In dit artikel zullen we ons concentreren op realtime operationele analyses en hoe deze benadering op een OLTP-database kan worden toegepast. Als we naar het traditionele analytische model kijken, zien we dat OLTP en analytische omgevingen afzonderlijke structuren zijn. Allereerst moeten de traditionele analytische modelomgevingen ETL-taken (Extract, Transform and Load) creëren. Omdat we transactiegegevens naar het datawarehouse moeten overbrengen. Dit soort architectuur heeft enkele nadelen. Dit zijn kosten, complexiteit en gegevenslatentie. Om deze nadelen weg te werken, hebben we een andere aanpak nodig.
Realtime operationele analyse
Microsoft heeft Real-Time Operational Analytics aangekondigd in SQL Server 2016. De mogelijkheid van deze functie is om de werklast van een transactiedatabase en analytische query's te combineren zonder prestatieproblemen. Realtime operationele analyse biedt:
- hybride structuur
- Transactionele en analytische zoekopdrachten kunnen tegelijkertijd worden uitgevoerd
- veroorzaakt geen prestatie- en latentieproblemen.
- een eenvoudige implementatie.
Deze functie kan de nadelen van de traditionele analytische omgeving overwinnen. Het belangrijkste thema van deze functie is dat de kolomopslagindex een kopie van gegevens bijhoudt zonder de prestaties van het transactiesysteem te beïnvloeden. Met dit thema kunnen de analytische query's worden uitgevoerd zonder de prestaties te beïnvloeden. Dit minimaliseert dus de impact op de prestaties. De belangrijkste beperking van deze functie is dat we geen gegevens uit verschillende gegevensbronnen kunnen verzamelen.
Niet-geclusterde Column Store-index
SQL Server 2016 introduceert updatebare "Niet-geclusterde Column Store Index". De niet-geclusterde Column Store Index is een op kolommen gebaseerde index die prestatievoordelen biedt voor analytische query's. Met deze functie kunnen we het realtime raamwerk voor operationele analyse creëren. Dat betekent dat we transacties en analytische queries tegelijkertijd kunnen uitvoeren. Bedenk dat we maandelijkse totale verkopen nodig hebben. In een traditioneel model moeten we ETL-taken, datamart en datawarehouse ontwikkelen. Maar in realtime operationele analyse kunnen we dit doen zonder dat er datawarehouses of wijzigingen in de OLTP-structuur nodig zijn. We hoeven alleen een geschikte niet-geclusterde kolomopslagindex te maken.
Architectuur van niet-geclusterde kolomopslagindex
Laten we kort kijken naar de architectuur van de niet-geclusterde kolomopslagindex en het lopende mechanisme. De niet-geclusterde kolomarchiefindex bevat een kopie van een deel of alle rijen en kolommen in de onderliggende tabel. Het hoofdthema van de niet-geclusterde kolomopslagindex is om een kopie van de gegevens bij te houden en deze kopie van de gegevens te gebruiken. Dit mechanisme minimaliseert de impact op de prestaties van de transactiedatabase. De niet-geclusterde kolomopslagindex kan een of meer kolommen maken en een filter toepassen op kolommen.
Wanneer we een nieuwe rij invoegen in een tabel die een niet-geclusterde kolomopslagindex heeft, maakt SQL Server eerst een "rijgroep". Rijgroep is een logische structuur die een reeks rijen vertegenwoordigt. Vervolgens slaat SQL Server deze rijen op in een tijdelijke opslag. De naam van deze tijdelijke opslag is “deltastore”. SQL Server gebruikt dit tijdelijke opslaggebied omdat dit mechanisme de compressieverhouding verbetert en de indexfragmentatie vermindert. Wanneer het aantal rijen 1.048.577 bereikt, sluit SQL Server de status van de rijgroep. SQL Server comprimeert deze rijgroep en verandert de status in "gecomprimeerd".
Nu gaan we een tabel maken en de niet-geclusterde kolomopslagindex toevoegen.
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO>
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
PRIMARY In deze stap zullen we verschillende rijen invoegen en kijken naar de eigenschappen van de niet-geclusterde kolomopslagindex.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
Deze zoekopdracht toont de status van de rijgroep, het totale aantal rijen en andere waarden.
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

De afbeelding hierboven toont ons de deltastore-status en het totale aantal rijen die niet zijn gecomprimeerd. Nu zullen we meer gegevens in de tabel invullen en wanneer het aantal rijen 1.048.577 bereikt, zal SQL Server de eerste rijgroep sluiten en een nieuwe rijgroep openen.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

SQL Server comprimeert deze rijgroep en maakt een nieuwe rijgroep. Met de optie "COMPRESSION_DELAY" kunnen we bepalen hoe lang de rijgroep wacht in de gesloten status.

Wanneer we de index-onderhoudsopdrachten uitvoeren (reorganiseren, opnieuw opbouwen), worden de verwijderde rijen fysiek verwijderd en wordt de index gedefragmenteerd.

Wanneer we enkele rijen in deze tabel bijwerken (verwijderen + invoegen), worden de verwijderde rijen gemarkeerd als "verwijderd" en worden nieuwe bijgewerkte rijen ingevoegd in de deltastore.
Analyse prestatiebenchmark voor zoekopdrachten
In deze kop zullen we gegevens invullen in de tabel Analysis_TableTest. Ik heb 4 miljoen records ingevoegd. (U moet deze stap en de volgende stappen in uw testomgeving testen. Er kunnen prestatieproblemen optreden en ook de opdracht DBCC DROPCLEANBUFFERS kan de prestaties schaden. Met deze opdracht worden alle buffergegevens in de bufferpool verwijderd.)
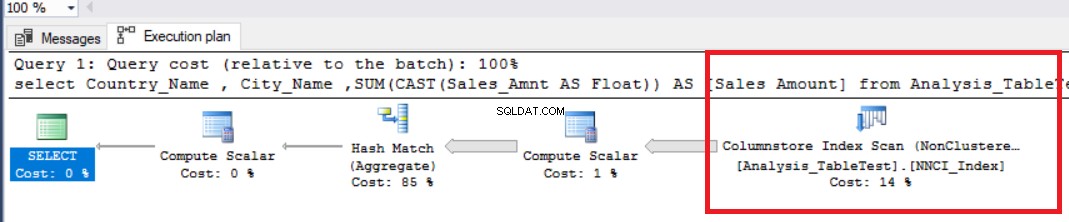
Nu zullen we de volgende analytische query uitvoeren en de prestatiewaarden onderzoeken.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

In de bovenstaande afbeelding kunnen we de niet-geclusterde kolomopslagindex-scanoperator zien. De onderstaande tabel toont de CPU- en uitvoeringstijden. Deze query verbruikt 1,765 milliseconden in CPU en is voltooid in 0,791 milliseconden. De CPU-tijd is groter dan de verstreken tijd omdat het uitvoeringsplan parallelle processors gebruikt en taken verdeelt over 4 processors. We kunnen het zien in de eigenschappen van de operator "Columnstore Index Scan". De waarde "Aantal uitvoeringen" geeft dit aan.

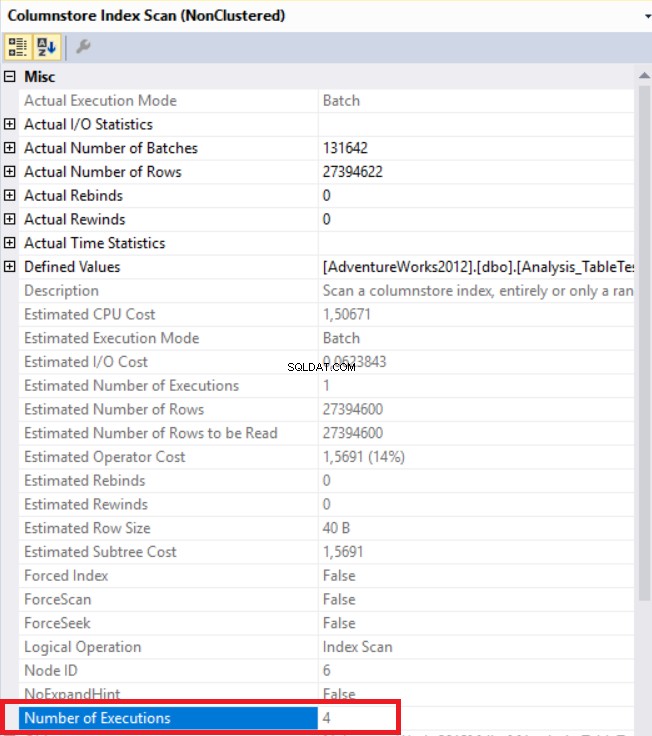
Nu zullen we een hint aan de query toevoegen om het aantal processors te verminderen. We zullen geen parallellisme-operator zien.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

De onderstaande tabel definieert uitvoeringstijden. In deze grafiek kunnen we zien dat de verstreken tijd groter is dan de CPU-tijd omdat SQL Server slechts één processor gebruikte.
Nu zullen we de niet-geclusterde kolomopslagindex uitschakelen en dezelfde query uitvoeren.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

De bovenstaande tabel laat zien dat de niet-geclusterde kolomopslagindex ongelooflijke prestaties biedt bij analytische zoekopdrachten. De geïndexeerde zoekopdracht in de kolomopslag is ongeveer vijf keer beter dan de andere.
Conclusie
Realtime operationele analyse biedt ongelooflijke flexibiliteit omdat we analytische query's in OLTP-systemen kunnen uitvoeren zonder enige gegevenslatentie. Tegelijkertijd hebben deze analytische query's geen invloed op de prestaties van de OLTP-database. Deze functie geeft ons de mogelijkheid om transactiegegevens en de analytische zoekopdrachten in dezelfde omgeving te beheren.
Referenties
Kolomopslagindexen - Begeleiding bij het laden van gegevens
Ga aan de slag met Column Store voor realtime operationele analyses
Realtime operationele analyse
Verder lezen:
Achterwaartse scan van SQL Server-index:begrijpen, afstemmen
Indexen gebruiken in voor geheugen geoptimaliseerde tabellen voor SQL Server