PostgreSQL-streamingreplicatie is een geweldige manier om PostgreSQL-clusters te schalen en voegt hieraan hoge beschikbaarheid toe. Zoals bij elke replicatie, is het idee dat de slave een kopie is van de master en dat de slave constant wordt bijgewerkt met de wijzigingen die op de master zijn aangebracht met behulp van een soort replicatiemechanisme.
Het kan gebeuren dat de slave om de een of andere reden niet meer synchroon loopt met de master. Hoe kan ik het terugbrengen naar de replicatieketen? Hoe kan ik ervoor zorgen dat de slave weer synchroon loopt met de master? Laten we een kijkje nemen in deze korte blogpost.
Wat erg handig is, is dat er geen manier is om op een slave te schrijven als deze zich in de herstelmodus bevindt. Je kunt het zo testen:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionHet kan nog steeds gebeuren dat de slave niet meer synchroon loopt met de master. Gegevenscorruptie - noch hardware of software is zonder bugs en problemen. Sommige problemen met de diskdrive kunnen datacorruptie op de slave veroorzaken. Sommige problemen met het "vacuüm"-proces kunnen ertoe leiden dat gegevens worden gewijzigd. Hoe herstel je van die toestand?
De slaaf opnieuw opbouwen met pg_basebackup
De belangrijkste stap is om de slave in te richten met behulp van de gegevens van de master. Aangezien we streamingreplicatie gaan gebruiken, kunnen we geen logische back-up gebruiken. Gelukkig is er een kant-en-klare tool die kan worden gebruikt om dingen in te stellen:pg_basebackup. Laten we eens kijken wat de stappen zijn die we moeten nemen om een slave-server in te richten. Om het duidelijk te maken, gebruiken we PostgreSQL 12 voor het doel van deze blogpost.
De beginstatus is eenvoudig. Onze slaaf repliceert niet van zijn meester. De gegevens die het bevat, zijn beschadigd en kunnen niet worden gebruikt of vertrouwd. Daarom is de eerste stap die we zullen doen, het stoppen van PostgreSQL op onze slave en het verwijderen van de gegevens die het bevat:
example@sqldat.com:~# systemctl stop postgresqlOf zelfs:
example@sqldat.com:~# killall -9 postgresLaten we nu de inhoud van het postgresql.auto.conf-bestand controleren, we kunnen de in dat bestand opgeslagen replicatiegegevens later gebruiken voor pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'We zijn geïnteresseerd in de gebruiker en het wachtwoord die worden gebruikt voor het instellen van de replicatie.
Eindelijk kunnen we de gegevens verwijderen:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*Zodra de gegevens zijn verwijderd, moeten we pg_basebackup gebruiken om de gegevens van de master te krijgen:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointDe vlaggen die we gebruikten hebben de volgende betekenis:
- -Xs: we willen WAL streamen terwijl de back-up wordt gemaakt. Dit helpt problemen met het verwijderen van WAL-bestanden te voorkomen wanneer u een grote dataset heeft.
- -P: we willen graag de voortgang van de back-up zien.
- -R: we willen dat pg_basebackup het standby.signal-bestand maakt en het postgresql.auto.conf-bestand met verbindingsinstellingen voorbereidt.
pg_basebackup wacht op het controlepunt voordat de back-up wordt gestart. Als het te lang duurt, kunt u twee opties gebruiken. Ten eerste is het mogelijk om de checkpoint-modus op snel in te stellen in pg_basebackup met de optie '-c fast'. Als alternatief kunt u controlepunten forceren door het volgende uit te voeren:
postgres=# CHECKPOINT;
CHECKPOINTOp de een of andere manier zal pg_basebackup starten. Met de vlag -P kunnen we de voortgang volgen:
416906/1588478 kB (26%), 0/1 tablespaceceaceZodra de back-up gereed is, hoeven we er alleen maar voor te zorgen dat de inhoud van de gegevensmap de juiste gebruiker en groep heeft - we hebben pg_basebackup uitgevoerd als 'root' en daarom willen we dit wijzigen in 'postgres' ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Dat is alles, we kunnen de slave starten en deze zou moeten beginnen te repliceren vanaf de master.
example@sqldat.com:~# systemctl start postgresqlU kunt de voortgang van de replicatie controleren door de volgende query op de master uit te voeren:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Zoals je kunt zien, repliceren beide slaven correct.
De slave opnieuw opbouwen met ClusterControl
Als u een ClusterControl-gebruiker bent, kunt u eenvoudig precies hetzelfde bereiken door een optie in de gebruikersinterface te kiezen.
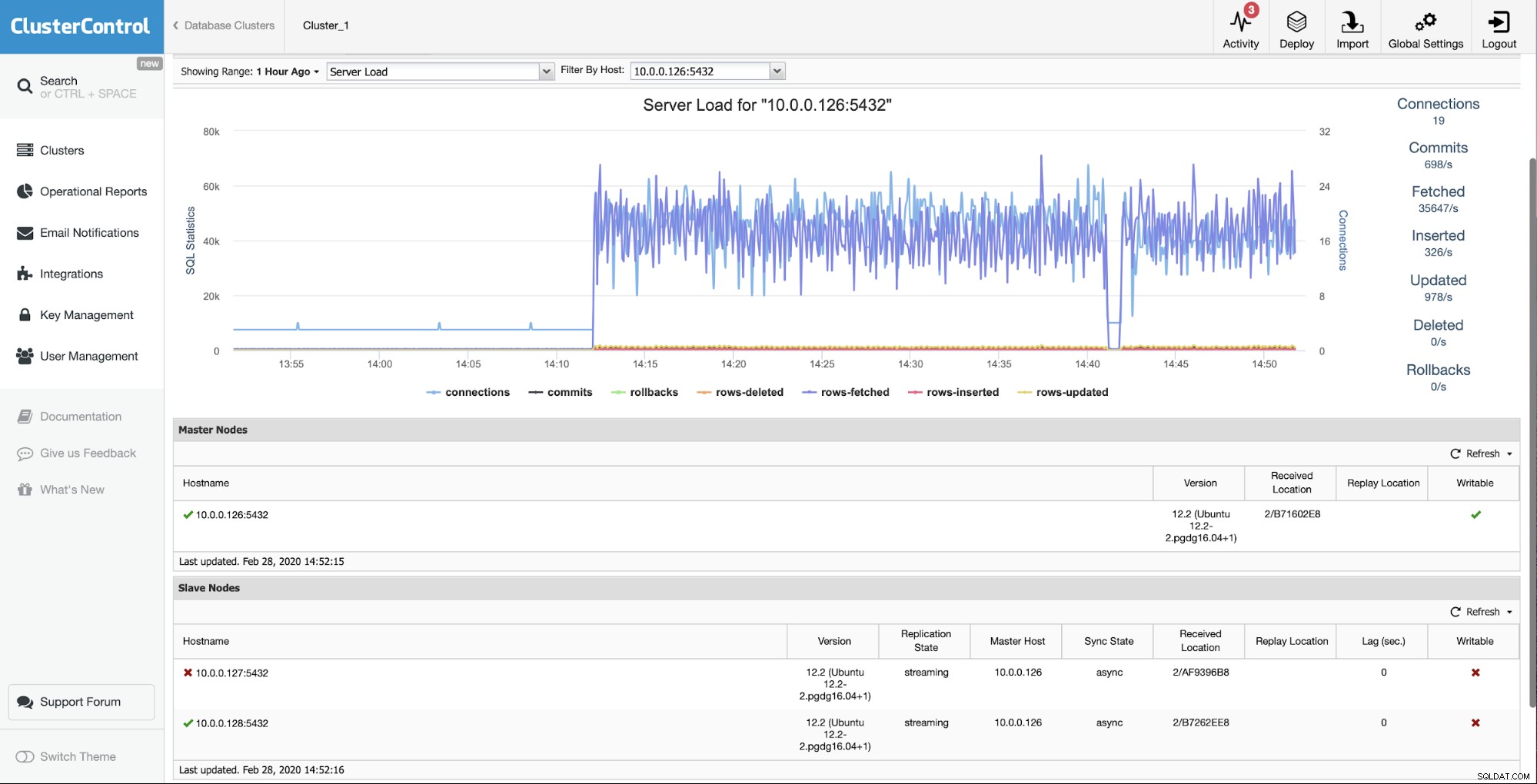
De beginsituatie is dat een van de slaves (10.0.0.127) werkt niet en repliceert niet. We waren van mening dat de herbouw de beste optie voor ons was.
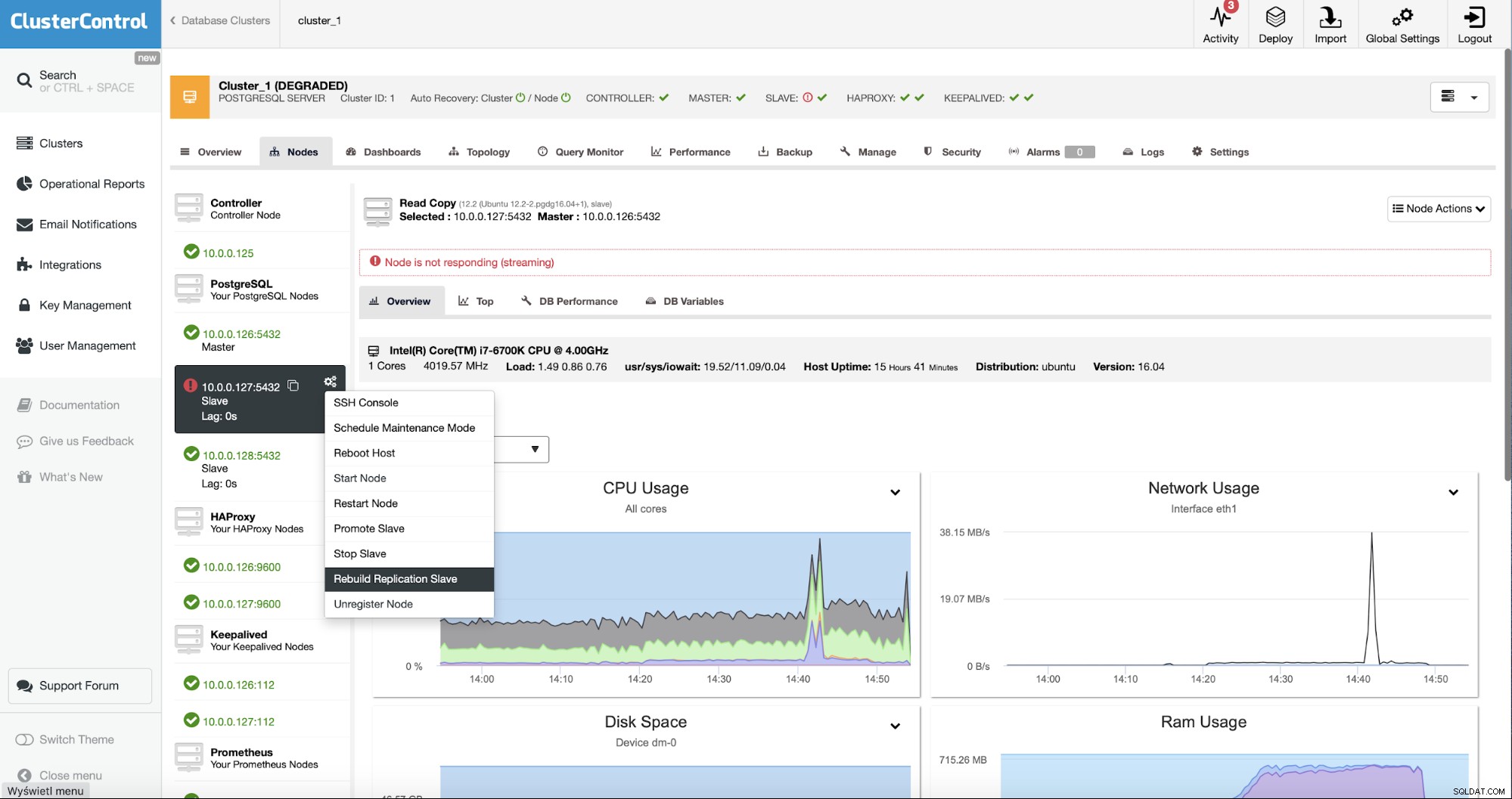
Als ClusterControl-gebruikers hoeven we alleen maar naar de "Nodes ” tabblad en voer de taak “Rebuild Replication Slave” uit.
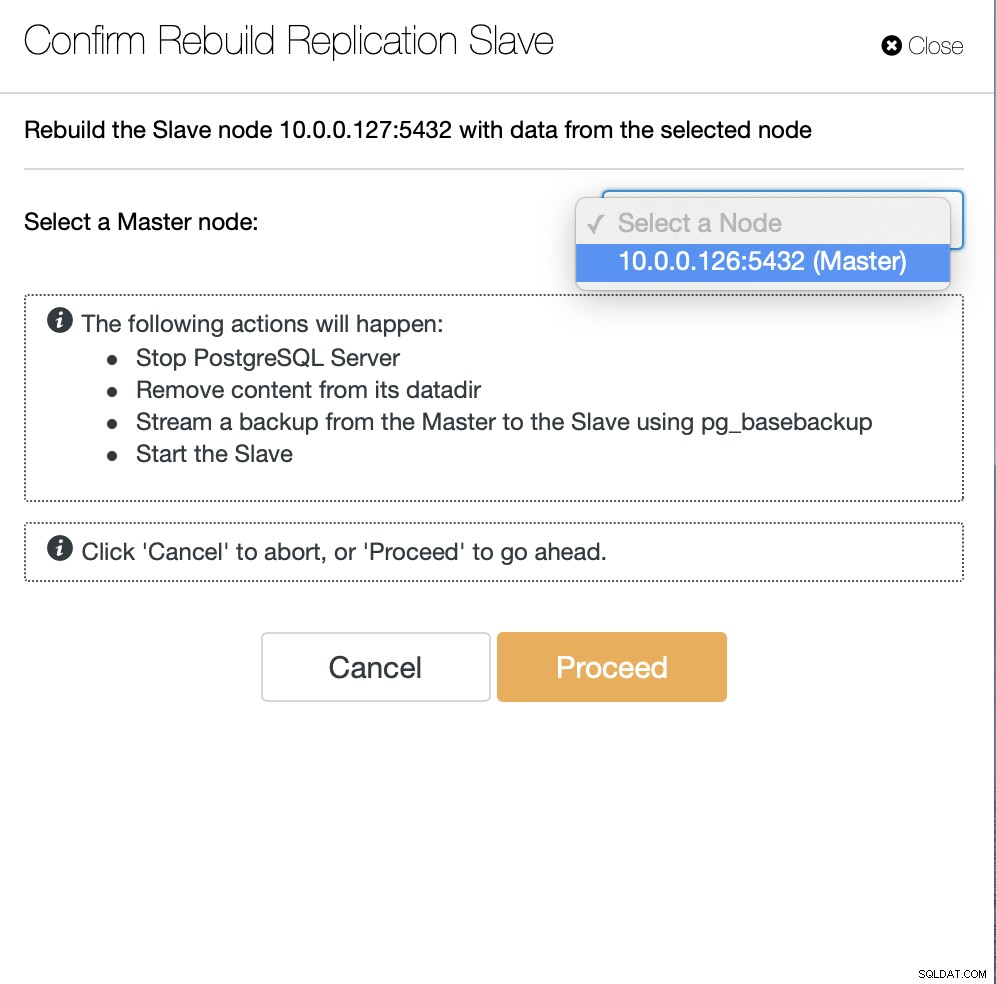
Vervolgens moeten we het knooppunt kiezen om de slaaf opnieuw op te bouwen en dat is alle. ClusterControl zal pg_basebackup gebruiken om de replicatieslave in te stellen en de replicatie te configureren zodra de gegevens zijn overgedragen.
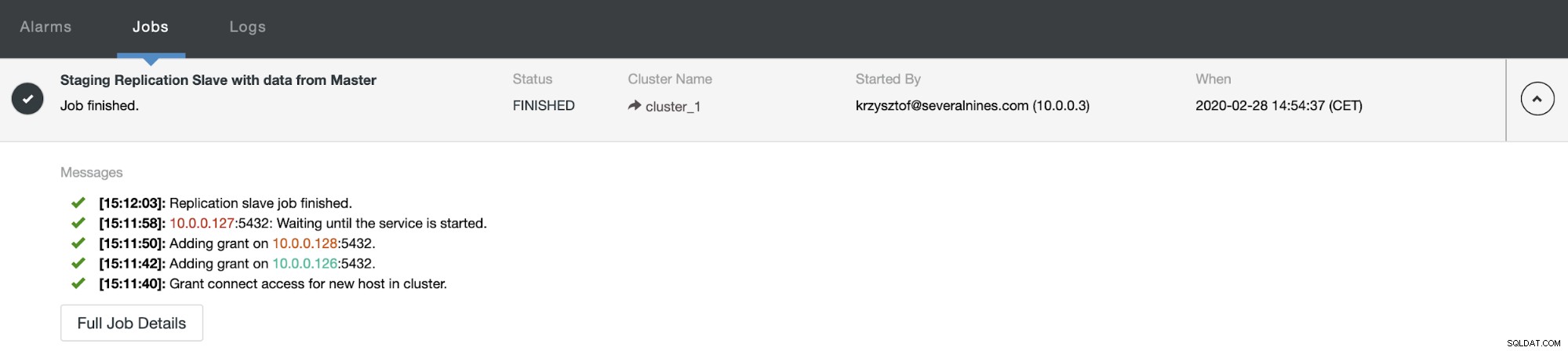
Na enige tijd is de taak voltooid en is de slave terug in de replicatieketen:
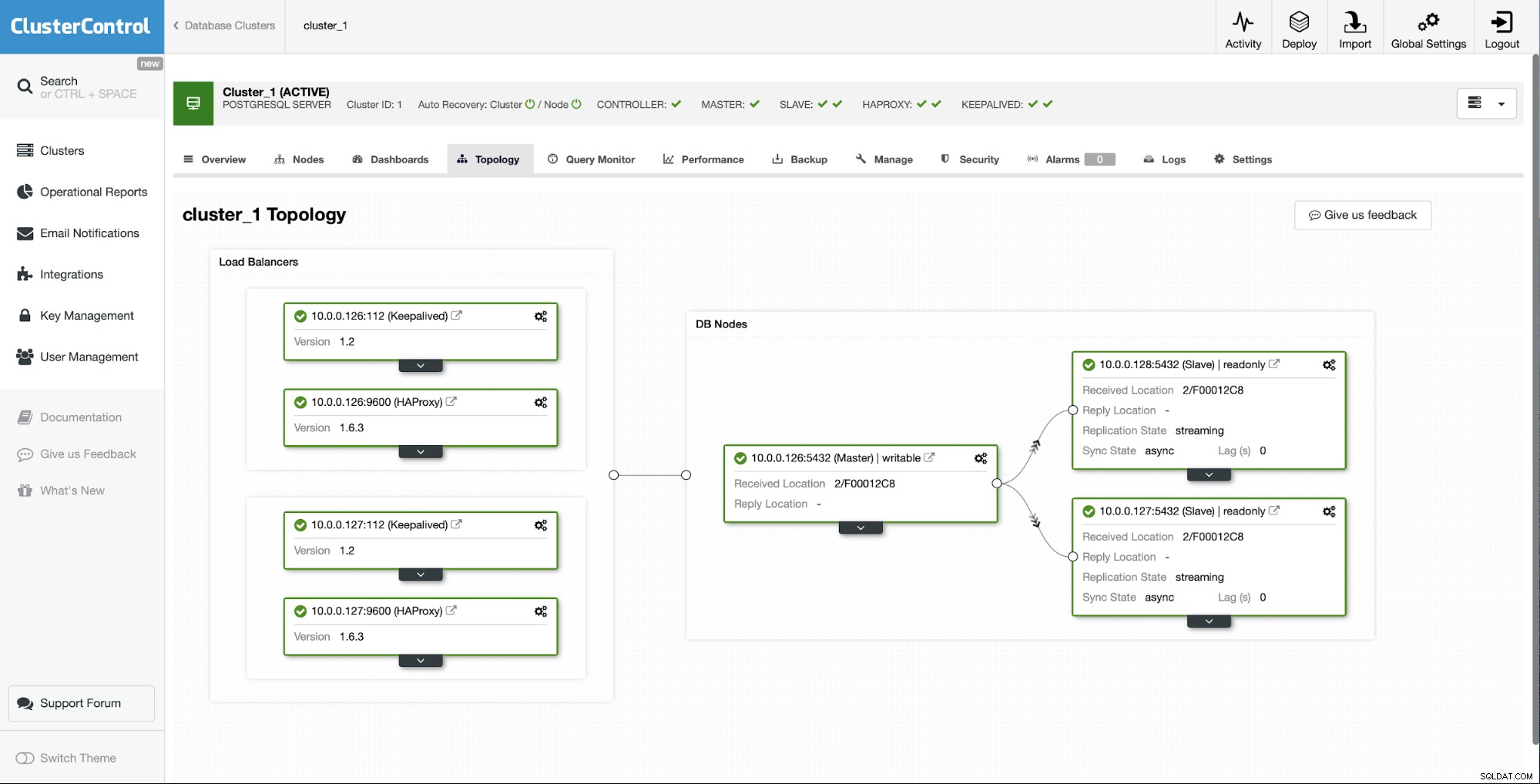
Zoals je kunt zien, zijn we er dankzij ClusterControl met slechts een paar klikken in geslaagd om onze mislukte slaaf opnieuw op te bouwen en terug te brengen naar het cluster.