NULL-verwerking is een van de lastigere aspecten van gegevensmodellering en gegevensmanipulatie met SQL. Laten we beginnen met het feit dat een poging om precies uit te leggen wat een NULL is is op zich niet triviaal. Zelfs onder mensen die verstand hebben van relationele theorie en SQL, zul je zeer uitgesproken meningen horen, zowel voor als tegen het gebruik van NULL's in je database. Of je ze nu leuk vindt of niet, als databasebeoefenaar heb je er vaak mee te maken, en aangezien NULL's het schrijven van SQL-code wel complexer maken, is het een goed idee om er een prioriteit van te maken om ze goed te begrijpen. Zo voorkom je onnodige bugs en valkuilen.
Dit artikel is het eerste in een serie over NULL-complexiteit. Ik begin met de dekking van wat NULL's zijn en hoe ze zich gedragen in vergelijkingen. Vervolgens behandel ik inconsistenties in de NULL-behandeling in verschillende taalelementen. Ten slotte behandel ik ontbrekende standaardfuncties met betrekking tot NULL-verwerking in T-SQL en stel alternatieven voor die beschikbaar zijn in T-SQL.
De meeste berichtgeving is relevant voor elk platform dat een dialect van SQL implementeert, maar in sommige gevallen noem ik aspecten die specifiek zijn voor T-SQL.
In mijn voorbeelden gebruik ik een voorbeelddatabase met de naam TSQLV5. U vindt het script dat deze database maakt en vult hier, en het ER-diagram hier.
NULL als markering voor een ontbrekende waarde
Laten we beginnen met te begrijpen wat NULL's zijn. In SQL is een NULL een markering of een tijdelijke aanduiding voor een ontbrekende waarde. Het is de poging van SQL om in uw database een realiteit weer te geven waarin een bepaalde attribuutwaarde soms aanwezig is en soms ontbreekt. Stel bijvoorbeeld dat u werknemersgegevens moet opslaan in een tabel Werknemers. Je hebt attributen voor voornaam, tussennaam en achternaam. De attributen voornaam en achternaam zijn verplicht, en daarom definieert u ze als het niet toestaan van NULL's. Het attribuut middlename is optioneel, en daarom definieert u het als het toestaan van NULL's.
Als je je afvraagt wat het relationele model te zeggen heeft over ontbrekende waarden:de maker van het model, Edgar F. Codd, geloofde er wel in. Hij maakte zelfs een onderscheid tussen twee soorten ontbrekende waarden:Missing But Applicable (A-Values-marker) en Missing But Inapplicable (I-Values-marker). Als we het kenmerk middlename als voorbeeld nemen, in het geval dat een werknemer een tweede naam heeft, maar om privacyredenen ervoor kiest de informatie niet te delen, gebruikt u de A-Values-markering. In het geval dat een werknemer helemaal geen tweede naam heeft, gebruikt u de I-Values-markering. Hier kan hetzelfde attribuut soms relevant en aanwezig zijn, soms ontbrekend maar van toepassing en soms ontbrekend maar niet van toepassing. Andere gevallen kunnen duidelijker worden omschreven en ondersteunen slechts één soort ontbrekende waarden. Stel bijvoorbeeld dat u een tabel Bestellingen heeft met een attribuut met de naam verzenddatum met de verzenddatum van de bestelling. Een bestelling die is verzonden, heeft altijd een actuele en relevante verzenddatum. Het enige geval voor het niet hebben van een bekende verzenddatum is voor bestellingen die nog niet zijn verzonden. Dus hier moet ofwel een relevante waarde voor de verzenddatum aanwezig zijn, of de I-Values-markering moet worden gebruikt.
De ontwerpers van SQL kozen ervoor om niet in te gaan op het onderscheid tussen toepasselijke en niet-toepasbare ontbrekende waarden, en gaven ons de NULL als een markering voor elke vorm van ontbrekende waarde. Voor het grootste deel is SQL ontworpen om aan te nemen dat NULL's de ontbrekende maar van toepassing zijnde ontbrekende waarde vertegenwoordigen. Met name wanneer u de NULL gebruikt als een tijdelijke aanduiding voor een niet-toepasbare waarde, is de standaard SQL NULL-afhandeling daarom mogelijk niet degene die u als correct beschouwt. Soms moet u expliciete NULL-verwerkingslogica toevoegen om de behandeling te krijgen die u als de juiste voor u beschouwt.
Als best practice, als u weet dat een kenmerk geen NULL's mag toestaan, zorg er dan voor dat u het afdwingt met een NOT NULL-beperking als onderdeel van de kolomdefinitie. Hiervoor zijn een aantal belangrijke redenen. Een reden is dat als je dit niet afdwingt, op een of ander moment NULL's er zullen komen. Dit kan het gevolg zijn van een fout in de toepassing of het importeren van slechte gegevens. Als u een beperking gebruikt, weet u dat NULL's nooit de tabel zullen halen. Een andere reden is dat de optimizer beperkingen zoals NOT NULL evalueert voor een betere optimalisatie, onnodig werk op zoek naar NULL's voorkomt en bepaalde transformatieregels mogelijk maakt.
Vergelijkingen met NULL's
Er is wat lastigs in de evaluatie van predikaten door SQL wanneer er NULL's bij betrokken zijn. Ik zal eerst vergelijkingen met constanten behandelen. Later zal ik vergelijkingen behandelen met variabelen, parameters en kolommen.
Wanneer u predikaten gebruikt die operanden vergelijken in query-elementen zoals WHERE, ON en HAVING, zijn de mogelijke uitkomsten van de vergelijking afhankelijk van of een van de operanden een NULL kan zijn. Als u met zekerheid weet dat geen van de operanden een NULL kan zijn, zal de uitkomst van het predikaat altijd WAAR of ONWAAR zijn. Dit is wat bekend staat als de tweewaardige predikaatlogica, of kortweg eenvoudigweg tweewaardige logica. Dit is bijvoorbeeld het geval wanneer u een kolom vergelijkt die is gedefinieerd als het niet toestaan van NULL's met een andere niet-NULL-operand.
Als een van de operanden in de vergelijking een NULL kan zijn, laten we zeggen een kolom die NULL's toestaat, waarbij zowel gelijkheid (=) als ongelijkheid (<>,>, <,>=, <=, enz.) operatoren worden gebruikt, dan ben je nu overgeleverd aan de driewaardige predikatenlogica. Als in een gegeven vergelijking de twee operanden toevallig niet-NULL-waarden zijn, krijgt u nog steeds TRUE of FALSE als uitkomst. Als een van de operanden echter NULL is, krijgt u een derde logische waarde met de naam UNKNOWN. Merk op dat dat zelfs het geval is bij het vergelijken van twee NULL's. De behandeling van TRUE en FALSE door de meeste elementen van SQL is behoorlijk intuïtief. De behandeling van UNKNOWN is niet altijd even intuïtief. Bovendien behandelen verschillende elementen van SQL het UNKNOWN-geval anders, zoals ik later in het artikel onder "NULL-behandelingsinconsistenties" in detail zal uitleggen.
Stel dat u bijvoorbeeld de tabel Sales.Orders in de TSQLV5-voorbeelddatabase moet opvragen en bestellingen moet retourneren die op 2 januari 2019 zijn verzonden. U gebruikt de volgende query:
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
Het is duidelijk dat het filterpredikaat TRUE evalueert voor rijen waarvan de verzenddatum 2 januari 2019 is, en dat die rijen moeten worden geretourneerd. Het is ook duidelijk dat het predikaat FALSE evalueert voor rijen waar de verzenddatum aanwezig is, maar niet 2 januari 2019 is, en dat die rijen moeten worden weggegooid. Maar hoe zit het met rijen met een NULL-verzenddatum? Onthoud dat zowel op gelijkheid gebaseerde predikaten als op ongelijkheid gebaseerde predikaten UNKNOWN retourneren als een van de operanden NULL is. Het WHERE-filter is ontworpen om dergelijke rijen te verwijderen. U moet onthouden dat het WHERE-filter rijen retourneert waarvoor het filterpredikaat WAAR is, en rijen negeert waarvoor het predikaat FALSE of UNKNOWN oplevert.
Deze query genereert de volgende uitvoer:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
Stel dat je bestellingen moet retourneren die op 2 januari 2019 nog niet zijn verzonden. Wat jou betreft horen bestellingen die nog niet zijn verzonden in de output te worden meegenomen. U gebruikt een zoekopdracht die lijkt op de vorige, waarbij alleen het predikaat wordt genegeerd, zoals:
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
Deze query retourneert de volgende uitvoer:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
De uitvoer sluit natuurlijk de rijen met de verzenddatum 2 januari 2019 uit, maar sluit ook de rijen uit met een NULL-verzenddatum. Wat hier contra-intuïtief zou kunnen zijn, is wat er gebeurt als je de NOT-operator gebruikt om een predikaat te ontkennen dat resulteert in UNKNOWN. Het is duidelijk dat NIET WAAR is ONWAAR en NIET ONWAAR is WAAR. NIET ONBEKEND blijft echter ONBEKEND. De logica van SQL achter dit ontwerp is dat als je niet weet of een propositie waar is, je ook niet weet of de propositie niet waar is. Dit betekent dat bij gebruik van operatoren voor gelijkheid en ongelijkheid in het filterpredikaat, noch de positieve noch de negatieve vormen van het predikaat de rijen met de NULL's retourneren.
Dit voorbeeld is vrij eenvoudig. Er zijn lastigere gevallen met subquery's. Er is een veelvoorkomende fout wanneer u het NOT IN-predikaat gebruikt met een subquery, wanneer de subquery een NULL retourneert tussen de geretourneerde waarden. De query retourneert altijd een leeg resultaat. De reden is dat de positieve vorm van het predikaat (het IN-gedeelte) een TRUE retourneert wanneer de buitenste waarde wordt gevonden, en UNKNOWN wanneer deze niet wordt gevonden vanwege de vergelijking met de NULL. Dan retourneert de ontkenning van het predikaat met de operator NOT altijd respectievelijk FALSE of UNKNOWN - nooit een TRUE. Ik behandel deze bug in detail in T-SQL-bugs, valkuilen en best practices - subquery's, inclusief voorgestelde oplossingen, optimalisatieoverwegingen en best practices. Als je nog niet bekend bent met deze klassieke bug, zorg er dan voor dat je dit artikel leest, aangezien de bug vrij vaak voorkomt en er eenvoudige maatregelen zijn die je kunt nemen om deze te voorkomen.
Terug naar onze behoefte, hoe zit het met het proberen om bestellingen te retourneren met een verzenddatum die anders is dan 2 januari 2019, met behulp van de andere dan (<>) operator:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
Helaas leveren zowel operatoren voor gelijkheid als ongelijkheid UNKNOWN op wanneer een van de operanden NULL is, dus deze query genereert de volgende uitvoer zoals de vorige query, met uitzondering van de NULL's:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
Om het probleem van vergelijkingen met NULL's die UNKNOWN opleveren te isoleren met behulp van gelijkheid, ongelijkheid en ontkenning van de twee soorten operatoren, retourneren alle volgende query's een lege resultatenset:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
Volgens SQL is het niet de bedoeling dat je controleert of iets gelijk is aan een NULL of anders is dan een NULL, maar of iets een NULL is of geen NULL, met behulp van respectievelijk de speciale operatoren IS NULL en IS NOT NULL. Deze operators gebruiken logica met twee waarden en retourneren altijd TRUE of FALSE. Gebruik bijvoorbeeld de operator IS NULL om niet-verzonden bestellingen te retourneren, zoals:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
Deze query genereert de volgende uitvoer:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
Gebruik de operator IS NOT NULL om verzonden bestellingen te retourneren, zoals:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
Deze query genereert de volgende uitvoer:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
Gebruik de volgende code om bestellingen te retourneren die zijn verzonden op een andere datum dan 2 januari 2019, evenals niet-verzonden bestellingen:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
Deze query genereert de volgende uitvoer:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
In een later deel van de serie behandel ik standaardfuncties voor NULL-behandeling die momenteel ontbreken in T-SQL, inclusief het DISTINCT-predikaat , die het potentieel hebben om de verwerking van NULL aanzienlijk te vereenvoudigen.
Vergelijkingen met variabelen, parameters en kolommen
De vorige sectie was gericht op predikaten die een kolom vergelijken met een constante. In werkelijkheid zal je een kolom echter vooral vergelijken met variabelen/parameters of met andere kolommen. Dergelijke vergelijkingen brengen nog meer complexiteit met zich mee.
Vanuit het oogpunt van NULL-verwerking worden variabelen en parameters op dezelfde manier behandeld. Ik zal variabelen gebruiken in mijn voorbeelden, maar de punten die ik maak over hun behandeling zijn net zo relevant voor parameters.
Overweeg de volgende basisquery (ik noem het Query 1), waarmee bestellingen worden gefilterd die op een bepaalde datum zijn verzonden:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Ik gebruik een variabele in dit voorbeeld en initialiseer deze met een voorbeelddatum, maar dit had net zo goed een geparametriseerde query in een opgeslagen procedure of een door de gebruiker gedefinieerde functie kunnen zijn.
Deze uitvoering van de query genereert de volgende uitvoer:
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
Het plan voor Query 1 wordt getoond in figuur 1.
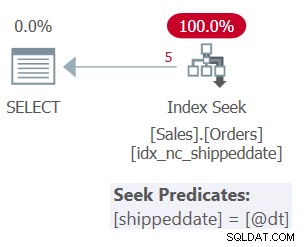 Figuur 1:Plan voor Query 1
Figuur 1:Plan voor Query 1
De tabel heeft een dekkende index om deze vraag te ondersteunen. De index heet idx_nc_shippeddate en wordt gedefinieerd met de sleutellijst (shippeddate, orderid). Het filterpredikaat van de zoekopdracht wordt uitgedrukt als een zoekargument (SARG) , wat betekent dat het de optimizer in staat stelt om een zoekbewerking in de ondersteunende index toe te passen en rechtstreeks naar het bereik van kwalificerende rijen te gaan. Wat het filterpredikaat SARGable maakt, is dat het een operator gebruikt die een opeenvolgend bereik van kwalificerende rijen in de index vertegenwoordigt, en dat het geen manipulatie toepast op de gefilterde kolom. Het plan dat u krijgt, is het optimale plan voor deze vraag.
Maar wat als u gebruikers wilt toestaan om niet-verzonden bestellingen te vragen? Dergelijke bestellingen hebben een NULL-verzenddatum. Hier is een poging om een NULL door te geven als invoerdatum:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Zoals u al weet, produceert een predikaat dat een gelijkheidsoperator gebruikt UNKNOWN wanneer een van de operanden een NULL is. Bijgevolg retourneert deze zoekopdracht een leeg resultaat:
orderid shippeddate ----------- ----------- (0 rows affected)
Hoewel T-SQL een IS NULL-operator ondersteunt, ondersteunt het geen expliciete IS
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
Deze query genereert de juiste uitvoer:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
Maar het plan voor deze zoekopdracht, zoals weergegeven in figuur 2, is niet optimaal.
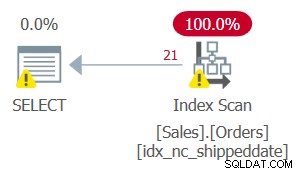 Figuur 2:Plan voor Query 2
Figuur 2:Plan voor Query 2
Aangezien u manipulatie op de gefilterde kolom hebt toegepast, wordt het filterpredikaat niet meer als een SARG beschouwd. De index is nog steeds dekkend, dus het kan worden gebruikt; maar in plaats van een zoekactie in de index toe te passen die rechtstreeks naar het bereik van kwalificerende rijen gaat, wordt het hele indexblad gescand. Stel dat de tafel 50.000.000 bestellingen had, en slechts 1.000 niet-verzonden bestellingen. Dit plan zou alle 50.000.000 rijen scannen in plaats van een zoekopdracht uit te voeren die rechtstreeks naar de kwalificerende 1.000 rijen gaat.
Een vorm van een filterpredikaat dat beide de juiste betekenis heeft waar we naar op zoek zijn en dat als een zoekargument wordt beschouwd, is (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Hier is een zoekopdracht die dit SARGable-predikaat gebruikt (we noemen het Query 3):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
Het plan voor deze zoekopdracht wordt getoond in figuur 3.
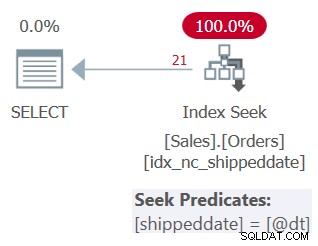 Figuur 3:Plan voor Query 3
Figuur 3:Plan voor Query 3
Zoals u kunt zien, past het plan een zoekopdracht toe in de ondersteunende index. Het zoekpredikaat zegt Shipdate =@dt, maar het is intern ontworpen om NULL's te verwerken, net als niet-NULL-waarden omwille van de vergelijking.
Deze oplossing wordt over het algemeen als redelijk beschouwd. Het is standaard, optimaal en correct. Het belangrijkste nadeel is dat het uitgebreid is. Wat als u meerdere filterpredikaten had op basis van NULL-kolommen? Je zou al snel eindigen met een lange en omslachtige WHERE-clausule. En het wordt nog veel erger wanneer u een filterpredikaat moet schrijven met een NULL-kolom die zoekt naar rijen waarvan de kolom anders is dan de invoerparameter. Het predikaat wordt dan:(shippeddate <> @dt AND ((shippeddate IS NULL AND @dt IS NOT NULL) OR (shippeddate IS NOT NULL en @dt IS NULL))).
U ziet duidelijk de behoefte aan een elegantere oplossing die zowel beknopt als optimaal is. Helaas nemen sommigen hun toevlucht tot een niet-standaard oplossing waarbij u de ANSI_NULLS-sessieoptie uitschakelt. Deze optie zorgt ervoor dat SQL Server niet-standaard afhandeling van de gelijkheid (=) en anders dan (<>) operators gebruikt met logica met twee waarden in plaats van logica met drie waarden, waarbij NULL's worden behandeld als niet-NULL-waarden voor vergelijkingsdoeleinden. Dat is tenminste het geval zolang een van de operanden een parameter/variabele of een letterlijke is.
Voer de volgende code uit om de ANSI_NULLS-optie in de sessie uit te schakelen:
SET ANSI_NULLS OFF;
Voer de volgende query uit met een eenvoudig predikaat op basis van gelijkheid:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Deze zoekopdracht retourneert de 21 niet-verzonden bestellingen. U krijgt hetzelfde plan als eerder in figuur 3, met een zoekactie in de index.
Voer de volgende code uit om terug te schakelen naar standaardgedrag waarbij ANSI_NULLS is ingeschakeld:
SET ANSI_NULLS ON;
Vertrouwen op dergelijk afwijkend gedrag wordt sterk afgeraden. In de documentatie staat ook dat ondersteuning voor deze optie in een toekomstige versie van SQL Server zal worden verwijderd. Bovendien realiseren velen zich niet dat deze optie alleen van toepassing is wanneer ten minste één van de operanden een parameter/variabele of een constante is, hoewel de documentatie er vrij duidelijk over is. Het is niet van toepassing bij het vergelijken van twee kolommen, zoals in een join.
Dus hoe ga je om met joins met NULLable join-kolommen als je een match wilt krijgen als de twee zijden NULL's zijn? Gebruik als voorbeeld de volgende code om de tabellen T1 en T2 te maken en in te vullen:
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
De code maakt dekkende indexen op beide tabellen om een join te ondersteunen op basis van de join-sleutels (k1, k2, k3) aan beide zijden.
Gebruik de volgende code om de kardinaliteitsstatistieken bij te werken en de getallen op te blazen zodat de optimizer zou denken dat je met grotere tabellen te maken hebt:
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
Gebruik de volgende code in een poging om de twee tabellen samen te voegen met behulp van eenvoudige op gelijkheid gebaseerde predikaten:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; Net als bij eerdere filtervoorbeelden, leveren ook hier vergelijkingen tussen NULL's met behulp van een gelijkheidsoperator UNKNOWN op, wat resulteert in niet-overeenkomende. Deze query genereert een lege uitvoer:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
Het gebruik van ISNULL of COALESCE zoals in een eerder filtervoorbeeld, en het vervangen van een NULL door een waarde die normaal niet in de gegevens aan beide zijden kan voorkomen, resulteert in een correcte query (ik zal naar deze query verwijzen als Query 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); Deze query genereert de volgende uitvoer:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Echter, net zoals het manipuleren van een gefilterde kolom de SARGability van het filterpredikaat verbreekt, voorkomt het manipuleren van een join-kolom de mogelijkheid om op indexvolgorde te vertrouwen. Dit is te zien in het plan voor deze query zoals weergegeven in figuur 4.
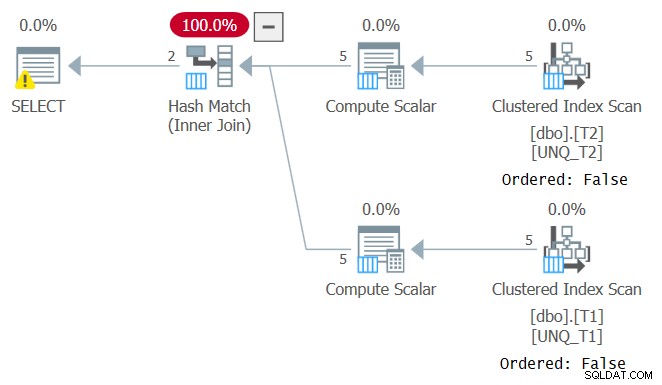 Figuur 4:Plan voor Query 4
Figuur 4:Plan voor Query 4
Een optimaal plan voor deze query is er een die geordende scans toepast van de twee dekkende indexen gevolgd door een Merge Join-algoritme, zonder expliciete sortering. De optimizer koos een ander plan omdat het niet kon vertrouwen op indexvolgorde. Als u een Merge Join-algoritme probeert te forceren met INNER MERGE JOIN, zou het plan nog steeds vertrouwen op ongeordende scans van de indexen, gevolgd door expliciete sortering. Probeer het!
Natuurlijk kunt u de lange predikaten gebruiken die vergelijkbaar zijn met de eerder getoonde SARGable-predikaten voor filtertaken:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); Deze query levert het gewenste resultaat op en stelt de optimizer in staat te vertrouwen op indexvolgorde. We hopen echter een oplossing te vinden die zowel optimaal als beknopt is.
Er is een weinig bekende elegante en beknopte techniek die u kunt gebruiken in zowel joins als filters, zowel voor het identificeren van overeenkomsten als voor het identificeren van niet-overeenkomsten. Deze techniek is al jaren geleden ontdekt en gedocumenteerd, zoals in Paul White's uitstekende artikel Undocumented Query Plans:Equality Comparisons uit 2011. Maar om de een of andere reden lijkt het erop dat nog steeds veel mensen zich er niet van bewust zijn en helaas uiteindelijk suboptimale, lange en niet-standaard oplossingen. Het verdient zeker meer bekendheid en liefde.
De techniek is gebaseerd op het feit dat set-operators zoals INTERSECT en EXCEPT een op onderscheid gebaseerde vergelijkingsbenadering gebruiken bij het vergelijken van waarden, en niet een op gelijkheid of ongelijkheid gebaseerde vergelijkingsbenadering.
Neem als voorbeeld onze join-taak. Als we geen andere kolommen dan de join-sleutels hoefden te retourneren, zouden we een eenvoudige query hebben gebruikt (ik zal ernaar verwijzen als Query 5) met een INTERSECT-operator, zoals:
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
Deze query genereert de volgende uitvoer:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
Het plan voor deze query wordt getoond in figuur 5, wat bevestigt dat de optimizer kon vertrouwen op indexvolgorde en een Merge Join-algoritme kon gebruiken.
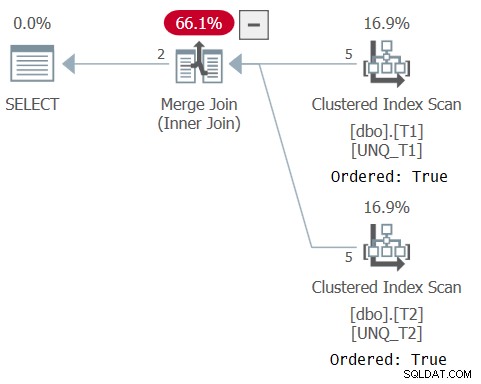 Figuur 5:Plan voor Query 5
Figuur 5:Plan voor Query 5
Zoals Paul in zijn artikel opmerkt, gebruikt het XML-plan voor de set-operator een impliciete IS-vergelijkingsoperator (CompareOp="IS" ) in tegenstelling tot de EQ-vergelijkingsoperator die wordt gebruikt in een normale join (CompareOp="EQ" ). Het probleem met een oplossing die uitsluitend afhankelijk is van een set-operator, is dat het u beperkt tot het retourneren van alleen de kolommen die u vergelijkt. Wat we echt nodig hebben, is een soort hybride tussen een join en een set-operator, waarmee je een subset van de elementen kunt vergelijken terwijl je extra elementen retourneert zoals een join, en op onderscheid gebaseerde vergelijking (IS) zoals een set-operator doet. Dit is mogelijk door een join te gebruiken als de buitenste constructie en een EXISTS-predikaat in de ON-clausule van de join op basis van een query met een INTERSECT-operator die de join-sleutels van de twee kanten vergelijkt, zoals zo (ik zal naar deze oplossing verwijzen als Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
De INTERSECT-operator werkt op twee query's, die elk een set van één rij vormen op basis van de samenvoegsleutels van beide kanten. Als de twee rijen hetzelfde zijn, retourneert de INTERSECT-query één rij; het predikaat EXISTS retourneert TRUE, wat resulteert in een overeenkomst. Als de twee rijen niet hetzelfde zijn, retourneert de INTERSECT-query een lege set; het predikaat EXISTS retourneert FALSE, wat resulteert in een niet-overeenkomende.
Deze oplossing genereert de gewenste output:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Het plan voor deze zoekopdracht wordt getoond in figuur 6, wat bevestigt dat de optimizer kon vertrouwen op indexvolgorde.
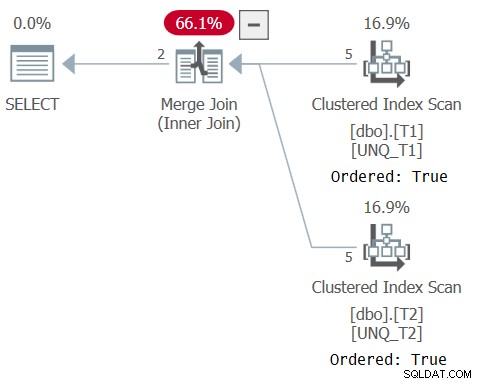 Figuur 6:Plan voor Query 6
Figuur 6:Plan voor Query 6
U kunt een vergelijkbare constructie gebruiken als een filterpredikaat met een kolom en een parameter/variabele om overeenkomsten te zoeken op basis van onderscheidbaarheid, zoals:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Het plan is hetzelfde als het eerder in figuur 3 getoonde.
Je kunt het predikaat ook ontkennen om te zoeken naar niet-overeenkomende, zoals:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Deze query genereert de volgende uitvoer:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
U kunt ook een positief predikaat gebruiken, maar INTERSECT vervangen door BEHALVE, zoals:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Houd er rekening mee dat de plannen in de twee gevallen kunnen verschillen, dus zorg ervoor dat u beide kanten op experimenteert met grote hoeveelheden gegevens.
Conclusie
NULL's voegen hun deel van de complexiteit toe aan het schrijven van uw SQL-code. U wilt altijd nadenken over het potentieel voor de aanwezigheid van NULL's in de gegevens, en ervoor zorgen dat u de juiste queryconstructies gebruikt en de relevante logica aan uw oplossingen toevoegt om NULL's correct af te handelen. Ze negeren is een zekere manier om te eindigen met bugs in uw code. Deze maand heb ik me gericht op wat NULL's zijn en hoe ze worden verwerkt in vergelijkingen met constanten, variabelen, parameters en kolommen. Volgende maand ga ik verder met de berichtgeving door het bespreken van inconsistenties in de NULL-behandeling in verschillende taalelementen en het ontbreken van standaardfuncties voor NULL-behandeling.