Inleiding tot SQL Server-indexen
Microsoft SQL Server wordt beschouwd als een van de relationele databasebeheersystemen (RDBMS ), waarin de gegevens logisch zijn georganiseerd in rijen en kolommen die zijn opgeslagen in gegevenscontainers die tabellen worden genoemd. Fysiek worden de tabellen opgeslagen als 8 KB pagina's die kunnen worden georganiseerd in Heap- of B-Tree Clustered-tabellen. In de hoop tabel, is er geen sorteervolgorde die de volgorde van de gegevens binnen de gegevenspagina's en de volgorde van pagina's in die tabel bepaalt, aangezien er geen geclusterde index voor die tabel is gedefinieerd om het sorteermechanisme af te dwingen. Als een geclusterde index is gedefinieerd op één kolom van de groep tabelkolommen, worden de gegevens binnen de gegevenspagina's gesorteerd op basis van de waarden van de geclusterde indexsleutelkolommen en worden de pagina's aan elkaar gekoppeld op basis van deze indexsleutelwaarden. Deze gesorteerde tabel heet een Geclusterde tabel .
In SQL Server wordt de index beschouwd als een belangrijke en effectieve sleutel in het prestatieafstemmingsproces. Het doel van het maken van een index is om de toegang tot de basistabel te versnellen en de gevraagde gegevens op te halen zonder dat u alle tabelrijen hoeft te scannen om de gevraagde gegevens te retourneren. Je kunt de database-index zien als een boekenindex waarmee je snel de woorden in het boek kunt vinden, zonder dat je het hele boek hoeft te lezen om dat woord te vinden. Stel dat u informatie over een specifieke klant moet ophalen met behulp van een klant-ID. Als er geen index is gedefinieerd voor de kolom Klant-ID in deze tabel, controleert de SQL Server Engine alle tabelrijen één voor één om de klant met de opgegeven ID op te halen. Als er een index is gedefinieerd voor de kolom Klant-ID in deze tabel, zoekt de SQL Server Engine naar de gevraagde klant-ID-waarden in de gesorteerde index, in plaats van in de basistabel, om informatie over de klant op te halen, waardoor het aantal gescande rijen om de gegevens op te halen.
In SQL Server is de index logisch gestructureerd als 8K-pagina's, of indexknooppunten, in de vorm van een B-tree. De B-Tree structuur bevat drie niveaus:een Root Level die één indexpagina bovenaan de B-tree bevat, een Bladniveau die zich onderaan de B-tree bevindt en datapagina's bevat, en een Intermediate Level dat omvat alle knooppunten die zich tussen de root- en de leaf-niveaus bevinden, met indexsleutelwaarden en verwijzingen naar de volgende pagina's. Deze B-boomvorm biedt een snelle manier om op basis van de indexsleutel van links naar rechts en van boven naar beneden door de gegevenspagina's te navigeren.
In SQL Server zijn er twee hoofdtypen indexen, een geclusterde index, waarin de feitelijke gegevens worden opgeslagen op de bladniveaupagina's van de index, met de mogelijkheid om slechts één geclusterde index voor elke tabel te maken, aangezien de gegevens binnen de gegevenspagina's en de volgorde van de pagina's worden gesorteerd op basis van de geclusterde index sleutel. Als u een primaire-sleutelbeperking in uw tabel definieert, wordt automatisch een geclusterde index gemaakt als er eerder geen geclusterde index voor die tabel is gedefinieerd. Het tweede type indexen is een Niet-geclusterde index die een gesorteerde kopie van de indexsleutelkolommen en een verwijzing naar de rest van de kolommen in de basistabel of de geclusterde index bevat, met de mogelijkheid om tot 999 niet-geclusterde indexen voor elke tabel te maken.
SQL Server biedt ons andere speciale soorten indexen, zoals een Unieke index die automatisch wordt gemaakt wanneer een unieke beperking wordt gedefinieerd om de uniciteit van specifieke kolomwaarden af te dwingen, een Samengestelde index waarin meer dan één sleutelkolom zal deelnemen aan de indexsleutel, een Dekkende index waarin alle kolommen die door een specifieke zoekopdracht worden gevraagd, deelnemen aan de indexsleutel, een Gefilterde index dat is een geoptimaliseerde niet-geclusterde index met een filterpredikaat voor het indexeren van slechts een klein deel van de tabelrijen, een Ruimtelijke index die is gemaakt op de kolommen waarin ruimtelijke gegevens zijn opgeslagen, een XML-index die is gemaakt op XML binaire grote objecten (BLOB's) in kolommen van het XML-gegevenstype, een Columnstore-index waarin gegevens zijn georganiseerd in zuilvormige gegevensindeling, een Full-text index die is gemaakt door de SQL Server Full-Text Engine, en een Hash-index die wordt gebruikt in voor geheugen geoptimaliseerde tabellen.
Zoals ik de SQL Server-index noemde, is dit een tweesnijdend zwaard , waarbij de SQL Server Query Optimizer kan profiteren van de index die goed is ontworpen om de prestaties van uw toepassingen te verbeteren door het proces voor het ophalen van gegevens te versnellen. Een index die op een slechte manier is ontworpen, zal daarentegen niet worden gekozen door de SQL Server Query Optimizer en zal de prestaties van uw toepassingen verslechteren door de bewerkingen voor het wijzigen van gegevens te vertragen en uw opslagruimte te verbruiken zonder er gebruik van te maken in de gegevens ophaalprocessen. Daarom is het beter om eerst de best practices en richtlijnen voor het maken van indexen te volgen, het effect van het maken van een op de ontwikkelomgeving te controleren en een compromis te vinden tussen de snelheid van gegevensophaalbewerkingen en de overhead van het toevoegen van die index aan de gegevenswijzigingsbewerkingen en de ruimtevereisten van die index, voordat u deze toepast op de productieomgeving.
Voordat u een index maakt, moet u de verschillende aspecten bestuderen die van invloed zijn op het maken en gebruiken van de index. Dit omvat het type van de database-workload, online transactieverwerking (OLTP) of online analytische verwerking (OLAP), de grootte van de tabel , de kenmerken van de tabelkolommen , de sorteervolgorde van de kolommen in de zoekopdracht, het type van de index die overeenkomt met de zoekopdracht en de opslageigenschappen zoals de FILLFACTOR en PAD_INDEX opties die het percentage ruimte op elk bladniveau bepalen en de pagina's op het tussenliggende niveau die met gegevens moeten worden gevuld.
SQL Server Index Fragmentatie
Jouw werk als DBA beperkt zich niet tot het maken van de juiste index. Nadat de index is gemaakt, moet u het indexgebruik en de statistieken controleren. U moet bijvoorbeeld weten of deze index slecht of helemaal niet wordt gebruikt. U kunt dus de juiste oplossing bieden om deze indexen te onderhouden of ze te vervangen door efficiëntere. Op deze manier behoudt u de hoogst mogelijke prestaties voor uw systeem. U vraagt zich misschien af:waarom gebruikt de SQL Server Query Optimizer mijn index niet meer, terwijl het dat eerder wel deed?
Het antwoord heeft voornamelijk te maken met de continue gegevens- en schemawijzigingen die worden uitgevoerd op de basistabel en die in de indexen moeten worden weerspiegeld. Na verloop van tijd, en met al deze veranderingen, raken indexpagina's ongesorteerd, waardoor de index gefragmenteerd raakt. Een andere reden voor de fragmentatie is een poging om een nieuwe waarde in te voegen of de huidige waarde bij te werken, en de nieuwe waarde past niet in de momenteel beschikbare vrije ruimte. In dit geval wordt de pagina opgesplitst in twee pagina's, waarbij de nieuwe pagina fysiek wordt aangemaakt na de laatste pagina. En je kunt je voorstellen dat je leest uit een gefragmenteerde index en het aantal pagina's dat moet worden gescand, en natuurlijk het aantal I/O-bewerkingen dat wordt uitgevoerd om verschillende records op te halen vanwege de afstand tussen deze pagina's. En vanwege deze extra kosten van het gebruik van deze gefragmenteerde index, zal de SQL Server Query Optimizer deze index negeren.
Verschillende manieren om indexfragmentatie te verkrijgen
SQL Server biedt ons verschillende manieren om het percentage indexfragmentatie te krijgen. De eerste manier is om het percentage indexfragmentatie in de Index . te controleren Eigenschappen venster, onder de Fragmentatie tabblad, zoals hieronder weergegeven:
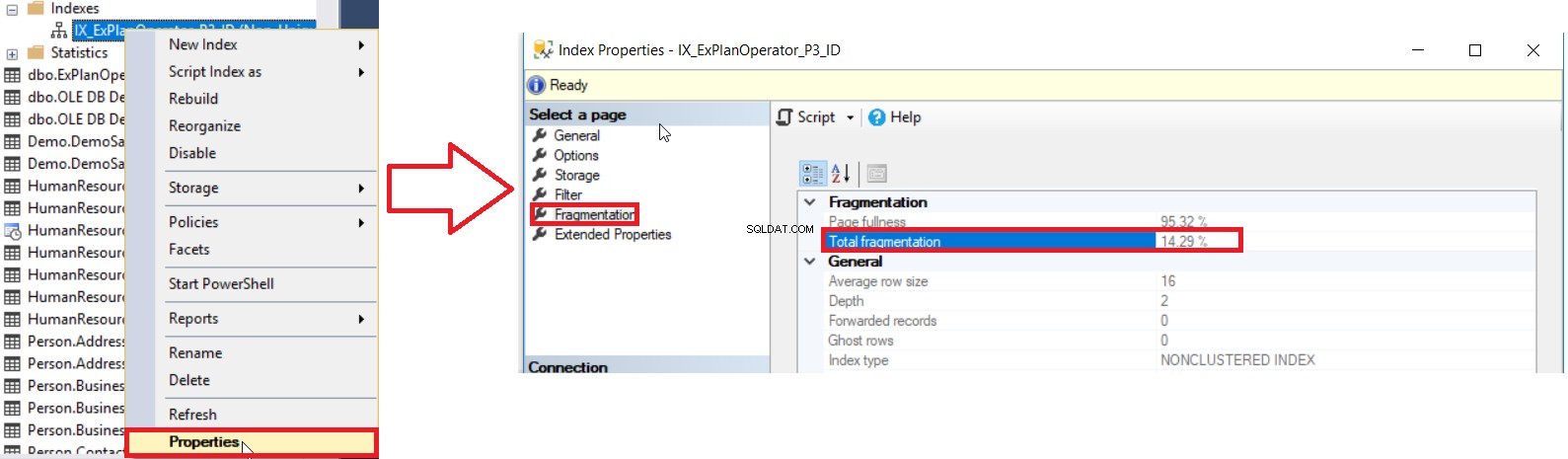
Maar om het fragmentatieniveau van meerdere indexen te controleren, moet u eerst de UI-methodecontrole voor alle indexen één voor één uitvoeren, wat een tijdrovende operatie is. De tweede beschikbare methode om het fragmentatieniveau van alle database-indexen te controleren, is het opvragen van de sys.dm_db_index_physical_stats DMF en deze samen te voegen met de sys.indexes DMV om alle informatie over deze indexen op te halen, rekening houdend met het feit dat deze statistieken worden vernieuwd wanneer de SQL Server-service wordt opnieuw gestart met een query die lijkt op de volgende:
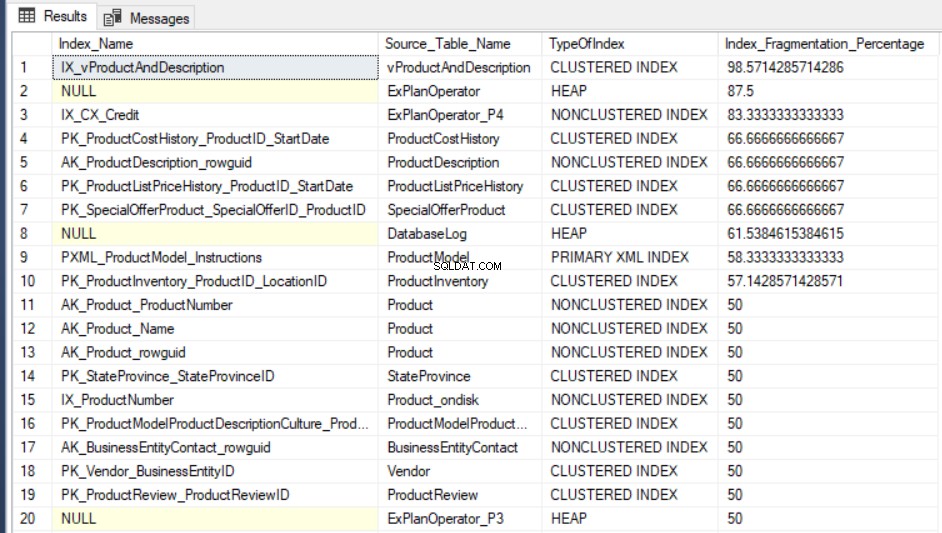
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Het uitvoerresultaat van het opvragen van de AdventureWorks2016CTP3 testdatabase ziet er als volgt uit:
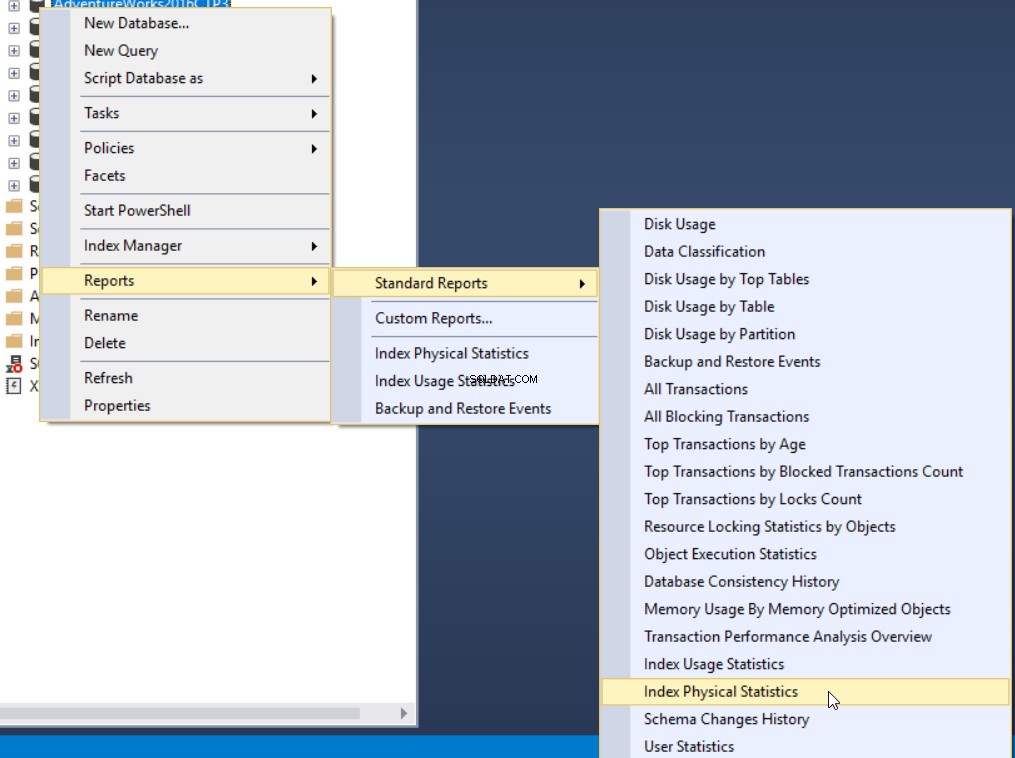
De derde methode om het fragmentatiepercentage te verkrijgen, is het gebruik van het ingebouwde standaardrapport van SQL Server, Index Physical Statistics. Dit rapport geeft nuttige informatie over de indexpartities, het fragmentatiepercentage, het aantal pagina's op elke indexpartitie en aanbevelingen voor het oplossen van het indexfragmentatieprobleem door de index opnieuw op te bouwen of te reorganiseren. Om het rapport te bekijken, klikt u met de rechtermuisknop op uw database, selecteert u de optie Rapporten, Standaardrapporten en selecteert u Fysische statistieken indexeren zoals hieronder:
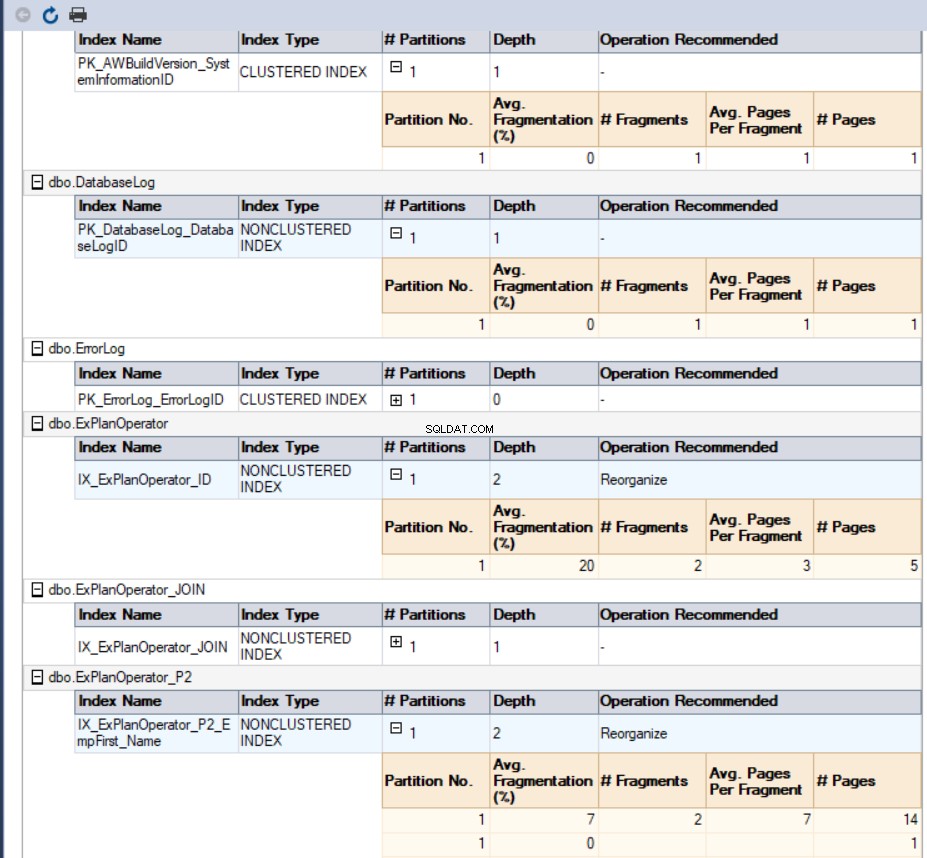
In ons geval ziet het gegenereerde rapport er als volgt uit:
De laatste en gemakkelijkste manier om het fragmentatiepercentage van alle database-indexen op te halen, is de dbForge Index Manager-tool. De dbForge Index Manager tool is een invoegtoepassing die kan worden toegevoegd aan uw SQL Server Management Studio om de indexen van SQL Server-databases te analyseren, waardoor u een zeer nuttig rapport krijgt met de status van de geselecteerde database-indexen en onderhoudssuggesties om deze problemen met indexfragmentatie op te lossen.
Nadat u de invoegtoepassing dbForge Index Manager op uw SSMS hebt geïnstalleerd, kunt u deze uitvoeren door met de rechtermuisknop op de te scannen database te klikken en Index Manager te selecteren. en vervolgens Indexfragmentatie beheren zoals hieronder weergegeven:
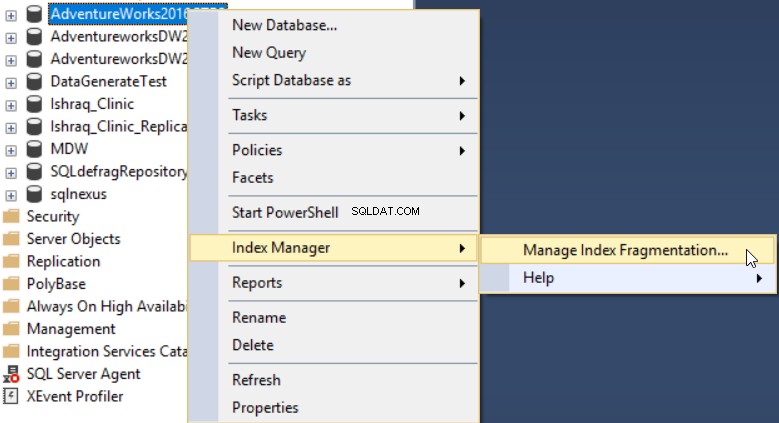
Met de tool dbForge Index Manager kunt u een algemeen beeld krijgen van de fragmentatie van de geselecteerde database-indexen, met aanbevelingen voor de juiste acties om dit probleem op te lossen, zoals hieronder weergegeven:

Met de tool dbForge Index Manager kunt u ook schakelen tussen databases, waardoor u een nieuw rapport krijgt na het scannen van deze database, zoals hieronder weergegeven:
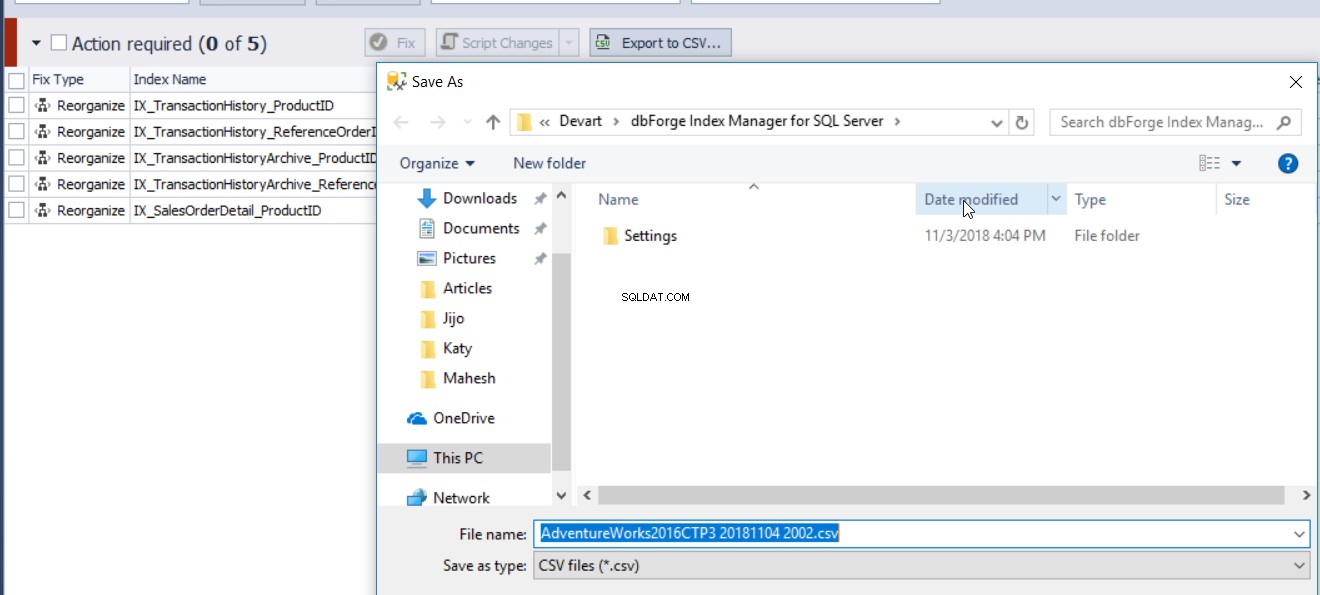
Het indexfragmentatierapport gegenereerd door de dbForge Index Manager-tool kan worden geëxporteerd naar een CSV-bestand om de fragmentatiestatus van de index te analyseren, zoals hieronder weergegeven:
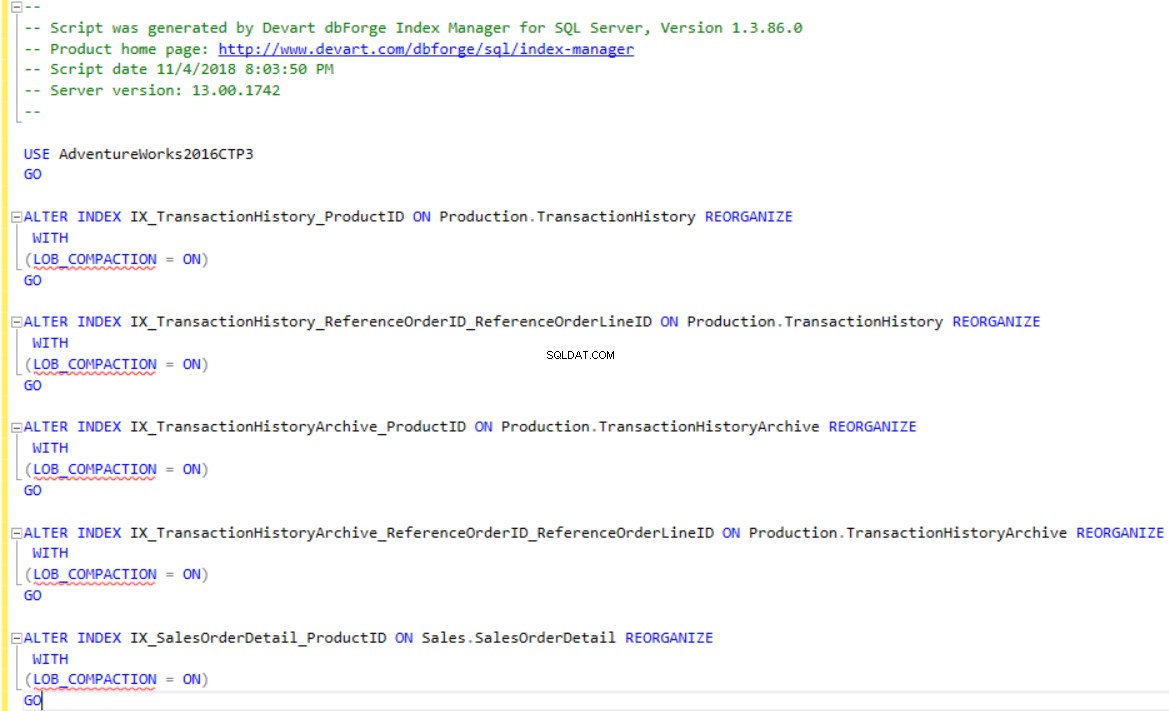
Met dbForge Index Manager kunt u T-SQL-scripts genereren om de indexen opnieuw op te bouwen of te reorganiseren volgens de toolaanbeveling. Gebruik de Scriptwijzigingen optie om het script te tonen of op te slaan voor de indexen die gefragmenteerd zijn, zoals hieronder getoond:
De dbForge Index Manager-tool biedt u de mogelijkheid om het indexfragmentatieprobleem direct op te lossen door op Fix te klikken knop die de aanbevolen actie rechtstreeks op de geselecteerde indexen uitvoert, waarbij de fixatiestatus wordt weergegeven op het Resultaat kolom zoals hieronder getoond:

Als u op Heranalyseren . klikt knop, zal het de indexfragmentatie in de database opnieuw scannen nadat de herstelbewerking met succes is uitgevoerd. Wat hier in dit artikel wordt vermeld, is slechts een inleiding tot hoe de dbForge Index Manager-tool ons zal helpen bij het identificeren en oplossen van problemen met indexfragmentatie. Mijn aanbeveling voor jou is om het te downloaden en te kijken wat deze tool je kan bieden.
Handige links:
- Basisprincipes van de index
- Soorten indexen
- Geclusterde en niet-geclusterde indexen beschreven
- Geclusterde indexstructuren
Handig hulpmiddel:
dbForge Index Manager – handige SSMS-invoegtoepassing voor het analyseren van de status van SQL-indexen en het oplossen van problemen met indexfragmentatie.