Replicatievertragingsproblemen in PostgreSQL zijn geen wijdverbreid probleem voor de meeste instellingen. Hoewel, het kan voorkomen en als het gebeurt, kan het van invloed zijn op uw productie-instellingen. PostgreSQL is ontworpen om meerdere threads af te handelen, zoals parallellisme van query's of het inzetten van worker-threads om specifieke taken af te handelen op basis van de toegewezen waarden in de configuratie. PostgreSQL is ontworpen om zware en stressvolle belastingen aan te kunnen, maar soms (vanwege een slechte configuratie) kan uw server toch naar het zuiden gaan.
Het identificeren van de replicatievertraging in PostgreSQL is geen ingewikkelde taak, maar er zijn een paar verschillende benaderingen om het probleem te onderzoeken. In deze blog bekijken we waar u op moet letten als uw PostgreSQL-replicatie achterblijft.
Typen replicatie in PostgreSQL
Laten we, voordat we ingaan op het onderwerp, eerst kijken hoe replicatie in PostgreSQL evolueert, aangezien er verschillende benaderingen en oplossingen zijn bij het omgaan met replicatie.
Warme stand-by voor PostgreSQL is geïmplementeerd in versie 8.2 (terug in 2006) en was gebaseerd op de verzendmethode voor logbestanden. Dit betekent dat de WAL-records direct van de ene databaseserver naar de andere worden verplaatst om te worden toegepast, of gewoon een analoge benadering van PITR, of heel erg lijkt op wat u doet met rsync.
Deze benadering, zelfs al oud, wordt nog steeds gebruikt en sommige instellingen geven zelfs de voorkeur aan deze oudere benadering. Deze aanpak implementeert een op bestanden gebaseerde verzending van logbestanden door WAL-records één bestand (WAL-segment) tegelijk over te dragen. Hoewel het een keerzijde heeft; Een grote storing op de primaire servers, transacties die nog niet zijn verzonden, gaan verloren. Er is een venster voor gegevensverlies (u kunt dit afstemmen door de parameter archive_timeout te gebruiken, die kan worden ingesteld op slechts enkele seconden, maar zo'n lage instelling zal de bandbreedte die nodig is voor het verzenden van bestanden aanzienlijk vergroten).
In PostgreSQL versie 9.0 is streamingreplicatie geïntroduceerd. Dankzij deze functie konden we up-to-date blijven in vergelijking met op bestanden gebaseerde verzending van logbestanden. De aanpak is door WAL-records (een WAL-bestand is samengesteld uit WAL-records) on-the-fly (slechts een op records gebaseerde logverzending) over te dragen tussen een masterserver en een of meerdere standby-servers. Dit protocol hoeft niet te wachten tot het WAL-bestand is gevuld, in tegenstelling tot op bestanden gebaseerde logverzending. In de praktijk zal een proces met de naam WAL-ontvanger, dat draait op de standby-server, verbinding maken met de primaire server via een TCP/IP-verbinding. Op de primaire server bestaat een ander proces met de naam WAL-afzender. Zijn rol is verantwoordelijk voor het verzenden van de WAL-registers naar de standby-server(s) wanneer ze plaatsvinden.
Asynchrone replicatie-instellingen bij streamingreplicatie kunnen problemen veroorzaken zoals gegevensverlies of slaafvertraging, dus versie 9.1 introduceert synchrone replicatie. Bij synchrone replicatie wacht elke vastlegging van een schrijftransactie totdat de bevestiging is ontvangen dat de vastlegging is geschreven naar het vooruitschrijflogboek op schijf van zowel de primaire als de stand-byserver. Deze methode minimaliseert de kans op gegevensverlies, want om dat te laten gebeuren, moeten zowel de master als de standby tegelijkertijd uitvallen.
Het voor de hand liggende nadeel van deze configuratie is dat de responstijd voor elke schrijftransactie toeneemt, omdat we moeten wachten tot alle partijen hebben gereageerd. In tegenstelling tot MySQL is er geen ondersteuning zoals in een semi-synchrone omgeving van MySQL, het zal terugvallen naar asynchroon als er een time-out is opgetreden. Dus in Met PostgreSQL is de tijd voor een commit (minimaal) de round trip tussen de primaire en de standby. Alleen-lezen transacties worden hierdoor niet beïnvloed.
Terwijl het evolueert, wordt PostgreSQL voortdurend verbeterd en toch is de replicatie ervan divers. U kunt bijvoorbeeld fysieke streaming asynchrone replicatie gebruiken of logische streaming-replicatie gebruiken. Beide worden anders gecontroleerd, maar gebruiken dezelfde aanpak bij het verzenden van gegevens via replicatie, wat nog steeds streamingreplicatie is. Raadpleeg voor meer details de handleiding voor verschillende soorten oplossingen in PostgreSQL bij het omgaan met replicatie.
Oorzaken van PostgreSQL-replicatievertraging
Zoals gedefinieerd in onze vorige blog, is een replicatievertraging de kosten van vertraging voor transactie(s) of bewerking(en) berekend door het tijdsverschil van uitvoering tussen de primaire/master en de standby/slave knooppunt.
Aangezien PostgreSQL streaming-replicatie gebruikt, is het ontworpen om snel te zijn, aangezien wijzigingen worden vastgelegd als een reeks reeksen logrecords (byte-by-byte) zoals onderschept door de WAL-ontvanger en deze logrecords vervolgens wegschrijven naar het WAL-bestand. Vervolgens speelt het opstartproces van PostgreSQL de gegevens van dat WAL-segment opnieuw af en begint de streamingreplicatie. In PostgreSQL kan een replicatievertraging optreden door de volgende factoren:
- Netwerkproblemen
- Kan het WAL-segment niet vinden in het primaire segment. Meestal is dit te wijten aan het controlepuntgedrag waarbij WAL-segmenten worden gedraaid of gerecycled
- Bezige nodes (primair en stand-by(s)). Kan worden veroorzaakt door externe processen of door een aantal slechte query's die veel resources kosten
- Slechte hardware of hardwareproblemen die enige vertraging veroorzaken
- Slechte configuratie in PostgreSQL, zoals kleine aantallen max_wal_senders die worden ingesteld tijdens het verwerken van tonnen transactieverzoeken (of een groot aantal wijzigingen).
Waar u op moet letten bij PostgreSQL-replicatievertraging
PostgreSQL-replicatie is nog divers, maar het bewaken van de replicatiestatus is subtiel maar niet ingewikkeld. In deze benadering zullen we laten zien dat ze zijn gebaseerd op een primaire standby-configuratie met asynchrone streaming-replicatie. De logische replicatie kan de meeste gevallen die we hier bespreken niet ten goede komen, maar de weergave pg_stat_subscription kan u helpen informatie te verzamelen. In deze blog gaan we daar echter niet op in.
Pg_stat_replication View gebruiken
De meest gebruikelijke benadering is om een query uit te voeren die verwijst naar deze weergave in het primaire knooppunt. Onthoud dat u met deze weergave alleen informatie van het primaire knooppunt kunt verzamelen. Deze weergave bevat de volgende tabeldefinitie op basis van PostgreSQL 11, zoals hieronder weergegeven:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Waar de velden zijn gedefinieerd als (inclusief PG <10 versie),
- pid :Proces-ID van walsender-proces
- usesysid :OID van gebruiker die wordt gebruikt voor streaming-replicatie.
- gebruikersnaam :Naam van de gebruiker die wordt gebruikt voor streaming-replicatie
- toepassingsnaam :Applicatienaam verbonden met master
- client_addr :Adres van stand-by/streaming-replicatie
- client_hostname :Hostnaam van stand-by.
- client_port :TCP-poortnummer waarop stand-by communiceert met WAL-zender
- backend_start :Starttijd wanneer SR verbonden is met Master.
- backend_xmin :xmin-horizon van stand-by gerapporteerd door hot_standby_feedback.
- staat :Huidige WAL-afzenderstatus, d.w.z. streaming
- sent_lsn /sent_location :Laatste transactielocatie naar stand-by gestuurd.
- write_lsn /write_location :Laatste transactie geschreven op schijf in stand-by
- flush_lsn /flush_locatie :Laatste transactiespoeling op schijf in stand-by.
- replay_lsn /replay_location :Laatste transactiespoeling op schijf in stand-by.
- write_lag :verstreken tijd tijdens vastgelegde WAL's van primair naar stand-by (maar nog niet vastgelegd in stand-by)
- flush_lag :verstreken tijd tijdens vastgelegde WAL's van primair naar stand-by (WAL's zijn al gewist maar nog niet toegepast)
- replay_lag :Verstreken tijd tijdens vastgelegde WAL's van primair naar stand-by (volledig vastgelegd in stand-byknooppunt)
- sync_priority :Prioriteit van de standby-server die wordt gekozen als synchrone standby
- sync_state :Synchronisatiestatus van stand-by (is het asynchroon of synchroon).
Een voorbeeldquery zou er als volgt uitzien in PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncDit vertelt je in feite welke locatieblokken in de WAL-segmenten zijn geschreven, gewist of toegepast. Het geeft u een gedetailleerd overzicht van de replicatiestatus.
Query's voor gebruik in het standby-knooppunt
In het standby-knooppunt zijn er functies die worden ondersteund waarvoor u dit in een query kunt verminderen en u een overzicht kunt geven van de status van uw standby-replicatie. Om dit te doen, kunt u de volgende query hieronder uitvoeren (query is gebaseerd op PG-versie> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00In oudere versies kunt u de volgende zoekopdracht gebruiken:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Wat zegt de query? Functies worden hier dienovereenkomstig gedefinieerd,
- pg_is_in_recovery ():(boolean) Waar als het herstel nog bezig is.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) De voorschrijfloglocatie die is ontvangen en naar schijf is gesynchroniseerd door streamingreplicatie.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) De laatste write-ahead loglocatie die tijdens het herstel is afgespeeld. Als het herstel nog aan de gang is, zal dit monotoon toenemen.
- pg_last_xact_replay_timestamp (): (tijdstempel met tijdzone) Ontvang het tijdstempel van de laatste transactie die tijdens herstel wordt afgespeeld.
Met wat basis wiskunde kun je deze functies combineren. De meest gebruikte functie die door DBA's wordt gebruikt, is:
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
of in versies PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Hoewel deze query in de praktijk is geweest en wordt gebruikt door DBA's. Toch geeft het u geen nauwkeurig beeld van de vertraging. Waarom? Laten we dit in het volgende gedeelte bespreken.
Lag identificeren die wordt veroorzaakt door de afwezigheid van het WAL-segment
PostgreSQL-standby-knooppunten, die zich in de herstelmodus bevinden, rapporteren niet de exacte status van wat er met uw replicatie gebeurt. Tenzij u het PG-logboek bekijkt, kunt u informatie verzamelen over wat er aan de hand is. Er is geen query die u kunt uitvoeren om dit te bepalen. In de meeste gevallen komen organisaties en zelfs kleine instellingen met software van derden om hen te laten waarschuwen wanneer er alarm wordt geslagen.
Een daarvan is ClusterControl, dat u observatie biedt, waarschuwingen verzendt wanneer er alarm wordt geslagen of uw node herstelt in geval van een ramp of catastrofe. Laten we dit scenario nemen, mijn primaire-stand-by asynchrone streaming replicatiecluster is mislukt. Hoe weet je of er iets mis is? Laten we het volgende combineren:
Stap 1:Bepaal of er een vertraging is
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Stap 2:Bepaal de WAL-segmenten die zijn ontvangen van het primaire knooppunt en vergelijk met het stand-byknooppunt
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70Gebruik pg_current_xlog_location voor oudere versies van PG <10.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Dat ziet er slecht uit.
Stap 3:Bepaal hoe erg het kan zijn
Laten we nu de formule van stap #1 en in stap #2 mengen en de diff. Hoe dit te doen, PostgreSQL heeft een functie genaamd pg_wal_lsn_diff die is gedefinieerd als,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (location pg_lsn, location pg_lsn): (numeriek) Bereken het verschil tussen twee voorschrijfloglocaties
Laten we het nu gebruiken om de vertraging te bepalen. Je kunt het in elk PG-knooppunt uitvoeren, omdat we alleen de statische waarden leveren:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Laten we schatten hoeveel 1800913104 is, dat lijkt ongeveer 1,6 GiB te zijn, zou afwezig kunnen zijn in de standby-node,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Ten slotte kunt u doorgaan of zelfs voorafgaand aan de zoekopdracht de logs bekijken, zoals het gebruik van staart -5f om te volgen en te controleren wat er aan de hand is. Doe dit voor zowel primaire/standby-knooppunten. In dit voorbeeld zullen we zien dat er een probleem is,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Als je dit probleem tegenkomt, is het beter om je standby-knooppunten opnieuw op te bouwen. In ClusterControl is het zo eenvoudig als één klik. Ga gewoon naar de sectie Knooppunten/Topologie en bouw de knoop opnieuw op zoals hieronder:
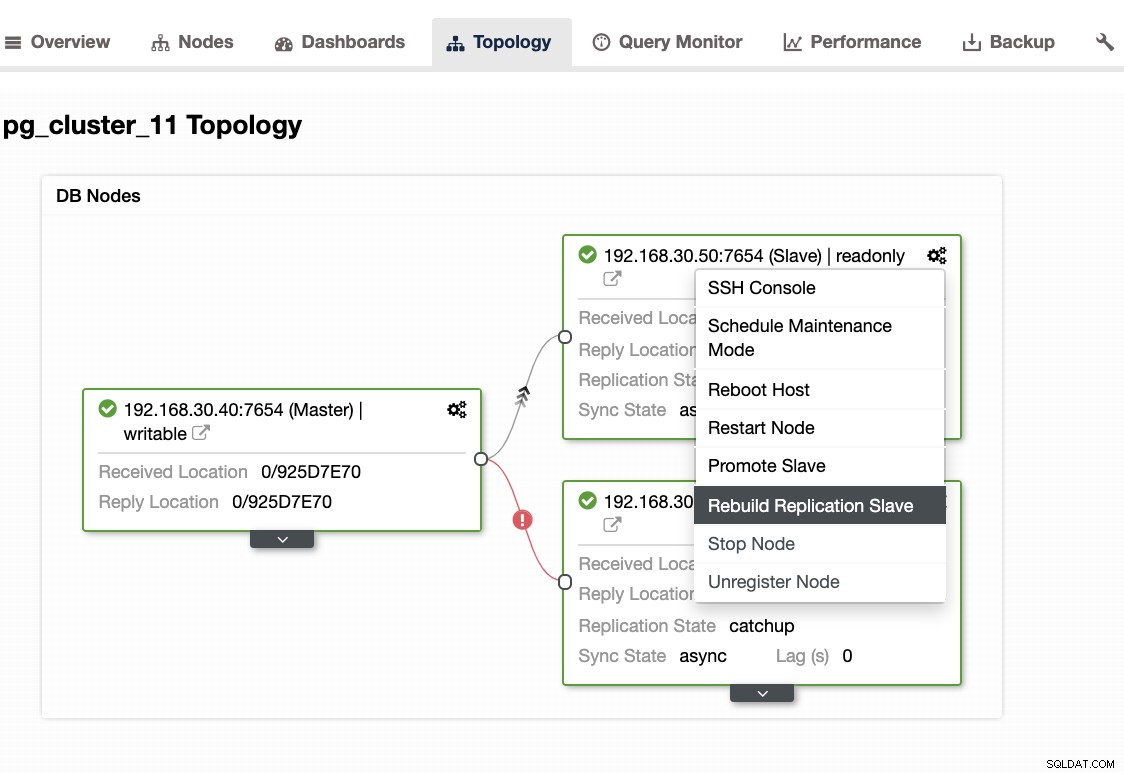
Andere dingen om te controleren
Je kunt dezelfde aanpak gebruiken in onze vorige blog (in MySQL), met systeemtools zoals ps, top, iostat, netstat combinatie. U kunt bijvoorbeeld ook het huidige herstelde WAL-segment ophalen van de standby-node,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Hoe kan ClusterControl helpen?
ClusterControl biedt een efficiënte manier om uw databaseknooppunten te bewaken van de primaire naar de slave-knooppunten. Als u naar het tabblad Overzicht gaat, heeft u al de weergave van uw replicatiestatus:
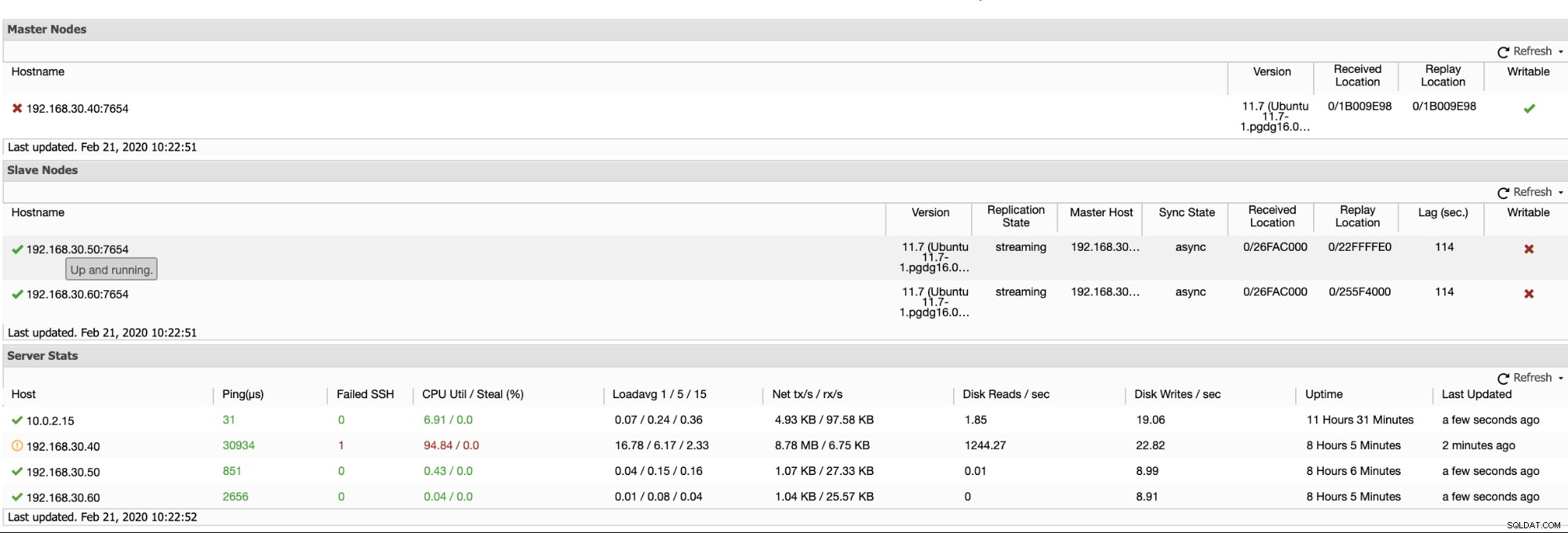
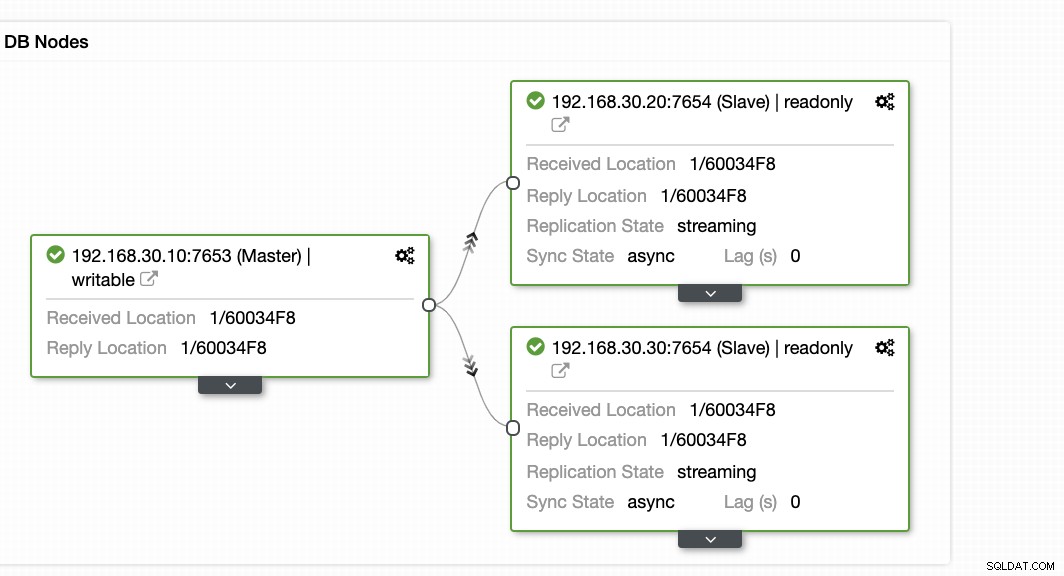
Kortom, de twee bovenstaande schermafbeeldingen laten zien hoe de replicatiestatus is en wat de huidige WAL-segmenten. Dat is helemaal niet. ClusterControl toont ook de huidige activiteit van wat er met uw Cluster gebeurt.
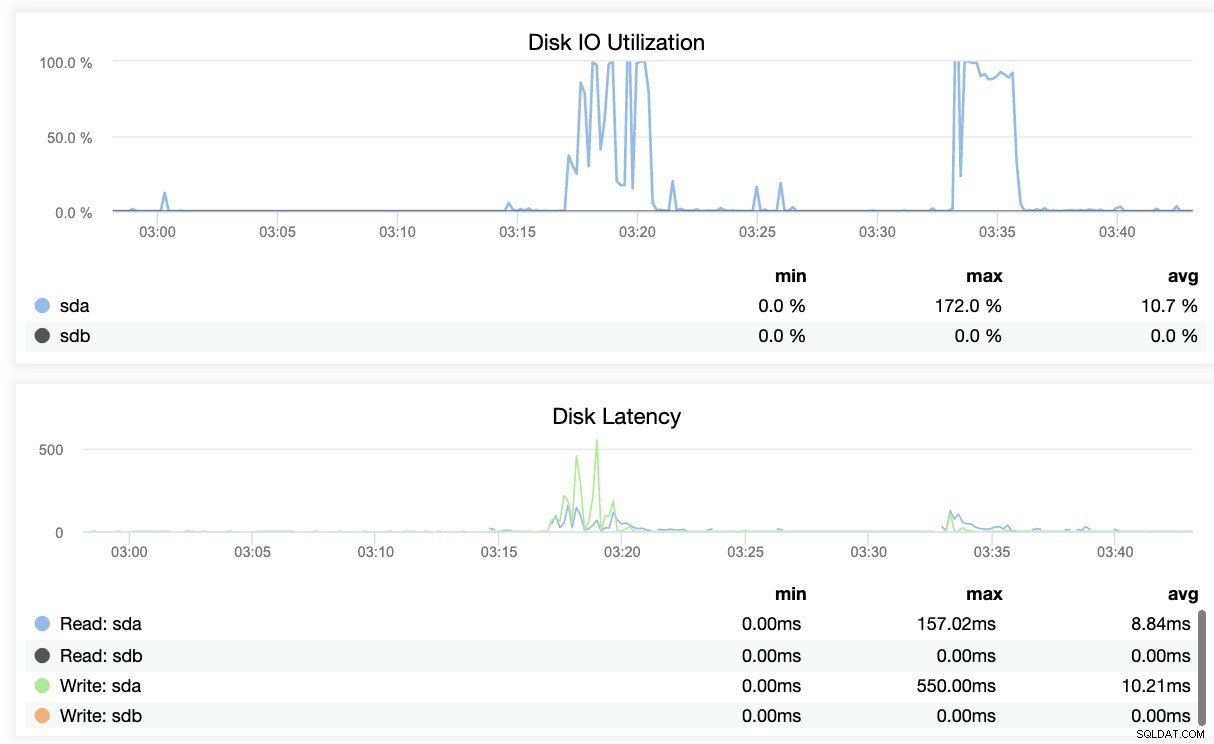
Conclusie
Het monitoren van de replicatiegezondheid in PostgreSQL kan op een andere aanpak eindigen, zolang u maar aan uw behoeften kunt voldoen. Het gebruik van observeerbare tools van derden die u kunnen waarschuwen in geval van een ramp is uw perfecte route, of dit nu een open source of onderneming is. Het belangrijkste is dat u uw rampenherstelplan en bedrijfscontinuïteit vóór dergelijke problemen hebt gepland.