[ Deel 1 | Deel 2 | Deel 3 ]
Onlangs vroeg iemand op het werk om meer ruimte voor een snelgroeiende tafel. Destijds had het 3,75 miljard rijen, gepresenteerd op 143 miljoen pagina's en ongeveer 1,14 TB in beslag. Natuurlijk kunnen we altijd meer schijf naar een tafel gooien, maar ik wilde kijken of we dit efficiënter konden schalen dan de huidige lineaire trend. Klinkt als een geweldige klus voor compressie, toch? Maar ik wilde ook een aantal andere oplossingen uitproberen, waaronder columnstore – waar mensen verrassend weinig zin in hebben. Ik ben geen Niko, maar ik wilde toch een poging doen om te kijken wat het hier voor ons zou kunnen betekenen.
Merk op dat ik me op dit moment niet concentreer op het rapporteren van werklast of andere leesqueryprestaties - ik wil alleen zien welke impact ik kan hebben op de opslag (en geheugen) voetafdruk van deze gegevens.
Hier is de originele tafel. Ik heb tabel- en kolomnamen veranderd om de onschuldigen te beschermen, maar al het andere is relatief nauwkeurig.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Er zijn nog wat andere kleine dingen die breder zijn dan ze zouden moeten zijn en/of die rijcompressie zou kunnen opschonen, zoals die numeric(24,12) en bigint kolommen die mogelijk voortijdig te groot zijn, maar ik ga niet terug naar het applicatieteam om erachter te komen of er weinig efficiëntie is, en ik ga rijcompressie voor deze oefening overslaan en me concentreren op pagina- en columnstore-compressie.
Dit is een kopie van de gegevens, op een inactieve server (8 cores, 64 GB RAM), met voldoende schijfruimte (ruim 6 TB). Laten we dus eerst een aantal bestandsgroepen toevoegen, één voor standaard geclusterde columnstore en één voor een gepartitioneerde versie van de tabel (waarbij alle partities behalve de meest recente worden gecomprimeerd met COLUMNSTORE_ARCHIVE , aangezien al die oudere gegevens nu "alleen lezen en niet vaak" zijn:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
En dan nog wat bestanden voor deze bestandsgroepen (één bestand per kern, mooi en uniform van 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Op deze specifieke hardware (YMMV!), duurde dit ongeveer 10 seconden per bestand en leverde het volgende op:
Om de partities te genereren, heb ik de gegevens naïef "gelijkmatig" verdeeld - dat dacht ik tenminste. Ik heb gewoon de 3,75 miljard rijen genomen en gepartitioneerd in iets waarvan ik dacht dat het beheersbaar zou zijn:38 partities met 100 miljoen rijen in de eerste 37 partities en de rest in de laatste. (Vergeet niet dat dit slechts deel 1 is! Er is hier een inherente aanname over een gelijkmatige verdeling van waarden in de brontabel, en ook over wat optimaal is voor de populatie van rijgroepen in de doeltabel.) Het maken van het partitieschema en de functie hiervoor is als volgt volgt:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Ik gebruik RANGE LEFT omdat, zoals Cathrine Wilhelmsen me eraan blijft herinneren, dit betekent dat de grenswaarde een deel is van de scheidingswand aan de linkerkant. Met andere woorden, de waarden die ik specificeer zijn de maximale waarden in elke partitie (met datums wil je meestal RANGE RIGHT ).
Ik heb toen twee kopieën van de tabel gemaakt, één op elke bestandsgroep. De eerste had een standaard geclusterde columnstore-index, met als enige verschillen de OID kolom is geen IDENTITY en de berekende kolom is slechts een varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
De tweede was gebouwd op het partitieschema, dus had eerst een benoemde PK nodig, die vervolgens moest worden vervangen door een geclusterde columnstore-index (hoewel Brent Ozar in dit korte bericht laat zien dat er een niet-intuïtieve syntaxis is die dit in minder stappen zal bereiken ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Vervolgens heb ik, om archiefcompressie op alle behalve de laatste partitie te zetten, het volgende uitgevoerd:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Nu was ik klaar om deze tabellen met gegevens te vullen, de benodigde tijd en de resulterende grootte te meten en te vergelijken. Ik heb een handig batchscript van Andy Mallon aangepast en de rijen opeenvolgend in beide tabellen ingevoegd, met een batchgrootte van 10 miljoen rijen. Er is veel meer dan dit in het echte script (inclusief het bijwerken van een wachtrijtabel met voortgang), maar in wezen:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Nadat ik beide columnstore-tabellen had gevuld met de originele (niet-gecomprimeerde) bron, heb ik die partities opnieuw opgebouwd om elke rommel van rijgroepen en woordenboeken op te ruimen. Ten slotte heb ik paginacompressie toegepast op de brontabel. Dit waren de timings en de compressieresultaten van elk type:
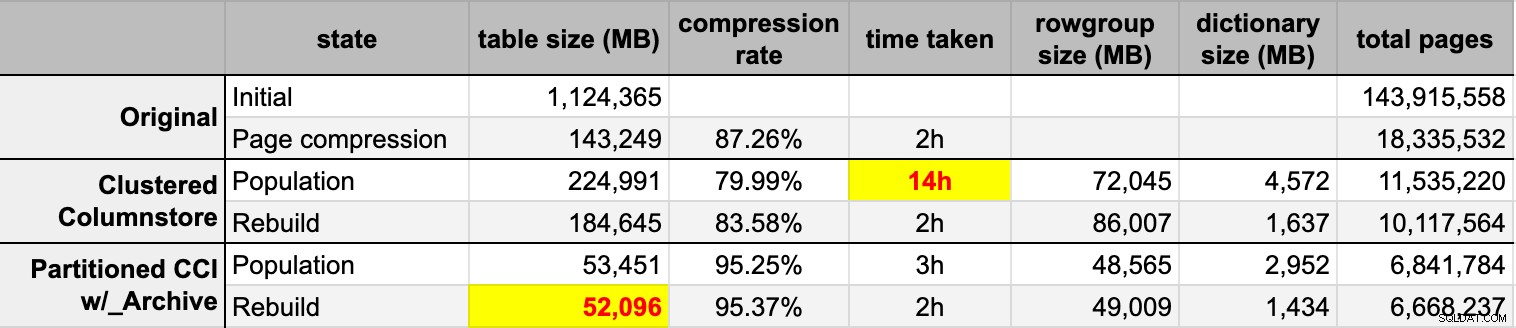
Ik ben zowel onder de indruk als teleurgesteld. Onder de indruk omdat deze gegevens heel goed worden gecomprimeerd - het verkleinen van de opslagvoetafdruk tot 5% van de oorspronkelijke 1TB is best verbazingwekkend. Teleurgesteld omdat:
- Ik heb die gegevensbestanden manier gemaakt te groot.
- Ik begrijp niet wat er is gebeurd met de 14 uur durende eerste columnstore-compressie:
- Ik heb geen geheugen- of logdruk waargenomen.
- Er waren geen bestandsgroeigebeurtenissen.
- Helaas heb ik er niet aan gedacht om wachttijden bij te houden. Nee, ik ga het niet nog een keer proberen. :-)
- Paginacompressie presteerde beter dan reguliere columnstore-compressie - misschien vanwege de gegevens.
- Het opnieuw opbouwen van de columnstore-archiefpartities kostte veel CPU-tijd voor bijna nul winst.
In komende berichten, en na het bekijken van mijn aantekeningen van een geweldige columnstore-presentatie door Joe Obbish op PASS Summit (waar ik rechtstreeks naar zou linken, als PASS maar wist hoe de gebruikersinterface moest), zal ik een beetje praten over de veranderingen die ik zal make aan de serverconfiguratie en mijn populatiescript om te zien of ik betere prestaties kan krijgen van de columnstore-populatie.
[ Deel 1 | Deel 2 | Deel 3 ]