[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]
Er is in de loop der jaren veel geschreven over het begrijpen en optimaliseren van SELECT query's, maar minder over gegevensmodificatie. In deze reeks berichten wordt gekeken naar een probleem dat specifiek is voor INSERT , UPDATE , DELETE en MERGE vragen – het Halloween-probleem.
De uitdrukking "Halloweenprobleem" werd oorspronkelijk bedacht met verwijzing naar een SQL UPDATE vraag die een loonsverhoging van 10% moest opleveren voor elke werknemer die minder dan $ 25.000 verdiende. Het probleem was dat de zoekopdracht 10% verhogingen bleef geven totdat iedereen verdiende minimaal $ 25.000. We zullen later in deze serie zien dat het onderliggende probleem ook van toepassing is op INSERT , DELETE en MERGE vragen, maar voor deze eerste invoer is het handig om de UPDATE . te onderzoeken probleem in een beetje detail.
Achtergrond
De SQL-taal biedt gebruikers een manier om databasewijzigingen op te geven met behulp van een UPDATE statement, maar de syntaxis zegt niets over hoe de database-engine moet de wijzigingen uitvoeren. Aan de andere kant specificeert de SQL-standaard wel dat het resultaat van een UPDATE moet hetzelfde zijn alsof het was uitgevoerd in drie afzonderlijke en niet-overlappende fasen:
- Een alleen-lezen zoekopdracht bepaalt de records die moeten worden gewijzigd en de nieuwe kolomwaarden
- Wijzigingen worden toegepast op betrokken records
- Consistentiebeperkingen voor databases zijn geverifieerd
Het letterlijk implementeren van deze drie fasen in een database-engine zou correcte resultaten opleveren, maar de prestaties zijn misschien niet erg goed. De tussentijdse resultaten in elke fase vereisen systeemgeheugen, waardoor het aantal query's dat het systeem gelijktijdig kan uitvoeren, wordt verminderd. Het vereiste geheugen kan ook groter zijn dan het beschikbare geheugen, waardoor ten minste een deel van de updateset moet worden weggeschreven naar de schijfopslag en later opnieuw moet worden gelezen. Last but not least moet elke rij in de tabel meerdere keren worden aangeraakt onder dit uitvoeringsmodel.
Een alternatieve strategie is het verwerken van de UPDATE een rij tegelijk. Dit heeft het voordeel dat elke rij slechts één keer wordt aangeraakt en vereist in het algemeen geen geheugen voor opslag (hoewel sommige bewerkingen, zoals een volledige sortering, de volledige invoerset moeten verwerken voordat de eerste rij uitvoer wordt geproduceerd). Dit iteratieve model wordt gebruikt door de SQL Server-engine voor het uitvoeren van query's.
De uitdaging voor de query-optimizer is om een iteratief (rij voor rij) uitvoeringsplan te vinden dat voldoet aan de UPDATE semantiek vereist door de SQL-standaard, met behoud van de prestatie- en gelijktijdigheidsvoordelen van pijplijnuitvoering.
Updateverwerking
Om het oorspronkelijke probleem te illustreren, zullen we een verhoging van 10% toepassen op elke werknemer die minder dan $ 25.000 verdient met behulp van de Employees onderstaande tabel:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Updatestrategie in drie fasen
De alleen-lezen eerste fase vindt alle records die voldoen aan de WHERE clausule predikaat, en slaat genoeg informatie op voor de tweede fase om zijn werk te doen. In de praktijk betekent dit het vastleggen van een unieke identifier voor elke kwalificerende rij (de geclusterde indexsleutels of heap row identifier) en de nieuwe salariswaarde. Zodra fase één is voltooid, wordt de hele set update-informatie doorgegeven aan de tweede fase, die elk record lokaliseert dat moet worden bijgewerkt met behulp van de unieke identifier, en het salaris verandert in de nieuwe waarde. De derde fase controleert vervolgens of de integriteitsbeperkingen van de database niet worden geschonden door de uiteindelijke status van de tabel.
Iteratieve strategie
Deze aanpak leest één rij tegelijk uit de brontabel. Als de rij voldoet aan de WHERE clausule predikaat, wordt de salarisverhoging toegepast. Dit proces herhaalt zich totdat alle rijen van de bron zijn verwerkt. Hieronder ziet u een voorbeeld van een uitvoeringsplan dat gebruik maakt van dit model:

Zoals gebruikelijk voor de vraaggestuurde pijplijn van SQL Server, begint de uitvoering bij de meest linkse operator - de UPDATE in dit geval. Het vraagt om een rij van de Table Update, die om een rij vraagt van de Compute Scalar, en verder in de keten naar de Table Scan:
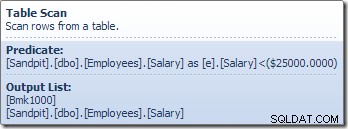
De operator Tabelscan leest rijen één voor één uit de opslagengine, totdat hij er een vindt die voldoet aan het predikaat Salaris. De uitvoerlijst in de bovenstaande afbeelding toont de tabelscanoperator die een rij-ID retourneert en de huidige waarde van de salariskolom voor deze rij. Een enkele rij met verwijzingen naar deze twee stukjes informatie wordt doorgegeven aan de Compute Scalar:
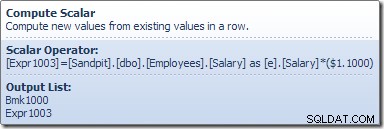
De Compute Scalar definieert een uitdrukking die de salarisverhoging toepast op de huidige rij. Het retourneert een rij met verwijzingen naar de rij-ID en het gewijzigde salaris naar de tabelupdate, die de opslagengine aanroept om de gegevenswijziging uit te voeren. Dit iteratieve proces gaat door totdat de tabelscan geen rijen meer heeft. Hetzelfde basisproces wordt gevolgd als de tabel een geclusterde index heeft:
Het belangrijkste verschil is dat de geclusterde indexsleutel(s) en uniquifier (indien aanwezig) worden gebruikt als rij-ID in plaats van een heap-RID.
Het probleem
De verandering van de logische driefasige operatie gedefinieerd in de SQL-standaard naar het fysieke iteratieve uitvoeringsmodel heeft een aantal subtiele veranderingen geïntroduceerd, waarvan we er vandaag slechts één zullen bekijken. In ons huidige voorbeeld kan een probleem optreden als er een niet-geclusterde index is in de kolom Salaris, die de query-optimizer besluit te gebruiken om rijen te vinden die in aanmerking komen (salaris <$ 25.000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Het uitvoeringsmodel per rij kan nu onjuiste resultaten opleveren of zelfs in een oneindige lus terechtkomen. Overweeg een (denkbeeldig) iteratief uitvoeringsplan dat de salarisindex zoekt, rij voor rij retourneert naar de Compute Scalar en uiteindelijk naar de Update-operator:

Er zijn een paar extra Compute Scalars in dit plan vanwege een optimalisatie die niet-geclusterd indexonderhoud overslaat als de Salariswaarde niet is gewijzigd (alleen mogelijk voor een nulsalaris in dit geval).
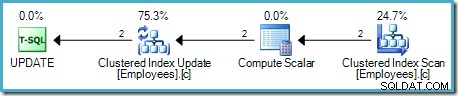
Als we dat negeren, is het belangrijke kenmerk van dit plan dat we nu een geordende gedeeltelijke indexscan hebben die rij voor rij doorgeeft aan een operator die dezelfde index wijzigt (de groene markering in de bovenstaande afbeelding van SQL Sentry Plan Explorer maakt duidelijk dat de geclusterde De operator Index Update onderhoudt zowel de basistabel als de niet-geclusterde index).
Hoe dan ook, het probleem is dat door één rij tegelijk te verwerken, de update de huidige rij kan verplaatsen voor de scanpositie die door de Index Seek wordt gebruikt om rijen te lokaliseren die moeten worden gewijzigd. Als u het voorbeeld doorloopt, wordt die verklaring een beetje duidelijker:
De niet-geclusterde index is ingetoetst en oplopend gesorteerd op de salariswaarde. De index bevat ook een verwijzing naar de bovenliggende rij in de basistabel (ofwel een heap-RID of de geclusterde indexsleutels plus uniquifier indien nodig). Om het voorbeeld gemakkelijker te volgen te maken, gaat u ervan uit dat de basistabel nu een unieke geclusterde index heeft in de kolom Naam, dus de niet-geclusterde indexinhoud aan het begin van de updateverwerking is:
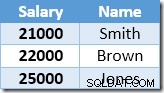
De eerste rij die door de Index Seek wordt geretourneerd, is het salaris van $ 21.000 voor Smith. Deze waarde wordt bijgewerkt naar $ 23.100 in de basistabel en de niet-geclusterde index door de operator Clustered Index. De niet-geclusterde index bevat nu:
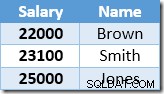
De volgende rij die door de Index Seek wordt geretourneerd, is de invoer van $ 22.000 voor Brown, die wordt bijgewerkt naar $ 24.200:
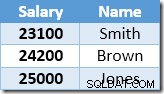
Nu vindt de Index Seek de waarde van $23.100 voor Smith, die opnieuw wordt bijgewerkt , tot $ 25.410. Dit proces gaat door totdat alle werknemers een salaris hebben van ten minste $ 25.000 - wat geen correct resultaat is voor de gegeven UPDATE vraag. Hetzelfde effect kan in andere omstandigheden leiden tot een runaway-update die alleen wordt beëindigd als de server geen logruimte meer heeft of als er een overloopfout optreedt (in dit geval zou het kunnen gebeuren als iemand een salaris van nul had). Dit is het Halloween-probleem zoals het van toepassing is op updates.
Het Halloween-probleem voor updates vermijden
Lezers met arendsogen zullen gemerkt hebben dat de geschatte kostenpercentages in het denkbeeldige Index Seek-plan niet optellen tot 100%. Dit is geen probleem met Plan Explorer - ik heb opzettelijk een key-operator uit het plan verwijderd:

De query-optimizer erkent dat dit gepijplijnde updateplan kwetsbaar is voor het Halloween-probleem en introduceert een Eager Table Spool om te voorkomen dat dit gebeurt. Er is geen hint of traceringsvlag om opname van de spoel in dit uitvoeringsplan te voorkomen, omdat dit vereist is voor correctheid.
Zoals de naam al doet vermoeden, verbruikt de spoel gretig alle rijen van zijn onderliggende operator (de Index Seek) voordat een rij wordt geretourneerd naar zijn bovenliggende Compute Scalar. Het effect hiervan is het introduceren van volledige fasescheiding – alle in aanmerking komende rijen worden gelezen en opgeslagen in tijdelijke opslag voordat er updates worden uitgevoerd.
Dit brengt ons dichter bij de driefasige logische semantiek van de SQL-standaard, maar houd er rekening mee dat de uitvoering van plannen nog steeds fundamenteel iteratief is, met operators aan de rechterkant van de spool die de leescursor vormen , en operators aan de linkerkant die de schrijfcursor vormen . De inhoud van de spoel wordt nog steeds rij voor rij gelezen en verwerkt (deze wordt niet en masse doorgegeven zoals de vergelijking met de SQL-standaard u anders zou doen geloven).
De nadelen van de fasescheiding zijn dezelfde als eerder genoemd. De Table Spool verbruikt tempdb ruimte (pagina's in de bufferpool) en kan fysieke lees- en schrijfbewerkingen naar schijf vereisen onder geheugendruk. De query-optimizer kent geschatte kosten toe aan de spoel (onder voorbehoud van alle gebruikelijke kanttekeningen bij schattingen) en zal kiezen tussen plannen die bescherming vereisen tegen het Halloween-probleem en plannen die dat niet doen op basis van geschatte kosten zoals normaal. Natuurlijk kan de optimizer om een van de normale redenen onjuist kiezen tussen de opties.
In dit geval is de afweging tussen de efficiëntieverhoging door rechtstreeks naar kwalificerende records te zoeken (die met een salaris <$ 25.000) versus de geschatte kosten van de spoel die nodig is om het Halloween-probleem te voorkomen. Een alternatief plan (in dit specifieke geval) is een volledige scan van de geclusterde index (of heap). Deze strategie vereist niet dezelfde Halloween-bescherming omdat de toetsen van de geclusterde index worden niet gewijzigd:

Omdat de indexsleutels stabiel zijn, kunnen rijen de positie in de index niet verplaatsen tussen iteraties, waardoor het Halloween-probleem in dit geval wordt vermeden. Afhankelijk van de runtime-kosten van de Clustered Index Scan vergeleken met de Index Seek plus Eager Table Spool-combinatie die eerder werd gezien, kan het ene plan sneller worden uitgevoerd dan het andere. Een andere overweging is dat het plan met Halloween Protection meer sluizen zal krijgen dan het volledig pijplijnplan, en dat de sluizen langer zullen worden vastgehouden.
Laatste gedachten
Als u het Halloween-probleem begrijpt en de effecten die het kan hebben op queryplannen voor gegevenswijziging, kunt u uitvoeringsplannen voor het wijzigen van gegevens analyseren en kunt u mogelijkheden bieden om de kosten en neveneffecten van onnodige bescherming te vermijden als er een alternatief beschikbaar is.
Er zijn verschillende vormen van het Halloween-probleem, die niet allemaal worden veroorzaakt door het lezen en schrijven naar de sleutels van een gemeenschappelijke index. Het Halloween-probleem is ook niet beperkt tot UPDATE vragen. De query-optimizer heeft meer trucs in petto om het Halloween-probleem te vermijden, afgezien van brute-force fasescheiding met behulp van een Eager Table Spool. Deze punten (en meer) zullen worden onderzocht in de volgende afleveringen van deze serie.
[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]