Dit is het tweede deel van een vijfdelige serie die een diepe duik neemt in de manier waarop parallelle plannen in de rijmodus van SQL Server worden opgestart. Tegen het einde van het eerste deel hadden we uitvoeringscontext nul . gemaakt voor de oudertaak. Deze context bevat de volledige boomstructuur van uitvoerbare operators, maar ze zijn nog niet klaar voor het iteratieve uitvoeringsmodel van de queryverwerkingsengine.
Iteratieve uitvoering
SQL Server voert een query uit via een proces dat bekend staat als een queryscan . Initialisatie van het plan begint bij de root door de queryprocessor die Open . aanroept op het hoofdknooppunt. Open oproepen doorkruisen de structuur van iterators recursief roepend Open op elk kind totdat de hele boom is geopend.
Het proces van het retourneren van resultaatrijen is ook recursief, geactiveerd door de queryprocessor die GetRow aanroept. aan de wortel. Elke root-aanroep retourneert een rij per keer. De queryprocessor blijft GetRow aanroepen op het hoofdknooppunt totdat er geen rijen meer beschikbaar zijn. Uitvoering wordt afgesloten met een laatste recursieve Close telefoongesprek. Deze opstelling stelt de queryprocessor in staat om elk willekeurig plan te initialiseren, uit te voeren en af te sluiten door dezelfde interfacemethoden aan te roepen, alleen bij de root.
Om de structuur van uitvoerbare operators te transformeren naar een die geschikt is voor verwerking per rij, voegt SQL Server een queryscan toe wikkel aan elke operator. De query-scan object biedt de Open , GetRow , en Close methoden die nodig zijn voor iteratieve uitvoering.
Het query-scanobject houdt ook statusinformatie bij en onthult andere operatorspecifieke methoden die nodig zijn tijdens de uitvoering. Bijvoorbeeld het query-scanobject voor een opstartfilter-operator (CQScanStartupFilterNew ) onthult de volgende methoden:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
De aanvullende methoden voor deze iterator worden meestal gebruikt in cursorplannen.
De query-scan initialiseren
Het inpakproces heet het initialiseren van de query-scan . Het wordt uitgevoerd door een aanroep van de queryprocessor naar CQueryScan::InitQScanRoot . De bovenliggende taak voert dit proces uit voor het hele plan (opgenomen in uitvoeringscontext nul). Het vertaalproces is zelf recursief van aard, het begint bij de wortel en werkt zich een weg naar beneden in de boom.
Tijdens dit proces is elke operator verantwoordelijk voor het initialiseren van zijn eigen gegevens en het creëren van runtimebronnen het heeft nodig. Dit kan het maken van extra objecten buiten de queryprocessor inhouden, bijvoorbeeld de structuren die nodig zijn om te communiceren met de opslagengine om gegevens op te halen uit permanente opslag.
Een herinnering aan het uitvoeringsplan, met knooppuntnummers toegevoegd (klik om te vergroten):
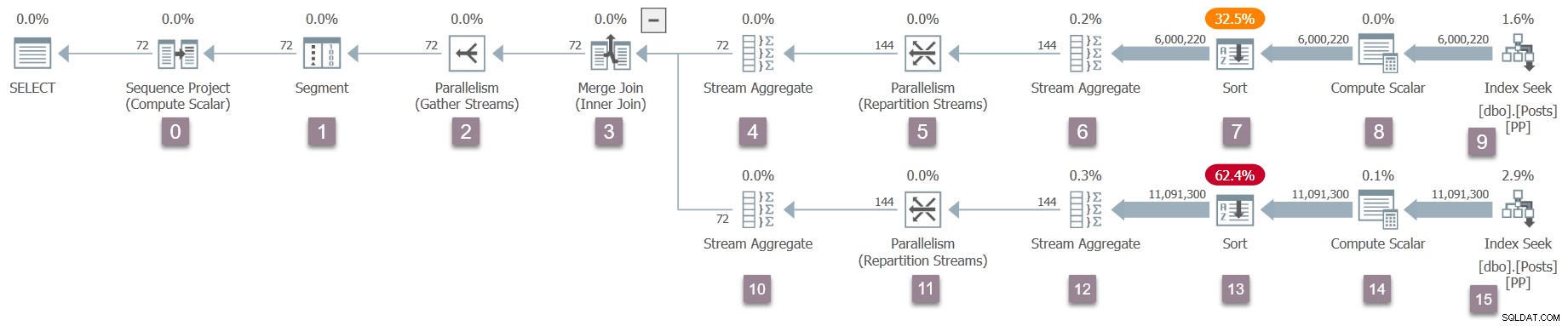
De operator in de root (knooppunt 0) van de uitvoerbare planboom is een sequentieproject . Het wordt vertegenwoordigd door een klasse met de naam CXteSeqProject . Zoals gewoonlijk begint hier de recursieve transformatie.
Query scan wrappers
Zoals gezegd, het CXteSeqProject object is niet uitgerust om deel te nemen aan de iteratieve query scan proces — het heeft niet de vereiste Open , GetRow , en Close methoden. De queryprocessor heeft een wrapper rond de uitvoerbare operator nodig om die interface te bieden.
Om die query-scanwrapper te krijgen, roept de bovenliggende taak CXteSeqProject::QScanGet aan om een object van het type CQScanSeqProjectNew te retourneren . De gekoppelde kaart van de operators die eerder zijn gemaakt, wordt bijgewerkt om te verwijzen naar het nieuwe query-scanobject en de iteratormethoden zijn verbonden met de hoofdmap van het plan.
Het kind van het reeksproject is een segment operator (knooppunt 1). CXteSegment::QScanGet . aanroepen retourneert een query scan wrapper object van het type CQScanSegmentNew . De gekoppelde kaart wordt opnieuw bijgewerkt en iteratorfunctie-aanwijzers zijn verbonden met de bovenliggende sequentieprojectquery-scan.
Een halve uitwisseling
De volgende operator is een collect streams uitwisseling (knooppunt 2). CXteExchange::QScanGet . aanroepen retourneert een CQScanExchangeNew zoals je nu misschien al verwacht.
Dit is de eerste operator in de boom die een significante extra initialisatie moet uitvoeren. Het creëert de consumentenkant van de uitwisseling via CXTransport::CreateConsumerPart . Dit maakt de poort (CXPort ) — een gegevensstructuur in gedeeld geheugen die wordt gebruikt voor synchronisatie en gegevensuitwisseling — en een pijp (CXPipe ) voor pakketvervoer. Merk op dat de producent kant van de uitwisseling is niet gemaakt momenteel. We hebben maar een halve ruil!
Meer verpakking
Het proces van het opzetten van de query processor scan gaat dan verder met de merge join (knooppunt 3). Ik zal niet altijd de QScanGet herhalen en CQScan* belt vanaf dit punt, maar ze volgen het vastgestelde patroon.
De merge join heeft twee kinderen. Het instellen van de queryscan gaat verder zoals voorheen met de buitenste (bovenste) invoer - een stroomaggregaat (knooppunt 4), dan streamt een herpartitie uitwisseling (knooppunt 5). De herverdelingsstromen creëren opnieuw alleen de consumentenkant van de uitwisseling, maar deze keer zijn er twee pijpen gemaakt omdat DOP twee is. De consumentenkant van dit type uitwisseling heeft DOP-verbindingen met de bovenliggende operator (één per thread).
Vervolgens hebben we nog een stroomaggregaat (knooppunt 6) en een sorteer (knooppunt 7). De sortering heeft een onderliggend item dat niet zichtbaar is in uitvoeringsplannen — een rijenset voor opslagengine die wordt gebruikt om morsen naar tempdb te implementeren . De verwachte CQScanSortNew wordt daarom vergezeld door een kind CQScanRowsetNew in de interne boom. Het is niet zichtbaar in showplan-uitvoer.
I/O-profilering en uitgestelde bewerkingen
De sorteer operator is ook de eerste die we tot nu toe hebben geïnitialiseerd en die mogelijk verantwoordelijk is voor I/O . Ervan uitgaande dat de uitvoering I/O-profileringsgegevens heeft aangevraagd (bijvoorbeeld door een 'werkelijk' plan op te vragen), maakt de sortering een object om deze runtime profileringsgegevens vast te leggen via CProfileInfo::AllocProfileIO .
De volgende operator is een bereken scalair (knooppunt 8) genaamd een project intern. De query scan setup-aanroep naar CXteProject::QScanGet doet niet een query-scanobject retourneren, omdat de berekeningen die door deze compute-scalar worden uitgevoerd, uitgesteld zijn naar de eerste bovenliggende operator die het resultaat nodig heeft. In dit plan is die operator de soort. De sortering doet al het werk dat is toegewezen aan de compute scalar, dus het project op knooppunt 8 maakt geen deel uit van de query-scanboom. De compute scalaire wordt echt niet uitgevoerd tijdens runtime. Zie Compute scalars, expressies en uitvoeringsplanprestaties voor meer informatie over uitgestelde compute-scalars.
Parallel scannen
De laatste operator na de compute scalaire op deze tak van het plan is een index seek (CXteRange ) op knooppunt 9. Dit produceert de verwachte query-scanoperator (CQScanRangeNew ), maar het vereist ook een complexe reeks initialisaties om verbinding te maken met de opslagengine en een parallelle scan van de index te vergemakkelijken.
Gewoon de hoogtepunten bedekken, de indexzoekopdracht initialiseren:
- Maakt een profileringsobject voor I/O (
CProfileInfo::AllocProfileIO). - Maakt een parallelle rijenset query-scan (
CQScanRowsetNew::ParallelGetRowset). - Stel een synchronisatie in object om de runtime parallelle bereikscan te coördineren (
CQScanRangeNew::GetSyncInfo). - Maakt de opslagengine tabelcursor en een alleen-lezen transactiebeschrijving .
- Opent de bovenliggende rijenset om te lezen (toegang tot de HoBt en de benodigde vergrendelingen nemen).
- Stelt de time-out voor vergrendeling in.
- Stel prefetching in (inclusief bijbehorende geheugenbuffers).
Profilingoperators voor rijmodus toevoegen
We hebben nu het bladniveau van deze tak van het plan bereikt (de indexzoekopdracht heeft geen kind). Nadat u zojuist het query-scanobject voor de indexzoekopdracht hebt gemaakt, is de volgende stap het inpakken van de query-scan met een profileringsles (ervan uitgaande dat we een echt plan hebben aangevraagd). Dit wordt gedaan door een aanroep van sqlmin!PqsWrapQScan . Merk op dat profilers worden toegevoegd nadat de queryscan is gemaakt, aangezien we de iteratorboom beginnen te beklimmen.
PqsWrapQScan maakt een nieuwe profileringsoperator als een ouder van de index zoeken, via een aanroep van CProfileInfo::GetOrCreateProfileInfo . De profileringsoperator (CQScanProfileNew ) heeft de gebruikelijke methoden voor het scannen van query's. Naast het verzamelen van de gegevens die nodig zijn voor de daadwerkelijke plannen, worden de profileringsgegevens ook weergegeven via de DMV sys.dm_exec_query_profiles .
Als u die DMV op dit precieze moment voor de huidige sessie opvraagt, blijkt dat er slechts één enkele planoperator (knooppunt 9) bestaat (wat betekent dat dit de enige is die wordt omhuld door een profiler):

Deze screenshot toont de volledige resultatenset van de DMV op dit moment (deze is niet bewerkt).
Vervolgens, CQScanProfileNew roept de query prestatiemeter-API aan (KERNEL32!QueryPerformanceCounterStub ) geleverd door het besturingssysteem om de eerste en laatste actieve tijden . te registreren van de geprofileerde operator:

De laatste actieve tijd wordt bijgewerkt met behulp van de API voor het prestatiemeteritem voor query's telkens wanneer code voor die iterator wordt uitgevoerd.
De profiler stelt vervolgens het geschatte aantal rijen in op dit punt in het plan (CProfileInfo::SetCardExpectedRows ), rekening houdend met elk rijdoel (CXte::CardGetRowGoal ). Aangezien dit een parallel plan is, wordt het resultaat gedeeld door het aantal threads (CXte::FGetRowGoalDefinedForOneThread ) en slaat het resultaat op in de uitvoeringscontext.
Het geschatte aantal rijen is niet zichtbaar via de DMV op dit punt, omdat de bovenliggende taak deze operator niet zal uitvoeren. In plaats daarvan zal de schatting per thread later worden weergegeven in parallelle uitvoeringscontexten (die nog niet zijn gemaakt). Desalniettemin wordt het nummer per thread opgeslagen in de profiler van de bovenliggende taak - het is alleen niet zichtbaar via de DMV.
De vriendelijke naam van de planoperator ("Index Seek") wordt vervolgens ingesteld via een aanroep naar CXteRange::GetPhysicalOp :

Voor die tijd is het je misschien opgevallen dat bij het opvragen van de DMV de naam als "???" werd weergegeven. Dit is de permanente naam die wordt getoond voor onzichtbare operators (bijv. geneste lussen prefetch, batch sort) waarvoor geen beschrijvende naam is gedefinieerd.
Ten slotte, index metadata en huidige I/O-statistieken voor de ingepakte index zoeken worden toegevoegd via een aanroep naar CQScanRowsetNew::GetIoCounters :

De tellers zijn op dit moment nul, maar worden bijgewerkt wanneer de indexzoekopdracht I/O uitvoert tijdens de voltooide uitvoering van het plan.
Meer scanverwerking van query's
Met de profileringsoperator die is gemaakt voor het zoeken naar de index, gaat de scanverwerking van query's terug in de boomstructuur naar de bovenliggende sorteer (knooppunt 7).
De sortering voert de volgende initialisatietaken uit:
- Registreert het geheugengebruik met de zoekopdracht geheugenbeheer (
CQryMemManager::RegisterMemUsage) - Berekent het geheugen dat nodig is voor de sorteerinvoer (
CQScanIndexSortNew::CbufInputMemory) en uitvoer (CQScanSortNew::CbufOutputMemory). - De sorteertabel wordt gemaakt, samen met de bijbehorende rijenset voor opslagengine (
sqlmin!RowsetSorted). - Een zelfstandige systeemtransactie (niet begrensd door de gebruikerstransactie) is gemaakt voor het sorteren van spill-schijftoewijzingen, samen met een nep-werktabel (
sqlmin!CreateFakeWorkTable). - De expressieservice wordt geïnitialiseerd (
sqlTsEs!CEsRuntime::Startup) voor de sort-operator om de berekeningen uitgesteld . uit te voeren van de compute scalaire. - Prefetch voor elke sortering wordt gemorst naar tempdb wordt vervolgens aangemaakt via (
CPrefetchMgr::SetupPrefetch).
Ten slotte wordt de sorteerquery-scan ingepakt door een profileringsoperator (inclusief I/O), net zoals we zagen voor de indexzoekopdracht:

Merk op dat de compute scalair (knooppunt 8) ontbreekt van de RDW. Dat komt omdat zijn werk wordt uitgesteld tot de sortering, geen deel uitmaakt van de query-scanstructuur en dus geen omhullend profiler-object heeft.
Omhoog naar de bovenliggende categorie, de stroomaggregaat query scan-operator (knooppunt 6) initialiseert zijn expressies en runtime-tellers (bijvoorbeeld het aantal huidige groepsrijen). Het stroomaggregaat is verpakt met een profileringsoperator, die de begintijden vastlegt:

De bovenliggende repartitie streamt uitwisseling (knooppunt 5) wordt ingepakt door een profiler (onthoud dat alleen de consumentenkant van deze uitwisseling op dit moment bestaat):

Hetzelfde wordt gedaan voor het bovenliggende stroomaggregaat (knooppunt 4), die ook is geïnitialiseerd zoals eerder beschreven:

De query-scanverwerking keert terug naar de bovenliggende join samenvoegen (knooppunt 3) maar initialiseert het nog niet. In plaats daarvan gaan we naar beneden langs de binnenzijde (onder) van de samenvoegverbinding en voeren we dezelfde gedetailleerde taken uit voor die operators (knooppunten 10 tot 15) als voor de bovenste (buitenste) tak:
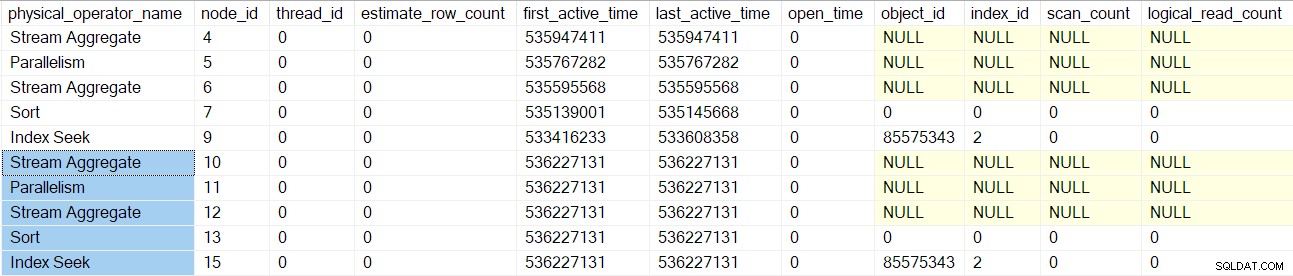
Zodra deze operators zijn verwerkt, wordt de merge-join queryscan wordt gemaakt, geïnitialiseerd en omwikkeld met een profileringsobject. Dit omvat I/O-tellers omdat een veel-veel merge-join een werktabel gebruikt (ook al is de huidige merge-join een-veel):
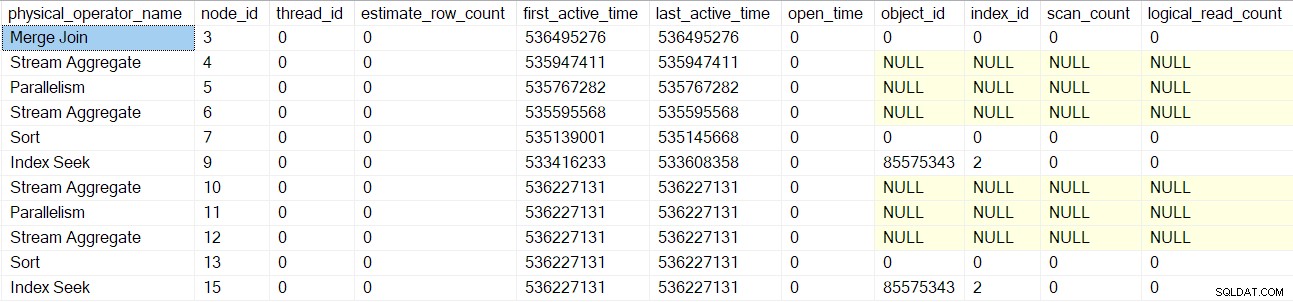
Hetzelfde proces wordt gevolgd voor de bovenliggende verzamelstromen uitwisseling (knooppunt 2) alleen consumentenzijde, segment (knooppunt 1) en sequentieproject (knooppunt 0) operators. Ik zal ze niet in detail beschrijven.
De queryprofielen DMV rapporteren nu een volledige set met profiler verpakte queryscanknooppunten:
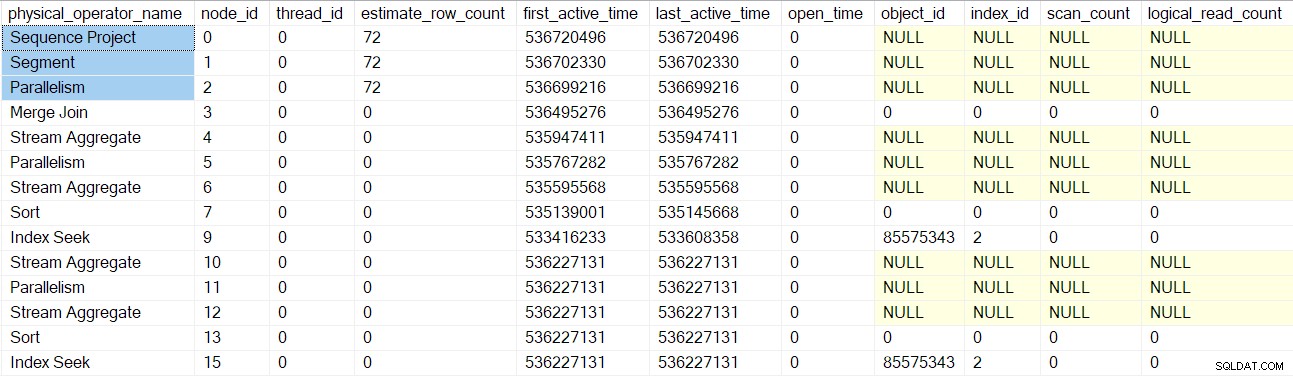
Merk op dat de reeks project-, segment- en verzamelstreams de consument een geschat aantal rijen heeft, omdat deze operators worden uitgevoerd door de bovenliggende taak , niet door aanvullende parallelle taken (zie CXte::FGetRowGoalDefinedForOneThread eerder). De bovenliggende taak heeft geen werk te doen in parallelle takken, dus het concept van het geschatte aantal rijen is alleen zinvol voor aanvullende taken.
De hierboven getoonde actieve tijdwaarden zijn enigszins vervormd omdat ik de uitvoering moest stoppen en bij elke stap DMV-screenshots moest maken. Een afzonderlijke uitvoering (zonder de kunstmatige vertragingen die werden geïntroduceerd door het gebruik van een debugger) leverde de volgende timings op:
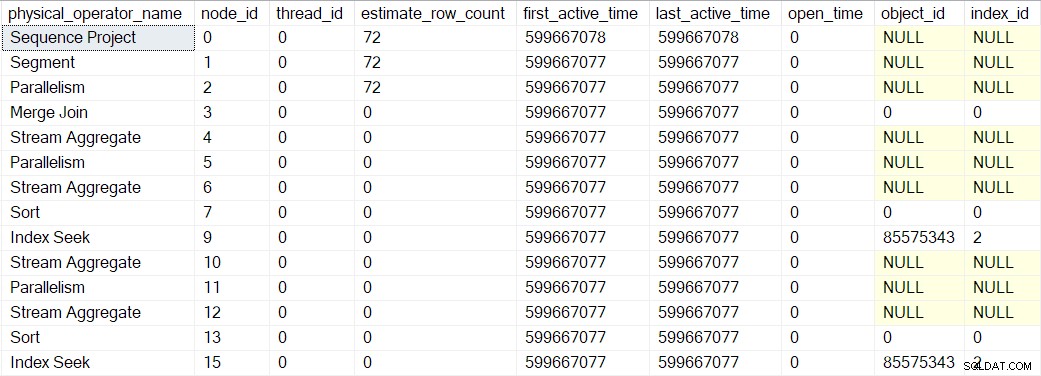
De boom is opgebouwd in dezelfde volgorde als eerder beschreven, maar het proces is zo snel dat er maar 1 microseconde is verschil tussen de actieve tijd van de eerste ingepakte operator (de indexzoekopdracht op knooppunt 9) en de laatste (reeksproject op knooppunt 0).
Einde van deel 2
Het klinkt misschien alsof we veel werk hebben verzet, maar onthoud dat we alleen een query-scanstructuur hebben gemaakt voor de bovenliggende taak , en de beurzen hebben alleen een consumentenkant (nog geen producent). Ons parallelle plan heeft ook maar één thread (zoals weergegeven in de laatste schermafbeelding). In deel 3 zullen onze eerste extra parallelle taken worden gemaakt.