Onlangs was ik betrokken bij de ontwikkeling van de functionaliteit die een snelle en frequente overdracht van grote hoeveelheden gegevens naar schijf vereiste. Bovendien moesten deze gegevens van tijd tot tijd van schijf worden gelezen. Daarom was ik voorbestemd om de plaats, de weg en de middelen te ontdekken om deze gegevens op te slaan. In dit artikel zal ik de taak kort bespreken en oplossingen voor het voltooien van deze taak onderzoeken en vergelijken.
Context van de taak :Ik werk in een team dat tools ontwikkelt voor relatieve databaseontwikkeling (SQL Server, MySQL, Oracle). De toolreeks omvat zowel zelfstandige tools als add-ins voor MS SSMS.
Taak :Herstellen van documenten die geopend waren op het moment dat IDE werd afgesloten bij de volgende start van IDE.
Gebruiksvoorbeeld :IDE snel afsluiten voordat u het kantoor verlaat zonder na te denken over welke documenten zijn opgeslagen en welke niet. Bij de volgende start van IDE moeten we dezelfde omgeving krijgen die op het moment van afsluiten was en het werk voortzetten. Alle resultaten van het werk moeten worden bewaard op het moment van wanordelijke sluiting, b.v. tijdens het crashen van een programma of besturingssysteem, of tijdens het uitschakelen.
Taakanalyse :De vergelijkbare functie is aanwezig in webbrowsers. Browsers slaan echter alleen URL's op die uit ongeveer 100 symbolen bestaan. In ons geval moeten we de volledige documentinhoud opslaan. Daarom hebben we een plek nodig om gebruikersdocumenten op te slaan en op te slaan. Bovendien werken gebruikers soms op een andere manier met SQL dan met andere talen. Als ik bijvoorbeeld een C#-klasse van meer dan 1000 rijen lang schrijf, is dat nauwelijks acceptabel. Terwijl in het SQL-universum, naast 10-20-rij-query's, de monsterlijke databasedumps bestaan. Dergelijke dumps kunnen nauwelijks worden bewerkt, wat betekent dat gebruikers hun bewerkingen liever veilig bewaren.
Vereisten voor een opslag:
- Het zou een lichtgewicht embedded oplossing moeten zijn.
- Het moet een hoge schrijfsnelheid hebben.
- Het zou een optie moeten hebben voor de multiprocessing-toegang. Deze vereiste is niet kritisch, omdat we de toegang kunnen garanderen met behulp van de synchronisatieobjecten, maar toch zou het leuk zijn om deze optie te hebben.
Kandidaten
De eerste kandidaat is nogal onhandig, namelijk om alles op te slaan in een map, ergens in AppData.
De tweede kandidaat ligt voor de hand:SQLite, een standaard van embedded databases. Zeer solide en populaire kandidaat.
De derde kandidaat is de LiteDB-database. Het is het eerste resultaat voor de "embedded database for .net"-query in Google.
Eerste gezicht
Bestandssysteem. Bestanden zijn bestanden, ze hebben onderhoud en een juiste naamgeving nodig. Naast de bestandsinhoud moeten we een kleine set eigenschappen opslaan (oorspronkelijk pad op schijf, verbindingsreeks, versie van IDE waarin deze is geopend). Het betekent dat we ofwel twee bestanden voor één document moeten maken, of een formaat moeten bedenken dat eigenschappen en inhoud scheidt.
SQLite is een klassieke relationele database. De database wordt vertegenwoordigd door één bestand op schijf. Dit bestand wordt gebonden aan het databaseschema, waarna we ermee moeten interageren met behulp van de SQL-middelen. We kunnen 2 tabellen maken, een voor eigenschappen en de andere voor inhoud, voor het geval we eigenschappen of inhoud afzonderlijk moeten gebruiken.
LiteDB is een niet-relationele database. Net als bij SQLite wordt de database vertegenwoordigd door een enkel bestand. Het is volledig geschreven in С#. Het heeft een boeiende gebruikseenvoud:we hoeven alleen maar een object aan de bibliotheek te geven, terwijl de serialisatie op zijn eigen manier wordt uitgevoerd.
Prestatietest
Voordat ik code geef, wil ik de algemene conceptie uitleggen en vergelijkingsresultaten geven.
De algemene opvatting is het vergelijken van de snelheid van het schrijven van grote hoeveelheden kleine bestanden naar de database, de gemiddelde hoeveelheid gemiddelde bestanden en een kleine hoeveelheid grote bestanden. De casus met gemiddelde dossiers benadert meestal de echte casus, terwijl zaken met kleine en grote dossiers grensgevallen zijn, waarmee ook rekening moet worden gehouden.
Ik was inhoud aan het schrijven in een bestand met behulp van FileStream met de standaard buffergrootte.
Er was één nuance in SQLite die ik zou willen noemen. We waren niet in staat om alle documentinhoud (zoals ik hierboven al zei, ze kunnen erg groot zijn) in één databasecel te plaatsen. Het punt is dat we voor optimalisatiedoeleinden documenttekst regel voor regel opslaan. Dit betekent dat om tekst in een enkele cel te plaatsen, we alle documenten in een enkele rij moeten plaatsen, wat de hoeveelheid van het gebruikte werkgeheugen zou verdubbelen. De andere kant van het probleem zou zich openbaren tijdens het uitlezen van gegevens uit de database. Daarom was er een aparte tabel in SQLite, waar gegevens rij voor rij werden opgeslagen en gegevens werden gekoppeld met behulp van een externe sleutel waarbij de tabel alleen bestandseigenschappen bevatte. Bovendien slaagde ik erin om de database te versnellen door batchgegevens in te voegen (meerdere duizenden rijen tegelijk) in de UIT-synchronisatiemodus zonder logboekregistratie en binnen één transactie.
LiteDB heeft een object ontvangen met List als eigenschappen en de bibliotheek heeft het zelf op schijf opgeslagen.
Tijdens de ontwikkeling van de testtoepassing begreep ik dat ik de voorkeur geef aan LiteDB. Het punt is dat de testcode voor SQLite meer dan 120 rijen in beslag neemt, terwijl code, die hetzelfde probleem in LiteDb oplost, slechts 20 rijen in beslag neemt.
Gegevens genereren testen
FileStrings.cs
internal class FileStrings {
private static readonly Random random = new Random();
public List Strings {
get;
set;
} = new List();
public int SomeInfo {
get;
set;
}
public FileStrings() {
}
public FileStrings(int id, int minLines, decimal lineIncrement) {
SomeInfo = id;
int lines = minLines + (int)(id * lineIncrement);
for (int i = 0; i < lines; i++) {
Strings.Add(GetString());
}
}
private string GetString() {
int length = 250;
StringBuilder builder = new StringBuilder(length);
for (int i = 0; i < length; i++) { builder.Append(random.Next((int)'a', (int)'z')); } return builder.ToString(); } } Program.cs List files = Enumerable.Range(1, NUM_FILES + 1) .Select(f => new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES))
.ToList();
SQLite
private static void SaveToDb(List files) {
using (var connection = new SQLiteConnection()) {
connection.ConnectionString = @"Data Source=data\database.db;FailIfMissing=False;";
connection.Open();
var command = connection.CreateCommand();
command.CommandText = @"CREATE TABLE files
(
id INTEGER PRIMARY KEY,
file_name TEXT
);
CREATE TABLE strings
(
id INTEGER PRIMARY KEY,
string TEXT,
file_id INTEGER,
line_number INTEGER
);
CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number);
PRAGMA synchronous = OFF;
PRAGMA journal_mode = OFF";
command.ExecuteNonQuery();
var insertFilecommand = connection.CreateCommand();
insertFilecommand.CommandText = "INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();";
insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter());
insertFilecommand.Prepare();
var insertLineCommand = connection.CreateCommand();
insertLineCommand.CommandText = "INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);";
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Prepare();
foreach (var item in files) {
using (var tr = connection.BeginTransaction()) {
SaveToDb(item, insertFilecommand, insertLineCommand);
tr.Commit();
}
}
}
}
private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {
string fileName = Path.Combine("data", item.SomeInfo + ".sql");
insertFileCommand.Parameters[0].Value = fileName;
var fileId = insertFileCommand.ExecuteScalar();
int lineIndex = 0;
foreach (var line in item.Strings) {
insertLinesCommand.Parameters[0].Value = line;
insertLinesCommand.Parameters[1].Value = fileId;
insertLinesCommand.Parameters[2].Value = lineIndex++;
insertLinesCommand.ExecuteNonQuery();
}
} LiteDB
private static void SaveToNoSql(List item) {
using (var db = new LiteDatabase("data\\litedb.db")) {
var data = db.GetCollection("files");
data.EnsureIndex(f => f.SomeInfo);
data.Insert(item);
}
}
De volgende tabel toont gemiddelde resultaten voor verschillende uitvoeringen van de testcode. Tijdens modificaties was de statistische afwijking vrij onmerkbaar.
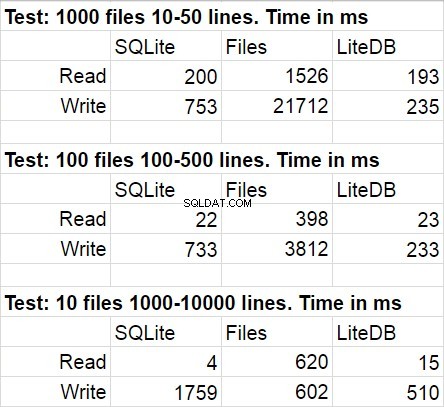
Het verbaasde me niet dat LiteDB won in deze vergelijking. Ik was echter geschokt door de overwinning van LiteDB op bestanden. Na een korte studie van de bibliotheekrepository, ontdekte ik dat pagineel schrijven naar schijf zeer nauwkeurig is geïmplementeerd, maar ik weet zeker dat dit slechts een van de vele prestatietrucs is die daar worden gebruikt. Nog iets waar ik op wil wijzen is dat de snelheid van de toegang tot het bestandssysteem afneemt wanneer het aantal bestanden in de map erg groot wordt.
We hebben LiteDB gekozen voor de ontwikkeling van onze functie en we hebben nauwelijks spijt gehad van deze keuze. Het punt is dat de bibliotheek in native C# is geschreven en als er iets niet helemaal duidelijk was, konden we altijd naar de broncode verwijzen.
Nadelen
Naast de bovengenoemde voordelen van LiteDB in vergelijking met zijn concurrenten, begonnen we tijdens de ontwikkeling nadelen op te merken. De meeste van deze nadelen kunnen worden verklaard door 'jeugd' van de bibliotheek. Nadat we de bibliotheek iets buiten de grenzen van het 'standaard'-scenario begonnen te gebruiken, ontdekten we verschillende problemen (#419, #420, #483, #496). De auteur van de bibliotheek beantwoordde vragen vrij snel en de meeste problemen werden snel opgelost. Nu is er nog maar één taak over (verwar dit niet met de status Gesloten). Dit is een kwestie van de concurrerende toegang. Het lijkt erop dat er ergens diep in de bibliotheek een erg vervelende race-conditie verstopt zit. We hebben deze bug op een heel originele manier overgeslagen (ik ben van plan een apart artikel over dit onderwerp te schrijven).
Ik wil ook de afwezigheid van een nette editor en viewer noemen. Er is LiteDBShell, maar dat is alleen voor echte consolefans.
Samenvatting
We hebben een grote en belangrijke functionaliteit over LiteDB gebouwd en nu werken we aan een andere grote functie waarbij we deze bibliotheek ook zullen gebruiken. Voor degenen die op zoek zijn naar een in-proces database, raad ik aan aandacht te besteden aan LiteDB en aan de manier waarop het zich zal bewijzen in de context van uw taak, aangezien, zoals u weet, als iets voor één taak had gewerkt, het niet per se trainen voor een andere taak.