
In maart begon ik een serie over alomtegenwoordige prestatiemythes in SQL Server. Een overtuiging die ik van tijd tot tijd tegenkom, is dat je varchar- of nvarchar-kolommen zonder enige boete kunt oversized.
Laten we aannemen dat u e-mailadressen opslaat. In een vorig leven heb ik hier nogal wat mee te maken gehad - destijds verklaarde RFC 3696 dat een e-mailadres uit 320 tekens kon bestaan (64chars@255chars). Een nieuwere RFC, #5321, erkent nu dat 254 tekens het langste is dat een e-mailadres zou kunnen zijn. En als iemand van jullie een adres heeft dat zo lang is, nou, misschien moeten we praten. :-)
Of je nu de oude of de nieuwe standaard gebruikt, je moet de mogelijkheid ondersteunen dat iemand alle toegestane tekens zal gebruiken. Dat betekent dat je 254 of 320 tekens moet gebruiken. Maar wat ik mensen heb zien doen, is helemaal niet de moeite nemen om de standaard te onderzoeken, en gewoon aannemen dat ze 1.000 tekens, 4.000 tekens of zelfs meer moeten ondersteunen.
Laten we dus eens kijken wat er gebeurt als we tabellen hebben met een e-mailadreskolom van verschillende grootte, maar met exact dezelfde gegevens:
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Laten we nu 10.000 fictieve e-mailadressen genereren uit systeemmetadata en alle vier de tabellen vullen met dezelfde gegevens:
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
Om te valideren dat elke tabel exact dezelfde gegevens bevat:
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Die leveren mij alle vier 35 en 77 op; uw kilometerstand kan variëren. Laten we er ook voor zorgen dat alle vier de tabellen hetzelfde aantal pagina's op de schijf in beslag nemen:
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Alle vier deze zoekopdrachten leveren 89 pagina's op (nogmaals, uw aantal kilometers kan variëren).
Laten we nu een typische zoekopdracht nemen die resulteert in een geclusterde indexscan:
SELECT id, email FROM dbo.Email_<size>;
Als we kijken naar zaken als duur, uitlezingen en geschatte kosten, lijken ze allemaal hetzelfde:
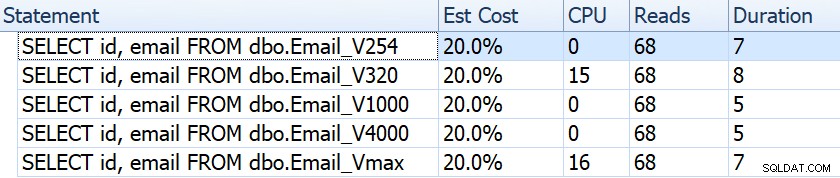
Dit kan mensen in de verkeerde veronderstelling brengen dat er helemaal geen prestatie-impact is. Maar als we iets beter kijken, zien we op de tooltip voor de geclusterde indexscan in elk plan een verschil dat een rol kan spelen bij andere, meer uitgebreide zoekopdrachten:

Vanaf hier zien we dat, hoe groter de kolomdefinitie, hoe groter de geschatte rij- en gegevensgrootte. In deze eenvoudige query zijn de I/O-kosten (0.0512731) hetzelfde voor alle query's, ongeacht de definitie, omdat de geclusterde indexscan toch alle gegevens moet lezen.
Maar er zijn andere scenario's waarin deze geschatte rij en totale gegevensomvang een impact zullen hebben:bewerkingen waarvoor extra middelen nodig zijn, zoals sorteringen. Laten we deze belachelijke vraag nemen die geen enkel echt doel dient, behalve om meerdere sorteerbewerkingen te vereisen:
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; We voeren deze vier zoekopdrachten uit en we zien dat de plannen er allemaal zo uitzien:

Maar dat waarschuwingspictogram op de SELECT-operator verschijnt alleen op de 4000/max-tabellen. Wat is de waarschuwing? Het is een waarschuwing voor overmatige geheugentoekenning, geïntroduceerd in SQL Server 2016. Hier is de waarschuwing voor varchar(4000):

En voor varchar(max):

Laten we eens wat beter kijken en zien wat er aan de hand is, althans volgens sys.dm_exec_query_stats:
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Resultaten:

In mijn scenario werd de duur niet beïnvloed door de verschillen in geheugentoekenning (behalve in het maximale geval), maar je kunt duidelijk de lineaire progressie zien die samenvalt met de aangegeven grootte van de kolom. Die u kunt gebruiken om te extrapoleren wat er zou gebeuren op een systeem met onvoldoende geheugen. Of een uitgebreidere query op een veel grotere dataset. Of significante gelijktijdigheid. Elk van die scenario's kan lekkage vereisen om de sorteerbewerkingen te verwerken, en de duur zou hierdoor vrijwel zeker worden beïnvloed.
Maar waar komen deze grotere geheugenbeurzen vandaan? Onthoud dat het dezelfde zoekopdracht is, tegen exact dezelfde gegevens. Het probleem is dat SQL Server voor bepaalde bewerkingen rekening moet houden met de hoeveelheid gegevens *mogelijk* in een kolom. Het doet dit niet op basis van het daadwerkelijk profileren van de gegevens, en het kan geen aannames doen op basis van de <=201 histogramstapwaarden. In plaats daarvan moet het schatten dat elke rij een waarde heeft die de helft is van de opgegeven kolomgrootte . Dus voor een varchar(4000) gaat het ervan uit dat elk e-mailadres 2000 tekens lang is.
Als het niet mogelijk is om een e-mailadres te hebben dat langer is dan 254 of 320 tekens, is er niets te winnen bij overdimensionering en valt er potentieel veel te verliezen. Het later vergroten van de grootte van een kolom met variabele breedte is veel gemakkelijker dan nu alle nadelen aan te pakken.
Natuurlijk, oversized char of nchar kolommen kunnen veel meer voor de hand liggende straffen hebben.