[ Deel 1 | Deel 2 | Deel 3 ]
In deel 1 liet ik zien hoe zowel pagina- als columnstore-compressie de grootte van een 1TB-tabel met 80% of meer kon verminderen. Hoewel ik onder de indruk was dat ik een tafel kon verkleinen van 1 TB naar 50 GB, was ik niet erg blij met de hoeveelheid tijd die het kostte (van 2 tot 14 uur). Met enkele tips die genadig zijn geleend van mensen als Joe Obbish, Lonny Niederstadt, Niko Neugebauer en anderen, zal ik in dit bericht proberen enkele wijzigingen aan te brengen in mijn oorspronkelijke poging om betere laadprestaties te krijgen. Aangezien de reguliere columnstore-index niet beter comprimeerde dan paginacompressie op deze dataset , en het 13 uur langer duurde om daar te komen, zal ik me uitsluitend concentreren op de meer geavanceerde oplossing met behulp van COLUMNSTORE_ARCHIVE compressie.
Enkele van de problemen waarvan ik denk dat ze de prestaties beïnvloedden, zijn de volgende:
- Onjuiste bestandsindelingskeuzes - Ik heb 8 bestanden in één bestandsgroep geplaatst, met parallellisme maar geen (of suboptimale) partitionering, waarbij ik I/O's over meerdere bestanden sproei met roekeloze overgave. Om dit aan te pakken, zal ik:
- partitioneer de tabel in 8 partities (één per core)
- zet het gegevensbestand van elke partitie op zijn eigen bestandsgroep
- gebruik 8 afzonderlijke processen om aan elke partitie te koppelen
- gebruik archiefcompressie op alles behalve de "actieve" partitie
- te veel kleine batches en suboptimale populatie rijgroepen – door 10 miljoen rijen tegelijk te verwerken, vulde ik negen rijgroepen met een mooie 1.048.576 rijen, en dan zouden de resterende 562.816 rijen in een andere kleinere rijgroep terechtkomen. En eventuele ongelijke verdelingen die een rest van <102.400 rijen achterlaten, zouden inserts in de minder efficiënte delta-opslagstructuur druppelen. Om rijen uniformer te verdelen en delta store te vermijden, zal ik:
- zoveel mogelijk gegevens verwerken in exacte veelvouden van 1.048.576 rijen
- verdeel die zo gelijkmatig mogelijk over 8 partities
- gebruik een batchgrootte die dichter bij 10x ligt -> 100 miljoen rijen
- planner stapelen - hoewel ik hier niet op heb gecontroleerd, is het mogelijk dat een deel van de vertraging werd veroorzaakt doordat de ene planner te veel werk op zich nam en een andere planner niet genoeg, vanwege de round-robining van de planner. Nu ik de gegevens opzettelijk zal laden met 8 maxdop 1-processen in plaats van één maxdop 8-proces, om alle planners even bezig te houden, zal ik:
- gebruik een opgeslagen procedure die een gelijkmatige balans probeert te vinden tussen planners (zie pagina's 189-191 in SQLCAT's Guide to:Relational Engine voor de inspiratie achter dit idee)
- schakel globale traceervlag 2467 en 2469 in, zoals gewaarschuwd in de documentatie
- comprimeertaak voor achtergrondkolommen – het was verkwistend om dit tijdens de populatie te laten draaien, aangezien ik toch van plan was om aan het eind weer op te bouwen. Deze keer zal ik:
- schakel deze taak uit met globale traceervlag 634
Ik heb de oorspronkelijke partitiefunctie en het oorspronkelijke schema geschrapt en een nieuwe gebouwd op basis van een meer gelijkmatige verdeling van de gegevens. Ik wil 8 partities die overeenkomen met het aantal kernen en het aantal gegevensbestanden, om het "arme man's parallellisme" dat ik van plan ben te gebruiken, te maximaliseren.
Eerst moeten we een nieuwe set bestandsgroepen maken, elk met zijn eigen bestand:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Vervolgens keek ik naar het aantal rijen in de tabel:3.754.965.954. Om die exact te verspreiden gelijkmatig verdeeld over 8 partities, dat zou 469.370.744,25 rijen per partitie zijn. Om het goed te laten werken, laten we de partitiegrenzen aanpassen aan de volgende veelvoud van 1.048.576 rijen. Dit is 1.048.576 x 448 =469.762.048 – wat het aantal rijen zou zijn waarop we schieten in de eerste 7 partities, waardoor er 466.631.618 rijen overblijven in de laatste partitie. Om de werkelijke OID te zien waarden die als grenzen zouden dienen om het optimale aantal rijen in elke partitie te bevatten, heb ik deze query uitgevoerd tegen de originele tabel (aangezien het 25 minuten duurde om uit te voeren, leerde ik snel om deze resultaten in een aparte tabel te dumpen):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
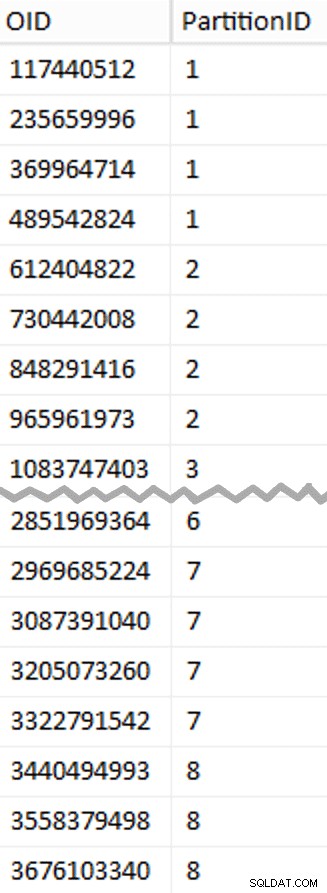 Hier valt meer uit te pakken dan je zou verwachten. De CTE doet al het zware werk, aangezien het de hele tabel van 1,14 TB moet scannen en een rijnummer aan elke rij moet toewijzen . Ik wil alleen elke
Hier valt meer uit te pakken dan je zou verwachten. De CTE doet al het zware werk, aangezien het de hele tabel van 1,14 TB moet scannen en een rijnummer aan elke rij moet toewijzen . Ik wil alleen elke (1048576*112)e . retourneren rij, aangezien dit mijn batchgrensrijen zijn, dus dit is wat de WHERE clausule doet. Onthoud dat ik het werk wil verdelen in batches die dichter bij 100 miljoen rijen per keer liggen, maar ik wil ook niet echt 469 miljoen rijen in één keer verwerken. Dus naast het opsplitsen van de gegevens in 8 partities, wil ik elk van die partities opsplitsen in vier batches van 117.440.512 (1.048.576*112) rijen. Elke aangrenzende set van vier batches behoort tot één partitie, dus de PartitionID I derive voegt er gewoon een toe aan het resultaat van het huidige rijnummer integer gedeeld door (1.048.576*448) , die ervoor zorgt dat de grens altijd in de "linkse" set ligt. We voegen er dan een toe aan het resultaat, omdat we anders zouden verwijzen naar een op 0 gebaseerde verzameling partities, en niemand wil dat.
Oké, dat waren veel woorden. Rechts is een afbeelding met de (verkorte) inhoud van de stage tabel (klik om het volledige resultaat weer te geven, waarbij de partitiegrenswaarden worden gemarkeerd).
We kunnen dan een andere query afleiden uit die staging-tabel die ons de min en max waarden laat zien voor elke batch binnen elke partitie, evenals de extra batch die niet is verantwoord (de rijen in de originele tabel met OID groter dan de hoogste grenswaarde):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Die waarden zien er als volgt uit:
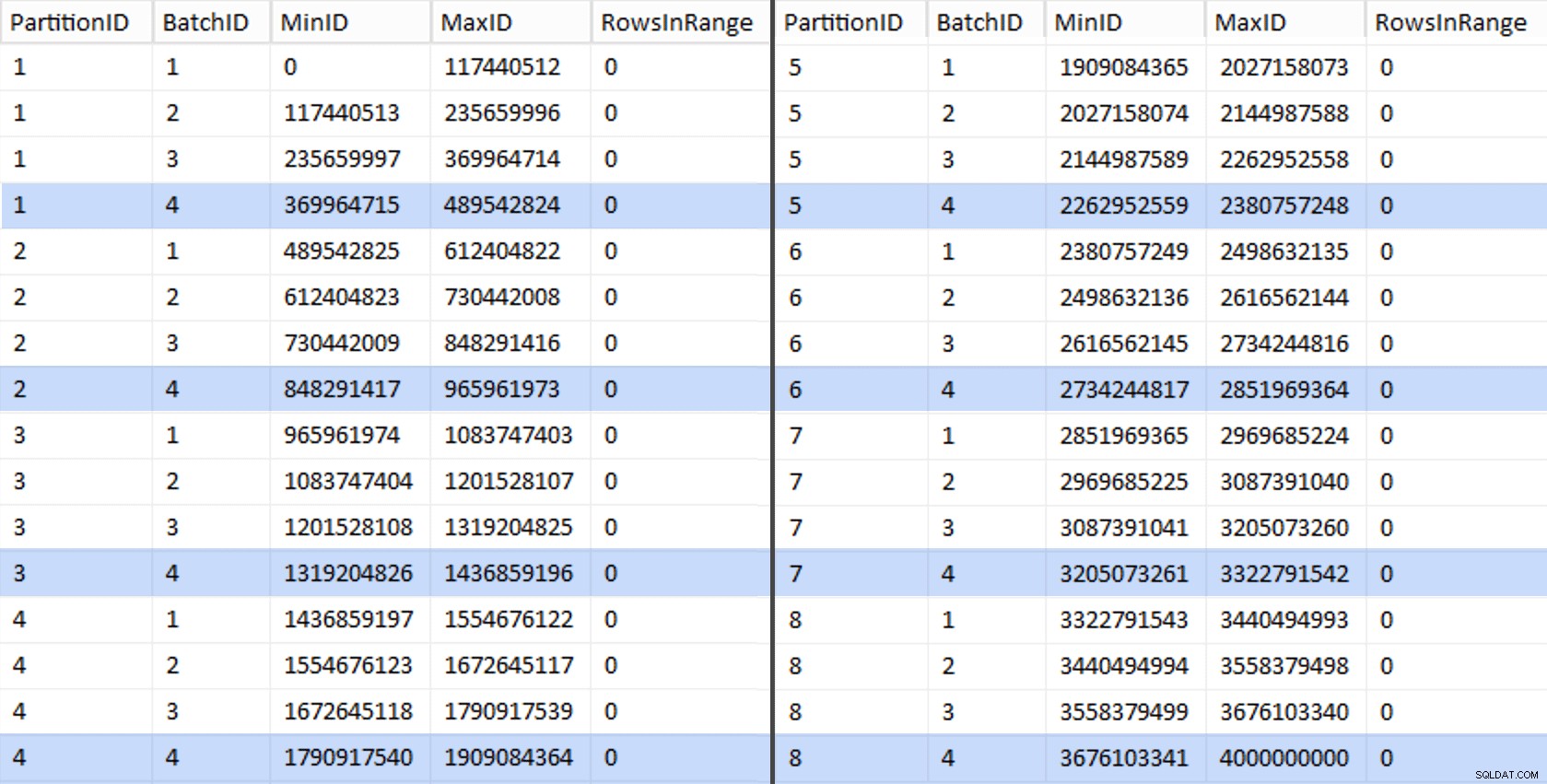
Om ons werk te testen, kunnen we daaruit een reeks query's afleiden die BatchQueue met werkelijke rijtellingen uit de tabel.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Dit duurde ongeveer 6 minuten op mijn systeem. Vervolgens kunt u de volgende query uitvoeren om aan te tonen dat elke batch, behalve de allerlaatste, in staat is rijgroepen volledig te vullen en geen rest over te laten voor mogelijk gebruik van deltastores:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Nu ziet de tabel er als volgt uit:
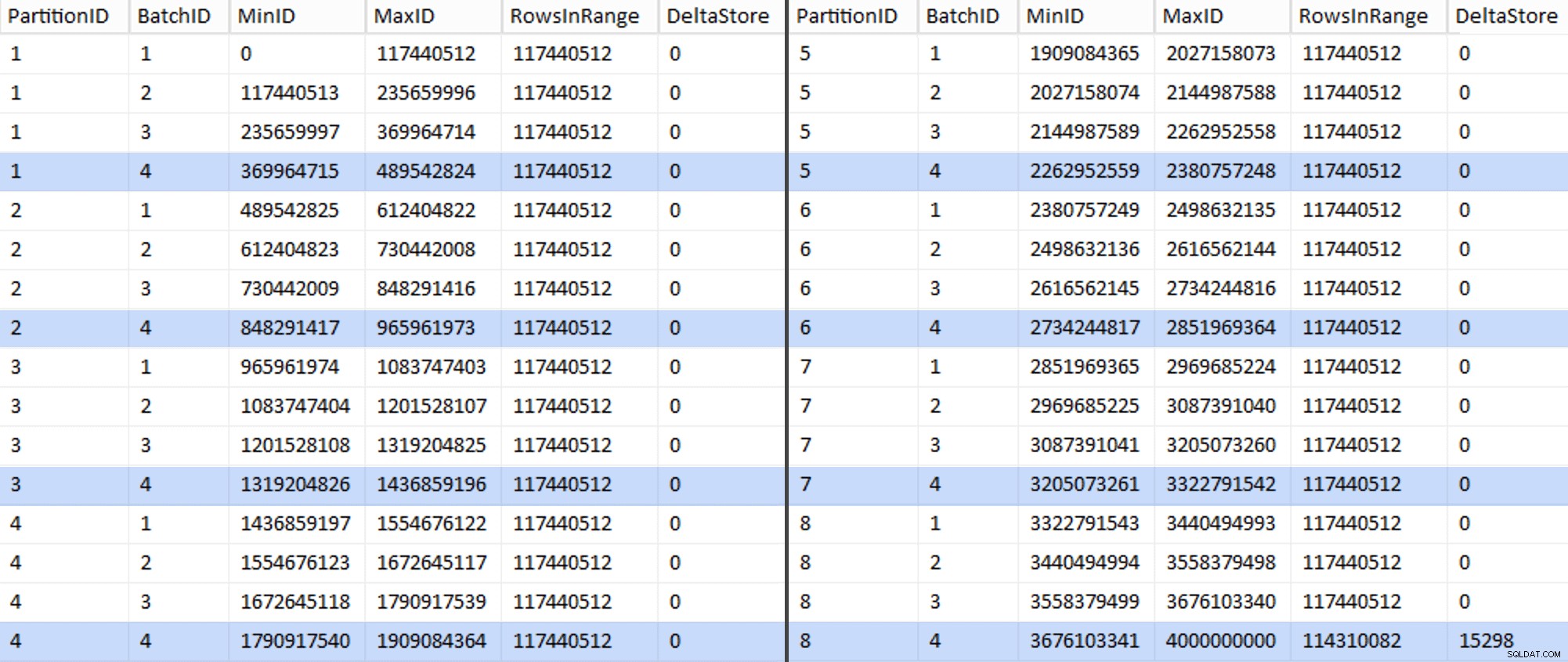
En ja hoor, elke batch heeft de berekende 117.440.512 miljoen rijen, behalve de laatste die, in ieder geval idealiter, onze enige niet-gecomprimeerde delta-opslag zal bevatten. We kunnen dit waarschijnlijk ook voorkomen door de batchgrootte een klein beetje te veranderen voor deze partitie zodat alle vier batches met dezelfde grootte worden uitgevoerd, of door het aantal batches te wijzigen om plaats te bieden aan een ander veelvoud van 102.400 of 1.048.576. Omdat daarvoor een nieuwe OID . nodig is waarden uit de basistabel, waarmee we nog eens 25 minuten aan onze migratie-inspanning toevoegen, laat ik deze ene onvolmaakte partitie verschuiven - vooral omdat we er toch niet het volledige voordeel van archiefcompressie van krijgen.
De BatchQueue table begint tekenen te vertonen van bruikbaarheid voor het verwerken van onze batches om gegevens te migreren naar onze nieuwe, gepartitioneerde, geclusterde columnstore-tabel. Die we moeten creëren, nu we de grenzen kennen. Er zijn maar 7 grenzen, dus je zou dit zeker handmatig kunnen doen, maar ik laat dynamische SQL graag mijn werk voor me doen:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Resultaten:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Als dat eenmaal is gemaakt, kunnen we ons partitieschema maken en elke volgende partitie toewijzen aan zijn speciale bestand:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Nu kunnen we de tabel maken en klaar maken voor migratie:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
In deel 3 zal ik de BatchQueue verder configureren tabel, bouw een procedure voor processen om de gegevens naar de nieuwe structuur te pushen en analyseer de resultaten.
[ Deel 1 | Deel 2 | Deel 3 ]