Stel dat u alle patiënten wilt vinden die nog nooit een griepprik hebben gehad. Of, in AdventureWorks2012 , zou een soortgelijke vraag kunnen zijn:"laat me alle klanten zien die nog nooit een bestelling hebben geplaatst." Uitgedrukt met NIET IN , een patroon dat ik maar al te vaak zie, dat er ongeveer zo uitziet (ik gebruik de vergrote kop- en detailtabellen uit dit script van Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Als ik dit patroon zie, krimp ik ineen. Maar niet om prestatieredenen - het creëert in dit geval tenslotte een goed genoeg plan:
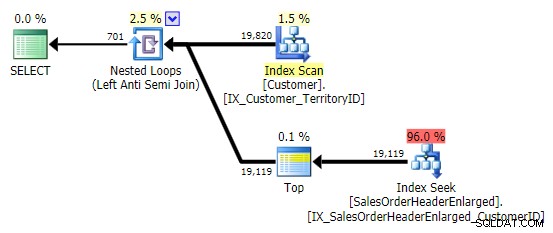
Het grootste probleem is dat de resultaten verrassend kunnen zijn als de doelkolom NULLable is (SQL Server verwerkt dit als een linker anti semi-join, maar kan je niet op betrouwbare wijze vertellen of een NULL aan de rechterkant gelijk is aan – of niet gelijk is aan – de referentie aan de linkerkant). Optimalisatie kan zich ook anders gedragen als de kolom NULL-able is, zelfs als deze eigenlijk geen NULL-waarden bevat (Gail Shaw sprak hierover in 2010).
In dit geval is de doelkolom niet nullable, maar ik wilde de mogelijke problemen met NOT IN vermelden – In een volgende post kan ik deze problemen grondiger onderzoeken.
TL;DR-versie
In plaats van NIET IN , gebruik een gecorreleerde NIET BESTAAT voor dit querypatroon. Altijd. Andere methoden kunnen het qua prestaties evenaren, terwijl alle andere variabelen hetzelfde zijn, maar alle andere methoden introduceren prestatieproblemen of andere uitdagingen.
Alternatieven
Dus op welke andere manieren kunnen we deze query schrijven?
BUITENSTE TOEPASSING
Een manier om dit resultaat uit te drukken is het gebruik van een gecorreleerde OUTER APPLY .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
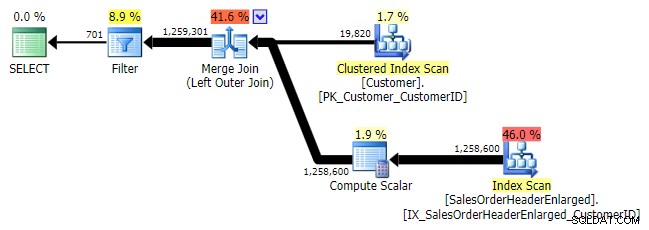
Logischerwijs is dit ook een left anti semi join, maar het resulterende plan mist de left anti semi join operator, en lijkt een stuk duurder te zijn dan de NOT IN gelijkwaardig. Dit komt omdat het niet langer een linkse anti semi-join is; het wordt eigenlijk op een andere manier verwerkt:een outer join brengt alle overeenkomende en niet-overeenkomende rijen binnen, en *vervolgens* wordt een filter toegepast om de overeenkomsten te elimineren:
LINKER BUITENSTE JOIN
Een meer typisch alternatief is LEFT OUTER JOIN waar de rechterkant is NULL . In dit geval zou de vraag zijn:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Dit levert dezelfde resultaten op; echter, net als OUTER APPLY, gebruikt het dezelfde techniek om alle rijen samen te voegen en pas dan de overeenkomsten te elimineren:
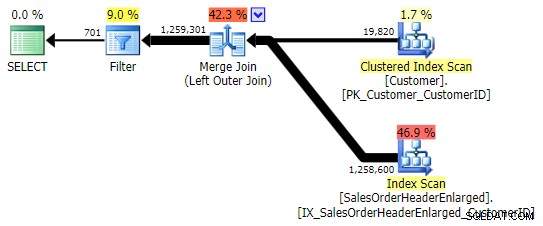
U moet echter voorzichtig zijn met welke kolom u controleert op NULL . In dit geval Klant-ID is de logische keuze omdat het de verbindingskolom is; het is toevallig ook geïndexeerd. Ik had SalesOrderID kunnen kiezen , wat de clustersleutel is, dus het staat ook in de index op CustomerID . Maar ik had een andere kolom kunnen kiezen die niet in de index staat (of die later wordt verwijderd uit) de index die voor de join wordt gebruikt, wat tot een ander plan leidt. Of zelfs een NULL-kolom, wat leidt tot onjuiste (of op zijn minst onverwachte) resultaten, aangezien er geen manier is om onderscheid te maken tussen een rij die niet bestaat en een rij die wel bestaat maar waarbij die kolom NULL . En het is misschien niet duidelijk voor de lezer / ontwikkelaar / probleemoplosser dat dit het geval is. Dus ik zal deze drie ook testen WHERE clausules:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
De eerste variatie levert hetzelfde plan op als hierboven. De andere twee kiezen een hash-join in plaats van een merge-join, en een smallere index in de Klant tabel, hoewel de zoekopdracht uiteindelijk exact hetzelfde aantal pagina's en hoeveelheid gegevens leest. Hoewel de h.SubTotal variatie geeft de juiste resultaten:
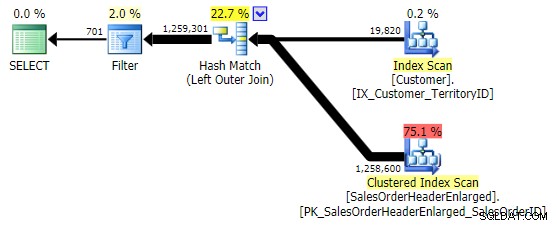
De h.Commentaar variatie niet, omdat het alle rijen bevat waar h.Comment IS NULL , evenals alle rijen die voor geen enkele klant bestonden. Ik heb het subtiele verschil in het aantal rijen in de uitvoer benadrukt nadat het filter is toegepast:
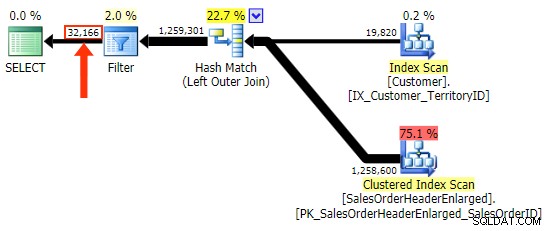
Behalve dat ik voorzichtig moet zijn met het selecteren van kolommen in het filter, is het andere probleem dat ik heb met de LEFT OUTER JOIN vorm is dat het niet zelfdocumenterend is, op dezelfde manier als een inner join in de "oude" vorm van FROM dbo.table_a, dbo.table_b WHERE ... is niet zelfdocumenterend. Daarmee bedoel ik dat het gemakkelijk is om de deelnamecriteria te vergeten wanneer het naar de WHERE . wordt gepusht clausule, of om vermengd te raken met andere filtercriteria. Ik besef dat dit nogal subjectief is, maar het is zo.
BEHALVE
Als we alleen geïnteresseerd zijn in de join-kolom (die per definitie in beide tabellen staat), kunnen we BEHALVE gebruiken – een alternatief dat in deze gesprekken niet veel naar voren lijkt te komen (waarschijnlijk omdat je – meestal – de zoekopdracht moet uitbreiden om kolommen op te nemen die je niet vergelijkt):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Dit komt met exact hetzelfde plan als de NIET IN variatie hierboven:
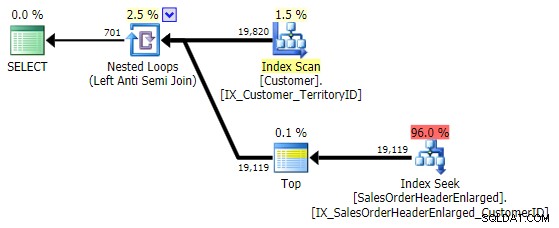
Een ding om in gedachten te houden is dat BEHALVE bevat een impliciete DISTINCT – dus als je gevallen hebt waarin je meerdere rijen met dezelfde waarde in de "linker" tabel wilt hebben, zal dit formulier die duplicaten elimineren. Geen probleem in dit specifieke geval, maar iets om in gedachten te houden – net als UNION versus UNION ALL .
BESTAAT NIET
Mijn voorkeur voor dit patroon is absoluut NIET BESTAAT :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(En ja, ik gebruik SELECT 1 in plaats van SELECT * … niet om prestatieredenen, aangezien het SQL Server niet uitmaakt welke kolom(men) u gebruikt in EXISTS en optimaliseert ze weg, maar gewoon om de bedoeling te verduidelijken:dit herinnert me eraan dat deze "subquery" eigenlijk geen gegevens retourneert.)
De prestaties zijn vergelijkbaar met NIET IN en BEHALVE , en het produceert een identiek plan, maar is niet gevoelig voor de mogelijke problemen veroorzaakt door NULL's of duplicaten:
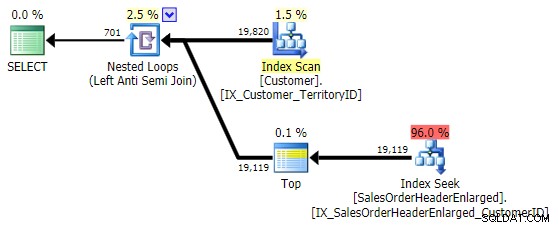
Prestatietests
Ik heb een groot aantal tests uitgevoerd, met zowel een koude als een warme cache, om te bevestigen dat mijn al lang bestaande perceptie over NIET BESTAAT dat het de juiste keuze was, bleef waar. De typische uitvoer zag er als volgt uit:
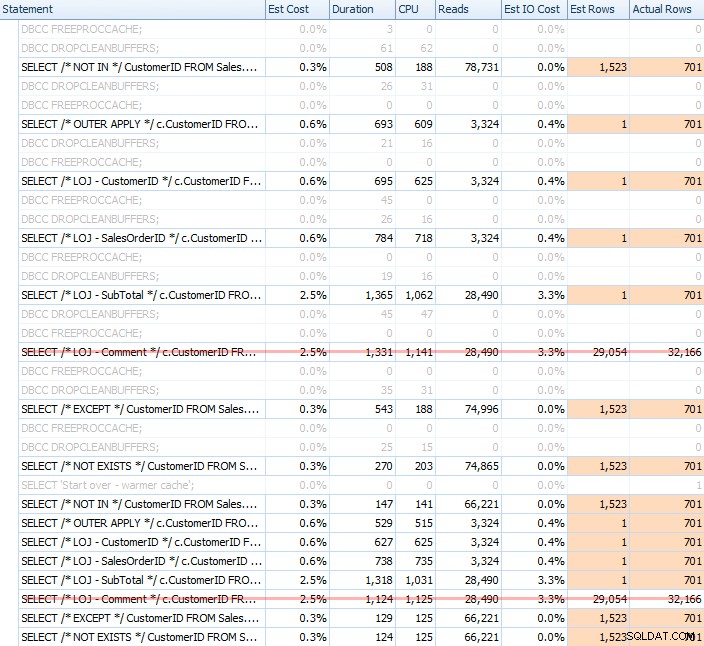
Ik zal het onjuiste resultaat uit de mix halen wanneer ik de gemiddelde prestaties van 20 runs in een grafiek laat zien (ik heb het alleen opgenomen om aan te tonen hoe fout de resultaten zijn), en ik heb de query's in verschillende tests uitgevoerd om er zeker van te zijn dat een zoekopdracht niet consequent profiteerde van het werk van een eerdere zoekopdracht. Gericht op de duur, hier zijn de resultaten:
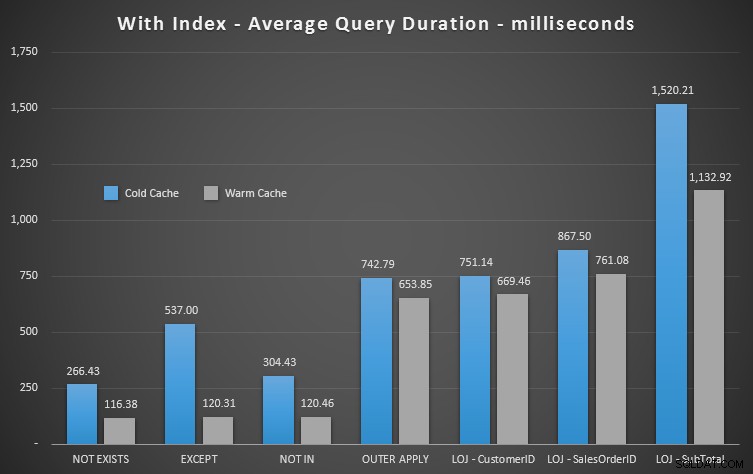
Als we naar de duur kijken en reads negeren, is NOT EXISTS uw winnaar, maar niet zozeer. EXCEPT en NOT IN lopen niet ver achter, maar nogmaals, je moet naar meer kijken dan alleen de prestaties om te bepalen of deze opties geldig zijn, en testen in jouw scenario.
Wat als er geen ondersteunende index is?
Bovenstaande zoekopdrachten profiteren natuurlijk van de index op Sales.SalesOrderHeaderEnlarged.CustomerID . Hoe veranderen deze resultaten als we deze index laten vallen? Ik heb dezelfde reeks tests opnieuw uitgevoerd, nadat ik de index had laten vallen:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Deze keer was er veel minder afwijking qua prestaties tussen de verschillende methoden. Eerst zal ik de plannen voor elke methode laten zien (waarvan de meeste, niet verrassend, het nut aangeven van de ontbrekende index die we zojuist hebben laten vallen). Daarna laat ik een nieuwe grafiek zien die het prestatieprofiel weergeeft, zowel met een koude cache als een warme cache.
NIET IN, BEHALVE, NIET BESTAAN (alle drie waren identiek)
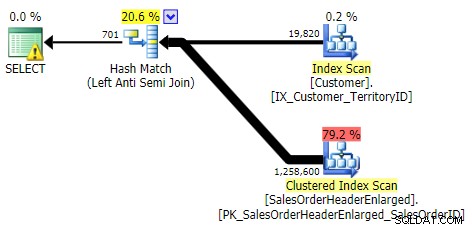
BUITENSTE TOEPASSING
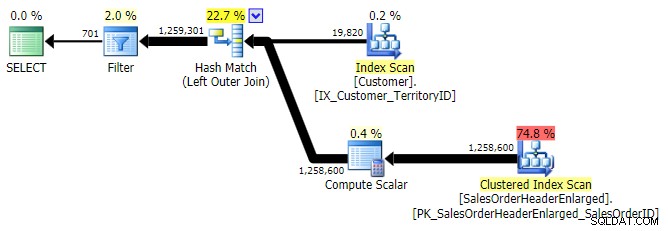
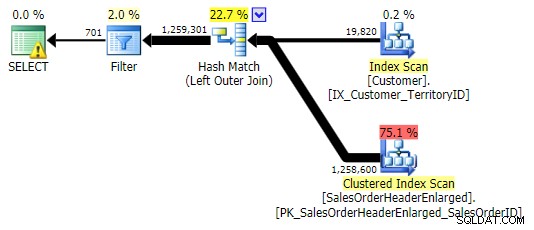
LEFT OUTER JOIN (alle drie waren identiek behalve het aantal rijen)
Prestatieresultaten
We kunnen meteen zien hoe nuttig de index is als we naar deze nieuwe resultaten kijken. In alle gevallen, op één na (de linker outer join die sowieso buiten de index gaat), zijn de resultaten duidelijk slechter als we de index hebben laten vallen:
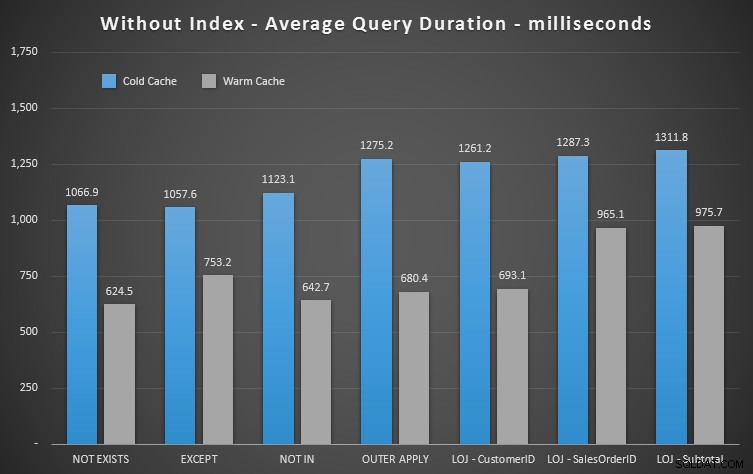
Dus we kunnen zien dat, hoewel er minder merkbare impact is, NIET BESTAAT is nog steeds uw marginale winnaar in termen van duur. En in situaties waarin de andere benaderingen vatbaar zijn voor schemavolatiliteit, is dit ook uw veiligste keuze.
Conclusie
Dit was gewoon een erg langdradige manier om je te vertellen dat, voor het patroon van het vinden van alle rijen in tabel A waar een voorwaarde niet bestaat in tabel B, NIET BESTAAT zal doorgaans uw beste keuze zijn. Maar zoals altijd moet u deze patronen testen in uw eigen omgeving, met behulp van uw schema, gegevens en hardware, en vermengd met uw eigen workloads.