In dit artikel onderzoeken we de basis en details van de SQL Server IDENTITY-eigenschap en de IDENTITY-kolomfuncties. We zullen ook bekijken hoe we expliciete waarden in de identiteitskolommen kunnen invoegen via de IDENTITY_INSERT-functie.
Inleiding tot SQL Server IDENTITY-eigenschap en IDENTITY-kolom
In SQL Server kunnen we met de identiteitseigenschap identiteitskolommen maken in de SQL Server-tabellen volgens de instellingen van de syntaxis van de identiteitseigenschap. De syntaxis van de identiteitseigenschap ziet er als volgt uit en we passen deze syntaxis toe om een tabelinstructie te maken of te wijzigen.
IDENTITEIT [(seed, increment)]
Eerst zullen we de parameters van de identiteitseigenschap onderzoeken. Deze eigenschap heeft twee invoerparameters:de eerste is seed en de tweede is increment. De seed-parameter geeft aan dat de eerste startwaarde van de ingevoegde waarde in de tabel en de Increment-parameter de incrementwaarde van de ingevoegde gegevens definieert.
Nu zullen we deze hoofddefinitie van identiteitseigenschap intensiveren met enkele voorbeelden.
Hoe maak je een identiteitskolom in SQL Server
Voorbeeld-1 :In het volgende voorbeeld zullen we een identiteitskolom maken en de eerste waarde begint bij 1 en wordt 1 met 1 verhoogd.
DROP TABLE IF EXISTS TestIdentity
CREATE TABLE TestIdentity
(Id INT IDENTITY(1,1) ,
Col1 VARCHAR(100))
GO
INSERT INTO TestIdentity
VALUES ('The first inserted row')
INSERT INTO TestIdentity
VALUES ('The second inserted row')
INSERT INTO TestIdentity
VALUES ('The third inserted row')
INSERT INTO TestIdentity
VALUES ('The fourth inserted row')
SELECT Id as [IdentityColumn],Col1 FROM TestIdentity
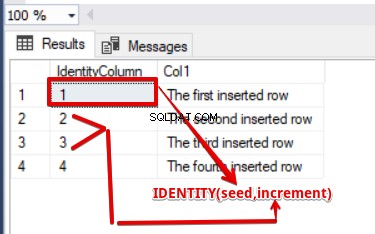
Voorbeeld-2 :In het volgende voorbeeld zullen we een identiteitskolom maken en de eerste waarde begint bij 37 en wordt 20 bij 20 verhoogd.
DROP TABLE IF EXISTS TestIdentity
CREATE TABLE TestIdentity
(Id INT IDENTITY(37,20) ,
Col1 VARCHAR(100))
GO
INSERT INTO TestIdentity
VALUES ('The first inserted row')
INSERT INTO TestIdentity
VALUES ('The second inserted row')
INSERT INTO TestIdentity
VALUES ('The third inserted row')
INSERT INTO TestIdentity
VALUES ('The fourth inserted row')
SELECT Id as [IdentityColumn],Col1 FROM TestIdentity
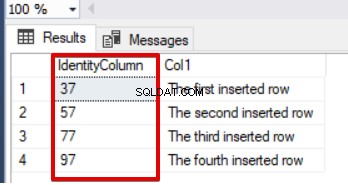
Zoals u in het bovenstaande voorbeeld kunt zien, zorgt de identiteitseigenschap voor het genereren van de waarden voor automatisch verhogen op basis van seed- en identiteitsparameters.
Hoe voeg ik expliciete waarden in de SQL Server-identiteitskolom in?
Met de identiteitseigenschap kunnen we standaard geen expliciete waarden invoegen in de identiteitskolommen. Als u expliciete waarden in een identiteitskolom probeert in te voegen, krijgt u de volgende fout te zien.
DROP TABLE IF EXISTS TestIdentity CREATE TABLE TestIdentity (Id INT IDENTITY(1,1) , Col1 VARCHAR(100)) GO INSERT INTO TestIdentity VALUES (1,'The first inserted row')
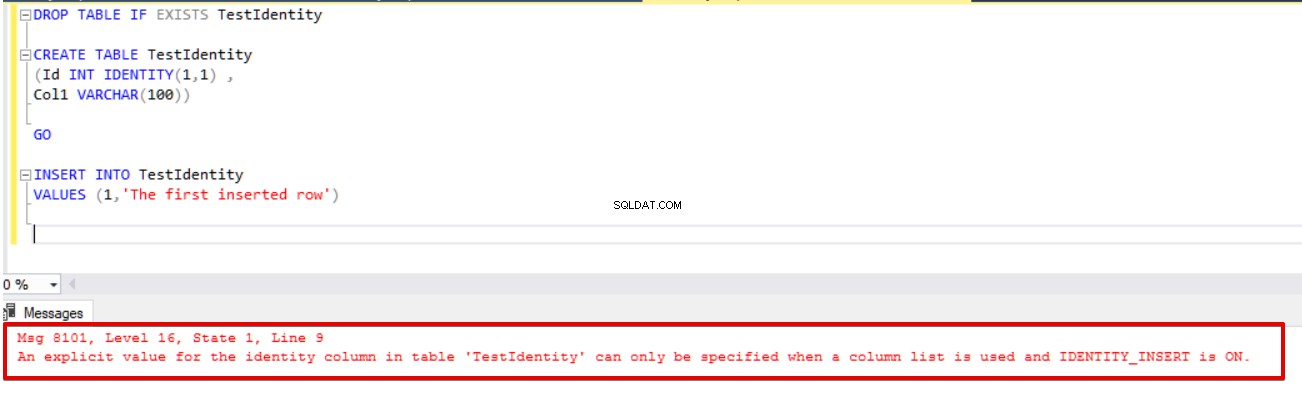
Bericht 8101, niveau 16, staat 1, regel 9
Een expliciete waarde voor de identiteitskolom in table, 'TestIdentity' kan alleen worden opgegeven als een kolomlijst wordt gebruikt en IDENTITY_INSERT is ingeschakeld.
We kunnen deze fout verhelpen door de IDENTITY_INSERT-functie van de tabel in te schakelen. Nu zullen we de insert-instructie als volgt wijzigen.
DROP TABLE IF EXISTS TestIdentity CREATE TABLE TestIdentity (Id INT IDENTITY(1,1) , Col1 VARCHAR(100)) SET IDENTITY_INSERT TestIdentity ON INSERT INTO TestIdentity (Id,Col1) VALUES (1,'The first inserted row') SET IDENTITY_INSERT TestIdentity OFF SELECT * FROM TestIdentity
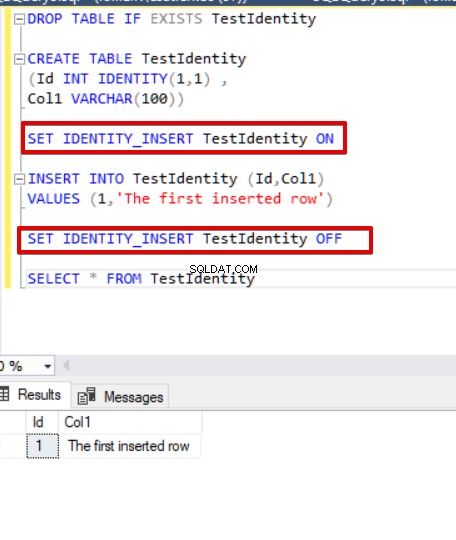
Een ander belangrijk punt over dit probleem is dat we een kolomlijst moeten schrijven om de instructie in te voegen. Als we dit niet doen, krijgen we de volgende fout te zien.
DROP TABLE IF EXISTS TestIdentity CREATE TABLE TestIdentity (Id INT IDENTITY(1,1) , Col1 VARCHAR(100)) SET IDENTITY_INSERT TestIdentity ON INSERT INTO TestIdentity VALUES (1,'The first inserted row') SET IDENTITY_INSERT TestIdentity OFF
Bericht 8101, niveau 16, staat 1, regel 9
Een expliciete waarde voor de identiteitskolom in table, 'TestIdentity' kan alleen worden opgegeven als een kolomlijst wordt gebruikt en IDENTITY_INSERT is ingeschakeld.
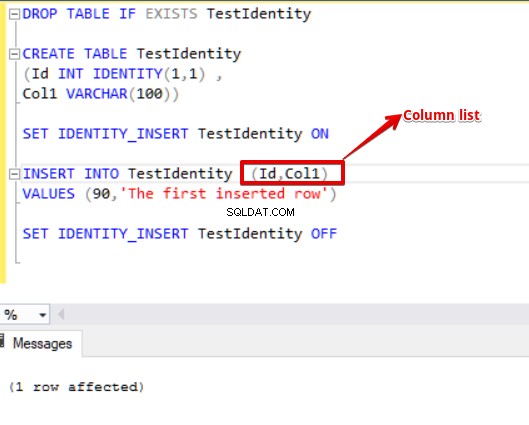
Deze fout definieert dat de kolomlijst ontbreekt in de insert-instructie. In de onderstaande insert-instructie zullen we deze fout herstellen.
DROP TABLE IF EXISTS TestIdentity CREATE TABLE TestIdentity (Id INT IDENTITY(1,1) , Col1 VARCHAR(100)) SET IDENTITY_INSERT TestIdentity ON INSERT INTO TestIdentity (Id,Col1) ---column list VALUES (90,'The first inserted row') SET IDENTITY_INSERT TestIdentity OFF
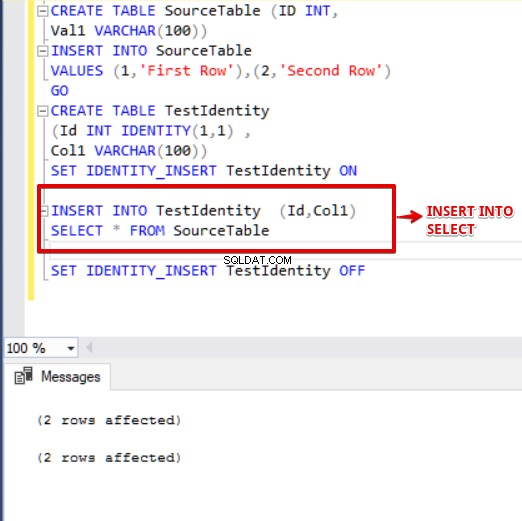
In sommige gevallen moeten we gegevens uit een andere tabel in de ene tabel invoegen. Een van de beste manieren om deze bewerking uit te voeren, is door de instructies "INSERT INTO SELECT" te gebruiken. Als de doeltabel echter een identiteitskolom heeft, moeten we de optie IDENTITY_INSERT in de doeltabel inschakelen. We moeten ook de kolomlijst van de doeltabel schrijven.
DROP TABLE IF EXISTS TestIdentity DROP TABLE IF EXISTS SourceTable CREATE TABLE SourceTable (ID INT, Val1 VARCHAR(100)) INSERT INTO SourceTable VALUES (1,'First Row'),(2,'Second Row') GO CREATE TABLE TestIdentity (Id INT IDENTITY(1,1) , Col1 VARCHAR(100)) SET IDENTITY_INSERT TestIdentity ON INSERT INTO TestIdentity (Id,Col1) SELECT * FROM SourceTable SET IDENTITY_INSERT TestIdentity OFF
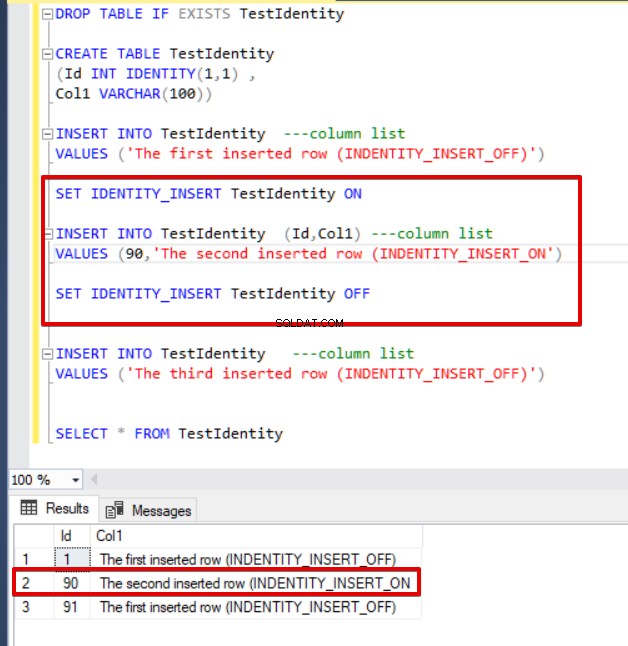
Het nadeel van de IDENTITY_INSERT-optie is dat deze een opening kan veroorzaken tussen de identiteitskolomwaarden. Een instructie die lijkt op de volgende zal een gat tussen de waarden van de identiteitskolommen genereren.
DROP TABLE IF EXISTS TestIdentity
CREATE TABLE TestIdentity
(Id INT IDENTITY(1,1) ,
Col1 VARCHAR(100))
INSERT INTO TestIdentity ---column list
VALUES ('The first inserted row (INDENTITY_INSERT_OFF)')
SET IDENTITY_INSERT TestIdentity ON
INSERT INTO TestIdentity (Id,Col1) ---column list
VALUES (90,'The second inserted row (INDENTITY_INSERT_ON')
SET IDENTITY_INSERT TestIdentity OFF
INSERT INTO TestIdentity ---column list
VALUES ('The third inserted row (INDENTITY_INSERT_OFF)')
SELECT * FROM TestIdentity
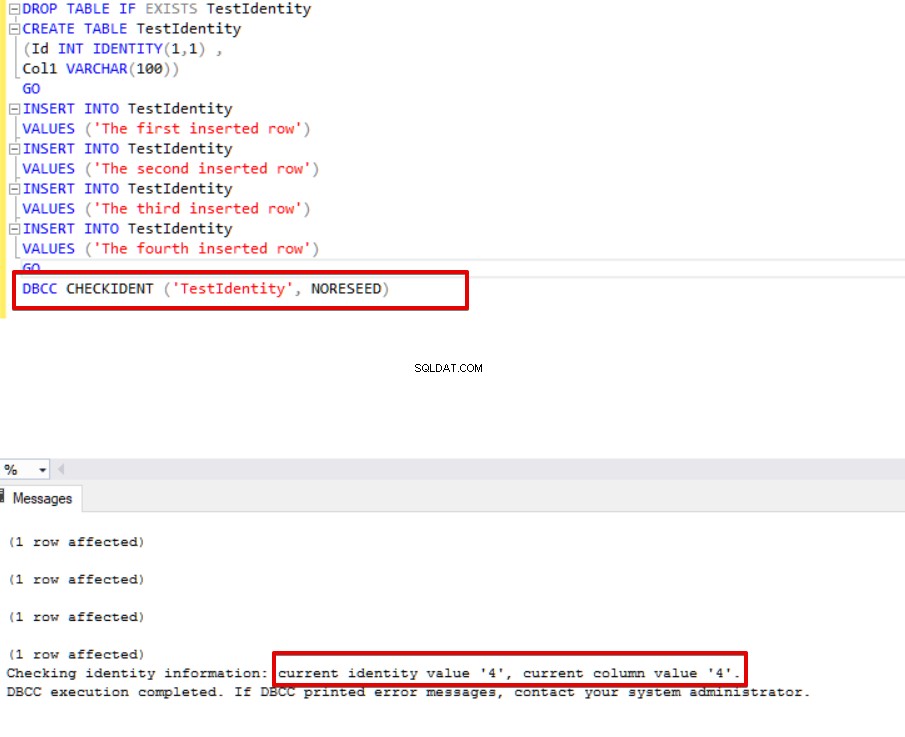
DBCC CHECKIDENT-opdracht
Met de opdracht DBCC CHECKIDENT kunnen we details krijgen over de laatste waarde van de identiteitskolom. Met deze functie kunt u ook de huidige waarde van de identiteitskolom resetten en wijzigen in een andere waarde. Nu krijgen we de laatste waarde van de identiteit via de opdracht DBCC CHECKIDENT.
DROP TABLE IF EXISTS TestIdentity
CREATE TABLE TestIdentity
(Id INT IDENTITY(1,1) ,
Col1 VARCHAR(100))
GO
INSERT INTO TestIdentity
VALUES ('The first inserted row')
INSERT INTO TestIdentity
VALUES ('The second inserted row')
INSERT INTO TestIdentity
VALUES ('The third inserted row')
INSERT INTO TestIdentity
VALUES ('The fourth inserted row')
DBCC CHECKIDENT ('TestIdentity', NORESEED)
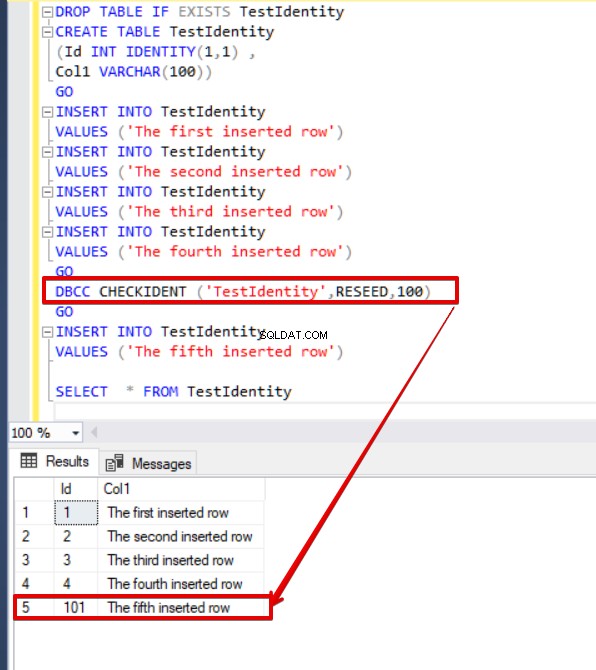
Een andere optie voor de opdracht DBCC CHECKIDENT is het resetten van de identiteitskolom naar een vereiste waarde. In het volgende voorbeeld verandert de RESEED-parameter de max-waarde van de identiteitskolom in 100 en de vervolgens ingevoegde waarden gebruiken deze max-waarde.
DROP TABLE IF EXISTS TestIdentity
CREATE TABLE TestIdentity
(Id INT IDENTITY(1,1) ,
Col1 VARCHAR(100))
GO
INSERT INTO TestIdentity
VALUES ('The first inserted row')
INSERT INTO TestIdentity
VALUES ('The second inserted row')
INSERT INTO TestIdentity
VALUES ('The third inserted row')
INSERT INTO TestIdentity
VALUES ('The fourth inserted row')
GO
DBCC CHECKIDENT ('TestIdentity',RESEED,100)
GO
INSERT INTO TestIdentity
VALUES ('The fifth inserted row')
SELECT * FROM TestIdentity
SQL Server-identiteitskolom en uniciteit
Identiteitskolommen bieden geen garantie voor het genereren van unieke waarden. Dit is een veelvoorkomend verwarrend probleem met identiteitskolommen, dus als we de uniekheid van de gegenereerde waarden willen garanderen, kunnen we de unieke index voor deze kolommen gebruiken. Nu zullen we bewijzen en demonstreren hoe dubbele waarden over de identiteitskolommen kunnen worden gemaakt.
DROP TABLE IF EXISTS TestIdentity CREATE TABLE TestIdentity (Id INT IDENTITY(1,1) , Col1 VARCHAR(100)) SET IDENTITY_INSERT TestIdentity ON INSERT INTO TestIdentity (Id,Col1) VALUES (1,'The first inserted row (INDENTITY_INSERT_OFF)') INSERT INTO TestIdentity (Id,Col1) VALUES (1,'The first inserted row (INDENTITY_INSERT_OFF)') SET IDENTITY_INSERT TestIdentity OFF SELECT * FROM TestIdentity

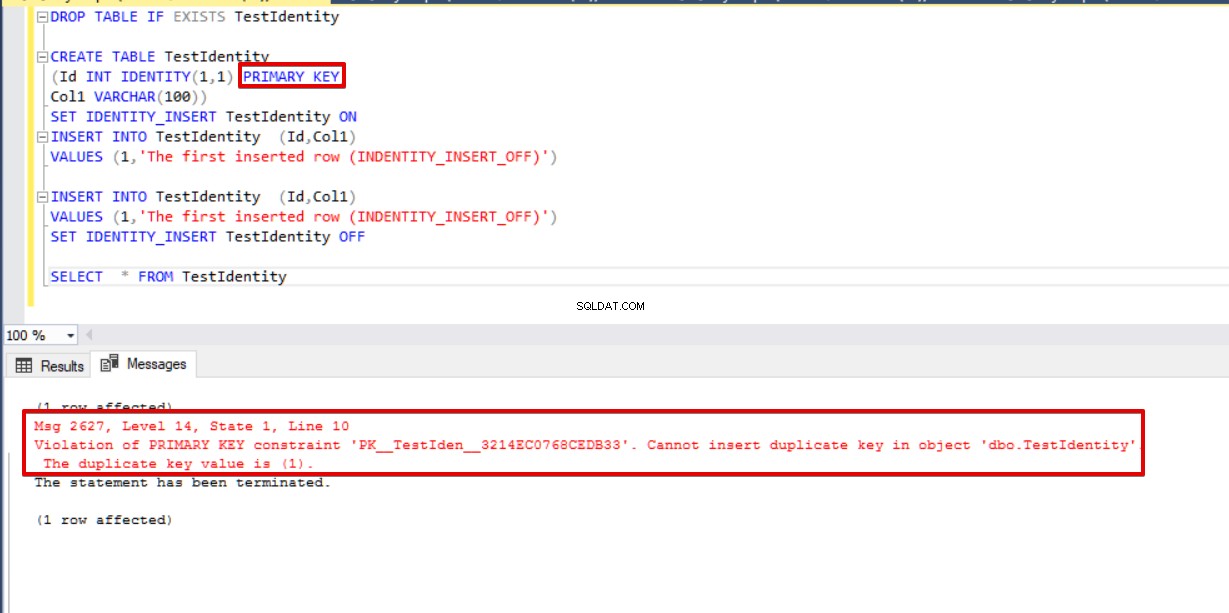
Bovendien zijn identiteitskolommen en primaire sleutels twee verschillende objecten in SQL Server. Het gebruiksdoel van de identiteitskolom is om het automatisch oplopende nummer te genereren. Aan de andere kant garandeert en verschaft de primaire sleutelbeperking de uniciteit van de waarden in een bepaalde kolom. De beperking Primary Key dwingt de unieke waarden voor de gedefinieerde kolommen af, omdat Primary Key standaard een geclusterde unieke index in de tabel maakt. In het algemene gebruik kunnen de beperking van de primaire sleutel en de identiteitseigenschap samen worden gebruikt. Deze gebruiksbenadering helpt ons om de flexibiliteit van de uniciteit van de primaire sleutel en de functie voor automatisch verhogen van identiteit naar de toegepaste kolom te brengen. In het volgende voorbeeld voegen we ook een primaire sleutelbeperking toe aan de Id-kolom om te voorkomen dat ingevoegde waarden worden gedupliceerd.
DROP TABLE IF EXISTS TestIdentity CREATE TABLE TestIdentity (Id INT IDENTITY(1,1) PRIMARY KEY, Col1 VARCHAR(100)) SET IDENTITY_INSERT TestIdentity ON INSERT INTO TestIdentity (Id,Col1) VALUES (1,'The first inserted row (INDENTITY_INSERT_OFF)') INSERT INTO TestIdentity (Id,Col1) VALUES (1,'The first inserted row (INDENTITY_INSERT_OFF)') SET IDENTITY_INSERT TestIdentity OFF SELECT * FROM TestIdentity
Wanneer we navigeren op het tabblad Indexen van de TestIdentity-tabel in de objectverkenner, kunnen we een unieke geclusterde index ontdekken die is gemaakt door primaire sleutelbeperking. Deze beperking wordt afgedwongen tot unieke waarden voor de Id-kolom.
Conclusie
In dit artikel hebben we de fundamentele concepten en gebruiksmethoden van SQL Server Identity-eigenschap en Identity-kolommen besproken.
Referenties
- MAAK TABEL (Transact-SQL) IDENTITEIT (Eigenschap)
- Primaire sleutels maken