Inleiding
Het kan een moeilijke taak zijn om erachter te komen welk soort database-infrastructuur u nodig hebt om te voldoen aan de prestatie-, betrouwbaarheids- en schaalvereisten van uw toepassingen. De keuzes die u maakt voor uw databasetopologie kunnen van invloed zijn op hoe uw gehele toepassingsstack reageert op verschillende soorten gebruik en voor welke storingsscenario's het kan zijn. Daarom is het belangrijk om uw opties te begrijpen en een weloverwogen beslissing te nemen die aansluit bij uw doelen.
Er zijn veel verschillende manieren om van een enkele database die al uw infrastructuurbehoeften afhandelt, naar complexere systemen te gaan. Daarnaast zijn er veel afwegingen om te overwegen.
In deze handleiding introduceren we enkele van de meest voorkomende patronen voor relationele database-infrastructuur en hoe deze aansluiten bij verschillende gebruikspatronen. We zullen doornemen welke voordelen elke configuratie biedt, evenals enkele van de tekortkomingen waarmee u rekening moet houden. We zullen ook praten over de impact van verschillende beslissingen op de algehele complexiteit van uw operaties. Als je klaar bent, zou je een betere beslissing moeten kunnen nemen over welke ontwerpen het meest geschikt zijn voor je huidige behoeften en met welke opties je misschien wilt experimenteren als je behoeften veranderen.
Verticaal schalen
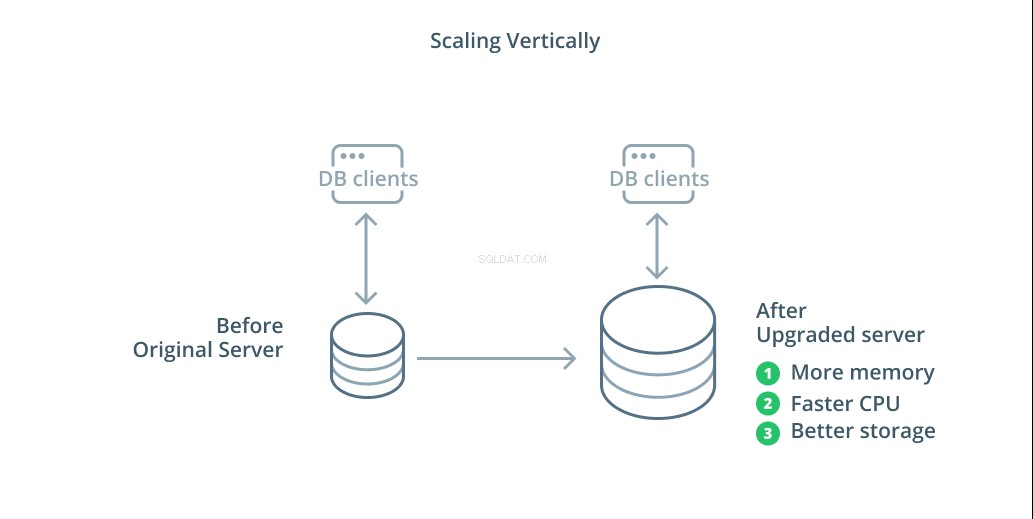
De eenvoudigste manier om een databasesysteem te schalen is verticaal schalen. Verticaal schalen , ook wel opschalen . genoemd , betekent het toevoegen van capaciteit aan de server die uw database beheert. Door de verwerkingskracht, geheugentoewijzing of opslagcapaciteit te vergroten, kunt u de prestaties en het volume verhogen dat een databasesysteem aankan zonder de complexiteit van het systeem als geheel te vergroten.
Als algemene regel geldt dat het opschalen van uw database een goede eerste stap is, omdat het de mogelijkheden van uw database vergroot zonder dat dit gevolgen heeft voor uw infrastructuurtopologie. Opschalen is meestal ook vrij eenvoudig, aangezien een machine met een grotere capaciteit kan worden geconfigureerd als een replicatievolger totdat deze is gesynchroniseerd en vervolgens een failover kan worden geactiveerd om er de nieuwe primaire server van te maken.
Opschalen heeft echter zijn beperkingen omdat de hoeveelheid resources die redelijkerwijs aan één machine kan worden toegewezen, beperkt is. Het vertegenwoordigt ook een single point of failure als er geen replicatievolgers zijn geconfigureerd om het over te nemen wanneer zich problemen voordoen. Deze zorgen worden verholpen door enkele van de andere schaalopties.
Command query responsibility segregation (CQRS) en alleen-lezen replica's
De andere primaire manier om uw database-infrastructuur te schalen, is door uit te schalen. Uitschalen betekent dat u in plaats van de capaciteit van een enkele server te vergroten, het aantal servers vergroot dat is bestemd voor een specifieke behoefte. U voegt dus capaciteit toe door extra machines aan uw infrastructuur toe te voegen.
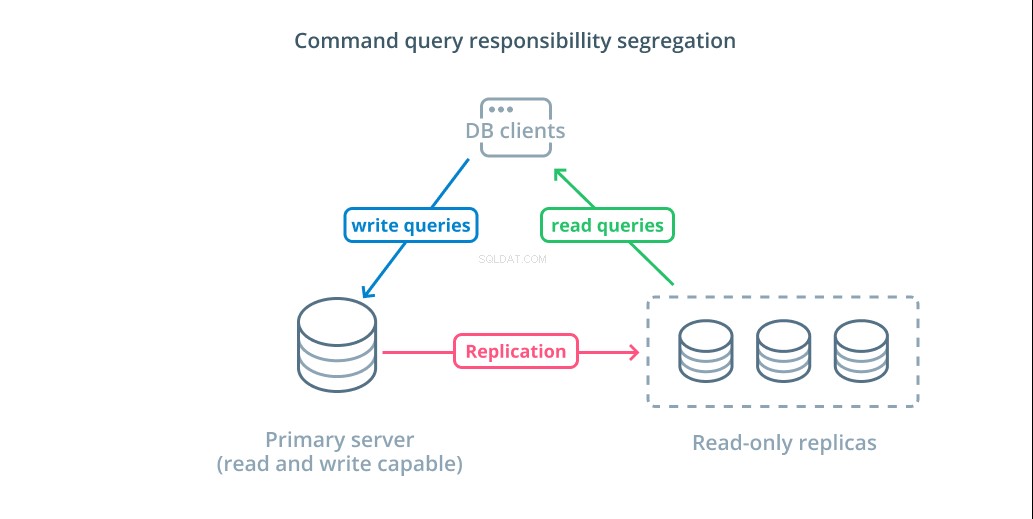
Command query verantwoordelijkheidssegregatie (CQRS) is een term die wordt gebruikt om het toevoegen van logica te beschrijven om query's die gegevens muteren (schrijfquery's) te scheiden van query's die dat niet doen (leesquery's). Dit stelt je in staat om deze verschillende categorieën verzoeken naar verschillende hosts te routeren om de belasting te verdelen.
De meest elementaire infrastructuur om van dit ontwerp te profiteren, is een primaire server die lees- en schrijfquery's kan accepteren in combinatie met een of meer replicaservers die de primaire server volgen die leesquery's kan accepteren. Dit ontwerp is geschikt voor gebruikspatronen van toepassingen die veel lezen vereisen, aangezien leesbewerkingen door alle databaseservers kunnen worden afgehandeld.
Bovendien biedt dit systeem enige redundantie aan uw architectuur, aangezien het systeem nog steeds zal functioneren als een van de servers uitvalt. Als een volger uitvalt, kunnen leesverzoeken naar de andere servers worden gerouteerd. Als de primaire server uitvalt, kan een van de replicavolgers worden gepromoveerd om schrijfquery's te accepteren.
Multi-primaire replicatie
Hoewel het gebruik van CQRS met alleen-lezen replica's u helpt om een groter aantal leesverzoeken aan te pakken, heeft dit geen significante invloed op de schrijfprestaties van uw infrastructuur. Om het aantal schrijfbewerkingen dat uw architectuur aankan te vergroten, moet u overwegen of u een multi-primair replicatieontwerp kunt toepassen.
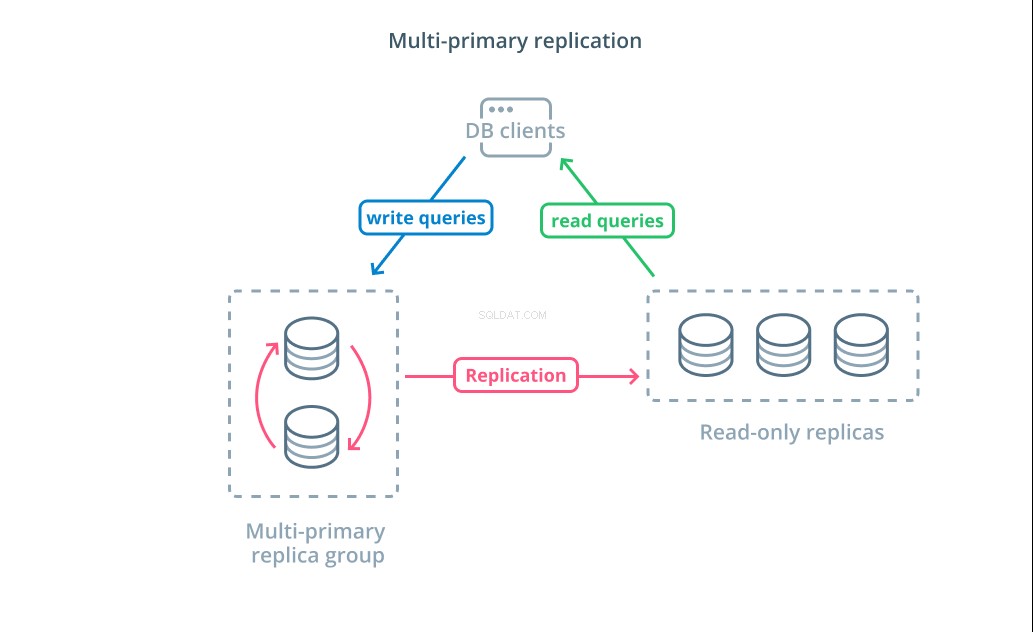
Multi-primaire replicatie is een vorm van replicatie waarbij meerdere servers schrijfverzoeken kunnen accepteren. Sommige systemen zijn zo geconfigureerd dat elke server schrijfverzoeken kan verwerken, terwijl andere zo zijn ontworpen dat een kerngroep van primaire servers schrijfbewerkingen afhandelt met een groter aantal alleen-lezen volgers. Ongeacht de implementatie verhoogt multi-primaire replicatie het aantal servers dat verantwoordelijk is voor schrijfquery's.
Hoewel dit ontwerp in het begin ideaal klinkt, zijn er enkele grote uitdagingen die voorkomen dat dit een algemeen aanvaard patroon is. Hoewel meerdere servers schrijfverzoeken kunnen verwerken, moeten ze nog steeds coördineren om wijzigingen tussen hun servers te repliceren en om conflicten in gegevenswijzigingen op te lossen. Dit kan leiden tot lange reactietijden als conflicten worden onderhandeld of de mogelijkheid van inconsistente gegevens.
Elk systeem kiest zijn eigen aanpak om deze uitdagingen aan te gaan. Dit is een demonstratie van CAP-stelling — een verklaring die de wisselwerking beschrijft tussen consistentie, beschikbaarheid en partitietolerantie in gedistribueerde systemen — in actie. Sommige systemen bieden zwakkere consistentiegaranties om de beschikbaarheid te behouden, terwijl andere databases wijzigingen weigeren als hun peers de transactie niet kunnen coördineren op het moment van schrijven. Het kiezen van de aanpak die het beste bij uw behoeften past, is een belangrijke factor bij het kiezen tussen verschillende implementaties.
Caching van leesquery's
Hoewel het gebruik van alleen-lezen-replica's een manier is om de beschikbare databases te vergroten die kunnen reageren op leesverzoeken, verbetert het de basisqueryprestaties van complexe leesbewerkingen niet. Er wordt nog steeds verwacht dat een van de servers de leesbewerking uitvoert telkens wanneer een verzoek wordt gedaan, zelfs als de resultaten identiek zijn aan de vorige zoekopdracht.
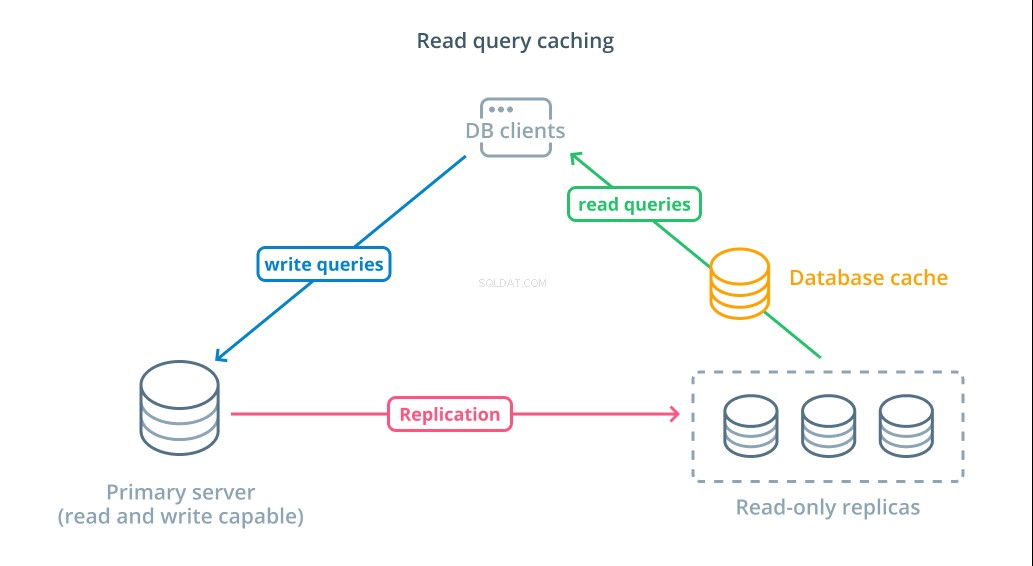
Om de reactietijden te verkorten, een caching voor leesquery's laag kan worden aangebracht. Het toevoegen van een cache tussen uw databaseclients en de databases zelf kan de querytijd voor veelvoorkomende verzoeken aanzienlijk verkorten. De applicatie kan leesresultaten uit de cache opvragen en deze, indien beschikbaar, vrijwel onmiddellijk ontvangen. Voor gevallen waarin de resultaten niet in de cache worden gevonden, worden ze uit de database zelf gehaald en voor de volgende keer aan de cache toegevoegd.
Het op deze manier configureren van caching is ongelooflijk efficiënt voor scenario's waarin het niet waarschijnlijk is dat gegevens elke keer dat het verzoek wordt gedaan, veranderen. Het is vooral handig voor dure leesquery's die meerdere tabellen raadplegen en complexe join-bewerkingen bevatten. Deze resultaten kunnen één keer worden uitgevoerd en vervolgens worden opgeslagen voor toekomstige zoekopdrachten.
In gevallen waarin gegevens sneller veranderen, kan een leescache niet zo veel helpen. Afhankelijk van het geconfigureerde gedrag, bestaat het risico dat caches in deze situaties verouderde gegevens retourneren en doordachte strategieën voor het ongeldig maken van de cache moeten worden geïmplementeerd om verouderde gegevens uit de cache te verwijderen wanneer ze worden gewijzigd.
Data-sharding
Tot nu toe hebben de ontwerpen die we hebben besproken databasecomponenten gesegmenteerd op basis van of ze reageren op schrijfverzoeken of niet. Een andere manier om de verantwoordelijkheid te verdelen, is door de feitelijke gegevensset in meerdere delen op te splitsen.
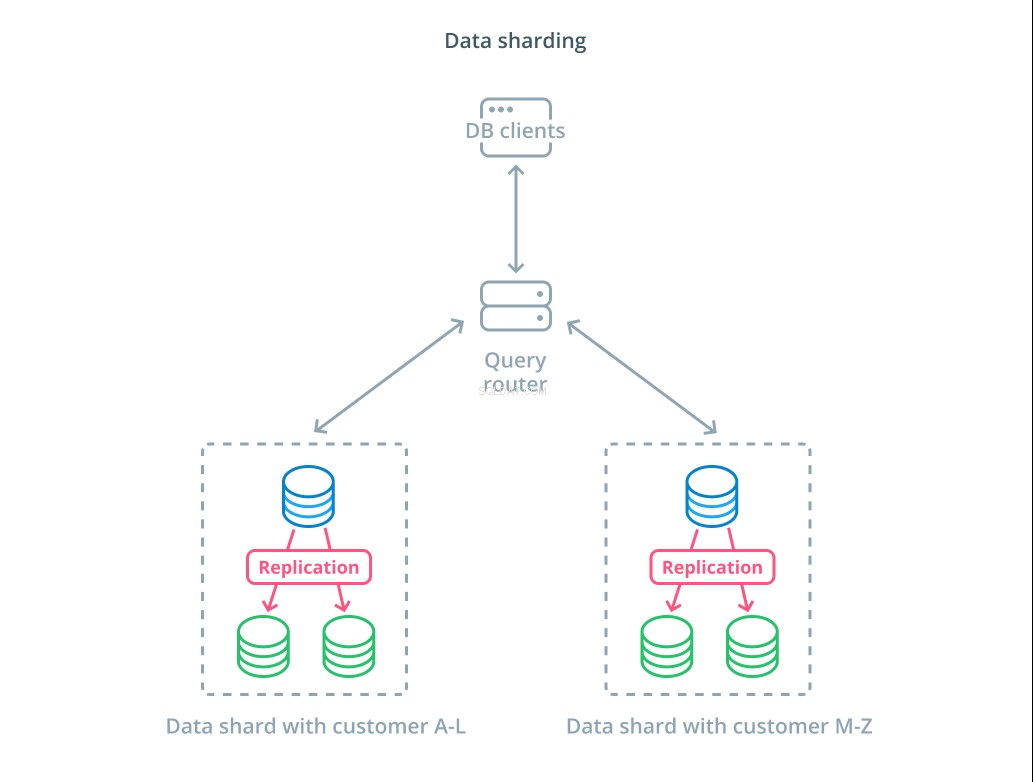
Sharden is het proces van het opsplitsen van een logische dataset in kleinere subsets om het beheer ervan over verschillende machines te verdelen. Elke databaseserver verwerkt slechts een deel van de gegevens en er wordt een routeringsmechanisme geïntroduceerd dat begrijpt welke machines verantwoordelijk zijn voor welke gegevens.
Sharding wordt doorgaans uitgevoerd in scenario's waarin het niet nodig of ongebruikelijk is om de gehele gegevensset tegelijk te gebruiken. De dataset is gesegmenteerd op basis van de waarde van elke record voor een specifieke sleutel, ook wel de sharding-sleutel genoemd. . U kunt bijvoorbeeld handmatig gegevens sharden op basis van de locatie van klanten. U kunt ook automatisch sharden met behulp van een hash-algoritme om te bepalen welke knoop punten welke sleutels moeten verwerken. Dit kan uw systeem helpen om onevenwichtige distributie te voorkomen in gevallen waarin de Shard-sleutelruimte ongelijk verdeeld is.
Sharding introduceert nogal wat complexiteit in datasystemen en is niet geschikt voor alle scenario's. Bewerkingen die interageren met meerdere shards zullen aanzienlijke prestatieboetes ondergaan wanneer ze resultaten van elk lid ophalen. Dit kan gebeuren voor geaggregeerde query's of als de specifieke shardsleutel niet van tevoren bekend is. Bovendien kan ongelijke toewijzing van shards ook leiden tot inefficiënties en knelpunten die moeten worden verholpen door de distributie van de gehele dataset opnieuw in evenwicht te brengen.
Gedecentraliseerd functioneel gegevensbeheer
In plaats van de waarden van een dataset op te splitsen in meerdere segmenten, is het in veel gevallen logischer om verschillende databases voor verschillende functionele doeleinden te gebruiken. Als u bijvoorbeeld een accountservice en een productservice heeft, kan het hebben van speciale databases die samenvallen met elk probleem u helpen om verschillende componenten onafhankelijk van elkaar te schalen.
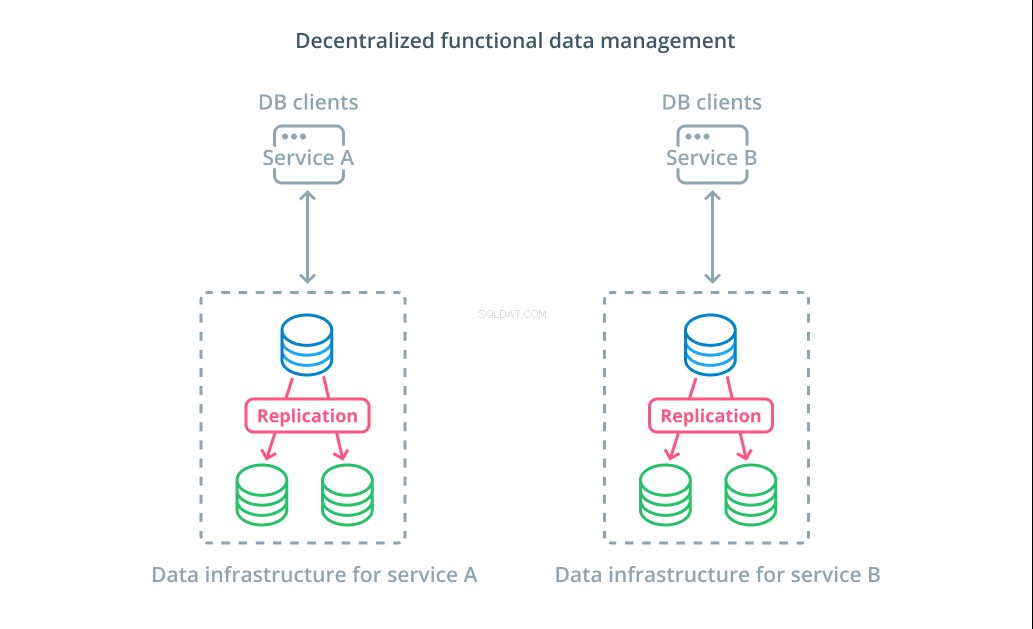
Functioneel gegevensbeheer stelt u in staat uw database-infrastructuur op te splitsen en elk onderdeel te beheren volgens de behoeften van zijn klanten. Elk functioneel onderdeel kan worden geschaald met behulp van de strategie die het meest logisch is. Hiermee kunt u het databaseschema ontwerpen en implementeren op een locatie die het beste past bij de patronen van een specifieke use case, in plaats van dat het de hele organisatie moet dienen.
Voor veel organisaties heeft deze strategie belangrijke voordelen die verder gaan dan de eigenschappen van de eigenlijke systemen. Door gegevensbeheer te decentraliseren, kunnen kleinere teams eigenaar worden van hun eigen gegevens zonder wijzigingen met andere partijen te coördineren. Het sluit goed aan bij de gerichte scheiding van zorgen die wordt gepromoot door microservice-georiënteerde applicatie-architecturen.
Serverloze databases
De verschillende afwegingen die u moet maken en de hoeveelheid infrastructuur die u mogelijk moet beheren voor een juiste opschaling, kan voor veel mensen overweldigend zijn. Een optie om deze complexiteit te ontlasten, is profiteren van databaseservices die de infrastructuur voor u beheren en schalen.
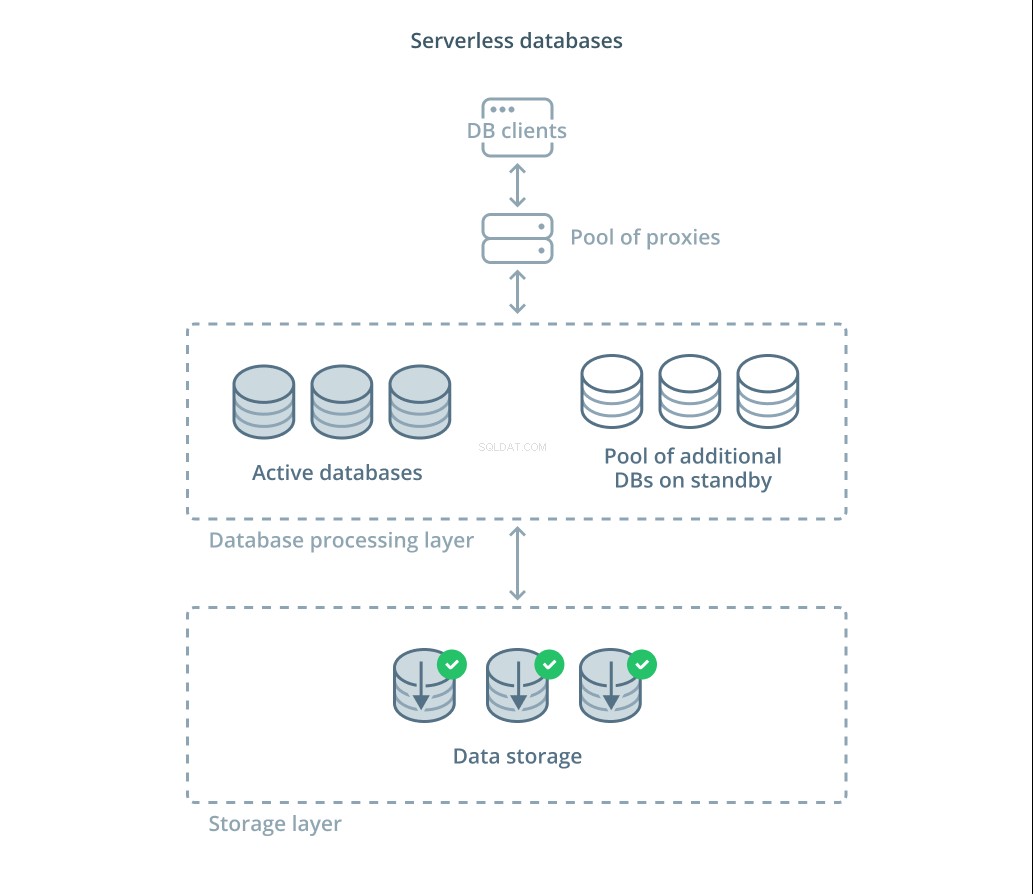
Serverloze databases zijn een categorie services die gegevensopslag loskoppelen van gegevensverwerking om resources gemakkelijk te schalen als reactie op veranderingen in de vraag.
Een gegevensopslaglaag is verantwoordelijk voor het onderhouden van de feitelijke gegevens die door het systeem worden beheerd. Voor deze laag wordt een laag van schaalbare databaseverwerkingseenheden ingezet om de daadwerkelijke queryverwerking op basis van de datasets af te handelen. Het aantal eenheden dat op een bepaald moment actief is, is rechtstreeks gekoppeld aan het huidige gebruik, dus er worden meer middelen toegewezen als de vraag piekt en de verwerkingseenheden worden teruggezet naar stand-by als het rustiger wordt.
Query's worden doorgestuurd naar de databaseprocessors via een routeringsproxy die weet hoe verzoeken naar de actieve knooppunten moeten worden doorgestuurd en wanneer aanvullende bronnen moeten worden aangevraagd.
Serverloze databases hebben veel van dezelfde eigenschappen als traditionele databaseservices die functies voor automatisch schalen implementeren. Beide kunnen capaciteit toewijzen op basis van de vraag. Met serverloze databases kunt u echter de opslagkosten scheiden van de verwerkingskosten en kunt u de verwerking terugschalen naar nul wanneer deze niet nodig is. Bovendien kunnen serverloze oplossingen veel sneller opschalen om aan de vraag te voldoen in vergelijking met de automatische schaling die wordt geboden door traditionele aanbiedingen.
Hoewel serverloze databases voor sommigen misschien geschikt zijn, zijn ze geen wondermiddel. In gevallen waarin de databaseprocessors waren verkleind tot nul, kunnen er opnieuw vertragingen in de verwerking optreden als gevolg van koude starts. Bovendien kan het doorlopen van verbindingen tussen de verschillende componenten in een serverloze databasestack leiden tot extra latentie.
Serverloze databaseplatforms kunnen ook vanuit operationeel oogpunt moeilijk zijn. Implementaties en databasewijzigingen kunnen moeilijker zijn om over te redeneren en te controleren. De lokale ontwikkelomgeving kan ook aanzienlijk verschillen van de productieomgeving vanwege de dynamische status van het databasesysteem. En tot slot, zoals bij elke andere cloudservice, kan het gebruik van serverloze databases u mogelijk in gevaar brengen van vendor lock-in. Het is belangrijk om deze afwegingen te onthouden bij het ontwerpen rond een serverloos platform.
Conclusie
Er zijn veel manieren om uw database-infrastructuur te ontwerpen, te implementeren en te beheren naarmate uw toepassingsvereisten ernstiger worden. Elke oplossing heeft zijn sterke punten en beperkingen die belangrijk zijn om te begrijpen wanneer u probeert een oplossing te vinden die bij uw omgeving past.
Door te leren hoe database-infrastructuur de beschikbaarheid, prestaties en integriteit van uw gegevens beïnvloedt, kunt u kostbare fouten en implementaties vermijden die niet de garanties bieden die u nodig hebt. Als een van de bovenstaande ontwerpen niet aan uw eisen voldoet, kunt u wellicht enkele elementen van verschillende benaderingen combineren om extra voordelen te behalen.
Als je meer wilt weten over de algemene patronen die hierboven worden behandeld, zijn hier enkele aanvullende bronnen die je misschien wilt bekijken:
- Opschalen versus uitschalen
- Command query verantwoordelijkheidssegregatie
- Multi-primaire replicatie
- Leesquery's in cache plaatsen
- Gegevens sharden
- Gedecentraliseerd gegevensbeheer
- Serverloze databases