Dit artikel is het tweede in een serie over T-SQL-bugs, valkuilen en best practices. Deze keer concentreer ik me op klassieke bugs met subquery's. In het bijzonder behandel ik substitutiefouten en driewaardige logische problemen. Verschillende van de onderwerpen die ik in de serie behandel, werden voorgesteld door collega-MVP's in een discussie die we over het onderwerp hadden. Met dank aan Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man en Paul White voor uw suggesties!
Vervangingsfout
Om de klassieke vervangingsfout te demonstreren, gebruik ik een eenvoudig scenario voor klantenbestellingen. Voer de volgende code uit om een helperfunctie met de naam GetNums te maken en om de tabellen Klanten en Bestellingen te maken en in te vullen:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); Momenteel heeft de tabel Klanten 100 klanten met opeenvolgende klant-ID's in het bereik van 1 tot 100. 98 van die klanten hebben overeenkomstige bestellingen in de tabel Bestellingen. Klanten met ID 17 en 59 hebben nog geen bestellingen geplaatst en zijn daarom niet aanwezig in de tabel Bestellingen.
U zoekt alleen klanten die bestellingen hebben geplaatst en u probeert dit te bereiken met de volgende zoekopdracht (noem het Query 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Je zou 98 klanten terug moeten krijgen, maar in plaats daarvan krijg je alle 100 klanten, inclusief die met ID's 17 en 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Kun je erachter komen wat er mis is?
Om de verwarring nog groter te maken, bekijkt u het plan voor Query 1 zoals weergegeven in Afbeelding 1.
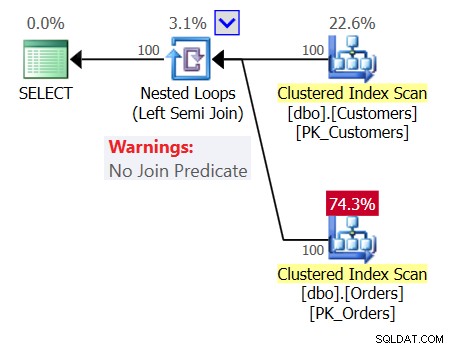 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
Het plan toont een operator voor geneste lussen (links semi-join) zonder join-predikaat, wat betekent dat de enige voorwaarde voor het retourneren van een klant een niet-lege Orders-tabel is, alsof de vraag die u schreef de volgende was:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
U had waarschijnlijk een plan verwacht dat vergelijkbaar is met dat in figuur 2.
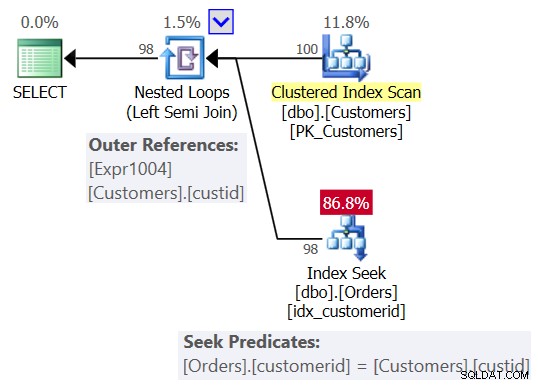 Figuur 2:Verwacht plan voor Query 1
Figuur 2:Verwacht plan voor Query 1
In dit plan zie je een Geneste Loops (Left Semi Join)-operator, met een scan van de geclusterde index op Klanten als de buitenste invoer en een zoekactie in de index op de klant-id-kolom in de Bestellingen als de binnenste invoer. U ziet ook een buitenste referentie (gecorreleerde parameter) op basis van de custid-kolom in Customers, en het seek-predicaat Orders.customerid =Customers.custid.
Dus waarom krijgt u het plan in figuur 1 en niet dat in figuur 2? Als je er nog niet achter bent gekomen, kijk dan goed naar de definities van beide tabellen, met name de kolomnamen, en naar de kolomnamen die in de query worden gebruikt. U zult zien dat de tabel Klanten klant-ID's bevat in een kolom met de naam custid, en dat de tabel Bestellingen klant-ID's bevat in een kolom met de naam klant-ID. De code gebruikt echter custid in zowel de buitenste als de binnenste query's. Aangezien de verwijzing naar custid in de inner query ongekwalificeerd is, moet SQL Server oplossen uit welke tabel de kolom komt. Volgens de SQL-standaard zou SQL Server eerst moeten zoeken naar de kolom in de tabel die in hetzelfde bereik wordt opgevraagd, maar aangezien er geen kolom is met de naam custid in Orders, moet het daarna worden gezocht in de tabel in de buitenste scope, en dit keer is er een match. Dus onbedoeld wordt de verwijzing naar custid impliciet een gecorreleerde verwijzing, alsof u de volgende vraag hebt geschreven:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Op voorwaarde dat Orders niet leeg zijn en dat de buitenste custid-waarde niet NULL is (kan in ons geval niet zijn omdat de kolom is gedefinieerd als NOT NULL), krijgt u altijd een overeenkomst omdat u de waarde met zichzelf vergelijkt . Dus Query 1 wordt het equivalent van:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Als de buitenste tabel NULL's in de custid-kolom zou ondersteunen, zou Query 1 gelijk zijn aan:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Nu begrijp je waarom Query 1 is geoptimaliseerd met het plan in Afbeelding 1 en waarom je alle 100 klanten terug hebt gekregen.
Enige tijd geleden bezocht ik een klant die een soortgelijke bug had, maar helaas met een DELETE-statement. Denk even na wat dit betekent. Alle tabelrijen zijn weggevaagd en niet alleen de rijen die ze oorspronkelijk wilden verwijderen!
Wat betreft best practices die u kunnen helpen dergelijke bugs te voorkomen, zijn er twee belangrijke. Ten eerste, voor zover je het kunt beheersen, zorg ervoor dat je consistente kolomnamen gebruikt in tabellen voor attributen die hetzelfde vertegenwoordigen. Ten tweede, zorg ervoor dat u kolomverwijzingen kwalificeert in subquery's, ook in op zichzelf staande query's waar dit niet gebruikelijk is. Natuurlijk kunt u een tabelalias gebruiken als u liever geen volledige tabelnamen gebruikt. Als u deze praktijk toepast op onze zoekopdracht, stel dat uw eerste poging de volgende code heeft gebruikt:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Hier staat u geen impliciete kolomnaamomzetting toe en daarom genereert SQL Server de volgende fout:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Je gaat de metadata voor de Orders-tabel controleren, realiseert je dat je de verkeerde kolomnaam hebt gebruikt en corrigeert de query (noem deze Query 2), zoals zo:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Deze keer krijg je de juiste output met 98 klanten, exclusief de klanten met ID's 17 en 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
U krijgt ook het verwachte plan dat eerder in figuur 2 is weergegeven.
Even terzijde, het is duidelijk waarom Customers.custid een buitenste referentie (gecorreleerde parameter) is in de operator Nested Loops (Left Semi Join) in figuur 2. Wat minder voor de hand ligt, is waarom Expr1004 ook in het plan wordt weergegeven als een buitenste referentie. Collega SQL Server MVP Paul White theoretiseert dat het te maken kan hebben met het gebruik van informatie uit het blad van de buitenste invoer om de opslagengine te hinten om dubbele inspanningen door de read-ahead-mechanismen te voorkomen. U vindt de details hier.
Driewaardige logische problemen
Een veelvoorkomende bug met betrekking tot subquery's heeft te maken met gevallen waarin de buitenste query het predikaat NOT IN gebruikt en de subquery mogelijk NULL's tussen zijn waarden kan retourneren. Stel bijvoorbeeld dat u bestellingen in onze tabel Bestellingen moet kunnen opslaan met een NULL als klant-ID. Een dergelijk geval zou een bestelling vertegenwoordigen die niet aan een klant is gekoppeld; bijvoorbeeld een bestelling die inconsistenties compenseert tussen de werkelijke productaantallen en de tellingen die in de database zijn vastgelegd.
Gebruik de volgende code om de tabel Orders opnieuw te maken met de custid-kolom die NULL's toestaat, en vul deze voorlopig met dezelfde voorbeeldgegevens als voorheen (met bestellingen op klant-ID's 1 tot 100, met uitzondering van 17 en 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Merk op dat terwijl we toch bezig zijn, ik de best practice heb gevolgd die in de vorige sectie is besproken om consistente kolomnamen in tabellen te gebruiken voor dezelfde attributen, en de kolom in de Orders-tabel custid heb genoemd, net als in de Customers-tabel.
Stel dat u een zoekopdracht moet schrijven die klanten retourneert die geen bestellingen hebben geplaatst. Je bedenkt de volgende simplistische oplossing met behulp van het NOT IN-predikaat (noem het Query 3, eerste uitvoering):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Deze query retourneert de verwachte output met klanten 17 en 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Er wordt een inventarisatie uitgevoerd in het magazijn van het bedrijf en er wordt een inconsistentie gevonden tussen de werkelijke hoeveelheid van een bepaald product en de hoeveelheid die in de database is geregistreerd. U voegt dus een dummy-compensatieorder toe om de inconsistentie te verklaren. Aangezien er geen echte klant aan de bestelling is gekoppeld, gebruikt u een NULL als klant-ID. Voer de volgende code uit om zo'n orderheader toe te voegen:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Voer Query 3 voor de tweede keer uit:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Deze keer krijg je een leeg resultaat:
custid companyname ------- ------------ (0 rows affected)
Het is duidelijk dat er iets mis is. U weet dat klanten 17 en 59 geen bestellingen hebben geplaatst, en ze verschijnen inderdaad in de tabel Klanten, maar niet in de tabel Bestellingen. Toch beweert het zoekresultaat dat er geen klant is die geen bestellingen heeft geplaatst. Kun je erachter komen waar de bug zit en hoe je deze kunt oplossen?
De bug heeft natuurlijk te maken met de NULL in de Orders-tabel. Voor SQL is een NULL een markering voor een ontbrekende waarde die een toepasselijke klant kan vertegenwoordigen. SQL weet niet dat voor ons de NULL een ontbrekende en niet-toepasbare (irrelevante) klant vertegenwoordigt. Voor alle klanten in de tabel Klanten die aanwezig zijn in de tabel Bestellingen, vindt het IN-predikaat een overeenkomst die TRUE oplevert en het NOT IN-gedeelte maakt het een ONWAAR, daarom wordt de klantrij verwijderd. Tot nu toe, zo goed. Maar voor klanten 17 en 59 levert het IN-predikaat UNKNOWN op, aangezien alle vergelijkingen met niet-NULL-waarden FALSE opleveren, en de vergelijking met NULL ONBEKEND. Onthoud dat SQL ervan uitgaat dat de NULL elke toepasselijke klant kan vertegenwoordigen, dus de logische waarde UNKNOWN geeft aan dat het onbekend is of de buitenste klant-ID gelijk is aan de binnenste NULL-klant-ID. ONBEKEND OF ONBEKEND is ONBEKEND. Dan levert het NIET IN-gedeelte toegepast op UNKNOWN nog steeds UNKNOWN op.
In eenvoudiger Engelse termen vroeg je om klanten die geen bestellingen hadden geplaatst terug te sturen. Dus natuurlijk verwijdert de query alle klanten uit de tabel Klanten die aanwezig zijn in de tabel Bestellingen, omdat met zekerheid bekend is dat ze bestellingen hebben geplaatst. Wat de rest betreft (17 en 59 in ons geval) de query verwijdert ze sindsdien naar SQL, net zoals het onbekend is of ze bestellingen hebben geplaatst, het is net zo onbekend of ze geen bestellingen hebben geplaatst, en het filter heeft zekerheid nodig (TRUE) in om een rij te retourneren. Wat een augurk!
Dus zodra de eerste NULL in de tabel Orders komt, krijg je vanaf dat moment altijd een leeg resultaat terug van de NOT IN-query. Hoe zit het met gevallen waarin u geen NULL's in de gegevens hebt, maar de kolom NULL's toestaat? Zoals je bij de eerste uitvoering van Query 3 hebt gezien, krijg je in zo'n geval wel het juiste resultaat. Misschien denkt u dat de toepassing nooit NULL's in de gegevens zal introduceren, dus u hoeft zich nergens zorgen over te maken. Dat is om een aantal redenen een slechte gewoonte. Ten eerste, als een kolom is gedefinieerd om NULL's toe te staan, is het vrijwel zeker dat de NULL's daar uiteindelijk zullen komen, zelfs als dat niet de bedoeling is; het is gewoon een kwestie van tijd. Dit kan het gevolg zijn van het importeren van slechte gegevens, een fout in de toepassing en andere redenen. Ten andere, zelfs als de gegevens geen NULL's bevatten, als de kolom die toestaat, moet de optimizer rekening houden met de mogelijkheid dat NULL's aanwezig zullen zijn wanneer het het queryplan wordt gemaakt, en in onze NOT IN-query leidt dit tot een prestatieverlies . Om dit te demonstreren, moet u het plan voor de eerste uitvoering van Query 3 bekijken voordat u de rij met de NULL toevoegt, zoals weergegeven in afbeelding 3.
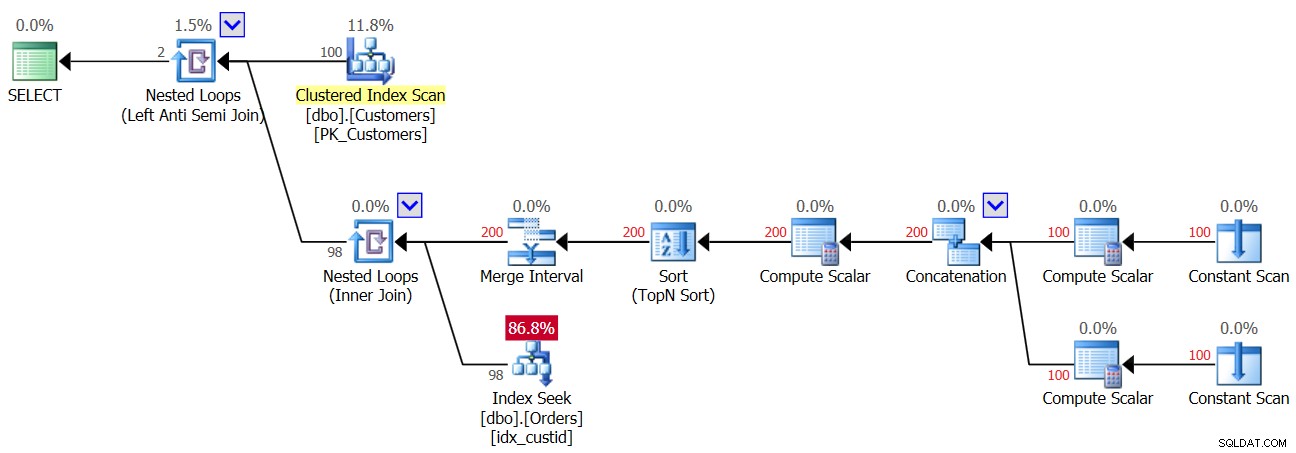 Figuur 3:Plan voor de eerste uitvoering van Query 3
Figuur 3:Plan voor de eerste uitvoering van Query 3
De bovenste geneste lussen-operator handelt de Left Anti Semi Join-logica af. Dat gaat in wezen over het identificeren van non-matches en het kortsluiten van de innerlijke activiteit zodra er een match is gevonden. Het buitenste deel van de lus haalt alle 100 klanten uit de tabel Klanten, vandaar dat het binnenste deel van de lus 100 keer wordt uitgevoerd.
Het binnenste deel van de bovenste lus voert een geneste lussen (Inner Join)-operator uit. Het buitenste deel van de onderste lus maakt twee rijen per klant:een voor een NULL-case en een andere voor de huidige klant-ID, in deze volgorde. Laat u niet verwarren door de operator Merge Interval. Het wordt normaal gesproken gebruikt om overlappende intervallen samen te voegen, bijvoorbeeld een predikaat zoals col1 TUSSEN 20 EN 30 OF col1 TUSSEN 25 EN 35 wordt geconverteerd naar col1 TUSSEN 20 EN 35. Dit idee kan worden gegeneraliseerd om duplicaten in een IN-predikaat te verwijderen. In ons geval kunnen er niet echt duplicaten zijn. In vereenvoudigde termen, zoals gezegd, denk aan het buitenste deel van de lus als het creëren van twee rijen per klant:de eerste voor een NULL-case en de tweede voor de huidige klant-ID. Vervolgens zoekt het binnenste deel van de lus eerst in de index idx_custid op Orders om naar een NULL te zoeken. Als er een NULL wordt gevonden, wordt de tweede zoekactie naar de huidige klant-ID niet geactiveerd (denk aan de kortsluiting die wordt afgehandeld door de bovenste Anti Semi Join-lus). In een dergelijk geval wordt de buitenste klant weggegooid. Maar als er geen NULL wordt gevonden, activeert de onderste lus een tweede zoekactie om de huidige klant-ID in Orders te zoeken. Als het wordt gevonden, wordt de buitenste klant weggegooid. Als het niet wordt gevonden, wordt de buitenste klant geretourneerd. Dit betekent dat wanneer NULL's niet aanwezig zijn in Orders, dit plan twee zoekopdrachten per klant uitvoert! Dit is in het plan te zien als het aantal rijen 200 in de buitenste ingang van de onderste lus. Bijgevolg zijn hier de I/O-statistieken die worden gerapporteerd voor de eerste uitvoering:
Table 'Orders'. Scan count 200, logical reads 603
Het plan voor de tweede uitvoering van Query 3, nadat een rij met een NULL is toegevoegd aan de tabel Orders, wordt weergegeven in figuur 4.
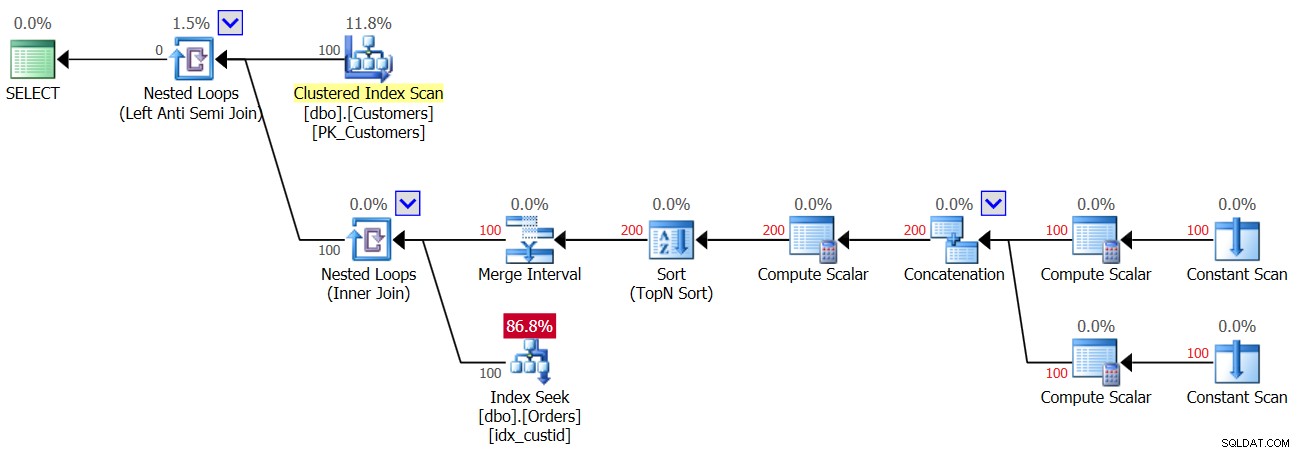 Figuur 4:Plan voor tweede uitvoering van Query 3
Figuur 4:Plan voor tweede uitvoering van Query 3
Aangezien er een NULL in de tabel aanwezig is, vindt voor alle klanten de eerste uitvoering van de Index Seek-operator een overeenkomst, en daarom worden alle klanten weggegooid. Dus ja, we doen maar één zoekopdracht per klant en niet twee, dus deze keer krijg je 100 zoekopdrachten en niet 200; Tegelijkertijd betekent dit echter dat u een leeg resultaat terugkrijgt!
Hier zijn de I/O-statistieken die worden gerapporteerd voor de tweede uitvoering:
Table 'Orders'. Scan count 100, logical reads 300
Een oplossing voor deze taak wanneer NULL's mogelijk zijn tussen de geretourneerde waarden in de subquery, is om deze er eenvoudig uit te filteren, zoals zo (noem het Oplossing 1/Query 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Deze code genereert de verwachte output:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Het nadeel van deze oplossing is dat je eraan moet denken om het filter toe te voegen. Ik geef de voorkeur aan een oplossing met het predikaat NOT BESTAAT, waarbij de subquery een expliciete correlatie heeft waarbij de klant-ID van de bestelling wordt vergeleken met de klant-ID van de klant, zoals (noem het Oplossing 2/Query 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Onthoud dat een op gelijkheid gebaseerde vergelijking tussen een NULL en wat dan ook UNKNOWN oplevert, en dat UNKNOWN wordt weggegooid door een WHERE-filter. Dus als er NULL's bestaan in Orders, worden ze geëlimineerd door het filter van de innerlijke query zonder dat u een expliciete NULL-behandeling hoeft toe te voegen, en daarom hoeft u zich geen zorgen te maken of NULL's wel of niet in de gegevens voorkomen.
Deze query genereert de verwachte output:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
De plannen voor beide oplossingen worden getoond in figuur 5.
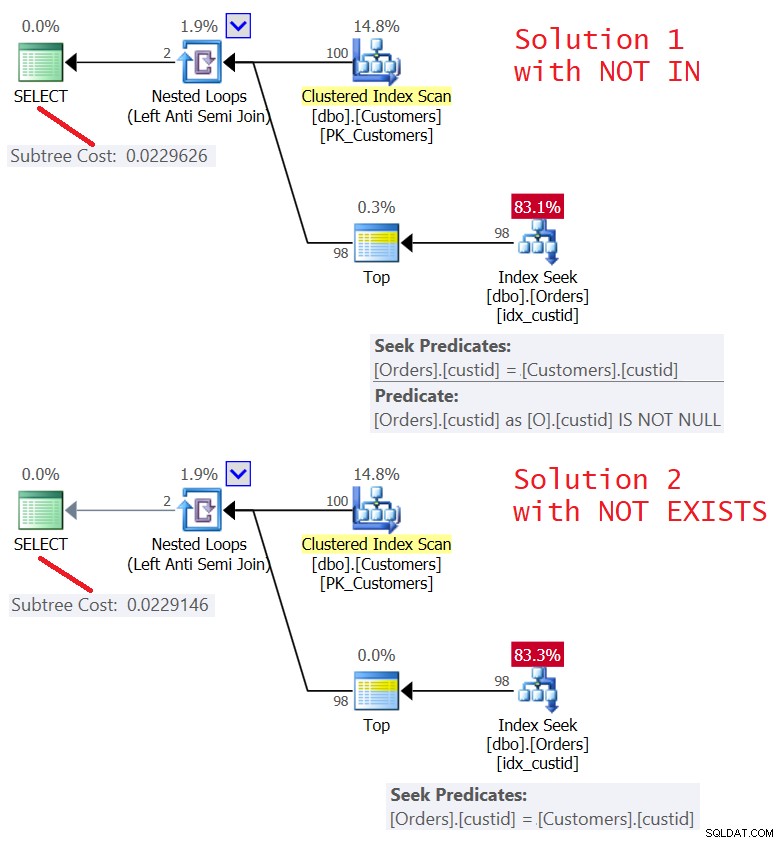 Figuur 5:Plannen voor Query 4 (Oplossing 1) en Query 5 (Oplossing 2 )
Figuur 5:Plannen voor Query 4 (Oplossing 1) en Query 5 (Oplossing 2 )
Zoals je kunt zien zijn de plannen bijna identiek. Ze zijn ook behoorlijk efficiënt, met behulp van een Left Semi Join-optimalisatie met een kortsluiting. Beide voeren slechts 100 zoekacties uit in de index idx_custid op Orders, en met de Top-operator, een kortsluiting toepassen nadat een rij in het blad is aangeraakt.
De I/O-statistieken voor beide zoekopdrachten zijn hetzelfde:
Table 'Orders'. Scan count 100, logical reads 348
Een ding om te overwegen is echter of er een kans is voor de buitenste tabel om NULL's in de gecorreleerde kolom te hebben (custid in ons geval). Het is zeer onwaarschijnlijk dat dit relevant is in een scenario zoals klantenorders, maar kan relevant zijn in andere scenario's. Als dat inderdaad het geval is, verwerken beide oplossingen een buitenste NULL onjuist.
Om dit te demonstreren, laat u de tabel Klanten vallen en maakt u deze opnieuw met een NULL als een van de klant-ID's door de volgende code uit te voeren:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); Oplossing 1 retourneert geen buitenste NULL, ongeacht of er een binnenste NULL aanwezig is of niet.
Oplossing 2 retourneert een buitenste NULL, ongeacht of er een binnenste NULL aanwezig is of niet.
Als u NULL's wilt afhandelen zoals u niet-NULL-waarden afhandelt, d.w.z. de NULL retourneert indien aanwezig in Klanten maar niet in Orders, en deze niet retourneert indien aanwezig in beide, moet u de logica van de oplossing wijzigen om een onderscheid te gebruiken -gebaseerde vergelijking in plaats van een op gelijkheid gebaseerde vergelijking. Dit kan worden bereikt door het EXISTS-predikaat en de EXCEPT set-operator te combineren, zoals zo (noem dit Oplossing 3/Query 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Aangezien er momenteel NULL's zijn in zowel Klanten als Bestellingen, retourneert deze zoekopdracht de NULL niet correct. Dit is de uitvoer van de zoekopdracht:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Voer de volgende code uit om de rij met de NULL uit de tabel Orders te verwijderen en herhaal Oplossing 3:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Aangezien er deze keer een NULL aanwezig is in Klanten maar niet in Bestellingen, bevat het resultaat de NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Het plan voor deze oplossing wordt getoond in figuur 6:
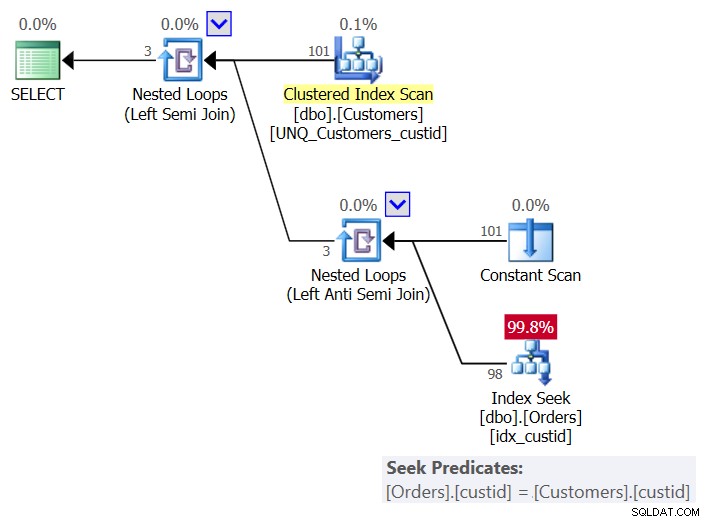 Figuur 6:Plan voor Query 6 (oplossing 3)
Figuur 6:Plan voor Query 6 (oplossing 3)
Per klant gebruikt het plan een Constant Scan-operator om een rij te maken met de huidige klant, en past een enkele zoekopdracht toe in de index idx_custid op Orders om te controleren of de klant bestaat in Orders. Je krijgt uiteindelijk één zoekopdracht per klant. Aangezien we momenteel 101 klanten in de tabel hebben, krijgen we 101 zoekopdrachten.
Dit zijn de I/O-statistieken voor deze query:
Table 'Orders'. Scan count 101, logical reads 415
Conclusie
Deze maand heb ik subquery-gerelateerde bugs, valkuilen en best practices behandeld. Ik behandelde vervangingsfouten en driewaardige logische problemen. Vergeet niet om consistente kolomnamen in tabellen te gebruiken en om kolommen altijd in tabellen te kwalificeren in subquery's, zelfs als het op zichzelf staande query's zijn. Denk er ook aan om een NOT NULL-beperking af te dwingen wanneer de kolom geen NULL's mag toestaan, en om altijd rekening te houden met NULL's wanneer ze mogelijk zijn in uw gegevens. Zorg ervoor dat u NULL's in uw voorbeeldgegevens opneemt wanneer ze zijn toegestaan, zodat u gemakkelijker bugs in uw code kunt ontdekken wanneer u deze test. Wees voorzichtig met het NOT IN predikaat in combinatie met subquery's. Als NULL's mogelijk zijn in het resultaat van de inner query, is het predikaat NOT EXISTS meestal het voorkeursalternatief.