Voor elke nieuwe database die in SQL Server is gemaakt, is de standaardwaarde voor de optie Statistieken automatisch bijwerken ingeschakeld . Ik vermoed dat de meeste DBA's de optie ingeschakeld laten, omdat het de optimizer in staat stelt automatisch statistieken bij te werken wanneer ze ongeldig zijn, en het wordt over het algemeen aanbevolen om het ingeschakeld te laten. Statistieken worden ook bijgewerkt wanneer indexen opnieuw worden opgebouwd, en hoewel het niet ongebruikelijk is dat statistieken goed worden beheerd via de optie voor automatisch bijwerken van statistieken en via indexreconstructies, kan het van tijd tot tijd voor een DBA nodig zijn om een normale taak op te zetten om een statistiek of reeks statistieken.
Aangepast beheer van statistieken omvat vaak de opdracht UPDATE STATISTICS, die redelijk goedaardig lijkt. Het kan worden uitgevoerd voor alle statistieken voor een tabel of geïndexeerde weergave, of voor een specifieke statistiek. De standaardsteekproef kan worden gebruikt, een specifieke steekproeffrequentie of het aantal te samplen rijen kan worden opgegeven, of u kunt dezelfde steekproefwaarde gebruiken die eerder werd gebruikt. Als statistieken worden bijgewerkt voor een tabel of geïndexeerde weergave, kunt u ervoor kiezen om alle statistieken, alleen indexstatistieken of alleen kolomstatistieken bij te werken. En tot slot kunt u de optie voor het automatisch bijwerken van statistieken voor een statistiek uitschakelen.
Voor de meeste DBA's kan de grootste overweging zijn wanneer om de instructie UPDATE STATISTICS uit te voeren. Maar ook DBA's bepalen, al dan niet bewust, de steekproefomvang voor de update. De geselecteerde steekproefomvang kan de prestaties van de daadwerkelijke update beïnvloeden, evenals de prestaties van zoekopdrachten.
De effecten van steekproefomvang begrijpen
De standaard steekproefomvang voor de UPDATE STATISTIEKEN komt van een niet-lineair algoritme en de steekproefomvang neemt af naarmate de tabel groter wordt, zoals Joe Sack aantoonde in zijn bericht, Auto-Update Stats Default Sampling Test. In sommige gevallen is de steekproefomvang mogelijk niet groot genoeg om voldoende interessante informatie vast te leggen, of de juiste informatie, voor het statistische histogram, zoals opgemerkt door Conor Cunningham in zijn bericht Statistieken met steekproefpercentages. Als de standaardsteekproef geen goed histogram oplevert, kunnen DBA's ervoor kiezen om statistieken bij te werken met een hogere steekproeffrequentie, tot aan een FULLSCAN (alle rijen in de tabel of geïndexeerde weergave scannen). Maar zoals Conor in zijn bericht al zei, kost het scannen van meer rijen een prijs, en de DBA staat voor de uitdaging om te beslissen of hij een FULLSCAN moet uitvoeren om te proberen het "beste" histogram te maken, of een kleiner percentage te nemen om de prestatie-impact van te minimaliseren de update.
Om te proberen te begrijpen op welk punt een sample langer duurt dan een FULLSCAN, heb ik de volgende statements vergeleken met kopieën van de SalesOrderDetail-tabel die vergroot waren met het script van Jonathan Kehayias:
| instructie-ID | UPDATE STATISTICS-instructie |
|---|---|
| 1 | UPDATE STATISTIEKEN [Sales].[SalesOrderDetailEnlarged] MET FULLSCAN; |
| 2 | UPDATE STATISTIEKEN [Sales].[SalesOrderDetailEnlarged]; |
| 3 | UPDATE STATISTIEKEN [Sales].[SalesOrderDetailEnlarged] MET VOORBEELD 10 PERCENT; |
| 4 | UPDATE STATISTIEKEN [Sales].[SalesOrderDetailEnlarged] MET VOORBEELD 25 PERCENT; |
| 5 | UPDATE STATISTIEKEN [Sales].[SalesOrderDetailEnlarged] MET VOORBEELD 50 PERCENT; |
| 6 | UPDATE STATISTIEKEN [Sales].[SalesOrderDetailEnlarged] MET VOORBEELD 75 PERCENT; |
Ik had drie exemplaren van de tabel SalesOrderDetailEnlarged, met de volgende kenmerken*:
| Aantal rijen | Aantal pagina's | MAXDOP | Maximum geheugen | Opslag | Machine |
|---|---|---|---|---|---|
| 23.899.449 | 363.284 | 4 | 8 GB | SSD_1 | Laptop |
| 607.312.902 | 7.757.200 | 16 | 54 GB | SSD_2 | Testserver |
| 607.312.902 | 7.757.200 | 16 | 54 GB | 15K | Testserver |
*Aanvullende details over de hardware staan aan het einde van dit bericht.
Alle exemplaren van de tabel hadden de volgende statistieken en geen van de drie indexstatistieken had kolommen:
| Statistieken | Type | Kolommen in sleutel |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Index | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Index | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Index | Product-ID |
| user_CarrierTrackingNumber | Kolom | CarrierTrackingNumber |
Ik heb de bovenstaande UPDATE STATISTICS-statements vier keer uitgevoerd tegen de SalesOrderDetailEnlarged-tabel op mijn laptop en twee keer tegen de SalesOrderDetailEnlarged-tabellen op de TestServer. De instructies werden elke keer in willekeurige volgorde uitgevoerd en de procedure-cache en buffercache werden vóór elke update-instructie gewist. De duur en het tempdb-gebruik voor elke set instructies (gemiddeld) staan in de onderstaande grafieken:
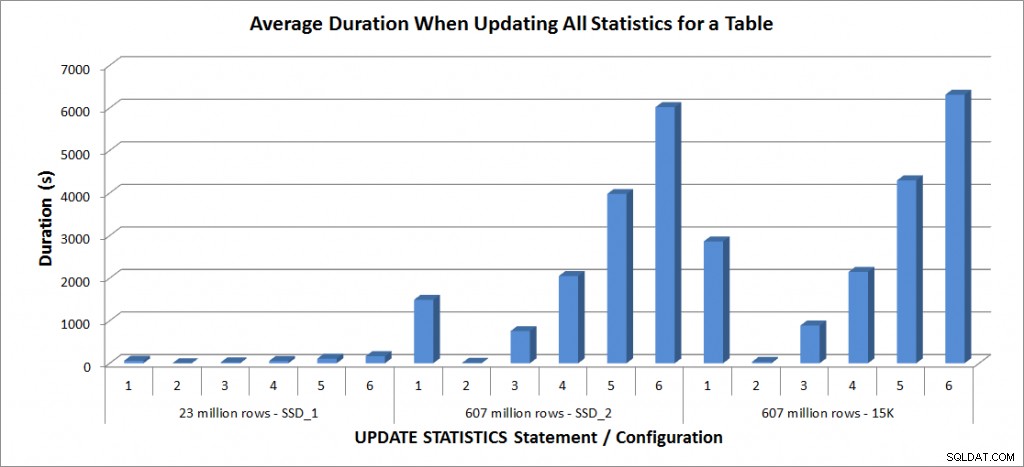
Gemiddelde duur – Update alle statistieken voor SalesOrderDetailEnlarged
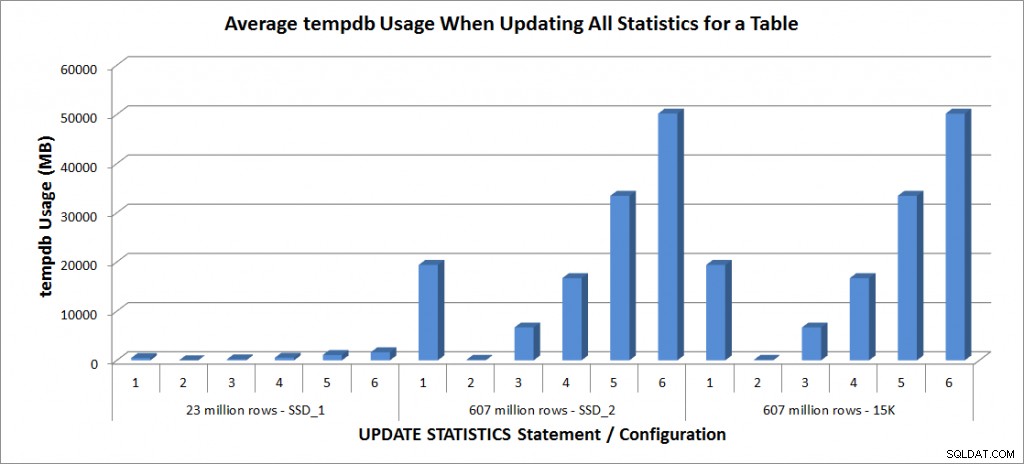
tempdb-gebruik - Alle statistieken voor SalesOrderDetailEnlarged bijwerken
De duur van de tabel met 23 miljoen rijen was allemaal minder dan drie minuten en wordt in de volgende sectie in meer detail beschreven. Voor de tabel op de SSD_2-schijven duurde de FULLSCAN-instructie 1492 seconden (bijna 25 minuten) en de update met een 25%-sample duurde 2051 seconden (meer dan 34 minuten). Op de 15K-schijven duurde de FULLSCAN-instructie daarentegen 2864 seconden (meer dan 47 minuten) en de update met een 25%-sample duurde 2147 seconden (bijna 36 minuten) - minder dan de tijd die de FULLSCAN. De update met een steekproef van 50% duurde echter 4296 seconden (meer dan 71 minuten).
Het gebruik van Tempdb is veel consistenter, vertoont een gestage toename naarmate de steekproef groter wordt, en gebruikt meer tempdb-ruimte dan een FULLSCAN ergens tussen 25% en 50%. Wat hier opvalt, is dat UPDATE STATISTIEKEN doet gebruik tempdb, wat belangrijk is om te onthouden wanneer u de grootte van tempdb voor een SQL Server-omgeving wilt aanpassen. Tempdb-gebruik wordt vermeld in het BOL-item UPDATE STATISTICS:
UPDATE STATISTICS kan tempdb gebruiken om het voorbeeld van rijen te sorteren voor het maken van statistieken."
En het effect is gedocumenteerd in de post van Linchi Shea, Prestatie-impact:tempdb en updatestatistieken. Het wordt echter niet altijd genoemd tijdens discussies over de grootte van tempdb. Als u grote tabellen heeft en updates uitvoert met FULLSCAN of hoge voorbeeldwaarden, houd dan rekening met het gebruik van tempdb.
Prestaties van selectieve updates
Vervolgens besloot ik de UPDATE STATISTICS-statements voor de andere statistieken op de tafel te testen, maar beperkte mijn tests tot de kopie van de tabel met 23 miljoen rijen. De bovenstaande zes varianten van de UPDATE STATISTICS-instructie werden vier keer herhaald voor de volgende afzonderlijke statistieken en vervolgens vergeleken met de update voor de hele tabel:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Alle tests zijn uitgevoerd met de bovengenoemde configuratie op mijn laptop, en de resultaten staan in de onderstaande grafiek:
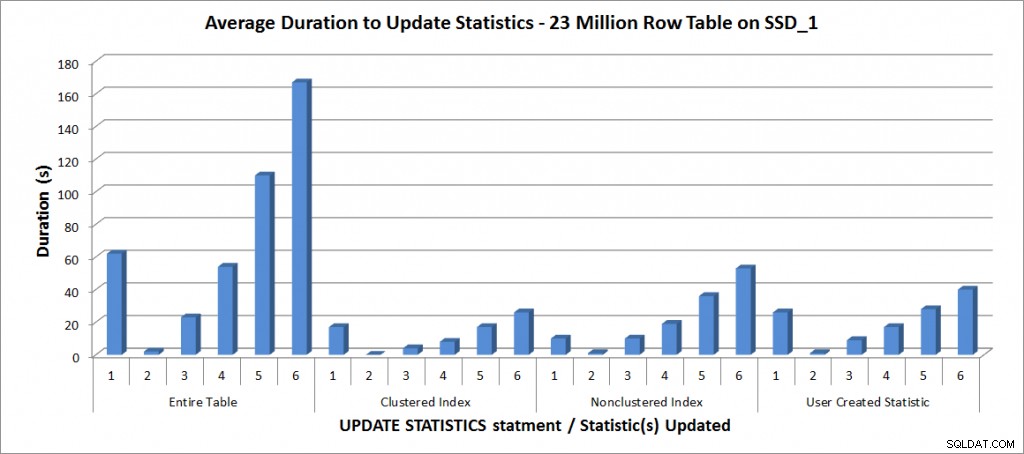
Gemiddelde duur voor UPDATE STATISTIEKEN – Alle statistieken vs. geselecteerde
Zoals verwacht kostte het bijwerken van een afzonderlijke statistiek minder tijd dan bij het bijwerken van alle statistieken voor de tabel. De waarde waarbij de gesamplede update langer duurde dan een FULLSCAN varieerde:
| UPDATE-instructie | FULLSCAN duur (s) | Eerste UPDATE die langer duurde |
|---|---|---|
| Hele tabel | 62 | 50% – 110 seconden |
| Geclusterde index | 17 | 75% – 26 seconden |
| Niet-geclusterde index | 10 | 25% – 19 seconden |
| Door gebruiker gemaakte statistiek | 26 | 50% – 28 seconden |
Conclusie
Op basis van deze gegevens en de FULLSCAN-gegevens van de 607 miljoen rijtabellen is er geen specifieke omslagpunt waar een gesamplede update langer duurt dan een FULLSCAN; dat punt is afhankelijk van de tafelgrootte en de beschikbare middelen. Maar de gegevens zijn nog steeds de moeite waard, omdat ze aantonen dat er is een punt waar het langer kan duren om een gesamplede waarde vast te leggen dan een FULLSCAN. Het komt weer neer op het kennen van uw gegevens. Dit is van cruciaal belang om niet alleen te begrijpen of een tabel aangepast beheer van statistieken nodig heeft, maar ook om de ideale steekproefomvang te begrijpen om een bruikbaar histogram te maken en ook om het gebruik van bronnen te optimaliseren.
Specificaties
Laptopspecificaties:Dell M6500, 1 Intel i7 (2.13GHz 4 cores en HT is ingeschakeld dus 8 logische cores), 32 GB geheugen, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), databasebestanden opgeslagen op een 265GB Samsung SSD PM810Test Server specificaties:Dell R720, 2 Intel E5-2670 (2.6GHz 8 cores en HT is ingeschakeld dus 16 logische cores per socket), 64 GB geheugen, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), databasebestanden voor één tabel bevindt zich op twee Fusion-io Duo MLC-kaarten van 640 GB, databasebestanden voor de andere tabel bevinden zich op negen 15K RPM-schijven in een RAID5-array