Spark begon in 2009 als een project binnen het AMPLab aan de University of California, Berkeley. Meer specifiek, het werd geboren uit de noodzaak om het concept van Mesos te bewijzen, dat ook in het AMPLab werd gecreëerd. Spark werd voor het eerst besproken in het Mesos-witboek getiteld Mesos:A Platform for Fine-Grained Resource Sharing in the Data Center, met name geschreven door Benjamin Hindman en Matei Zaharia.
Het kwam naar voren als een snelle en handige oplossing om complexe analyses van grootschalige gegevens uit te voeren. Spark is geëvolueerd als een nieuw verwerkingsraamwerk voor big data dat veel van de tekortkomingen in het MapReduce-model aanpakt. Het ondersteunt grootschalige gegevensanalyse en de gegevens kunnen afkomstig zijn uit verschillende bronnen, zoals realtime, batchverwerking in verschillende formaten zoals afbeeldingen, teksten, grafieken en nog veel meer. Naast de Apache Spark-kern biedt het ook een aantal handige bibliotheken voor big data-analyse.
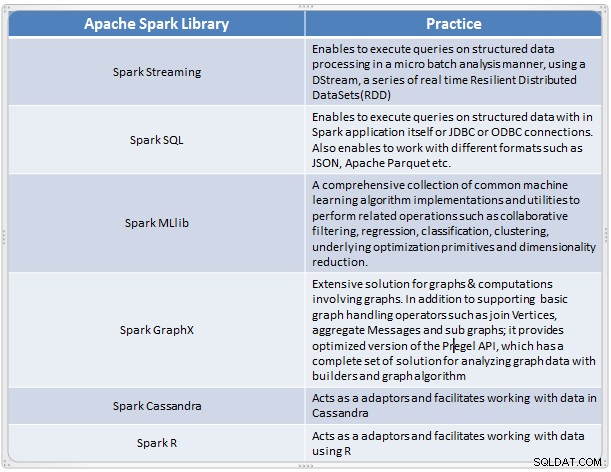
Overzicht van Spark-componenten
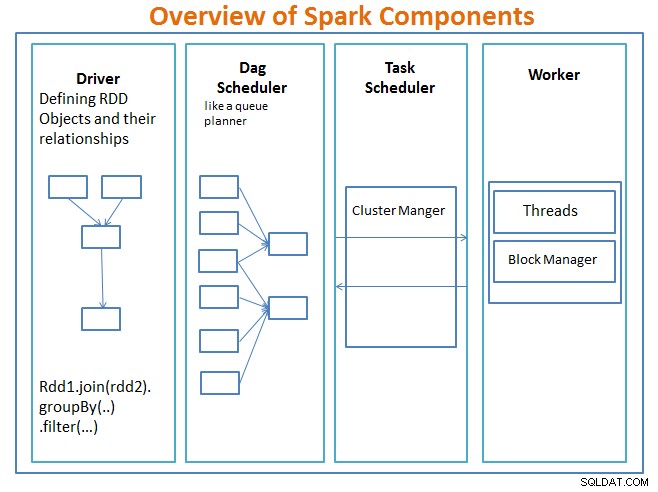
De chauffeur is de code die de hoofdfunctie bevat en de veerkrachtige gedistribueerde datasets (RDD's) en hun transformaties definieert. RDD's zijn de belangrijkste gegevensstructuren die in onze Spark-programma's zullen worden gebruikt.
Parallelle bewerkingen op de RDD's worden verzonden naar de DAG-planner , die de code optimaliseert en tot een efficiënte DAG komt die de gegevensverwerkingsstappen in de applicatie vertegenwoordigt.
De resulterende DAG wordt verzonden naar de clustermanager en de clustermanager heeft informatie over de werknemers, toegewezen threads en de locatie van gegevensblokken en is verantwoordelijk voor het toewijzen van specifieke verwerkingstaken aan werknemers. Het behandelt ook de vergoeding in het geval dat de werknemer faalt. De clustermanager kan YARN, Mesos, Spark's cluster Manager zijn.
De werker ontvangt werkeenheden en gegevens om te beheren en de werknemer voert zijn specifieke taak uit zonder kennis van de hele DAG en de resultaten worden teruggestuurd naar de stuurprogrammatoepassingen.
Spark is, net als andere big data-tools, krachtig, capabel en geschikt voor het aanpakken van een reeks gegevensuitdagingen. Spark is, net als andere big data-technologieën, niet per se de beste keuze voor elke gegevensverwerkingstaak.
In deel 2 bespreken we de basisprincipes van Spark-concepten zoals veerkrachtige gedistribueerde datasets, gedeelde variabelen, SparkContext, transformaties, actie , en Voordelen van het gebruik van Spark samen met voorbeelden en wanneer Spark te gebruiken.
Referentie:
Leer Spark in een dag door Acodemy &Hadoop Applications-architecturen.