Soms is het moeilijk om een grote hoeveelheid gegevens in een bedrijf te beheren, vooral met de exponentiële toename van gegevensanalyse en IoT-gebruik. Afhankelijk van de grootte kan deze hoeveelheid gegevens de prestaties van uw systemen beïnvloeden en zult u waarschijnlijk uw databases moeten schalen of een manier moeten vinden om dit op te lossen. Er zijn verschillende manieren om uw PostgreSQL-databases te schalen en een daarvan is Sharding. In deze blog zullen we zien wat Sharding is en hoe je het in PostgreSQL kunt configureren met ClusterControl om de taak te vereenvoudigen.
Wat is sharden?
Sharding is het optimaliseren van een database door gegevens uit een grote tabel te scheiden in meerdere kleine. Kleinere tabellen zijn Shards (of partities). Partitionering en Sharding zijn vergelijkbare concepten. Het belangrijkste verschil is dat sharding impliceert dat de gegevens over meerdere computers zijn verspreid, terwijl partitionering gaat over het groeperen van subsets van gegevens binnen een enkele database-instantie.
Er zijn twee soorten sharding:
-
Horizontale sharding:elke nieuwe tabel heeft hetzelfde schema als de grote tabel, maar heeft unieke rijen. Het is handig wanneer zoekopdrachten de neiging hebben om een subset van rijen te retourneren die vaak bij elkaar zijn gegroepeerd.
-
Vertical Sharding:elke nieuwe tabel heeft een schema dat een subset is van het schema van de oorspronkelijke tabel. Het is handig wanneer zoekopdrachten de neiging hebben om slechts een subset van kolommen van de gegevens te retourneren.
Laten we een voorbeeld bekijken:
Originele tabel
ID
Naam
Leeftijd
Land
1
James Smith
26
VS
2
Mary Johnson
31
Duitsland
3
Robert Williams
54
Canada
4
Jennifer Brown
47
Frankrijk
Verticale sharding
Shard1
Shard2
ID
Naam
Leeftijd
ID
Land
1
James Smith
26
1
VS
2
Mary Johnson
31
2
Duitsland
3
Robert Williams
54
3
Canada
4
Jennifer Brown
47
4
Frankrijk
Horizontale Sharding
Shard1
Shard2
ID
Naam
Leeftijd
Land
ID
Naam
Leeftijd
Land
1
James Smith
26
VS
3
Robert Williams
54
Canada
2
Mary Johnson
31
Duitsland
4
Jennifer Brown
47
Frankrijk
Nu we enkele Sharding-concepten hebben bekeken, gaan we verder met de volgende stap.
Hoe een PostgreSQL-cluster implementeren?
We zullen ClusterControl gebruiken voor deze taak. Als u ClusterControl nog niet gebruikt, kunt u het installeren en uw huidige PostgreSQL-database implementeren of importeren door de optie "Importeren" te selecteren en de stappen volgen om te profiteren van alle ClusterControl-functies zoals back-ups, automatische failover, waarschuwingen, monitoring en meer .
Als u een implementatie wilt uitvoeren vanuit ClusterControl, selecteert u gewoon de optie "Deploy" en volgt u de instructies die worden weergegeven.
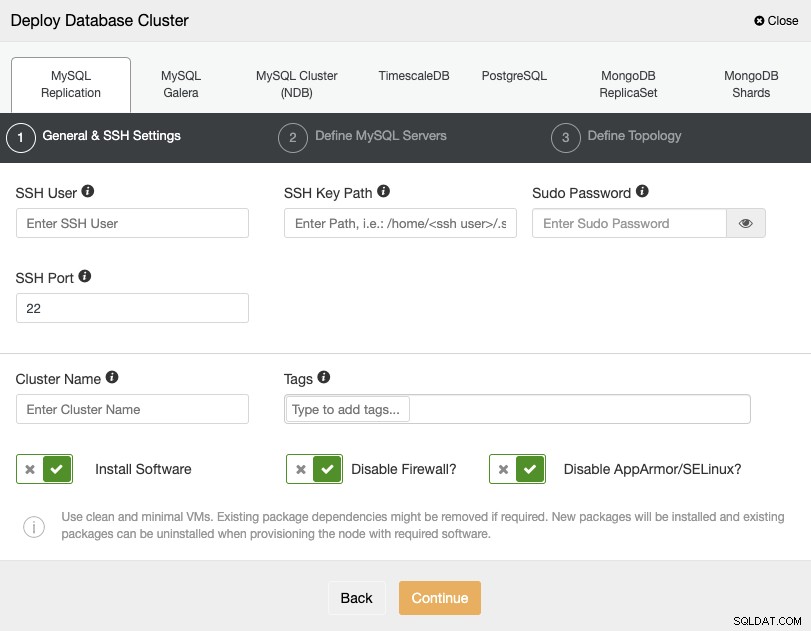
Als u PostgreSQL selecteert, moet u uw gebruiker, sleutel of wachtwoord opgeven en Poort om via SSH verbinding te maken met uw servers. U kunt ook een naam voor uw nieuwe cluster toevoegen en desgewenst kunt u ClusterControl ook gebruiken om de bijbehorende software en configuraties voor u te installeren.
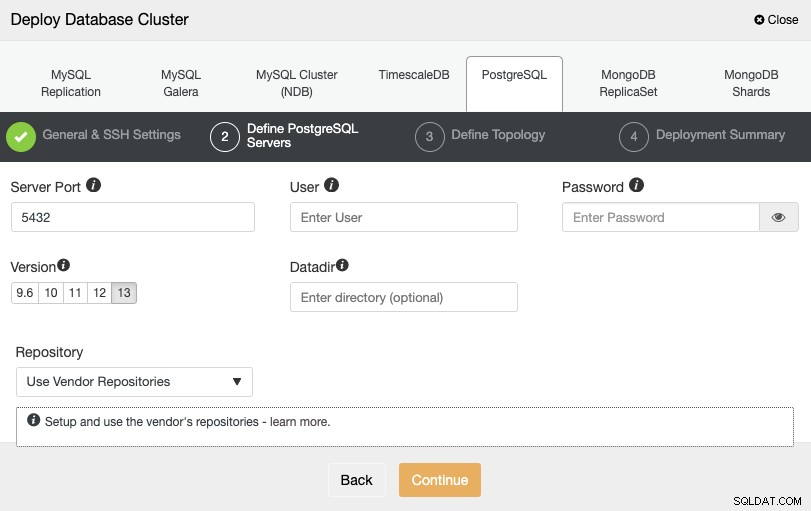
Na het instellen van de SSH-toegangsinformatie, moet u de databasereferenties definiëren , versie en datadir (optioneel). Je kunt ook aangeven welke repository je wilt gebruiken.
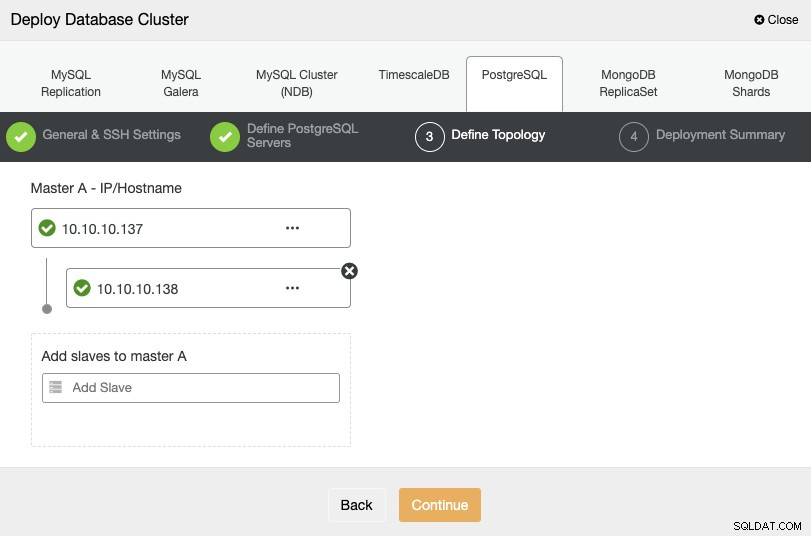
Voor de volgende stap moet u uw servers toevoegen aan het cluster dat u gaat maken met het IP-adres of de hostnaam.
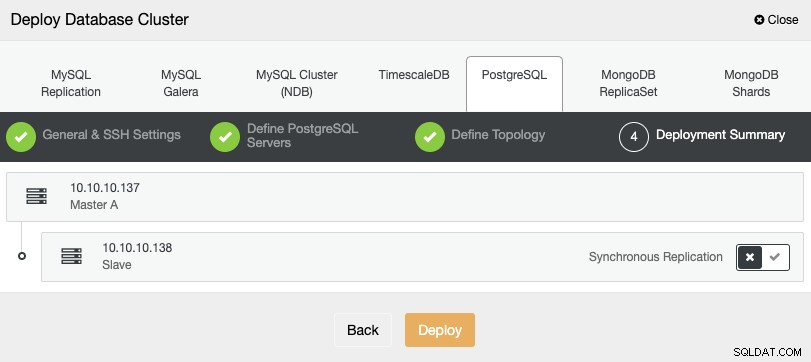
In de laatste stap kunt u kiezen of uw replicatie Synchroon of Asynchroon, en druk dan gewoon op "Deploy".
Zodra de taak is voltooid, ziet u uw nieuwe PostgreSQL-cluster in de hoofdscherm van ClusterControl.

Nu u uw cluster hebt gemaakt, kunt u er verschillende taken op uitvoeren zoals het toevoegen van een load balancer (HAProxy), verbindingspooler (pgBouncer) of een nieuwe replica.
Herhaal het proces om ten minste twee afzonderlijke PostgreSQL-clusters te hebben om Sharding te configureren, wat de volgende stap is.
Hoe PostgreSQL Sharding configureren?
Nu gaan we Sharding configureren met PostgreSQL-partities en Foreign Data Wrapper (FDW). Met deze functionaliteit heeft PostgreSQL toegang tot gegevens die zijn opgeslagen op andere servers. Het is een extensie die standaard beschikbaar is in de algemene PostgreSQL-installatie.
We zullen de volgende omgeving gebruiken:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersOm de FDW-extensie in te schakelen, hoeft u alleen de volgende opdracht op uw hoofdserver uit te voeren, in dit geval Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONLaten we nu de tafel voor klanten maken, gepartitioneerd op geregistreerde datum:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);En de volgende partities:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Deze partities zijn locals. Laten we nu enkele testwaarden invoegen en controleren:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Hier kunt u de hoofdpartitie opvragen om alle gegevens te zien:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Of vraag zelfs de corresponderende partitie:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Zoals je kunt zien, werden de gegevens ingevoegd in verschillende partities, volgens de geregistreerde datum. Laten we nu in het externe knooppunt, in dit geval Shard2, een andere tabel maken:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);U moet deze Shard2-server op deze manier in Shard1 maken:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');En de gebruiker om toegang te krijgen:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Maak nu de BUITENLANDSE TABLE in Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;En laten we gegevens invoegen in deze nieuwe externe tabel van Shard1:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Als alles goed is verlopen, zou u toegang moeten hebben tot de gegevens van zowel Shard1 als Shard2:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Dat is het. Nu gebruikt u Sharding in uw PostgreSQL-cluster.
Conclusie
Partitionering en Sharding in PostgreSQL zijn goede eigenschappen. Het helpt u onder andere als u gegevens in een grote tabel moet scheiden om de prestaties te verbeteren, of zelfs om gegevens op een eenvoudige manier op te schonen. Een belangrijk punt wanneer u Sharding gebruikt, is het kiezen van een goede shardsleutel die de gegevens op de beste manier tussen de knooppunten verdeelt. U kunt ClusterControl ook gebruiken om de PostgreSQL-implementatie te vereenvoudigen en om te profiteren van enkele functies zoals monitoring, waarschuwingen, automatische failover, back-up, herstel op een bepaald tijdstip en meer.