Geïndexeerde weergaven kunnen in elke editie van SQL Server worden gemaakt, maar er zijn een aantal gedragingen waarmee u rekening moet houden als u er het meeste uit wilt halen.
Automatische statistieken vereisen een NOEXPAND-hint
SQL Server kan automatisch statistieken maken om te helpen bij het schatten van kardinaliteit en op kosten gebaseerde besluitvorming tijdens query-optimalisatie. Deze functie werkt zowel met geïndexeerde weergaven als met basistabellen, maar alleen als de weergave expliciet wordt genoemd in de query en de NOEXPAND hint is opgegeven. (Er is altijd een statistiekobject gekoppeld aan elke index in een weergave, het is het automatisch genereren en onderhouden van statistieken die niet zijn gekoppeld aan een index waar we het hier over hebben.)
Als u gewend bent om met niet-Enterprise-edities van SQL Server te werken, is dit gedrag u misschien nog nooit eerder opgevallen. Lagere edities van SQL Server vereisen de NOEXPAND hint om een queryplan te maken dat toegang heeft tot een geïndexeerde weergave. Wanneer NOEXPAND is opgegeven, worden automatische statistieken gemaakt op geïndexeerde weergaven, precies zoals bij gewone tabellen.
Voorbeeld – Standaardeditie met NOEXPAND
Met behulp van SQL Server 2012 Standard Edition en de Adventure Works-voorbeelddatabase maken we eerst een weergave die twee verkooptabellen verbindt en de totale bestelhoeveelheid per klant en product berekent:
WEERGAVE MAKEN dbo.CustomerOrdersMET SCHEMABINDING ASSELECT SOH.CustomerID, SOD.ProductID, OrderQty =SUM(SOD.OrderQty), NumRows =COUNT_BIG(*)FROM Sales.SalesOrderDetail AS SODJOIN Sales.SalesOrder =OD.OD SOH ON .SalesOrderIDGROUP DOOR SOH.CustomerID, SOD.ProductID;
Om ervoor te zorgen dat deze weergave statistieken ondersteunt, moeten we deze realiseren door een unieke geclusterde index toe te voegen. De combinatie van klant- en product-ID is gegarandeerd uniek in de weergave (per definitie), dus die zullen we als sleutel gebruiken. We zouden de twee kolommen in beide richtingen in de index kunnen specificeren, maar ervan uitgaande dat we verwachten dat meer zoekopdrachten per product zullen worden gefilterd, maken we Product-ID de leidende kolom. Deze actie creëert ook indexstatistieken, met een histogram opgebouwd uit product-ID-waarden.
CREER UNIEKE GECLUSTERDE INDEX cuq ON dbo.CustomerOrders (ProductID, CustomerID);
We worden nu gevraagd om een query te schrijven die het totale aantal bestellingen per klant laat zien, voor een bepaald assortiment producten. We verwachten dat een uitvoeringsplan met behulp van de geïndexeerde weergave een effectieve strategie zal zijn, omdat het een samenvoeging vermijdt en werkt op gegevens die al gedeeltelijk zijn geaggregeerd. Aangezien we SQL Server Standard Edition gebruiken, moeten we de weergave expliciet specificeren en een NOEXPAND gebruiken hint om een queryplan te maken dat toegang heeft tot de geïndexeerde weergave:
SELECTEER CO.CustomerID, SUM(CO.OrderQty)VAN dbo.CustomerOrders ALS CO MET (NOEXPAND)WHERE CO.ProductID TUSSEN 711 EN 718GROEP OP CO.CustomerID;
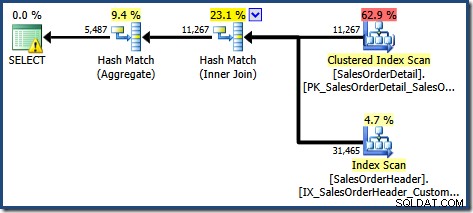
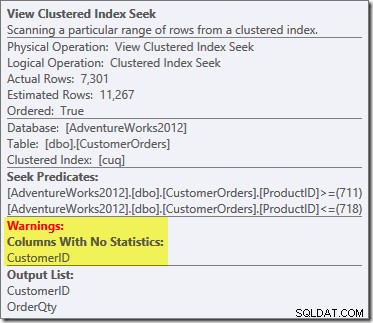
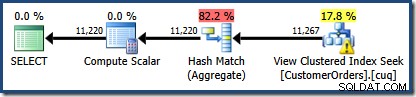
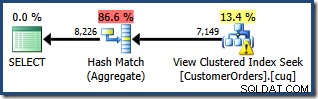
Het geproduceerde uitvoeringsplan toont een zoekactie op de geïndexeerde weergave om rijen te vinden voor de producten van belang, gevolgd door een aggregatie om de totale hoeveelheid per klant te berekenen:
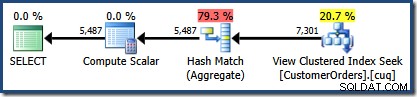
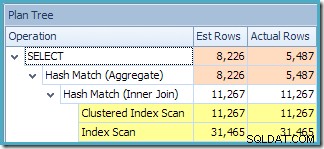
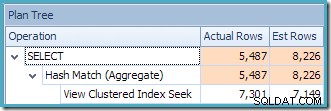
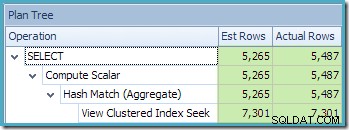
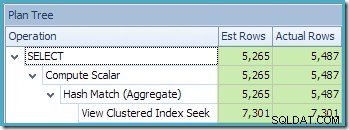
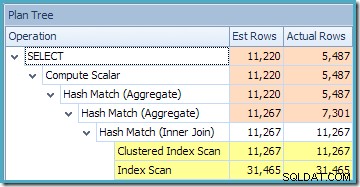
De Plan Tree-weergave van SQL Sentry Plan Explorer laat zien dat de schatting van de kardinaliteit precies correct is voor het zoeken naar geïndexeerde weergaven, en zeer goed voor het resultaat van het aggregaat:
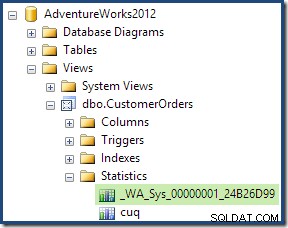
Als onderdeel van het compilatie- en optimalisatieproces voor deze query heeft SQL Server een extra statistiekobject gemaakt in de kolom Klant-ID van de geïndexeerde weergave. Deze statistiek is opgesteld omdat het verwachte aantal en de distributie van klant-ID's belangrijk kan zijn, bijvoorbeeld bij het kiezen van een aggregatiestrategie. We kunnen de nieuwe statistiek zien met Management Studio Object Explorer:
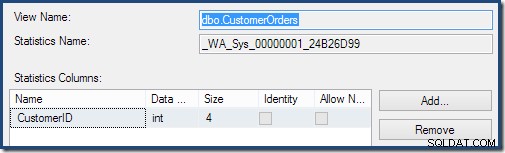
Dubbelklikken op het statistiekobject bevestigt dat het is gemaakt vanuit de kolom Klant-ID in de weergave (geen basistabel):
Geïndexeerde weergaven kunnen de kardinaliteitsschatting verbeteren
We gebruiken nog steeds de Standard Edition, we laten nu de geïndexeerde weergave vallen en maken deze opnieuw (waardoor ook de weergavestatistieken worden verwijderd) en voeren de query opnieuw uit, dit keer met de NOEXPAND hint uitgecommentarieerd:
SELECTEER CO.CustomerID, SUM(CO.OrderQty)VAN dbo.CustomerOrders AS CO --MET (NOEXPAND)WAAR CO.ProductID TUSSEN 711 EN 718GROEP OP CO.CustomerID;
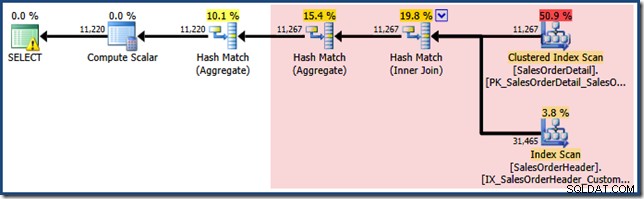
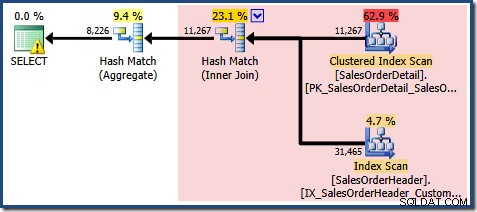
Zoals verwacht bij gebruik van Standard Edition zonder NOEXPAND , werkt het resulterende queryplan op de basistabellen in plaats van de weergave rechtstreeks:

De gevarendriehoek op de root-operator in het bovenstaande plan waarschuwt ons voor een potentieel bruikbare index op de tabel met verkooporderdetails, die niet belangrijk is voor onze huidige doeleinden. Deze compilatie maakt geen statistieken over de geïndexeerde weergave. De enige statistiek in de weergave na het compileren van de query is de statistiek die is gekoppeld aan de geclusterde index:
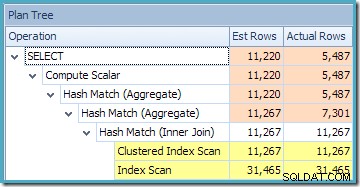
De Plan Tree-weergave voor de query laat zien dat de schatting van de kardinaliteit correct is voor de twee tabelscans en de join, maar een stuk slechter voor de andere planoperators:
De geïndexeerde weergave gebruiken met een NOEXPAND hint resulteerde in nauwkeurigere schattingen voor onze testquery omdat informatie van betere kwaliteit beschikbaar was uit statistieken over de weergave, met name de statistieken die zijn gekoppeld aan de weergave-index.
Als algemene regel geldt dat de nauwkeurigheid van statistische informatie vrij snel achteruit gaat als deze wordt doorgegeven en wordt gewijzigd door queryplan-operators. Simpele joins zijn in dit opzicht vaak niet slecht, maar informatie over het resultaat van een aggregatie is vaak niet beter dan een gefundeerde gok. Het kan een nuttige techniek zijn om de kwaliteit en robuustheid van het plan te verhogen door de query-optimizer nauwkeurigere informatie te verstrekken met behulp van statistieken over geïndexeerde weergaven.
Een weergave zonder NOEXPAND kan een inferieur plan opleveren
Het hierboven getoonde zoekplan (Standaardeditie, zonder NOEXPAND ) is eigenlijk minder optimaal dan wanneer we de query zelf tegen de basistabellen hadden geschreven, in plaats van de query-optimizer de weergave te laten uitbreiden. De onderstaande query drukt dezelfde logische vereiste uit, maar verwijst niet naar de weergave:
SELECTEER SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID TUSSEN 711 EN 718GROUP DOOR SOH.CustomerID;
Deze query levert het volgende uitvoeringsplan op:
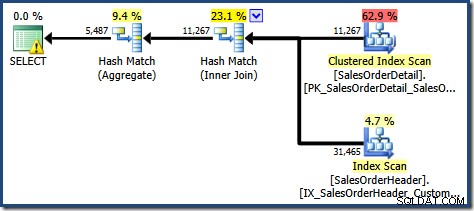
Dit plan bevat één aggregatiebewerking minder dan voorheen. Toen weergave-uitbreiding werd gebruikt, was de query-optimizer helaas niet in staat om een redundante aggregatiebewerking te verwijderen, wat resulteerde in een minder efficiënt uitvoeringsplan. De uiteindelijke kardinaliteitsschatting voor de nieuwe zoekopdracht is ook iets beter dan wanneer naar de geïndexeerde weergave werd verwezen zonder NOEXPAND :
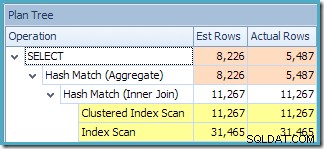
Desalniettemin zijn de beste schattingen nog steeds die geproduceerd bij het verwijzen naar de geïndexeerde weergave met NOEXPAND (voor het gemak hieronder herhaald):
Enterprise Edition en Matching bekijken
Op een Enterprise Edition-instantie kan de query-optimizer mogelijk een geïndexeerde weergave gebruiken, zelfs als de query de weergave niet expliciet vermeldt. Als de optimizer een deel van de zoekstructuur kan matchen met een geïndexeerde weergave, kan hij ervoor kiezen om dit te doen, op basis van zijn schatting van de kosten van het al dan niet gebruiken van de weergave. De view-matching-logica is redelijk slim, maar heeft wel limieten die in de praktijk vrij gemakkelijk te bereiken zijn. Zelfs wanneer weergave-matching succesvol is, kan de optimizer nog steeds worden misleid door onnauwkeurige kostenramingen.
De zoekhint EXPAND VIEWS
Om te beginnen met de zeldzamere mogelijkheden, kunnen er gevallen zijn waarin een query verwijst naar een geïndexeerde weergave, maar een beter plan zou worden verkregen door in plaats daarvan toegang te krijgen tot de basistabellen. In deze omstandigheden is de vraaghint EXPAND VIEWS kan worden gebruikt:
SELECTEER CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders ALS COWHERE CO.ProductID TUSSEN 711 EN 718GROEP DOOR CO.CustomerIDOPTION (UITBREID VIEWS);
In Enterprise Edition levert deze query hetzelfde plan op als in Standard Edition wanneer de NOEXPAND hint is weggelaten (inclusief de redundante aggregatiebewerking):

Even terzijde, de EXPAND VIEWS hint is slecht genoemd, naar mijn mening. SQL Server breidt weergavedefinities altijd uit in een query, tenzij de NOEXPAND hint is opgegeven. De EXPAND VIEWS hint schakelt regels in de optimizer uit die delen van de uitgevouwen boom terug kunnen matchen met geïndexeerde weergaven. Bij het ontbreken van een van beide hints, breidt SQL Server eerst een weergave uit naar de basistabeldefinitie en overweegt later om terug te koppelen naar geïndexeerde weergaven. Een betere naam voor de EXPAND VIEWS hint kan zijn geweest DISABLE INDEXED VIEW MATCHING , want dat is wat het doet.
De EXPAND VIEWS hint wordt waarschijnlijk het vaakst gebruikt om te voorkomen dat een zoekopdracht tegen basistabellen wordt gekoppeld aan een geïndexeerde weergave:
SELECTEER SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID TUSSEN 711 EN 718GROUP DOOR SOH.CustomerIDOPTION (EXPAND UITBREIDING>De query-hint resulteert in hetzelfde uitvoeringsplan en dezelfde schattingen als toen we de Standard Edition gebruikten en dezelfde query met alleen een basistabel:
Enterprise View Matching en Statistieken
Zelfs in Enterprise Edition worden niet-indexweergavestatistieken nog steeds alleen gemaakt als de
NOEXPANDhint wordt gebruikt. Voor alle duidelijkheid:de functie voor het matchen van weergaven alleen voor bedrijven resulteert nooit in het maken of bijwerken van weergavestatistieken. Dit niet-intuïtieve gedrag is de moeite waard om een beetje te onderzoeken, omdat het verrassende bijwerkingen kan hebben.We voeren nu onze basisquery uit tegen de weergave op een Enterprise Edition-instantie, zonder enige hint:
SELECTEER CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders ALS COWHERE CO.ProductID TUSSEN 711 EN 718GROUP OP CO.CustomerID;
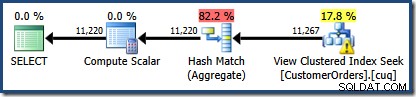
Nieuw is de gevarendriehoek op de View Clustered Index Seek. De tooltip toont de details:
We hebben geen
NOEXPAND. gebruikt hint, dus statistieken over de kolom Klant-ID van de geïndexeerde weergave werden niet automatisch gemaakt. De statistieken over klant-ID zijn in dit vereenvoudigde voorbeeld niet erg belangrijk, maar dat zal niet altijd het geval zijn.Nieuwsgierige schattingen van kardinaliteit
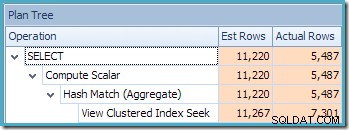
Het tweede interessante is dat de kardinaliteitsschattingen slechter lijken te zijn dan alle gevallen die we tot nu toe zijn tegengekomen, inclusief de voorbeelden van de Standard Edition.
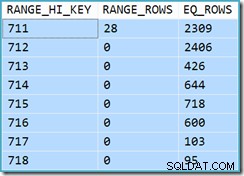
Het is aanvankelijk moeilijk om te zien waar de schatting van de kardinaliteit voor de View Clustered Index Seek (11.267) vandaan kwam. We verwachten dat de schatting is gebaseerd op product-ID-histogramgegevens uit de statistieken die zijn gekoppeld aan de geclusterde weergave-index. Het relevante deel van dit histogram wordt hieronder weergegeven:
DBCC SHOW_STATISTICS ('dbo.CustomerOrders', 'cuq') MET HISTOGRAM;
Aangezien de tabel niet is gewijzigd sinds de statistieken zijn gemaakt, verwachten we dat de schatting een eenvoudige som is van RANGE_ROWS en EQ_ROWS voor product-ID-waarden tussen 711 en 718 (merk op dat de schatting de 28 RANGE_ROWS moet uitsluiten die worden weergegeven voor de 711-invoer aangezien die rijen onder de 711-sleutelwaarde bestaan). De som van de getoonde EQ_ROWS is 7.301. Dit is precies het aantal rijen dat daadwerkelijk door de weergave wordt geretourneerd - dus waar komt de schatting van 11.267 vandaan?
Het antwoord ligt in de manier waarop weergave-matching momenteel werkt. Onze zoekopdracht specificeerde niet de
NOEXPANDhint, dus initiële kardinaliteitsschattingen zijn gebaseerd op de view-expanded query tree. Dit is het gemakkelijkst te zien door opnieuw te kijken naar het geschatte abonnement voor dezelfde zoekopdracht metEXPAND VIEWSgespecificeerd:
Het rood gearceerde gebied vertegenwoordigt het deel van de boom dat is vervangen door activiteit voor het matchen van weergaven. De outputkardinaliteit van dit gebied is 11.267. Het niet-gearceerde deel met de schatting van 11.220 wordt niet beïnvloed door weergave-matching. Dit zijn precies de schattingen die we wilden uitleggen:
View matching verving eenvoudigweg het rood gearceerde gebied door een logisch equivalente zoekactie op de geïndexeerde weergave. Het heeft geen statistische informatie uit de weergave gebruikt om de kardinaliteitsschatting opnieuw te berekenen.
Tot op zekere hoogte kunt u begrijpen waarom het op deze manier zou kunnen werken:over het algemeen is er weinig reden om te verwachten dat een schatting die is berekend op basis van de ene reeks statistische informatie, beter is dan een andere. Er zou kunnen worden gesteld dat statistieken van geïndexeerde weergaven hier waarschijnlijk nauwkeuriger zijn, vergeleken met de post-join afgeleide statistieken in het rood gearceerde gebied, maar het kan lastig zijn om dat te generaliseren, of om correct te verklaren hoe snel verschillende bronnen van statistische informatie kan verouderd raken als de onderliggende gegevens veranderen.
Je zou ook kunnen stellen dat als we er zo zeker van waren dat de geïndexeerde weergave-informatie beter was, we een
NOEXPANDzouden hebben gebruikt hint.Nog meer merkwaardige schattingen van kardinaliteit
Een nog interessantere situatie doet zich voor met Enterprise Edition als we de query schrijven tegen de basistabellen en vertrouwen op geautomatiseerde weergave-overeenkomst:
SELECTEER SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD ON SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProductID TUSSEN 711 EN 718GROUP DOOR SOH.CustomerID;
De waarschuwing voor ontbrekende statistieken is hetzelfde als voorheen en heeft dezelfde uitleg. De interessantere eigenschap is dat we nu een lagere schatting hebben voor het aantal rijen geproduceerd door de View Clustered Index Seek (7.149) en een hogere schatting voor het aantal rijen dat wordt geretourneerd door de aggregatie (8.226).
Om dit punt te benadrukken, lijkt dit queryplan gebaseerd te zijn op het idee dat 7.149 bronrijen kunnen worden geaggregeerd om 8.226 rijen te produceren!
Een deel van de uitleg is hetzelfde als voorheen. De
EXPAND VIEWSzoekplan, met het rode gebied dat zal worden vervangen door weergaveovereenkomsten, wordt hieronder weergegeven:
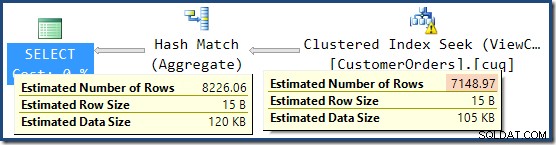
Dit verklaart waar de uiteindelijke schatting van 8.226 vandaan komt, maar hoe zit het met de 7.149 rijschatting? Volgens de logica die eerder is gezien, lijkt het erop dat de weergave een schatting van 11.267 rijen zou moeten tonen?
Het antwoord is dat de 7.149 schatting een gok is. Ja werkelijk. De geïndexeerde weergave bevat in totaal 79.433 rijen. Het magische gokpercentage voor het predikaat Product-ID BETWEEN is 9% - met 0,09 * 79433 =7148,97 rijen. Het SSMS-queryplan laat zien dat deze berekening precies correct is, zelfs vóór afronding:
In deze situatie lijkt de SQL Server-optimizer de voorkeur te hebben gegeven aan een schatting op basis van de geïndexeerde weergave-kardinaliteit boven de schatting van de post-join-kardinaliteit van de vervangen substructuur. Nieuwsgierig.
Samenvatting
De
NOEXPAND. gebruiken hint garandeert dat een geïndexeerde weergave wordt gebruikt in het uiteindelijke queryplan, en zorgt ervoor dat niet-indexstatistieken automatisch worden gemaakt, onderhouden en gebruikt door de query-optimizer.NOEXPANDgebruiken zorgt er ook voor dat de initiële kardinaliteitsschattingen gebaseerd zijn op geïndexeerde weergave-informatie in plaats van afgeleid te worden van basistabellen.Als
NOEXPANDniet is opgegeven, worden weergaveverwijzingen altijd vervangen door hun basistabeldefinities voordat de querycompilatie begint (en dus vóór de initiële schatting van de kardinaliteit). Alleen in Enterprise-SKU's kunnen geïndexeerde weergaven later in het optimalisatieproces worden teruggeplaatst in de querystructuur.De
EXPAND VIEWSqueryhint voorkomt dat het optimalisatieprogramma de geïndexeerde weergaveovereenkomsten van Enterprise Edition uitvoert. Dit is van toepassing, ongeacht of de query oorspronkelijk naar een geïndexeerde weergave verwees of niet. Wanneer weergavevergelijking wordt uitgevoerd, kan in sommige omstandigheden een bestaande kardinaliteitsschatting worden vervangen door een schatting.Statistieken die worden weergegeven als ontbrekend in een geïndexeerde weergave kunnen handmatig worden gemaakt, maar de optimizer zal ze over het algemeen niet gebruiken voor zoekopdrachten die geen gebruik maken van een
NOEXPANDhint.Het gebruik van geïndexeerde weergaven kan de schatting van de kardinaliteit verbeteren, vooral als de weergave samenvoegingen of aggregaties bevat. Query's hebben de meeste kans om te profiteren van nauwkeurigere weergavestatistieken als
NOEXPANDis opgegeven.