SQL Server introduceerde In-Memory OLTP-objecten in SQL Server 2014. Er waren veel beperkingen in de eerste release; sommige zijn aangepakt in SQL Server 2016 en naar verwachting zullen er meer worden aangepakt in de volgende release naarmate de functie zich verder ontwikkelt. Tot nu toe lijkt het gebruik van In-Memory OLTP niet erg wijdverbreid, maar naarmate de functie volwassener wordt, verwacht ik dat meer klanten zullen gaan vragen naar de implementatie. Zoals bij elke grote wijziging in schema of code, raad ik aan om grondig te testen om te bepalen of In-Memory OLTP de verwachte voordelen biedt. Met dat in gedachten was ik geïnteresseerd om te zien hoe de prestaties veranderden voor zeer eenvoudige INSERT-, UPDATE- en DELETE-instructies met In-Memory OLTP. Ik hoopte dat als ik vergrendeling of vergrendeling zou kunnen aantonen als een probleem met op schijf gebaseerde tabellen, de tabellen in het geheugen een oplossing zouden bieden, omdat ze vrij van vergrendeling en vergrendeling zijn.
Ik ontwikkelde de volgende test gevallen:
- Een schijfgebaseerde tabel met traditionele opgeslagen procedures voor DML.
- Een In-Memory-tabel met traditionele opgeslagen procedures voor DML.
- Een In-Memory-tabel met native gecompileerde procedures voor DML.
Ik was geïnteresseerd in het vergelijken van de prestaties van traditionele opgeslagen procedures en native gecompileerde procedures, omdat een beperking van een native gecompileerde procedure is dat alle tabellen waarnaar wordt verwezen in het geheugen moeten zijn. Hoewel enkele-rij, solitaire wijzigingen in sommige systemen gebruikelijk kunnen zijn, zie ik vaak wijzigingen optreden binnen een grotere opgeslagen procedure met meerdere instructies (SELECT en DML) die toegang hebben tot een of meer tabellen. De In-Memory OLTP-documentatie raadt ten zeerste aan om native gecompileerde procedures te gebruiken om het meeste voordeel te behalen in termen van prestaties. Ik wilde begrijpen in hoeverre het de prestaties verbeterde.
De Opstelling
Ik heb een database gemaakt met een voor geheugen geoptimaliseerde bestandsgroep en vervolgens drie verschillende tabellen in de database gemaakt (één op schijf, twee in het geheugen):
- Schijftabel
- InMemory_Temp1
- InMemory_Temp2
De DDL was bijna hetzelfde voor alle objecten, waar nodig rekening houdend met on-disk versus in-memory. DiskTable DDL versus In-Memory DDL:
CREATE TABLE [dbo].[DiskTable] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) ON [DiskTables]; GO CREATE TABLE [dbo].[InMemTable_Temp1] ( [ID] INT IDENTITY(1,1) NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000), [Name] VARCHAR (100) NOT NULL, [Type] INT NOT NULL, [c4] INT NULL, [c5] INT NULL, [c6] INT NULL, [c7] INT NULL, [c8] VARCHAR(255) NULL, [c9] VARCHAR(255) NULL, [c10] VARCHAR(255) NULL, [c11] VARCHAR(255) NULL) WITH (MEMORY_OPTIMIZED=ON, DURABILITY = SCHEMA_AND_DATA); GO
Ik heb ook negen opgeslagen procedures gemaakt - één voor elke combinatie van tabel en wijziging.
- DiskTable_Insert
- DiskTable_Update
- DiskTable_Delete
- InMemRegularSP_Insert
- InMemRegularSP _Update
- InMemRegularSP _Verwijderen
- InMemCompiledSP_Insert
- InMemCompiledSP_Update
- InMemCompiledSP_Delete
Elke opgeslagen procedure accepteerde een integer-invoer om te herhalen voor dat aantal wijzigingen. De opgeslagen procedures volgden hetzelfde formaat, variaties waren alleen de tabel die werd geopend en of het object native was gecompileerd of niet. De volledige code om de database en objecten aan te maken is hier te vinden, met voorbeelden van INSERT- en UPDATE-instructies hieronder:
CREATE PROCEDURE dbo.[DiskTable_Inserts] @NumRows INT AS BEGIN SET NOCOUNT ON; DECLARE @Name INT; DECLARE @Type INT; DECLARE @ColInt INT; DECLARE @ColVarchar VARCHAR(255) DECLARE @RowLoop INT = 1; WHILE (@RowLoop <= @NumRows) BEGIN SET @Name = CONVERT (INT, RAND () * 1000) + 1; SET @Type = CONVERT (INT, RAND () * 100) + 1; SET @ColInt = CONVERT (INT, RAND () * 850) + 1 SET @ColVarchar = CONVERT (INT, RAND () * 1300) + 1 INSERT INTO [dbo].[DiskTable] ( [Name], [Type], [c4], [c5], [c6], [c7], [c8], [c9], [c10], [c11] ) VALUES (@Name, @Type, @ColInt, @ColInt + (CONVERT (INT, RAND () * 20) + 1), @ColInt + (CONVERT (INT, RAND () * 30) + 1), @ColInt + (CONVERT (INT, RAND () * 40) + 1), @ColVarchar, @ColVarchar + (CONVERT (INT, RAND () * 20) + 1), @ColVarchar + (CONVERT (INT, RAND () * 30) + 1), @ColVarchar + (CONVERT (INT, RAND () * 40) + 1)) SELECT @RowLoop = @RowLoop + 1 END END GO CREATE PROCEDURE [InMemUpdates_CompiledSP] @NumRows INT WITH NATIVE_COMPILATION, SCHEMABINDING AS BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english') DECLARE @RowLoop INT = 1; DECLARE @ID INT DECLARE @RowNum INT = @@SPID * (CONVERT (INT, RAND () * 1000) + 1) WHILE (@RowLoop <= @NumRows) BEGIN SELECT @ID = ID FROM [dbo].[IDs_InMemTable2] WHERE RowNum = @RowNum UPDATE [dbo].[InMemTable_Temp2] SET [c4] = [c5] * 2 WHERE [ID] = @ID SET @RowLoop = @RowLoop + 1 SET @RowNum = @RowNum + (CONVERT (INT, RAND () * 10) + 1) END END GO
Opmerking:de IDs_*-tabellen werden opnieuw ingevuld nadat elke set INSERT's was voltooid en waren specifiek voor de drie verschillende scenario's.
Testmethodologie
Het testen is gedaan met .cmd-scripts die sqlcmd gebruikten om een script aan te roepen dat de opgeslagen procedure uitvoerde, bijvoorbeeld:
sqlcmd -S CAP\ROGERS -i"C:\Temp\SentryOne\InMemTable_RegularDeleteSP_100.sql"afsluiten
Ik heb deze benadering gebruikt om een of meer verbindingen met de database tot stand te brengen die gelijktijdig zouden worden uitgevoerd. Naast het begrijpen van fundamentele veranderingen in prestaties, wilde ik ook het effect van verschillende workloads onderzoeken. Deze scripts zijn gestart vanaf een aparte machine om de overhead van het maken van verbindingen te elimineren. Elke opgeslagen procedure is 1000 keer uitgevoerd door een verbinding en ik heb 1 verbinding, 10 verbindingen en 100 verbindingen getest (respectievelijk 1000, 10000 en 100000 wijzigingen). Ik legde prestatiestatistieken vast met behulp van Query Store en legde ook wachtstatistieken vast. Met Query Store kon ik de gemiddelde duur en CPU voor elke opgeslagen procedure vastleggen. Wachtstatistieken werden voor elke verbinding vastgelegd met dm_exec_session_wait_stats en vervolgens verzameld voor de hele test.
Ik heb elke test vier keer uitgevoerd en vervolgens de algemene gemiddelden berekend voor de gegevens die in dit bericht worden gebruikt. Scripts die worden gebruikt voor het testen van de werkbelasting kunnen hier worden gedownload.
Resultaten
Zoals te verwachten was, waren de prestaties met In-Memory-objecten beter dan met op schijf gebaseerde objecten. Een In-Memory-tabel met een reguliere opgeslagen procedure had echter soms vergelijkbare of slechts iets betere prestaties in vergelijking met een op schijf gebaseerde tabel met een reguliere opgeslagen procedure. Onthoud:ik was geïnteresseerd om te begrijpen of ik echt een gecompileerde opgeslagen procedure nodig had om een groot voordeel te behalen met een in-memory tabel. Voor dit scenario deed ik dat. In alle gevallen presteerde de in-memory tabel met de native gecompileerde procedure aanzienlijk beter. De twee grafieken hieronder tonen dezelfde gegevens, maar met verschillende schalen voor de x-as, om die prestaties aan te tonen voor reguliere opgeslagen procedures die gegevens wijzigen die verslechteren bij meer gelijktijdige verbindingen.
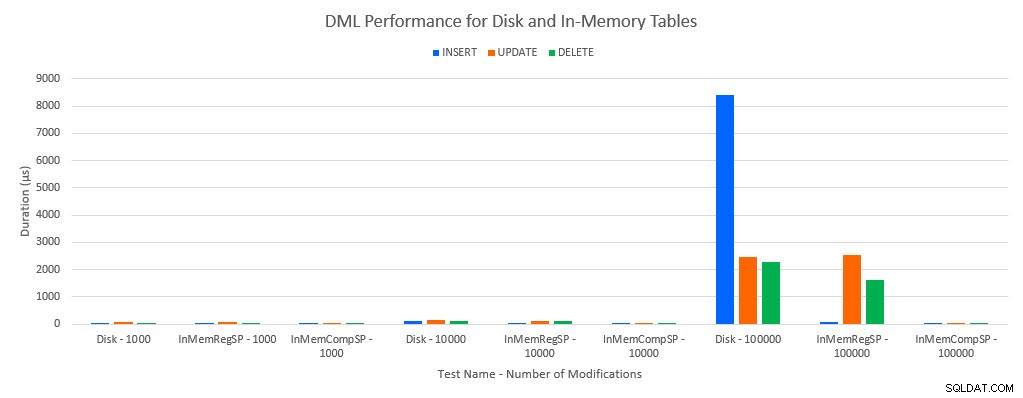
DML-prestaties per test en werkbelasting
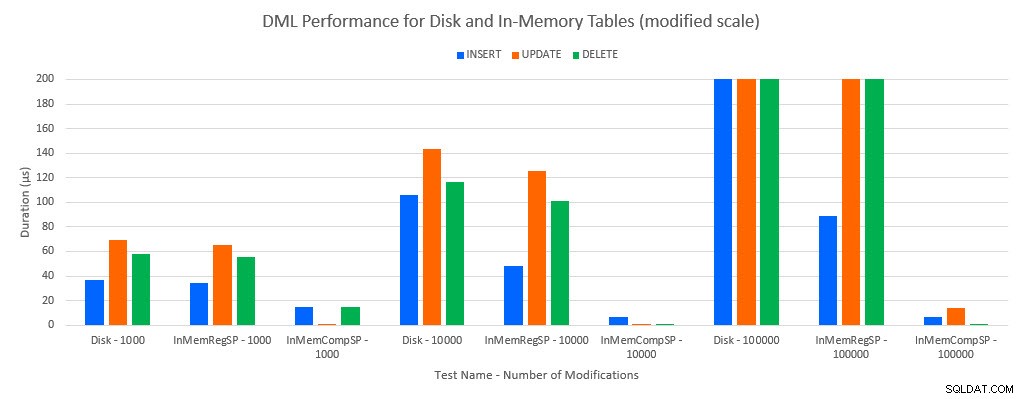
DML-prestaties per test en werkbelasting [Gewijzigde schaal]
De uitzondering is INSERT's in de In-Memory-tabel met de reguliere opgeslagen procedure. Met 100 verbindingen is de gemiddelde duur meer dan 8 ms voor een schijfgebaseerde tabel, maar minder dan 100 microseconden voor de In-Memory-tabel. De waarschijnlijke reden is de afwezigheid van vergrendeling en vergrendeling met de In-Memory-tabel, en dit wordt ondersteund met wachtstatistieken:
| Test | INSERT | UPDATE | VERWIJDEREN |
|---|---|---|---|
| Schijftabel – 1000 | WRITELOG | WRITELOG | WRITELOG |
| InMemTable_RegularSP – 1000 | SCHRIJFLOG | SCHRIJFLOG | SCHRIJFLOG |
| InMemTable_CompiledSP – 1000 | SCHRIJFLOG | MEMORY_ALLOCATION_EXT | MEMORY_ALLOCATION_EXT |
| Schijftabel – 10.000 | SCHRIJFLOG | SCHRIJFLOG | SCHRIJFLOG |
| InMemTable_RegularSP – 10.000 | SCHRIJFLOG | SCHRIJFLOG | SCHRIJFLOG |
| InMemTable_CompiledSP – 10.000 | SCHRIJFLOG | SCHRIJFLOG | MEMORY_ALLOCATION_EXT |
| Schijftabel – 100.000 | PAGELATCH_EX | SCHRIJFLOG | SCHRIJFLOG |
| InMemTable_RegularSP – 100.000 | SCHRIJFLOG | SCHRIJFLOG | SCHRIJFLOG |
| InMemTable_CompiledSP – 100.000 | SCHRIJFLOG | SCHRIJFLOG | SCHRIJFLOG |
Wachtstatistieken per test
Wachtstatistieken worden hier weergegeven op basis van de totale wachttijd voor resources (die over het algemeen ook vertaald worden naar de hoogste gemiddelde resourcetijd, maar er waren uitzonderingen). Het WRITELOG-wachttype is meestal de beperkende factor in dit systeem. De PAGELATCH_EX wacht echter op 100 gelijktijdige verbindingen met INSERT-instructies, suggereert dat met extra belasting het vergrendelings- en vergrendelingsgedrag dat bestaat met schijfgebaseerde tabellen een beperkende factor zou kunnen zijn. In de UPDATE- en DELETE-scenario's met 10 en 100 verbindingen voor de schijfgebaseerde tabeltests was de gemiddelde wachttijd voor resources het hoogst voor vergrendelingen (LCK_M_X).
Conclusie
In-Memory OLTP kan absoluut een prestatieverbetering bieden voor de juiste workload. De hier geteste voorbeelden zijn echter uiterst eenvoudig en mogen niet alleen worden beschouwd als reden om naar een In-Memory-oplossing te migreren. Er zijn nog steeds meerdere beperkingen waarmee rekening moet worden gehouden, en er moeten grondige tests worden uitgevoerd voordat een migratie plaatsvindt (vooral omdat het migreren naar een In-Memory-tabel een offline proces is). Maar voor het juiste scenario kan deze nieuwe functie een prestatieverbetering bieden. Zolang je begrijpt dat er nog steeds enkele onderliggende beperkingen zullen bestaan, zoals de snelheid van transactielogboeken voor duurzame tabellen, hoewel hoogstwaarschijnlijk op een beperkte manier - ongeacht of de tabel op schijf of in het geheugen bestaat.