze eenvoudige query komt in aanmerking voor het samenstellen van een TRIVIAL-plan. Het uitvoeringsplan bevat zes afzonderlijke zoekbewerkingen voor de index in één:
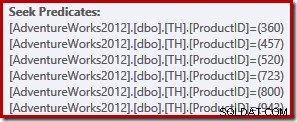
Lezers met adelaarsogen zullen hebben opgemerkt dat de zes zoekopdrachten worden weergegeven in oplopend product-ID-volgorde, niet in de (willekeurige) volgorde die is opgegeven in de IN-lijst van de oorspronkelijke zoekopdracht. Als u de zoekopdracht zelf uitvoert, is de kans groot dat de resultaten worden geretourneerd in oplopende product-ID-volgorde. De zoekopdracht is niet gegarandeerd om resultaten in die volgorde te retourneren natuurlijk, omdat we geen ORDER BY-clausule op het hoogste niveau hebben gespecificeerd. We kunnen echter een dergelijke ORDER BY-clausule toevoegen, zonder het in dit geval geproduceerde uitvoeringsplan te wijzigen:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Ik zal de afbeelding van het uitvoeringsplan niet herhalen, omdat het precies hetzelfde is:de zoekopdracht komt nog steeds in aanmerking voor een triviaal plan, de zoekbewerkingen zijn precies hetzelfde en de twee plannen hebben precies dezelfde geschatte kosten. Het toevoegen van de ORDER BY-clausule kostte ons precies niets, maar gaf ons een garantie voor het bestellen van resultaatsets.
We hebben nu de garantie dat de resultaten worden geretourneerd in de volgorde van de product-ID's, maar onze zoekopdracht specificeert momenteel niet hoe rijen met de dezelfde product-ID wordt besteld. Als u naar de resultaten kijkt, ziet u mogelijk dat rijen voor dezelfde product-ID gerangschikt lijken te zijn op transactie-ID, oplopend.
Zonder een expliciete ORDER BY is dit gewoon een andere observatie (d.w.z. we kunnen niet vertrouwen op deze volgorde), maar we kunnen de zoekopdracht wijzigen om ervoor te zorgen dat rijen worden gerangschikt op transactie-ID binnen elke product-ID:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Nogmaals, het uitvoeringsplan voor deze query is precies hetzelfde als voorheen; hetzelfde triviale plan met dezelfde geschatte kosten wordt geproduceerd. Het verschil is dat de resultaten nu gegarandeerd zijn eerst te bestellen op product-ID en vervolgens op transactie-ID.
Sommige mensen zouden in de verleiding kunnen komen om te concluderen dat de twee vorige zoekopdrachten ook altijd rijen in deze volgorde zouden retourneren, omdat de uitvoeringsplannen hetzelfde zijn. Dit is geen veilige implicatie, omdat niet alle details van de uitvoeringsengine worden weergegeven in uitvoeringsplannen (zelfs in de XML-vorm). Zonder een expliciete volgorde per clausule is het SQL Server vrij om de rijen in elke willekeurige volgorde te retourneren, zelfs als het plan er voor ons hetzelfde uitziet (het zou bijvoorbeeld de zoekopdrachten kunnen uitvoeren in de volgorde die is opgegeven in de querytekst). Het punt is dat de query-optimizer op de hoogte is van bepaalde gedragingen binnen de engine die niet zichtbaar zijn voor gebruikers, en deze kan afdwingen.
Voor het geval u zich afvraagt hoe onze niet-unieke niet-geclusterde index op Product-ID rijen kan retourneren in Product en Transactie-ID-volgorde, het antwoord is dat de niet-geclusterde indexsleutel de transactie-ID (de unieke geclusterde indexsleutel) bevat. In feite is de fysieke structuur van onze niet-geclusterde index is precies hetzelfde, op alle niveaus, alsof we de index hadden gemaakt met de volgende definitie:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
We kunnen de query zelfs schrijven met een expliciete DISTINCT of GROUP BY en toch precies hetzelfde uitvoeringsplan krijgen:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Voor alle duidelijkheid:hiervoor is op geen enkele manier een wijziging van de oorspronkelijke niet-geclusterde index vereist. Houd er als laatste voorbeeld rekening mee dat we resultaten ook in aflopende volgorde kunnen opvragen:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
De eigenschappen van het uitvoeringsplan laten nu zien dat de index achteruit wordt gescand:

Afgezien daarvan is het plan hetzelfde:het werd geproduceerd in de triviale optimalisatiefase van het plan en heeft nog steeds dezelfde geschatte kosten.
De vraag herschrijven
Er is niets mis met de vorige zoekopdracht of het uitvoeringsplan, maar we hebben er misschien voor gekozen om de zoekopdracht anders uit te drukken:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Het is duidelijk dat dit formulier exact dezelfde resultaten specificeert als het origineel, en inderdaad levert de nieuwe query hetzelfde uitvoeringsplan op (triviaal plan, meerdere zoekopdrachten in één, dezelfde geschatte kosten). Het OR-formulier maakt het misschien iets duidelijker dat het resultaat een combinatie is van de resultaten voor de zes individuele product-ID's, wat ertoe kan leiden dat we een andere variatie proberen die dit idee nog explicieter maakt:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Het uitvoeringsplan voor de UNION ALL-query is heel anders:
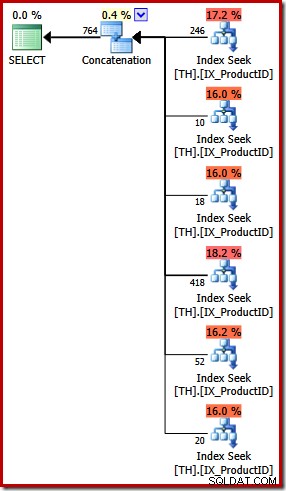
Afgezien van de voor de hand liggende visuele verschillen, vereiste dit plan op kosten gebaseerde (VOLLEDIGE) optimalisatie (het kwam niet in aanmerking voor een triviaal plan), en de geschatte kosten zijn (relatief gezien) een stuk hoger, rond 0,02 eenheden versus rond 0,005 eenheden eerder.
Dit komt terug op mijn openingsopmerkingen:de query-optimizer kent niet elke logische equivalentie en kan alternatieve query's niet altijd herkennen als die dezelfde resultaten specificeren. Het punt dat ik in dit stadium maak, is dat het uiten van deze specifieke vraag met UNION ALL in plaats van IN resulteerde in een minder optimaal uitvoeringsplan.
Tweede voorbeeld
In dit voorbeeld wordt een andere set van zes product-ID's gekozen en verzoeken resulteren in een transactie-ID-volgorde:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Onze niet-geclusterde index kan geen rijen in de gevraagde volgorde leveren, dus de query-optimizer kan kiezen tussen zoeken op de niet-geclusterde index en sorteren, of de geclusterde index scannen (die alleen op transactie-ID is ingetoetst) en de predikaten van de product-ID toepassen als een residu. De vermelde product-ID's hebben een lagere selectiviteit dan de vorige set, dus de optimizer kiest in dit geval voor een geclusterde indexscan:
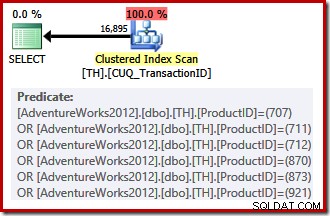
Omdat er een op kosten gebaseerde keuze moet worden gemaakt, kwam dit uitvoeringsplan niet in aanmerking voor een triviaal plan. De geschatte kosten van het definitieve plan bedragen ongeveer 0,714 eenheden. Voor het scannen van de geclusterde index is 797 . vereist logische leest tijdens uitvoering.
Misschien verrast dat de zoekopdracht de productindex niet gebruikte, zouden we kunnen proberen een zoekopdracht naar de niet-geclusterde index te forceren met behulp van een indexhint, of door FORCESEEK op te geven:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
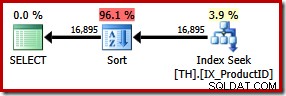
Dit resulteert in een expliciete sortering op transactie-ID. De nieuwe soort wordt geschat op 96% van de 1.15 . van het nieuwe abonnement kosten per eenheid. Deze hogere geschatte kosten verklaren waarom de optimizer koos voor de ogenschijnlijk goedkopere geclusterde indexscan wanneer hij aan zijn lot werd overgelaten. De I/O-kosten van de nieuwe query zijn echter lager:wanneer uitgevoerd, verbruikt de indexzoekopdracht slechts 49 logische leest (verlaagd vanaf 797).
We hebben er misschien ook voor gekozen om deze vraag uit te drukken met (het eerder mislukte) UNION ALL-idee:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Het levert het volgende uitvoeringsplan op (klik op de afbeelding om te vergroten in een nieuw venster):

Dit plan lijkt misschien ingewikkelder, maar het kost naar schatting slechts 0,099 eenheden, wat veel lager is dan de geclusterde indexscan (0,714 eenheden) of zoeken plus sorteren (1.15 eenheden). Bovendien verbruikt het nieuwe abonnement slechts 49 logische leest tijdens uitvoering - hetzelfde als het plan zoeken + sorteren, en veel lager dan de 797 die nodig is voor de geclusterde indexscan.
Deze keer leverde het uitdrukken van de vraag met UNION ALL een veel beter plan op, zowel wat betreft geschatte kosten als logische uitlezingen. De brongegevensset is iets te klein om een echt zinvolle vergelijking te maken tussen de duur van de query's of het CPU-gebruik, maar de geclusterde indexscan duurt twee keer zo lang (26 ms) als de andere twee op mijn systeem.
De extra sortering in het aangegeven plan is in dit eenvoudige voorbeeld waarschijnlijk onschadelijk omdat het onwaarschijnlijk is dat het op schijf terechtkomt, maar veel mensen zullen toch de voorkeur geven aan het UNION ALL-plan omdat het niet-blokkerend is, een geheugentoelage vermijdt en geen vraaghint.
Conclusie
We hebben gezien dat de querysyntaxis van invloed kan zijn op het uitvoeringsplan dat door de optimizer is gekozen, ook al specificeren de query's logischerwijs exact dezelfde resultatenset. Dezelfde herschrijving (bijv. UNION ALL) leidt soms tot een verbetering en soms tot een slechter plan.
Het herschrijven van query's en het uitproberen van alternatieve syntaxis is een geldige afstemmingstechniek, maar enige voorzichtigheid is geboden. Een risico is dat toekomstige wijzigingen aan het product ertoe kunnen leiden dat het andere vraagformulier plotseling stopt met het produceren van het betere plan, maar men zou kunnen stellen dat dit altijd een risico is en wordt beperkt door tests voorafgaand aan de upgrade of het gebruik van planhandleidingen.
Het risico bestaat ook dat u zich laat meeslepen door deze techniek:het gebruik van 'rare' of 'ongewone' queryconstructies om een beter presterend plan te krijgen, is vaak een teken dat er een grens is overschreden. Waar het onderscheid precies ligt tussen geldige alternatieve syntaxis en 'ongebruikelijk/raar' is waarschijnlijk nogal subjectief; mijn eigen persoonlijke gids is om met equivalente relationele vraagformulieren te werken en de zaken zo eenvoudig mogelijk te houden.