Ik heb eerder geblogd over waarom ik niet van sp_updatestats hou. Ik heb onlangs een andere reden gevonden dat het niet mijn vriend is. TL;DR:Het werkt geen statistieken bij van geïndexeerde weergaven. Nu, de documentatie beweert niet dat dit het geval is, dus er is hier geen bug. In de MSDN-documentatie staat duidelijk:
Voert UPDATE STATISTICS uit op alle door de gebruiker gedefinieerde en interne tabellen in de huidige database.Maar... hoeveel van jullie hebben nagedacht over je geïndexeerde weergaven en vroegen zich af of die werden bijgewerkt? Ik geef toe dat ik dat niet deed. Ik vergeet geïndexeerde weergaven, wat jammer is omdat ze echt krachtig kunnen zijn als ze op de juiste manier worden gebruikt. Ze kunnen ook een nachtmerrie zijn om te ontrafelen wanneer je problemen oplost, maar ik ga vandaag niet in op het gebruik ervan. Ik wil dat je je ervan bewust bent dat ze niet worden bijgewerkt door sp_updatestats, en kijk welke opties je hebt.
Instellen
Aangezien de World Series net is afgelopen, gaan we de Baseball-database gebruiken voor onze tests. U kunt het downloaden van de pagina SQLskills-bronnen. Eenmaal hersteld, maken we een kopie van de dbo.Players-tabel, genaamd dbo.PlayerInfo, laden er een paar duizend rijen in en maken dan een geïndexeerde weergave die onze nieuwe tabel aan de PitchingPost-tabel toevoegt:
GEBRUIK [BaseballData];GO CREATE TABLE [dbo].[PlayerInfo]( [lahmanID] [int] NOT NULL, [playerID] [varchar](10) NULL STANDAARD (NULL), [managerID] [varchar]( 10) NULL STANDAARD (NULL), [hofID] [varchar] (10) NULL STANDAARD (NULL), [geboortejaar] [int] NULL STANDAARD (NULL), [geboortemaand] [int] NULL STANDAARD (NULL), [geboortedag] [int] NULL DEFAULT (NULL), [birthCountry] [varchar](50) NULL DEFAULT (NULL), [birthState] [varchar](2) NULL DEFAULT (NULL), [birthCity] [varchar](50) NULL DEFAULT (NULL), [deathYear] [int] NULL DEFAULT (NULL), [deathMonth] [int] NULL DEFAULT (NULL), [deathDay] [int] NULL DEFAULT (NULL), [deathCountry] [varchar](50) NULL DEFAULT (NULL), [deathState] [varchar](2) NULL DEFAULT (NULL), [deathCity] [varchar](50) NULL DEFAULT (NULL), [nameFirst] [varchar](50) NULL DEFAULT (NULL), [nameLast] [varchar](50) NULL DEFAULT (NULL), [nameNote] [varchar](255) NULL DEFAULT (NULL), [nameGiven] [varchar](255) NULL DEFAULT (NULL), [nameNick] [varchar ](255) NULL STANDAARD (NULL), [gewicht] [int] NULL DEFAULT (NULL), [height] [int] NULL, [bats] [varchar](1) NULL DEFAULT (NULL), [throws] [varchar](1) NULL DEFAULT (NULL), [debut] [varchar]( 10) NULL STANDAARD (NULL), [finalGame] [varchar] (10) NULL STANDAARD (NULL), [college] [varchar](50) NULL STANDAARD (NULL), [lahman40ID] [varchar] (9) NULL STANDAARD ( NULL), [lahman45ID] [varchar] (9) NULL DEFAULT (NULL), [retroID] [varchar] (9) NULL DEFAULT (NULL), [holtzID] [varchar] (9) NULL DEFAULT (NULL), [bbrefID ] [varchar](9) NULL STANDAARD (NULL),PRIMAIRE SLEUTEL GECLUSTERD ([lahmanID] ASC) OP [PRIMARY]) OP [PRIMARY];GO INSERT INTO [dbo].[PlayerInfo] ([lahmanID] ,[playerID] ,[managerID] ,[hofID] ,[geboortejaar] ,[geboortemaand] ,[geboortedag] ,[geboorteland] ,[geboortestaat] ,[geboorteplaats] ,[overlijdensjaar] ,[overledenmaand] ,[dag van overlijden] ,[land van overlijden] ,[ deathState] ,[deathCity] ,[nameFirst] ,[nameLast] ,[nameNote] ,[nameGiven] ,[nameNick] ,[gewicht] ,[hoogte] ,[vleermuizen] ,[worpen] ,[debuut] ,[finalGame] ,[college] ,[lahman40ID] ,[lahman45ID] ,[ retroID] ,[holtzID] ,[bbrefID])SELECT [lahmanID] ,[spelerID] ,[managerID] ,[hofID] ,[geboortejaar] ,[geboortemaand] ,[geboortedag] ,[geboorteland] ,[geboortestaat] ,[geboorteplaats ] ,[deathYear] ,[deathMonth] ,[deathDay] ,[deathCountry] ,[deathState] ,[deathCity] ,[nameFirst] ,[nameLast] ,[nameNote] ,[nameGiven] ,[nameNick] ,[gewicht] , [hoogte] ,[vleermuizen] ,[worpen] ,[debuut] ,[finalGame] ,[college] ,[lahman40ID] ,[lahman45ID] ,[retroI D] ,[holtzID] ,[bbrefID]VAN [dbo].[Spelers]WAAR [lahmanID] <=10000; MAAK VIEW [PlayerPostSeason]MET SCHEMABINDINGAS SELECTEER [p].[lahmanID], [p].[nameFirst], [p].[nameLast], [p].[debut], [p].[finalGame], [pp ].[jaarID], [pp].[ronde], [pp].[teamID], [pp].[W], [pp].[L], [pp].[G] VAN [dbo]. [PlayerInfo] [p] JOIN [dbo].[PitchingPost] [pp] ON [p].[playerID] =[pp].[playerID]; MAAK UNIEKE GECLUSTERDE INDEX [CI_PlayerPostSeason] OP [PlayerPostSeason] ([lahmanID], [yearID], [round]); MAAK NIET-GECLUSTERDE INDEX [NCI_PlayerPostSeason_Name] OP [PlayerPostSeason] ([nameFirst], [nameLast]);
Als we statistieken controleren voor de geclusterde en niet-geclusterde indexen, zien we dat ze bestaan:
DBCC SHOW_STATISTICS ('PlayerPostSeason', CI_PlayerPostSeason) WITH STAT_HEADER;GODBCC SHOW_STATISTICS ('PlayerPostSeason', NCI_PlayerPostSeason_Name) WITH STAT_HEADER;GO
 Statistieken indexweergave na eerste aanmaak
Statistieken indexweergave na eerste aanmaak
Nu voegen we meer rijen toe aan PlayerInfo:
INSERT INTO [dbo].[PlayerInfo] ([lahmanID] ,[playerID] ,[managerID] ,[hofID] ,[birthYear] ,[birthMonth] ,[birthDay] ,[birthCountry] ,[birthState] ,[ geboorteplaats] ,[overlijdensjaar] ,[overledenmaand] ,[dag van overlijden] ,[land van overlijden] ,[overlijdensstaat] ,[overlijdensplaats] ,[naamEerste] ,[naamLaatste] ,[naamOpmerking] ,[naamGiven] ,[naamNick] ,[gewicht] ,[hoogte] ,[vleermuizen] ,[worpen] ,[debuut] ,[finalGame] ,[college] ,[lahman40ID] ,[lahman45ID] ,[retroID] ,[holtzID] ,[bbrefID])SELECT [lahmanID] , [playerID] ,[managerID] ,[hofID] ,[geboortejaar] ,[geboortemaand] ,[geboortedag] ,[geboorteland] ,[geboortestaat] ,[geboorteplaats] ,[deathYear] ,[deathMonth] ,[deathDay] ,[deathCountry] ,[deathState] ,[deathCity] ,[nameFirst] ,[nameLast] ,[nameNote] ,[nameGiven] ,[nameNick] ,[gewicht] ,[ hoogte] ,[vleermuizen] ,[worpen] ,[debuut] ,[finalGame] ,[college] ,[lahman40ID] ,[lahman45ID] ,[retroID] ,[holtzID] ,[bbrefID]VAN [dbo].[Spelers] WAAR [lahmanID]> 10000;
En als we sys.dm_db_stats_properties controleren, kunnen we de rijwijzigingen zien:
SELECT [sch].[name] AS [Schema], [so].[name] AS [ObjectName], [so].[type] AS [ObjectType], [ss].[name] AS [Statistieken ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications]FROM [sys].[objects] [so]JOIN [sys].[stats] [ss] ON [so].[object_id] =[ss].[object_id]JOIN [sys].[schemas] [sch] ON [ so].[schema_id] =[sch].[schema_id]OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) spWHERE [so].[name] =' PlayerPostSeason';
 Rijen gewijzigd in de geïndexeerde weergave, via sys.dm_db_stats_properties
Rijen gewijzigd in de geïndexeerde weergave, via sys.dm_db_stats_properties
En voor de lol, als we sys.sysindexes controleren, kunnen we de wijzigingen daar ook zien:
SELECT [so].[name], [si].[name], [si].[rowcnt], [si].[rowmodctr]FROM [sys].[sysindexes] [si]JOIN [sys] .[objects] [so] ON [si].[id] =[so].[object_id]WHERE [so].[name] ='PlayerPostSeason';
 Rijen gewijzigd in de geïndexeerde weergave, via sys.sysindexes
Rijen gewijzigd in de geïndexeerde weergave, via sys.sysindexes
Nu is sys.sysindexes verouderd, maar als je je herinnert van mijn vorige post, is dat wat sp_updatestats gebruikt om te zien wat er is gewijzigd. Maar... de objectenlijst voor sys.indexes wordt aangestuurd door de query op sys.objects, die, als u het zich herinnert, filtert op gebruikerstabellen ('U') en interne tabellen ('IT'). Het bevat geen weergaven ('V') in dat filter. Als we dus sp_updatestats uitvoeren en de uitvoer controleren (kortheidshalve niet meegeleverd), wordt er geen melding gemaakt van onze PlayerPostSeason-weergave.
Als u dus geïndexeerde weergaven hebt en u vertrouwt op sp_updatestats om uw statistieken bij te werken, worden uw weergavestatistieken niet bijgewerkt. Ik vermoed echter dat de meesten van u de optie Statistieken automatisch bijwerken hebben ingeschakeld voor uw databases. Dit is goed, want met deze optie worden de weergavestatistieken bijgewerkt als ze ongeldig zijn verklaard. We weten dat we meer dan 2000 wijzigingen hebben aangebracht aan de indexen op PlayerPostSeason. Als we zoeken op een voornaam die selectief is, moet ons zoekplan de NCI_PlayerPostSeason_Name-index gebruiken en omdat de statistieken verouderd zijn, moeten ze worden bijgewerkt. Laten we eens kijken:
SELECTEER *FROM [PlayerPostSeason]WHERE [nameFirst] ='Madison';GO
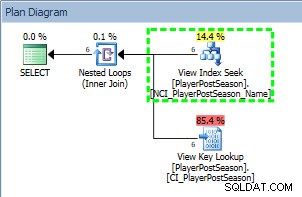 Queryplan van SELECT tegen niet-geclusterde index
Queryplan van SELECT tegen niet-geclusterde index
We kunnen in het plan zien dat de NCI_PlayerPostSeason_Name niet-geclusterde index is gebruikt, en als we de statistieken controleren:
 Statistieken na automatische update
Statistieken na automatische update
En ja hoor, de statistieken voor de niet-geclusterde index zijn bijgewerkt. Maar we willen natuurlijk niet afhankelijk zijn van automatische updates om statistieken te beheren, we willen proactief zijn. We hebben twee opties:
- Onderhoudstaak
- Aangepast script
De onderhoudstaak voor updatestatistieken doet bekijk statistieken bijwerken. Dit wordt nergens in de gebruikersinterface specifiek genoemd, maar als we een onderhoudsplan maken met de taak updatestatistieken en deze uitvoeren, worden de statistieken voor de geïndexeerde weergave bijgewerkt. Het nadeel van de onderhoudstaak voor updatestatistieken is dat het een voorhamerbenadering is. Het werkt alles bij statistieken, ongeacht of het nodig is (het is bijna net zo erg als sp_updatestats). Ik geef de voorkeur aan een aangepast script, waarbij SQL Server alleen bijwerkt wat is gewijzigd. Als je niet van je eigen script houdt, kun je het script van Ola Hallengren gebruiken. Het is gebruikelijk om statistieken bij te werken als onderdeel van het opnieuw opbouwen en reorganiseren van uw index. Met Ola's script in de SQL Agent-taak zou je bijvoorbeeld het volgende hebben:
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q "EXECUTE [dbo].[IndexOptimize] @Databases ='BaseballData', @FragmentationLow =NULL, @FragmentationMedium ='INDEX_REORGANIZE', @FragmentationREBUIL ='INDEX_REBUILD ', @FragmentationLevel1 =5, @FragmentationLevel2 =30, @UpdateStatistics ='ALL', @OnlyModifiedStatistics ='Y', @LogToTable ='Y'" –bMet deze optie, als statistieken zijn gewijzigd, worden ze bijgewerkt, en als we de [dbo].[IndexOptimize] opgeslagen procedure controleren, kunnen we zien waar Ola controleert op wijzigingen:
-- Zijn de gegevens in de statistieken gewijzigd sinds de statistieken voor het laatst zijn bijgewerkt? ALS @CurrentStatisticsID NIET NULL IS EN @UpdateStatistics NIET NULL EN @OnlyModifiedStatistics ='Y' BEGIN SET @CurrentCommand10 ='' IF @LockTimeout NIET NULL IS SET @CurrentCommand10 ='SET LOCK_TIMEOUT ' + CAST(@LockTimeout) 1000 AS + '; ' IF (@Version>=10.504000 AND @Version <11) OR @Version>=11.03000 BEGIN MET INSTELLEN @CurrentCommand10 =@CurrentCommand10 + 'USE' + QUOTENAME(@CurrentDatabaseName) + '; IF EXISTS(SELECT * FROM sys.dm_db_stats_properties (@ParamObjectID, @ParamStatisticsID) WHERE modificatie_counter> 0) BEGIN SET @ParamStatisticsModified =1 END' EINDE ANDERS BEGIN SET @CurrentCommand10 =@CurrentNAME 'S10 + @CurrentDatabaseName) + '.sys.sysindexes sysindexes WHERE sysindexes.[id] =@ParamObjectID EN sysindexes.[indid] =@ParamStatisticsID AND sysindexes.[rowmodctr] <> 0) BEGIN SET @Parampreistics END'Modified =1>Voor versies die de DMF sys.dm_stats_properties ondersteunen, controleert Ola deze op statistieken die zijn gewijzigd, en voor versies die de nieuwe DMF sys.dm_db_stats_properties niet ondersteunen, wordt de systeemtabel sys.sysindexes gecontroleerd. Mijn enige klacht hier is dat het script zich op dezelfde manier gedraagt als sp_updatestats:als ten minste één rij is gewijzigd, wordt de statistiek bijgewerkt.
Als je niet van het schrijven van je eigen code voor het beheren van statistieken houdt, raad ik aan om bij Ola's script te blijven. Maar als u uw updates wat meer wilt targeten, raad ik u aan sys.dm_db_stats_properties te gebruiken. Deze DMF is alleen beschikbaar voor SQL Server 2008R2 SP2 en hoger, en SQL Server 2012 SP1 en hoger, dus als u een lagere versie gebruikt, moet u sys.indexes gebruiken. Maar voor degenen onder u met toegang tot sys.dm_db_stats_properties, hier is een vraag om u op weg te helpen:
SELECT [sch].[name] AS [Schema], [so].[name] AS [ObjectName], [so].[type] AS [ObjectType], [ss].[name] AS [Statistieken ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , CAST(100 * [sp].[rows_sampled] / [sp].[rijen] AS DECIMAAL (18, 2)) AS [PercentSampled], [sp].[modification_counter] AS [RowModifications] , CAST(100 * [sp].[modification_counter] / [sp].[rijen ] AS DECIMAL (18, 2)) AS [ProcentChange]FROM [sys].[objects] AS [so]INNER JOIN [sys].[stats] AS [ss] ON [so].[object_id] =[ss] .[object_id]INNER JOIN [sys].[schemas] AS [sch] ON [so].[schema_id] =[sch].[schema_id]OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id] , [ss].[stats_id]) AS [sp]WHERE [so].[type] IN ('U','V')AND ((CAST(100 * [sp].[modification_counter] / [sp]. [rijen] ALS DECIMAAL (18,2))>=10.0))BESTEL DOOR CAST(100 * [sp].[modification_counter] / [sp].[rijen] ALS DECIMAAL (18, 2)) DESC;Merk op dat we met sys.objects filteren op tabellen en views; je zou dit kunnen wijzigen om systeemtabellen op te nemen. U kunt het predikaat vervolgens wijzigen om alleen rijen op te halen op basis van het percentage gewijzigde rijen, of misschien een combinatie van wijzigingspercentage en aantal rijen (voor tabellen met miljoenen of miljarden rijen kan dat percentage lager zijn dan voor kleine tabellen).
Samenvatting
De take home-boodschap hier is vrij duidelijk:ik raad het gebruik van sp_updatestats niet aan om statistieken te beheren. Statistieken worden bijgewerkt wanneer een of meer rijen zijn gewijzigd (wat een extreem lage drempel is voor het bijwerken van statistieken) en statistieken voor geïndexeerde weergaven zijn niet bijgewerkt. Dit is geen uitgebreide en efficiënte methode voor het beheren van statistieken... en de taak om statistieken bij te werken in een onderhoudsplan is niet veel beter. Het werkt de geïndexeerde weergavestatistieken bij, maar het werkt elke . bij statistiek, ongeacht de wijzigingen. Een aangepast script is echt de juiste keuze, maar begrijp dat het script van Ola Hallengren, als je bijwerkt op basis van wijziging, ook wordt bijgewerkt wanneer alleen de rij is gewijzigd (maar het krijgt in ieder geval de geïndexeerde weergaven). Voor de beste controle moet u uiteindelijk uw eigen script gebruiken voor het beheren van statistieken. Ik heb je de basisquery gegeven om te beginnen. Als je een paar uur kunt vrijmaken om je T-SQL-schrijven te oefenen en het vervolgens uit te testen, heb je een werkend aangepast script klaar voor je databases voordat de feestdagen eraan komen.