Ik zie mensen vaak worstelen met SQL Server wanneer ze twee verschillende uitvoeringsplannen zien voor wat volgens hen dezelfde query is. Meestal wordt dit ontdekt na andere observaties, zoals enorm verschillende uitvoeringstijden. Ik zeg dat ze denken dat het dezelfde vraag is, omdat het soms zo is en soms niet.
Een van de meest voorkomende gevallen is wanneer ze een zoekopdracht in SSMS testen en een ander plan krijgen dan het plan dat ze van hun toepassing krijgen. Hier spelen mogelijk twee factoren een rol (die ook relevant kunnen zijn als de vergelijking NIET tussen de applicatie en SSMS is):
- De applicatie heeft bijna altijd een andere
SETinstellingen dan SSMS (dit zijn zaken alsARITHABORT,ANSI_NULLSenQUOTED_IDENTIFIER). Dit dwingt SQL Server om de twee plannen afzonderlijk op te slaan; Erland Sommarskog heeft dit uitgebreid behandeld in zijn artikel Slow in the Application, Fast in SSMS?
- De parameters die door de toepassing werden gebruikt toen de kopie van het plan voor het eerst werd gecompileerd, kunnen heel anders zijn geweest en tot een ander plan hebben geleid dan de parameters die werden gebruikt de eerste keer dat de query werd uitgevoerd vanuit SSMS - dit staat bekend als parameter sniffing . Erland gaat daar ook uitgebreid over in, en ik ga zijn aanbevelingen niet herhalen, maar vat het samen door u eraan te herinneren dat het testen van de aanvraag van de toepassing in SSMS niet altijd nuttig is, aangezien het vrij onwaarschijnlijk is dat het een appels-tot-appels-test is.
Er zijn een paar andere scenario's die een beetje meer obscuur zijn en die ik naar voren breng in mijn Bad Habits &Best Practices-lezing. Dit zijn gevallen waarin de plannen niet verschillen, maar er zijn meerdere exemplaren van hetzelfde plan die de plancache doen opzwellen. Ik dacht dat ik ze hier moest noemen omdat ze altijd zoveel mensen verrassen.
cAsE en witruimte zijn belangrijk
SQL Server hasht de querytekst in een binaire indeling, wat betekent dat elk afzonderlijk teken in de querytekst cruciaal is. Laten we de volgende eenvoudige vragen nemen:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO SELECT StoreID FROM Sales.Customer; GO -- original query GO SELECT StoreID FROM Sales.Customer; GO ----^---- extra space GO SELECT storeid FROM sales.customer; GO ---- lower case names GO select StoreID from Sales.Customer; GO ---- lower case keywords GO
Deze genereren uiteraard exact dezelfde resultaten en genereren exact hetzelfde plan. Als we echter kijken naar wat we in de plancache hebben:
SELECT t.[text], p.size_in_bytes, p.usecounts FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t WHERE LOWER(t.[text]) LIKE N'%sales'+'.'+'customer%';
De resultaten zijn ongelukkig:
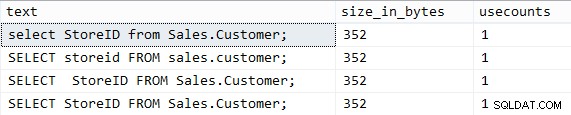
In dit geval is het dus duidelijk dat hoofdletters en witruimte erg belangrijk zijn. Ik heb hier afgelopen mei veel uitgebreider over gesproken.
Schemareferenties zijn belangrijk
Ik heb eerder geblogd over het belang van het specificeren van het schemavoorvoegsel bij het verwijzen naar een object, maar op dat moment was ik me er niet volledig van bewust dat het ook gevolgen had voor de plancache.
Laten we eens kijken naar een heel eenvoudig geval waarin we twee gebruikers hebben met verschillende standaardschema's, en ze voeren exact dezelfde querytekst uit, zonder naar het object te verwijzen door zijn schema:
USE AdventureWorks2014; DBCC FREEPROCCACHE WITH NO_INFOMSGS; GO CREATE USER SQLPerf1 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Sales; CREATE USER SQLPerf2 WITHOUT LOGIN WITH DEFAULT_SCHEMA = Person; GO CREATE TABLE dbo.AnErrorLog(id INT); GRANT SELECT ON dbo.AnErrorLog TO SQLPerf1, SQLPerf2; GO EXECUTE AS USER = N'SQLPerf1'; GO SELECT id FROM AnErrorLog; GO REVERT; GO EXECUTE AS USER = N'SQLPerf2'; GO SELECT id FROM AnErrorLog; GO REVERT; GO
Als we nu naar de plancache kijken, kunnen we sys.dm_exec_plan_attributes binnenhalen om precies te zien waarom we twee verschillende plannen krijgen voor identieke vragen:
SELECT t.[text], p.size_in_bytes, p.usecounts, [schema_id] = pa.value, [schema] = s.name FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS pa INNER JOIN sys.schemas AS s ON s.[schema_id] = pa.value WHERE t.[text] LIKE N'%AnError'+'Log%' AND pa.attribute = N'user_id';
Resultaten:

En als u het allemaal opnieuw uitvoert, maar de dbo. . toevoegt prefix voor beide query's, ziet u dat er maar één abonnement is dat twee keer wordt gebruikt. Dit wordt een zeer overtuigend argument om altijd volledig naar objecten te verwijzen.
SET instellingen redux
Even terzijde:je kunt een vergelijkbare benadering gebruiken om te bepalen of SET instellingen zijn verschillend voor twee of meer versies van dezelfde query. In dit geval onderzoeken we de query's die betrokken zijn bij meerdere plannen die zijn gegenereerd door verschillende oproepen naar dezelfde opgeslagen procedure, maar u kunt ze ook identificeren aan de hand van de querytekst of query-hash.
SELECT p.plan_handle, p.usecounts, p.size_in_bytes, set_options = MAX(a.value) FROM sys.dm_exec_cached_plans AS p CROSS APPLY sys.dm_exec_sql_text(p.plan_handle) AS t CROSS APPLY sys.dm_exec_plan_attributes(p.plan_handle) AS a WHERE t.objectid = OBJECT_ID(N'dbo.procedure_name') AND a.attribute = N'set_options' GROUP BY p.plan_handle, p.usecounts, p.size_in_bytes;
Als je hier meerdere resultaten hebt, zou je verschillende waarden moeten zien voor set_options (wat een bitmasker is). Dat is nog maar het begin; Ik ga het hier uitzoeken en je vertellen dat je kunt bepalen welke set opties voor elk plan zijn ingeschakeld door de waarde uit te pakken volgens de sectie "Setopties evalueren" hier. Ja, ik ben zo lui.
Conclusie
Er zijn verschillende redenen waarom u verschillende plannen kunt zien voor dezelfde zoekopdracht (of waarvan u denkt dat het dezelfde zoekopdracht is). In de meeste gevallen kun je de oorzaak vrij eenvoudig isoleren; de uitdaging is vaak om er in de eerste plaats naar te zoeken. In mijn volgende bericht zal ik het hebben over een iets ander onderwerp:waarom een database die is hersteld naar een "identieke" server, verschillende plannen kan opleveren voor dezelfde zoekopdracht.