Inleiding
Het bereiken van minimale logboekregistratie met behulp van INSERT...SELECT in een lege geclusterd indexdoel is niet zo eenvoudig als beschreven in de Handleiding voor het laden van gegevensprestaties .
Dit bericht biedt nieuwe details over de vereisten voor minimale logging wanneer het invoegdoel een lege traditionele geclusterde index is. (Het woord "traditioneel" daar sluit columnstore uit en geoptimaliseerd voor geheugen ('Hekaton') geclusterde tabellen). Voor de voorwaarden die gelden wanneer de doeltafel een hoop is, zie het vorige artikel in deze serie.
Samenvatting voor geclusterde tabellen
De Prestatiegids voor het laden van gegevens bevat een samenvatting op hoog niveau van de voorwaarden die vereist zijn voor minimale logging in geclusterde tabellen:
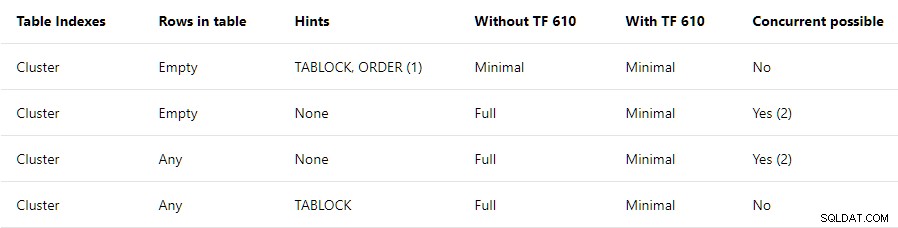
Dit bericht betreft alleen de bovenste rij . Er staat dat TABLOCK en ORDER hints zijn vereist, met een opmerking die zegt:
Als u BULK INSERT gebruikt, moet de bestelhint worden gebruikt.
Leeg doel met Table Lock
De samenvatting bovenste rij suggereert dat alle invoegingen in een lege geclusterde index worden minimaal gelogd zolang TABLOCK en ORDER hints zijn opgegeven. De TABLOCK hint is vereist om de RowSetBulk . in te schakelen faciliteit zoals gebruikt voor bulkladingen op de stapeltafel. Een ORDER hint is vereist om ervoor te zorgen dat rijen aankomen bij de Geclusterde Index Insert planoperator in doelindex sleutelvolgorde . Zonder deze garantie zou SQL Server indexrijen kunnen toevoegen die niet correct zijn gesorteerd, wat niet goed zou zijn.
In tegenstelling tot andere bulklaadmethoden is het niet mogelijk om de vereiste ORDER op te geven hint op een INSERT...SELECT uitspraak. Deze hint is niet hetzelfde zoals het gebruik van een ORDER BY clausule op de INSERT...SELECT uitspraak. Een ORDER BY clausule op een INSERT garandeert alleen de manier waarop een identiteit waarden worden toegewezen, niet de volgorde voor het invoegen van rijen.
Voor INSERT...SELECT , SQL Server maakt zijn eigen besluit of u ervoor wilt zorgen dat rijen worden weergegeven in de geclusterde index-insert operator in volgorde van sleutel of niet. De uitkomst van deze beoordeling is zichtbaar in uitvoeringsplannen via de DMLRequestSort eigenschap van de Invoegen exploitant. De DMLRequestSort eigenschap moet worden ingesteld op true voor INSERT...SELECT in een index om minimaal te loggen . Wanneer het is ingesteld op false , minimale logboekregistratie kan niet plaatsvinden.
Met DMLRequestSort ingesteld op true is de enige aanvaardbare garantie van invoervolgorde voor SQL Server. Men zou het uitvoeringsplan kunnen inspecteren en voorspellen die rijen zouden/zullen/moeten aankomen in geclusterde indexvolgorde, maar zonder de specifieke interne garanties geleverd door DMLRequestSort , die beoordeling telt voor niets.
Wanneer DMLRequestSort is waar , SQL Server mag introduceer een expliciete Sorteren exploitant in het uitvoeringsplan. Als het intern bestellen op andere manieren kan garanderen, kan de Sorteren mag worden weggelaten. Als zowel sorteer- als niet-sorteeralternatieven beschikbaar zijn, maakt de optimizer een op kosten gebaseerde keuze. De kostenanalyse houdt geen rekening met minimale logboekregistratie direct; het wordt aangedreven door de verwachte voordelen van sequentiële I/O en het vermijden van paginasplitsing.
DMLRequestSort-voorwaarden
Beide volgende tests moeten slagen voordat SQL Server ervoor kiest om DMLRequestSort in te stellen tot waar bij het invoegen in een lege geclusterde index met gespecificeerde tabelvergrendeling:
- Een schatting van meer dan 250 rijen aan de invoerzijde van de Geclusterde Index Insert exploitant; en
- Een geschatte gegevensgrootte van meer dan 2 pagina's . De geschatte gegevensgrootte is geen geheel getal, dus een resultaat van 2.001 pagina's zou aan deze voorwaarde voldoen.
(Dit kan u herinneren aan de voorwaarden voor heap minimale logging , maar de vereiste geschatte gegevensgrootte is hier twee pagina's in plaats van acht.)
Berekening gegevensgrootte
De geschatte gegevensgrootte berekening hier is onderhevig aan dezelfde eigenaardigheden als beschreven in het vorige artikel voor hopen, behalve dat de 8-byte RID is niet aanwezig.
Voor SQL Server 2012 en eerder betekent dit 5 extra bytes per rij worden opgenomen in de berekening van de gegevensgrootte:één byte voor een interne bit vlag en vier bytes voor de uniquifier (gebruikt in de berekening, zelfs voor unieke indexen, die geen uniquifier opslaan ).
Voor SQL Server 2014 en later, de uniquifier is correct weggelaten voor uniek indexen, maar de één byte extra voor het interne bit vlag blijft behouden.
Demo
Het volgende script moet worden uitgevoerd op een ontwikkelings-SQL Server-instantie in een nieuwe testdatabase ingesteld om de SIMPLE . te gebruiken of BULK_LOGGED herstelmodel.
De demo laadt 268 rijen in een gloednieuwe geclusterde tabel met behulp van INSERT...SELECT met TABLOCK en rapporten over de gegenereerde transactielogboekrecords.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Als u het script uitvoert op SQL Server 2012 of eerder, wijzigt u de TOP clausule in het script van 268 tot 252, om redenen die zo dadelijk worden uitgelegd.)
De uitvoer laat zien dat alle ingevoegde rijen volledig zijn geregistreerd ondanks de lege doel geclusterde tabel en de TABLOCK hint:
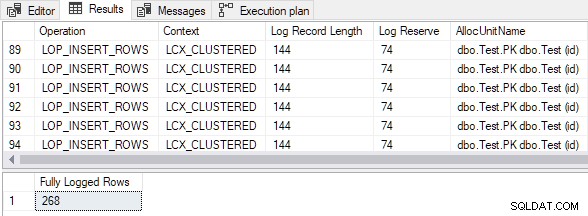
Berekende grootte van invoeggegevens
De eigenschappen van het uitvoeringsplan van de Geclusterde Index Insert operator laat zien dat DMLRequestSort is ingesteld op false . Dit komt omdat, hoewel het geschatte aantal in te voegen rijen meer dan 250 is (voldoende aan de eerste vereiste), de berekende gegevensgrootte doet niet meer dan twee pagina's van 8 KB.
De berekeningsdetails (voor SQL Server 2014 en later) zijn als volgt:
- Totaal vaste lengte kolomgrootte =54 bytes :
- Typ id 104
bit=1 byte (intern). - Typ id 56
integer=4 bytes (idkolom). - Typ id 56
integer=4 bytes (c1kolom). - Typ id 175
char(45)=45 bytes (paddingkolom).
- Typ id 104
- Null-bitmap =3 bytes .
- Rijkoptekst overhead =4 bytes .
- Berekende rijgrootte =54 + 3 + 4 =61 bytes .
- Berekende gegevensgrootte =61 bytes * 268 rijen =16.348 bytes .
- Pagina's met berekende gegevens =16.384 / 8192 =1.99560546875 .
De berekende rijgrootte (61 bytes) verschilt van de werkelijke rijopslaggrootte (60 bytes) door de extra één byte interne metadata die aanwezig is in de invoegstroom. De berekening houdt ook geen rekening met de 96 bytes die op elke pagina worden gebruikt door de paginakoptekst, of andere zaken zoals overhead voor rijversies. Dezelfde berekening op SQL Server 2012 voegt nog eens 4 bytes per rij toe voor de uniquifier (die niet aanwezig is in unieke indexen zoals eerder vermeld). De extra bytes betekenen dat er naar verwachting minder rijen op elke pagina passen:
- Berekende rijgrootte =61 + 4 =65 bytes .
- Berekende gegevensgrootte =65 bytes * 252 rijen =16.380 bytes
- Pagina's met berekende gegevens =16.380 / 8192 =1.99951171875 .
De TOP wijzigen clausule van 268 rijen tot 269 (of van 252 tot 253 voor 2012) maakt de berekening van de verwachte gegevensgrootte slechts tip over de minimumdrempel van 2 pagina's:
- SQL Server 2014
- 61 bytes * 269 rijen =16.409 bytes.
- 16.409 / 8192 =2.0030517578125 pagina's.
- SQL Server 2012
- 65 bytes * 253 rijen =16.445 bytes.
- 16.445 / 8192 =2.0074462890625 pagina's.
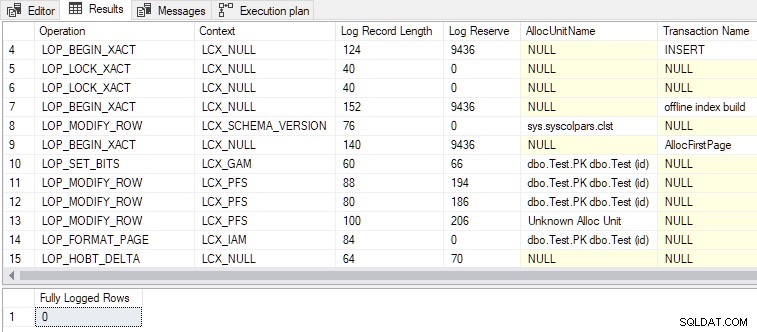
Nu ook aan de tweede voorwaarde is voldaan, DMLRequestSort is ingesteld op waar , en minimale logboekregistratie wordt bereikt, zoals weergegeven in de onderstaande output:
Enkele andere aandachtspunten:
- Er worden in totaal 79 logrecords gegenereerd, vergeleken met 328 voor de volledig gelogde versie. Minder logrecords zijn het verwachte resultaat van minimale logging.
- De
LOP_BEGIN_XACTrecords in de minimaal gelogde records reserveren relatief veel logruimte (elk 9436 bytes). - Een van de transactienamen in de logrecords is “offline index build” . Hoewel we niet hebben gevraagd om een index als zodanig te maken, is het in bulk laden van rijen in een lege index in wezen dezelfde bewerking.
- De volledig geregistreerde insert neemt een exclusief slot op tafelniveau (
Tab-X), terwijl de minimaal gelogde invoegen vergt schemawijziging (Sch-M) net zoals een 'echte' offline indexopbouw doet. - Bulk laden van een lege geclusterde tabel met
INSERT...SELECTmetTABLOCKenDMRequestSortingesteld op true gebruikt deRowsetBulkmechanisme, net als de minimaal gelogde heap load deed in het vorige artikel.
Kardinaliteitsschattingen
Pas op voor lage kardinaliteitsschattingen bij de Geclusterde Index Insert exploitant. Als een van de drempels vereist is om DMLRequestSort in te stellen tot waar niet wordt bereikt vanwege een onnauwkeurige schatting van de kardinaliteit, wordt de invoeging volledig geregistreerd , ongeacht het werkelijke aantal rijen en de totale gegevensgrootte die tijdens de uitvoering zijn aangetroffen.
Bijvoorbeeld het wijzigen van de TOP clausule in het demoscript om een variabele te gebruiken resulteert in een vaste kardinaliteit gissing van 100 rijen, wat lager is dan het minimum van 251 rijen:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Caching plannen
De DMLRequestSort property wordt opgeslagen als onderdeel van het cacheplan. Wanneer een plan in de cache hergebruikt , de waarde van DMLRequestSort is niet herberekend op het moment van uitvoering, tenzij een hercompilatie plaatsvindt. Merk op dat hercompilaties niet plaatsvinden voor TRIVIAL plannen op basis van wijzigingen in statistieken of tabelkardinaliteit.
Een manier om onverwacht gedrag als gevolg van caching te voorkomen, is door een OPTION (RECOMPILE) te gebruiken hint. Dit zorgt voor de juiste instelling voor DMLRequestSort wordt herberekend, ten koste van een compilatie bij elke uitvoering.
Vlag traceren
Het is mogelijk om DMLRequestSort . te forceren in te stellen op true door ongedocumenteerd en niet-ondersteund . in te stellen traceringsvlag 2332, zoals ik schreef in T-SQL-query's optimaliseren die gegevens wijzigen. Helaas doet dit niet invloed op minimale logboekregistratie geschiktheid voor lege geclusterde tabellen — de invoeging moet nog steeds worden geschat op meer dan 250 rijen en 2 pagina's. Deze traceringsvlag heeft invloed op andere minimale logging scenario's, die in het laatste deel van deze serie worden behandeld.
Samenvatting
Bulksgewijs laden van een lege geclusterde index met behulp van INSERT...SELECT hergebruikt de RowsetBulk mechanisme dat wordt gebruikt om stapeltafels in bulk te laden. Dit vereist tafelvergrendeling (normaal bereikt met een TABLOCK hint) en een ORDER hint. Er is geen manier om een ORDER toe te voegen hint naar een INSERT...SELECT uitspraak. Als gevolg hiervan wordt minimale logboekregistratie naar een lege geclusterde tabel vereist dat de DMLRequestSort eigenschap van de Geclusterde Index Insert operator is ingesteld op true . Dit garandeert naar SQL Server die rijen gepresenteerd aan de Invoegen operator arriveert in de volgorde van de doelindexsleutel. Het effect is hetzelfde als bij het gebruik van de ORDER hint beschikbaar voor andere bulk-invoegmethoden zoals BULK INSERT en bcp .
Om DMLRequestSort in te stellen op true , er moet zijn:
- Meer dan 250 rijen geschat in te voegen; en
- Een geschatte gegevensgrootte invoegen van meer dan twee pagina's .
De geschatte gegevensgrootte berekening invoegen niet overeenkomen met het resultaat van vermenigvuldiging van het uitvoeringsplan geschat aantal rijen en geschatte rijgrootte eigenschappen bij de invoer naar de Invoegen exploitant. De interne berekening bevat (ten onrechte) een of meer interne kolommen in de invoegstroom, die niet worden bewaard in de uiteindelijke index. De interne berekening houdt ook geen rekening met paginakoppen of andere overheadkosten zoals rijversiebeheer.
Bij het testen of debuggen van minimale logboekregistratie pas op voor lage kardinaliteitsschattingen en onthoud dat de instelling van DMLRequestSort wordt in de cache opgeslagen als onderdeel van het uitvoeringsplan.
Het laatste deel van deze serie beschrijft de voorwaarden die nodig zijn om minimale logging te bereiken zonder de RowsetBulk . te gebruiken mechanisme. Deze komen rechtstreeks overeen met de nieuwe faciliteiten die zijn toegevoegd onder traceringsvlag 610 aan SQL Server 2008, en vervolgens gewijzigd om standaard ingeschakeld te zijn vanaf SQL Server 2016.