[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]
In het eerste deel van deze serie hebben we gezien hoe het Halloween-probleem van toepassing is op UPDATE vragen. Om het kort samen te vatten, het probleem was dat de sleutels van een index die werd gebruikt om records te vinden die moesten worden bijgewerkt, werden gewijzigd door de update-bewerking zelf (nog een goede reden om opgenomen kolommen in een index te gebruiken in plaats van de sleutels uit te breiden). De query-optimizer introduceerde een Eager Table Spool-operator om de lees- en schrijfzijde van het uitvoeringsplan te scheiden om het probleem te voorkomen. In dit bericht zullen we zien hoe hetzelfde onderliggende probleem van invloed kan zijn op INSERT en DELETE verklaringen.
Afschriften invoegen
Nu we iets weten over de voorwaarden die Halloween-bescherming vereisen, is het vrij eenvoudig om een INSERT te maken voorbeeld waarbij wordt gelezen van en geschreven naar de sleutels van dezelfde indexstructuur. Het eenvoudigste voorbeeld is het dupliceren van rijen in een tabel (waarbij het toevoegen van nieuwe rijen onvermijdelijk de sleutels van de geclusterde index wijzigt):
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
SELECT SomeKey FROM dbo.Demo; Het probleem is dat nieuw ingevoegde rijen kunnen worden aangetroffen aan de leeszijde van het uitvoeringsplan, wat mogelijk kan resulteren in een lus die rijen voor altijd toevoegt (of in ieder geval totdat een bepaalde resourcelimiet is bereikt). De query-optimizer herkent dit risico en voegt een Eager Table Spool toe om de noodzakelijke fasescheiding te bieden :
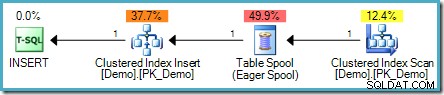
Een realistischer voorbeeld
U schrijft waarschijnlijk niet vaak query's om elke rij in een tabel te dupliceren, maar u schrijft waarschijnlijk wel query's waarbij de doeltabel voor een INSERT verschijnt ook ergens in de SELECT clausule. Een voorbeeld is het toevoegen van rijen uit een verzameltabel die nog niet bestaan in de bestemming:
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
); Het uitvoeringsplan is:
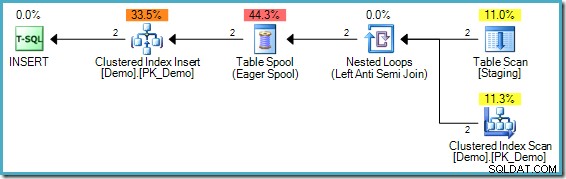
Het probleem is in dit geval subtiel anders, hoewel het nog steeds een voorbeeld is van hetzelfde kernprobleem. Er is geen waarde '1234' in de doeldemotabel, maar de Staging-tabel bevat twee van dergelijke items. Zonder fasescheiding zou de eerste aangetroffen waarde '1234' met succes worden ingevoegd, maar bij de tweede controle zou blijken dat de waarde '1234' nu bestaat en niet opnieuw zou proberen deze in te voegen. De verklaring als geheel zou met succes worden voltooid.
Dit zou in dit specifieke geval een wenselijk resultaat kunnen opleveren (en misschien zelfs intuïtief correct lijken), maar het is geen correcte implementatie. De SQL-standaard vereist dat query's voor gegevensaanpassing worden uitgevoerd alsof de drie fasen van lees-, schrijf- en controlebeperkingen volledig afzonderlijk plaatsvinden (zie deel één).
Als we zoeken naar alle rijen om als een enkele bewerking in te voegen, moeten we beide '1234'-rijen uit de Staging-tabel selecteren, omdat deze waarde nog niet in het doel bestaat. Het uitvoeringsplan moet daarom proberen om beide . in te voegen '1234'-rijen uit de Staging-tabel, resulterend in een schending van de primaire sleutel:
Msg 2627, Level 14, State 1, Line 1Schending van de PRIMARY KEY-beperking 'PK_Demo'.
Kan geen dubbele sleutel invoegen in object 'dbo.Demo'.
De waarde van de dubbele sleutel is ( 1234).
De instructie is beëindigd.
De fasescheiding door de Table Spool zorgt ervoor dat alle controles op het bestaan zijn voltooid voordat er wijzigingen worden aangebracht in de doeltabel. Als u de query uitvoert in SQL Server met de voorbeeldgegevens hierboven, krijgt u de (juiste) foutmelding.
Halloween-beveiliging is vereist voor INSERT-instructies waarbij ook naar de doeltabel wordt verwezen in de SELECT-clausule.
Verwijder uitspraken
We kunnen verwachten dat het Halloween-probleem niet van toepassing is op DELETE uitspraken, omdat het niet echt uitmaakt of we een rij meerdere keren proberen te verwijderen. We kunnen ons staging-tabelvoorbeeld wijzigen om verwijderen rijen uit de Demo-tabel die niet bestaan in Staging:
TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
); Deze test lijkt onze intuïtie te valideren omdat er geen Table Spool in het uitvoeringsplan zit:
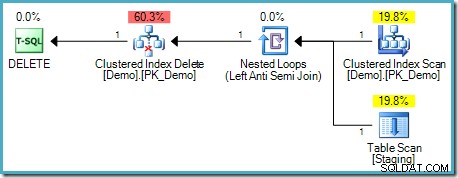
Dit type DELETE vereist geen fasescheiding omdat elke rij een unieke id heeft (een RID als de tabel een heap is, geclusterde indexsleutel(s) en anders mogelijk een uniquifier). Deze unieke rijzoeker is een stabiele sleutel – er is geen mechanisme waardoor het kan veranderen tijdens de uitvoering van dit plan, dus het Halloween-probleem doet zich niet voor.
Halloweenbescherming VERWIJDEREN
Desalniettemin is er ten minste één geval waarin een DELETE Halloween-bescherming vereist:wanneer het plan verwijst naar een andere rij in de tabel dan de rij die wordt verwijderd. Dit vereist een self-join, die vaak wordt aangetroffen wanneer hiërarchische relaties worden gemodelleerd. Hieronder ziet u een vereenvoudigd voorbeeld:
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C');
Er zou hier echt een referentie voor een buitenlandse sleutel in dezelfde tabel moeten zijn, maar laten we dat ontwerp even negeren - de structuur en gegevens zijn niettemin geldig (en het is helaas heel gewoon om vreemde sleutels te vinden die in de echte wereld worden weggelaten). Hoe dan ook, de taak is om elke rij te verwijderen waar de ref kolom verwijst naar een niet-bestaand pk waarde. De natuurlijke DELETE zoekopdracht die aan deze vereiste voldoet, is:
DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
); Het zoekplan is:
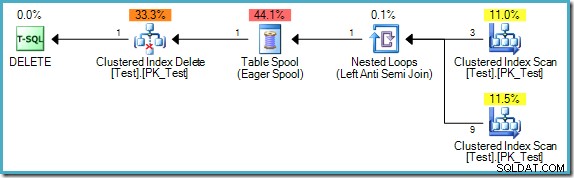
Merk op dat dit plan nu een dure Eager Table Spool bevat. Fasescheiding is hier vereist omdat de resultaten anders kunnen afhangen van de volgorde waarin rijen worden verwerkt:
Als de uitvoeringsengine begint met de rij waar pk =B, het zou geen overeenkomende rij vinden (ref =A en er is geen rij waar pk =A). Als de uitvoering dan verder gaat naar de rij waar pk =C, het zou ook worden verwijderd omdat we zojuist rij B hebben verwijderd waarnaar wordt verwezen door zijn ref kolom. Het eindresultaat zou zijn dat iteratieve verwerking in deze volgorde alle rijen uit de tabel zou verwijderen, wat duidelijk onjuist is.
Aan de andere kant, als de uitvoeringsengine de rij verwerkte met pk =D eerst zou het een overeenkomende rij vinden (ref =C). Ervan uitgaande dat de uitvoering in omgekeerde volgorde wordt voortgezet pk volgorde, is de enige rij die uit de tabel wordt verwijderd de rij waar pk =B. Dit is het juiste resultaat (onthoud dat de query moet worden uitgevoerd alsof de lees-, schrijf- en validatiefasen opeenvolgend en zonder overlappingen hebben plaatsgevonden).
Fasescheiding voor validatie van beperkingen
Even terzijde, we kunnen nog een voorbeeld van fasescheiding zien als we een externe-sleutelbeperking van dezelfde tabel toevoegen aan het vorige voorbeeld:
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); Het uitvoeringsplan voor de INSERT is:
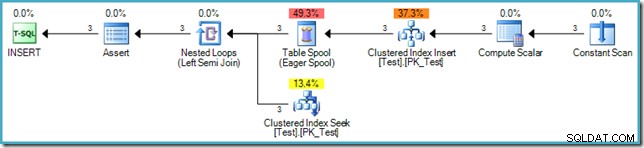
De invoeging zelf vereist geen Halloween-beveiliging omdat het plan niet uit dezelfde tabel kan worden gelezen (de gegevensbron is een virtuele tabel in het geheugen die wordt weergegeven door de Constant Scan-operator). De SQL-standaard vereist echter dat fase 3 (constraint-checking) plaatsvindt nadat de schrijffase is voltooid. Om deze reden wordt een fasescheiding Eager Table Spool toegevoegd aan het plan na de Clustered Index Index, en net voor elke rij wordt gecontroleerd om er zeker van te zijn dat de externe sleutelbeperking geldig blijft.
Als u begint te denken dat het vertalen van een op sets gebaseerde declaratieve SQL-wijzigingsquery naar een robuust iteratief fysiek uitvoeringsplan een lastige zaak is, begint u te begrijpen waarom het verwerken van updates (waarvan Halloween Protection maar een heel klein onderdeel is) de meest complexe onderdeel van de Query Processor.
Delete-instructies vereisen Halloween-bescherming waar een self-join van de doeltabel aanwezig is.
Samenvatting
Halloween-bescherming kan een dure (maar noodzakelijke) functie zijn in uitvoeringsplannen die gegevens wijzigen (waarbij 'wijzigen' alle SQL-syntaxis omvat die rijen toevoegen, wijzigen of verwijderen). Halloween-bescherming is vereist voor UPDATE plannen waarbij de sleutels van een gemeenschappelijke indexstructuur zowel worden gelezen als gewijzigd, voor INSERT plannen waarbij naar de doeltabel wordt verwezen aan de leeszijde van het plan, en voor DELETE plannen waar een self-join op de doeltafel wordt uitgevoerd.
Het volgende deel in deze serie behandelt enkele speciale Halloween-probleemoptimalisaties die alleen van toepassing zijn op MERGE verklaringen.
[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]