Inleiding
Ontwikkelaars wordt vaak verteld om opgeslagen procedures te gebruiken om de zogenaamde ad-hocquery's te vermijden wat kan resulteren in een onnodig opgeblazen gevoel van de plancache. Zie je, wanneer terugkerende SQL-code inconsistent wordt geschreven of wanneer er code is die dynamische SQL on-the-fly genereert, heeft SQL Server de neiging om een uitvoeringsplan te maken voor elke individuele uitvoering. Dit kan de algehele prestaties verminderen door:
Een compilatiefase eisen voor elke uitvoering van de code.
De plancache opblazen met te veel planhandvatten die niet opnieuw mogen worden gebruikt.
Optimaliseren voor ad-hoc workloads
Een manier waarop dit probleem in het verleden is opgelost, is het optimaliseren van de instantie voor ad-hocwerkbelastingen. Dit kan alleen nuttig zijn als de meeste databases of de belangrijkste databases op de instantie voornamelijk Ad Hoc SQL uitvoeren.
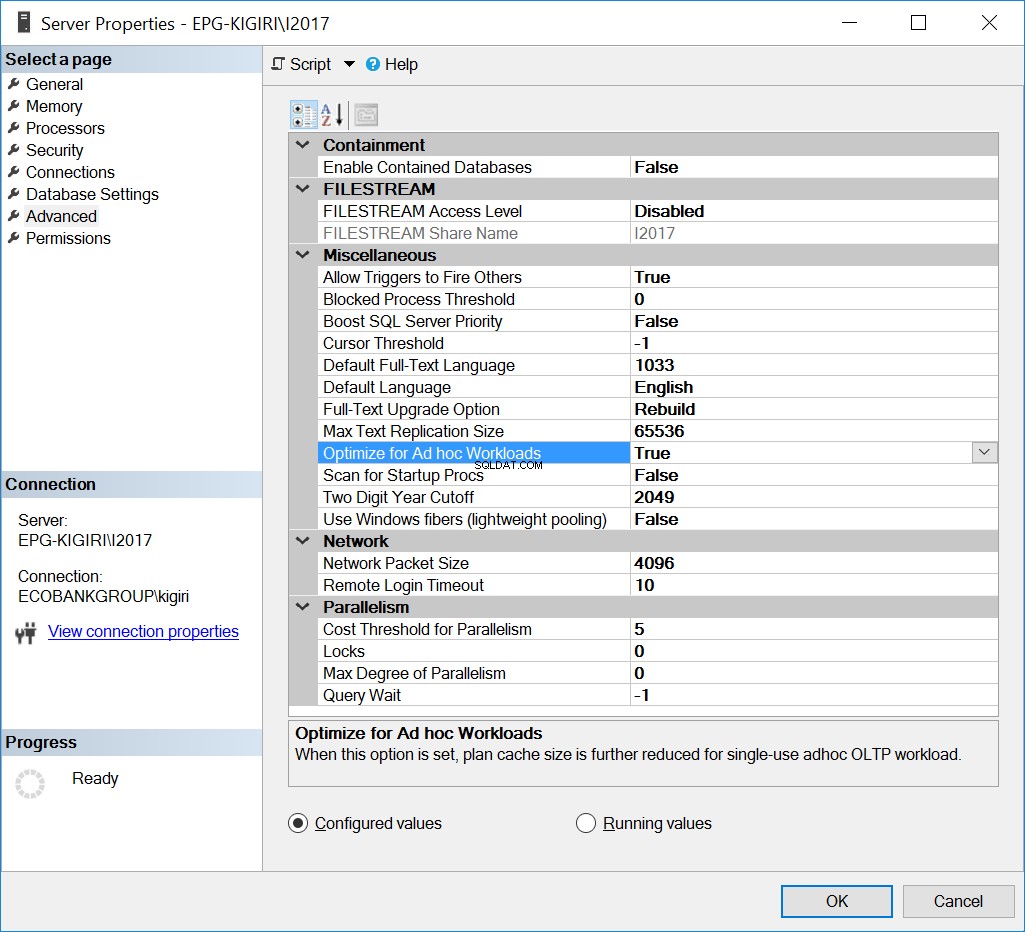
Afb. 1 Optimaliseren voor ad-hoc werklasten
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
In wezen vertelt deze optie SQL Server om een gedeeltelijke versie van het plan op te slaan dat bekend staat als de gecompileerde plan-stub. De stomp neemt veel minder ruimte in beslag dan het hele plan.
Als alternatief voor deze methode benaderen sommige mensen het probleem nogal brutaal en spoelen ze de plancache zo nu en dan door. Of, op een meer zorgvuldige manier, spoel "plannen voor eenmalig gebruik" door met DBCC FREESYSTEMCACHE. Het doorspoelen van de hele plancache heeft zijn nadelen, zoals je misschien al weet.
Opgeslagen procedures en parameters gebruiken
Door opgeslagen procedures te gebruiken, kan men het probleem veroorzaakt door Ad Hoc SQL vrijwel elimineren. Een opgeslagen procedure wordt slechts één keer gecompileerd en hetzelfde plan wordt opnieuw gebruikt voor volgende uitvoeringen van dezelfde of vergelijkbare SQL-query's. Wanneer opgeslagen procedures worden gebruikt om bedrijfslogica te implementeren, ligt het belangrijkste verschil in de SQL-query's die uiteindelijk door SQL Server worden uitgevoerd in de parameters die tijdens de uitvoering worden doorgegeven. Aangezien het plan al bestaat en klaar is voor gebruik, zal SQL Server hetzelfde plan gebruiken, ongeacht welke parameter wordt doorgegeven.
Scheve gegevens
In bepaalde scenario's worden de gegevens waarmee we te maken hebben niet gelijkmatig verdeeld. We kunnen dit aantonen – eerst moeten we een tabel maken:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Onze tabel bevat gegevens van clubleden uit verschillende landen. Een groot aantal clubleden komt uit Ghana, terwijl twee andere landen respectievelijk tien en twee leden hebben. Om gefocust te blijven op de agenda en omwille van de eenvoud heb ik slechts drie landen en dezelfde naam gebruikt voor leden die uit hetzelfde land komen. Ik heb ook een geclusterde index toegevoegd in de ID-kolom en een niet-geclusterde index in de CountryCode-kolom om het effect van verschillende uitvoeringsplannen voor verschillende waarden aan te tonen.
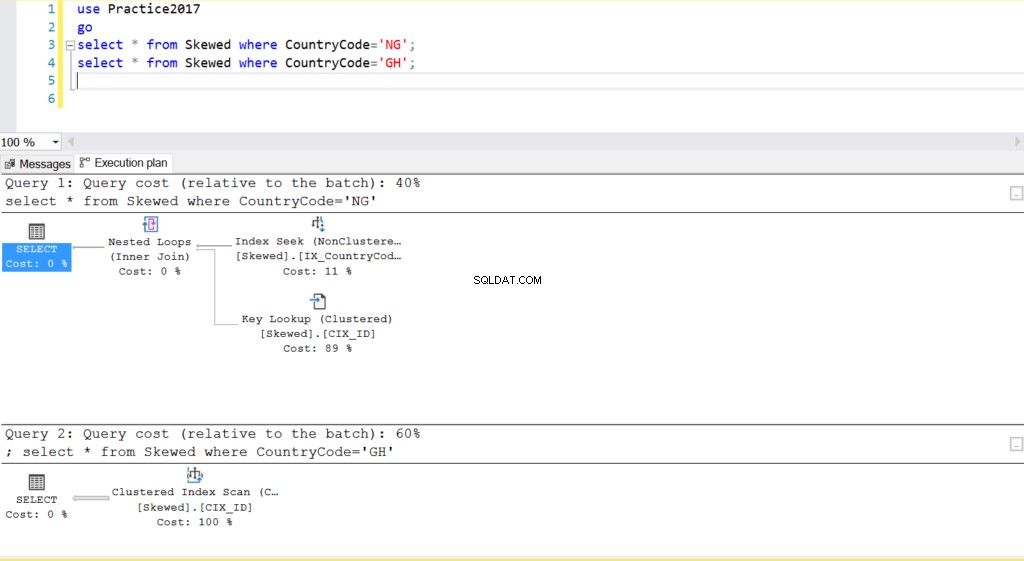
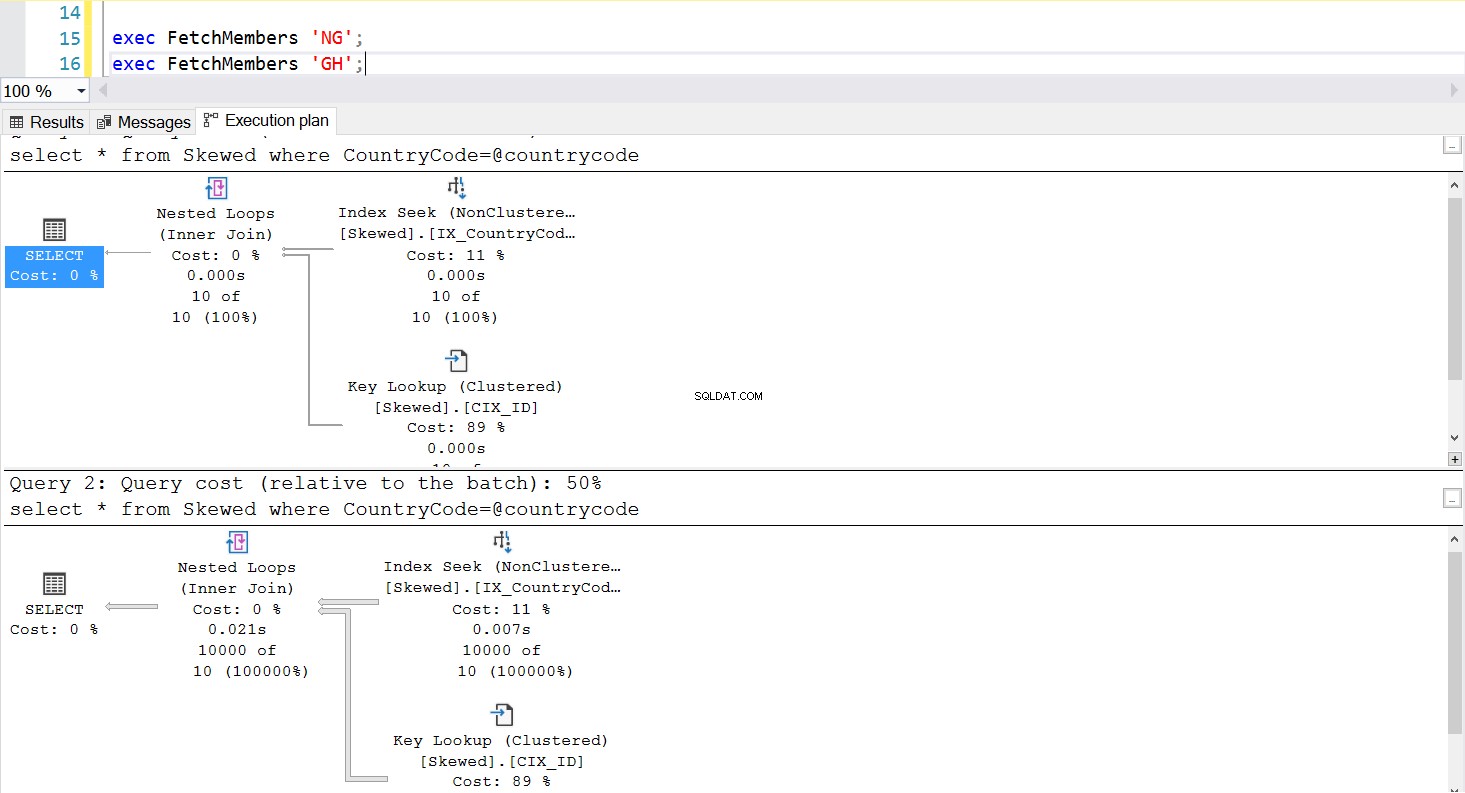
Afb. 2 Uitvoeringsplannen voor twee queries
Als we de tabel opvragen voor records waarin CountryCode NG en GH is, zien we dat SQL Server in deze gevallen twee verschillende uitvoeringsplannen gebruikt. Dit gebeurt omdat het verwachte aantal rijen voor CountryCode='NG' 10 is, terwijl dat voor CountryCode='GH' 10000 is. SQL Server bepaalt het uitvoeringsplan dat de voorkeur heeft op basis van tabelstatistieken. Als het verwachte aantal rijen hoog is in vergelijking met het totale aantal rijen in de tabel, besluit SQL Server dat het beter is om gewoon een volledige tabelscan uit te voeren in plaats van te verwijzen naar een index. Met een veel kleiner geschat aantal rijen wordt de index nuttig.
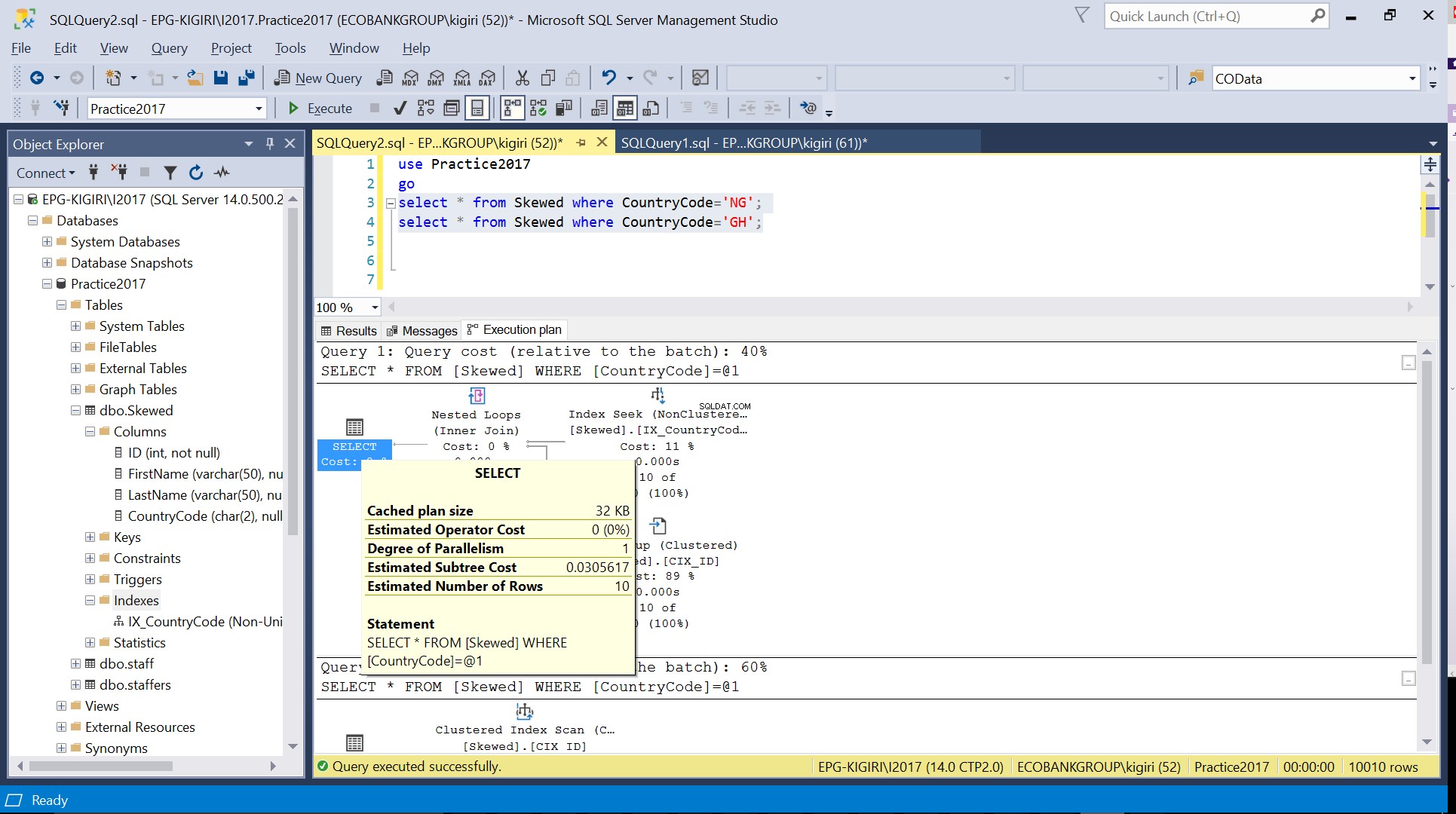
Afb. 3 Geschat aantal rijen voor CountryCode=’NG’
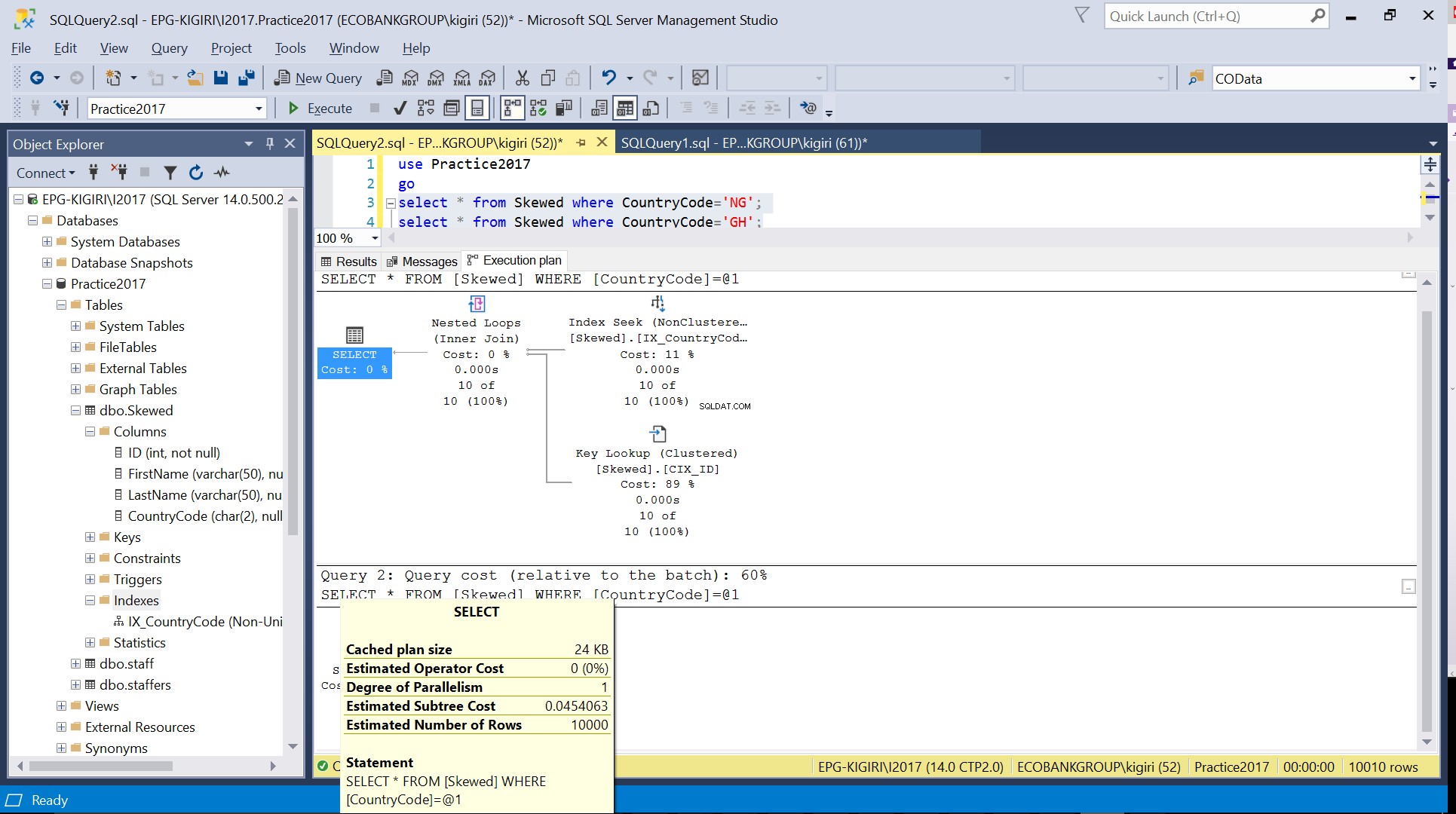
Afb. 4 Geschat aantal rijen voor CountryCode=’GH’
Opgeslagen procedures invoeren
We kunnen een opgeslagen procedure maken om de gewenste records op te halen door dezelfde query te gebruiken. Het enige verschil deze keer is dat we CountryCode als parameter doorgeven (zie Listing 3). Wanneer we dit doen, ontdekken we dat het uitvoeringsplan hetzelfde is, ongeacht welke parameter we passeren. Het uitvoeringsplan dat zal worden gebruikt, wordt bepaald door het uitvoeringsplan dat wordt geretourneerd bij de eerste keer dat de opgeslagen procedure wordt aangeroepen. Als we bijvoorbeeld de procedure eerst uitvoeren met CountryCode='GH', wordt vanaf dat moment een volledige tabelscan gebruikt. Als we vervolgens de procedurecache wissen en de procedure eerst uitvoeren met CountryCode='NG', zal deze in de toekomst op index gebaseerde scans gebruiken.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
Afb. 5 Index zoek uitvoeringsplan wanneer 'NG' eerst wordt gebruikt
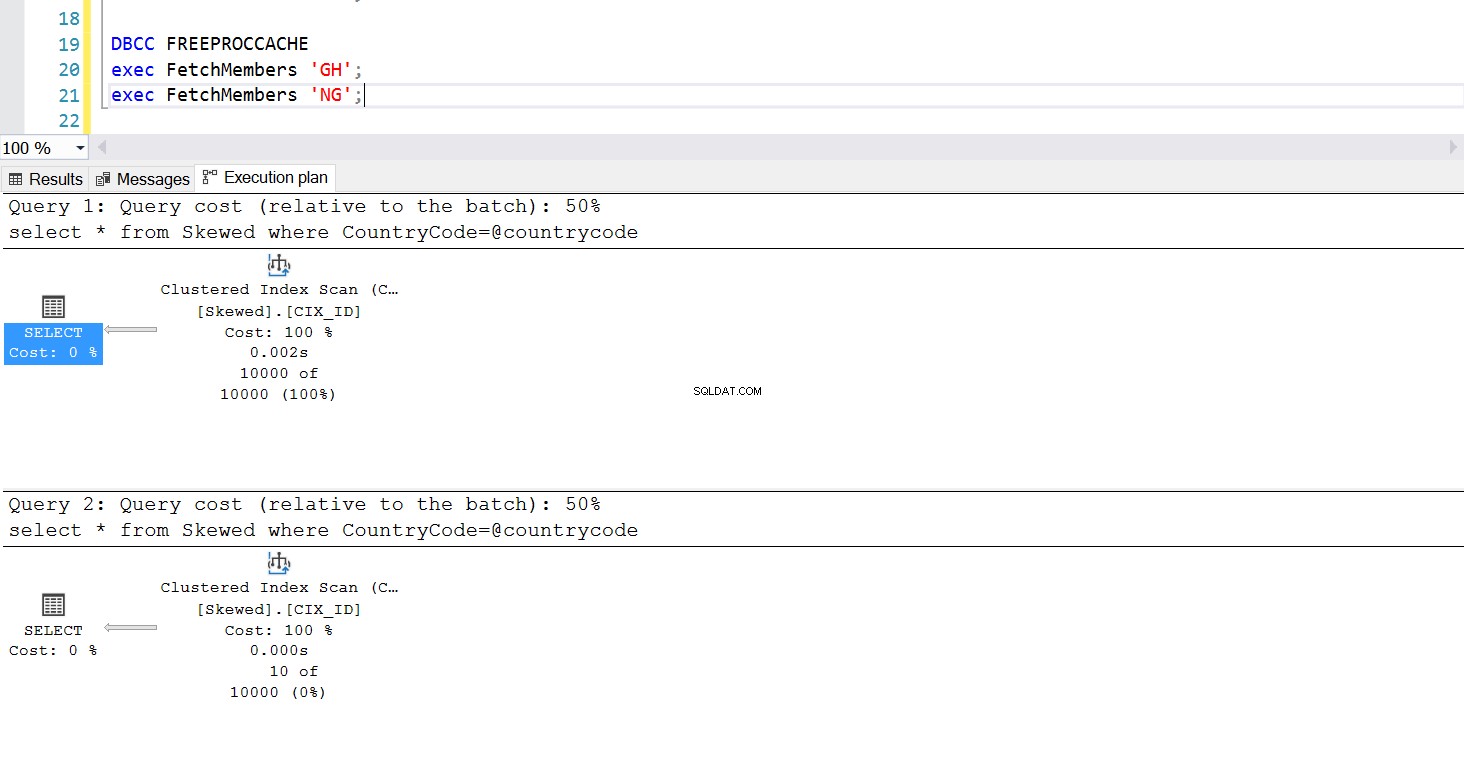
Afb. 6 Geclusterd uitvoeringsplan voor indexscan wanneer 'GH' eerst wordt gebruikt
Uitvoering van de opgeslagen procedure verloopt zoals bedoeld – het vereiste uitvoeringsplan wordt consequent gebruikt. Dit kan echter een probleem zijn omdat één uitvoeringsplan niet geschikt is voor alle query's als de gegevens scheef staan. Het is niet efficiënt om een index te gebruiken om een verzameling rijen op te halen die bijna net zo groot zijn als de hele tabel. Evenmin is het gebruik van een volledige scan om slechts een klein aantal rijen op te halen. Dit is het Parameter Sniffing-probleem.
Mogelijke oplossingen
Een veelgebruikte manier om het parameter Sniffing-probleem te beheersen, is door opzettelijk hercompilatie aan te roepen wanneer de opgeslagen procedure wordt uitgevoerd. Dit is veel beter dan het leegmaken van de plancache - behalve als u de cache van deze specifieke SQL-query wilt leegmaken, wat heel goed mogelijk is. Bekijk een bijgewerkte versie van de opgeslagen procedure. Deze keer gebruikt het OPTION (RECOMPILE) om het probleem te beheren. Afb.6 laat ons zien dat, wanneer de nieuwe opgeslagen procedure wordt uitgevoerd, deze een plan gebruikt dat geschikt is voor de parameter die we doorgeven.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
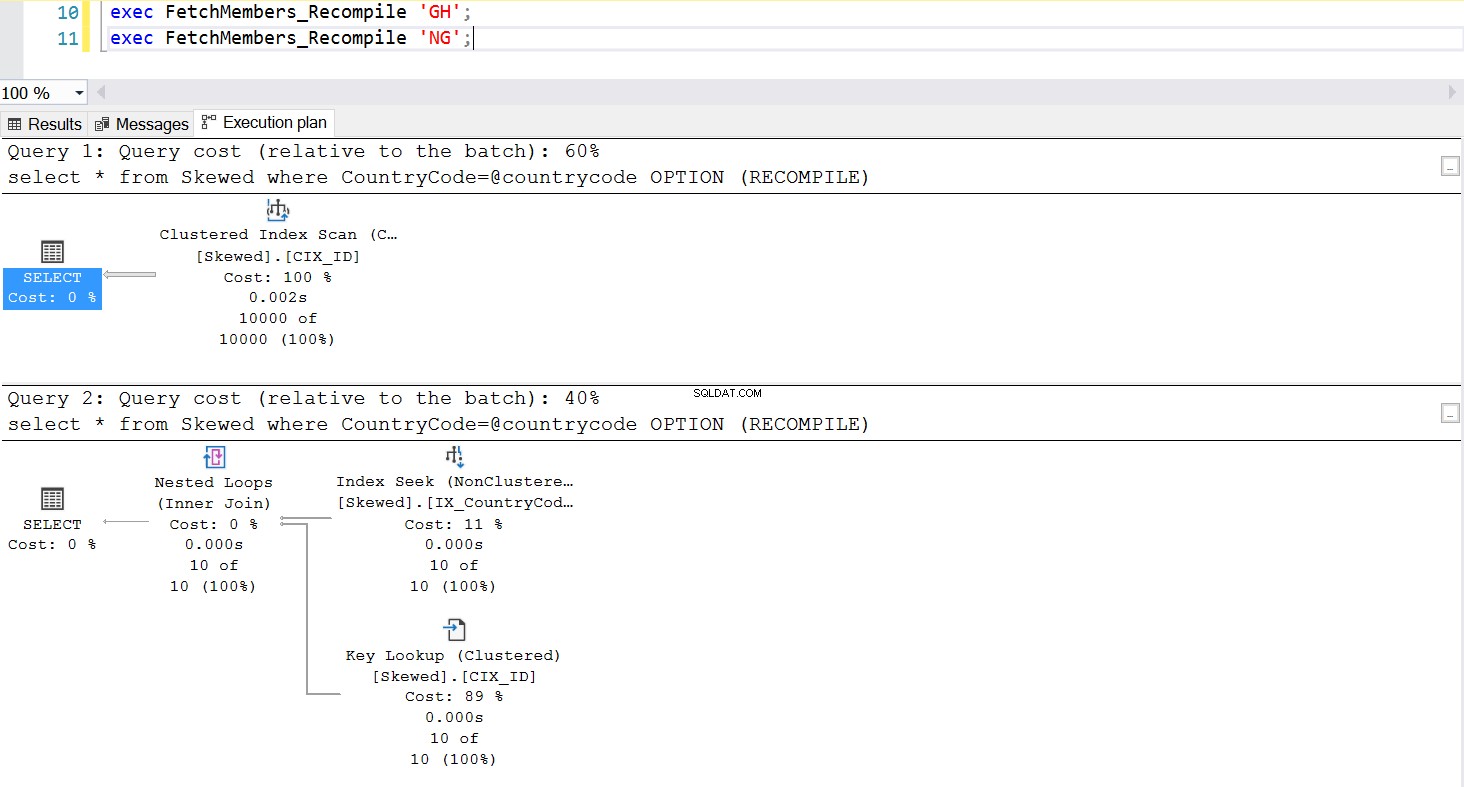
Afb. 7 Gedrag van de opgeslagen procedure met OPTIE (RECOMPILE)
Conclusie
In dit artikel hebben we gekeken hoe consistente uitvoeringsplannen voor opgeslagen procedures een probleem kunnen worden wanneer de gegevens waarmee we te maken hebben scheef zijn. We hebben dit ook in de praktijk aangetoond en geleerd over een gemeenschappelijke oplossing voor het probleem. Ik durf te zeggen dat deze kennis van onschatbare waarde is voor ontwikkelaars die SQL Server gebruiken. Er zijn een aantal andere oplossingen voor dit probleem – Brent Ozar is dieper op het onderwerp ingegaan en heeft op SQLDay Poland 2017 diepere details en oplossingen naar voren gebracht. Ik heb de bijbehorende link in de referentiesectie vermeld.
Referenties
Cache plannen en optimaliseren voor adhoc-workloads
Identificeren en oplossen van problemen met het snuiven van parameters