Het ontleden van gegevens uit XML met behulp van XQuery is een routinepraktijk. Om dit zo effectief mogelijk te doen, is er weinig inspanning nodig.
Stel dat we gegevens van het schijfbestand moeten ontleden met de volgende structuur:
<tables> <table name="Accounting" schema="Production" object="Accounting"> <column name="Date" order="3" visible="1" /> <column name="DateFrom" order="5" visible="1" /> <column name="DateTo" order="6" visible="1" /> <column name="Description" order="4" visible="1" /> <column name="DocumentUID" order="1" visible="0" /> <column name="Number" order="2" visible="1" /> <column name="Warehouse" order="7" visible="1" /> </table> </tables>
Gebruik BULK INSERT als u gegevens uit een bestand moet lezen:
SELECT BulkColumn FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x sample xml file
Een voorbeeld xml-bestand is hier.
Houd echter één ding in gedachten... Probeer de gegevens niet rechtstreeks te lezen:
;WITH cte AS
(
SELECT x = CAST(BulkColumn AS XML)
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
)
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM cte
CROSS APPLY x.nodes('tables/table') t(c) Wijs gegevens toe aan een variabele. Op deze manier kunt u een efficiënter uitvoeringsplan krijgen:
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SELECT t.c.value('@name', 'VARCHAR(100)')
FROM @xml.nodes('tables/table') t(c) Vergelijk de resultaten:
Table 'Worktable'. Scan count 0, logical reads 729, physical reads 0, read-ahead reads 0, lob logical reads 62655,... SQL Server Execution Times: CPU time = 1203 ms, elapsed time = 1214 ms. Table 'Worktable'. Scan count 0, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 202,.... SQL Server Execution Times: CPU time = 16 ms, elapsed time = 4 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
Zoals je kunt zien, is de tweede optie aanzienlijk sneller.
Een ander belangrijk kenmerk van SQL Server bij het werken met XQuery is dat het lezen van een bovenliggend element kan leiden tot slechte prestaties. Beschouw het volgende voorbeeld:
SET STATISTICS PROFILE OFF
DECLARE @xml XML
SELECT @xml = BulkColumn
FROM OPENROWSET(BULK 'D:\data.xml', SINGLE_BLOB) x
SET STATISTICS PROFILE ON
SELECT
t.c.value('@name', 'SYSNAME')
, t.c.value('@order', 'INT')
, t.c.value('@visible', 'BIT')
, t.c.value('../@name', 'SYSNAME')
, t.c.value('../@schema', 'SYSNAME')
, t.c.value('../@object', 'SYSNAME')
FROM @xml.nodes('tables/table/*') t(c) Laten we eens kijken naar het werkelijke aantal rijen dat van de operator is ontvangen. De waarde is abnormaal hoog:
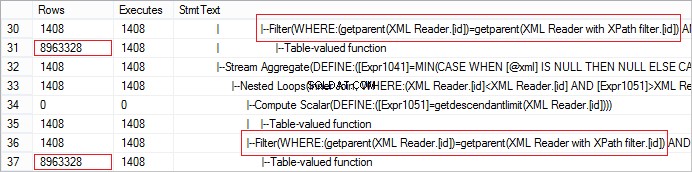
Het verzoek kan eenvoudig worden geoptimaliseerd met CROSS APPLY:
SELECT
t2.c2.value('@name', 'SYSNAME')
, t2.c2.value('@order', 'INT')
, t2.c2.value('@visible', 'BIT')
, t.c.value('@name', 'SYSNAME')
, t.c.value('@schema', 'SYSNAME')
, t.c.value('@object', 'SYSNAME')
FROM @xml.nodes('tables/table') t(c)
CROSS APPLY t.c.nodes('column') t2(c2) Laten we de uitvoeringstijd vergelijken:
(1408 row(s) affected) SQL Server Execution Times: CPU time = 10125 ms, elapsed time = 10135 ms. (1408 row(s) affected) SQL Server Execution Times: CPU time = 78 ms, elapsed time = 156 ms.
Zoals je in het voorbeeld kunt zien, werkt het verzoek met CROSS APPLY direct.
Bedankt voor uw aandacht. Ik hoop dat dit artikel nuttig was. Stel gerust al je vragen, laat je opmerkingen en suggesties over dit artikel achter.