Tijdens het aanpassen van postgresql.conf , heb je misschien gemerkt dat er een optie is met de naam full_page_writes . De opmerking ernaast zegt iets over het schrijven van gedeeltelijke pagina's, en mensen laten het over het algemeen ingesteld op on - wat een goede zaak is, zoals ik later in dit bericht zal uitleggen. Het is echter nuttig om te begrijpen wat het schrijven van volledige pagina's doet, omdat de impact op de prestaties behoorlijk groot kan zijn.
In tegenstelling tot mijn vorige bericht over het afstemmen van checkpoints, is dit geen handleiding voor het afstemmen van de server. Er is eigenlijk niet veel dat u kunt aanpassen, maar ik zal u laten zien hoe sommige beslissingen op toepassingsniveau (bijvoorbeeld de keuze van gegevenstypen) kunnen interageren met het schrijven van volledige pagina's.
Gedeeltelijke schrijfacties / gescheurde pagina's
Dus waar schrijft een volledige pagina over? Zoals de opmerking in postgresql.conf zegt dat het een manier is om te herstellen van gedeeltelijk geschreven pagina's - PostgreSQL gebruikt 8 kB pagina's (standaard), maar andere delen van de stapel gebruiken verschillende chunk-groottes. Linux-bestandssystemen gebruiken meestal 4kB-pagina's (het is mogelijk om kleinere pagina's te gebruiken, maar 4kB is het maximum op x86), en op hardwareniveau gebruikten de oude schijven 512B-sectoren, terwijl nieuwe apparaten gegevens vaak in grotere brokken schrijven (vaak 4kB of zelfs 8kB) .
Dus wanneer PostgreSQL de pagina van 8 kB schrijft, kunnen de andere lagen van de opslagstack dit opsplitsen in kleinere stukjes, afzonderlijk beheerd. Dit levert een probleem op met betrekking tot schrijfatomiciteit. De 8kB PostgreSQL-pagina kan worden opgesplitst in twee 4kB-bestandssysteempagina's en vervolgens in 512B-sectoren. Wat nu als de server crasht (stroomstoring, kernelbug, ...)?
Zelfs als de server een opslagsysteem gebruikt dat is ontworpen om met dergelijke storingen om te gaan (SSD's met condensatoren, RAID-controllers met batterijen, ...), splitst de kernel de gegevens al in pagina's van 4 kB. Het is dus mogelijk dat de database een gegevenspagina van 8 kB heeft geschreven, maar dat slechts een deel daarvan vóór de crash op schijf is terechtgekomen.
Op dit punt denk je nu waarschijnlijk dat dit precies de reden is waarom we een transactielogboek (WAL) hebben, en je hebt gelijk! Dus na het starten van de server zal de database WAL lezen (sinds het laatste voltooide controlepunt) en de wijzigingen opnieuw toepassen om ervoor te zorgen dat de gegevensbestanden compleet zijn. Eenvoudig.
Maar er is een addertje onder het gras - het herstel past de wijzigingen niet blindelings toe, het moet vaak de gegevenspagina's enz. lezen. Wat ervan uitgaat dat de pagina niet al op de een of andere manier is borked, bijvoorbeeld vanwege een gedeeltelijk schrijven. Dat lijkt een beetje tegenstrijdig, want om datacorruptie op te lossen, gaan we ervan uit dat er geen datacorruptie is.
Het schrijven van volledige pagina's is een manier om dit raadsel te omzeilen - wanneer een pagina voor het eerst wordt gewijzigd na een controlepunt, wordt de hele pagina in WAL geschreven. Dit garandeert dat tijdens het herstel het eerste WAL-record dat een pagina aanraakt, de hele pagina bevat, waardoor het niet nodig is om de - mogelijk kapotte - pagina uit het gegevensbestand te lezen.
Schrijf versterking
Het negatieve gevolg hiervan is natuurlijk een grotere WAL-grootte - het veranderen van een enkele byte op de 8kB-pagina zal het geheel in WAL loggen. Het schrijven van de volledige pagina gebeurt alleen bij de eerste keer schrijven na een checkpoint, dus het minder frequent maken van checkpoints is een manier om de situatie te verbeteren - meestal is er een korte "burst" van volledige pagina's schrijven na een checkpoint, en dan relatief weinig volledige paginaschrijfacties tot het einde van een controlepunt.
UUID vs. BIGSERIAL-toetsen
Maar er zijn enkele onverwachte interacties met ontwerpbeslissingen die op applicatieniveau worden genomen. Laten we aannemen dat we een eenvoudige tabel hebben met een primaire sleutel, ofwel een BIGSERIAL of UUID , en we voegen er gegevens in. Zal er een verschil zijn in de hoeveelheid gegenereerde WAL (ervan uitgaande dat we hetzelfde aantal rijen invoegen)?
Het lijkt redelijk om te verwachten dat beide gevallen ongeveer dezelfde hoeveelheid WAL produceren, maar zoals de volgende grafieken illustreren, is er in de praktijk een enorm verschil.
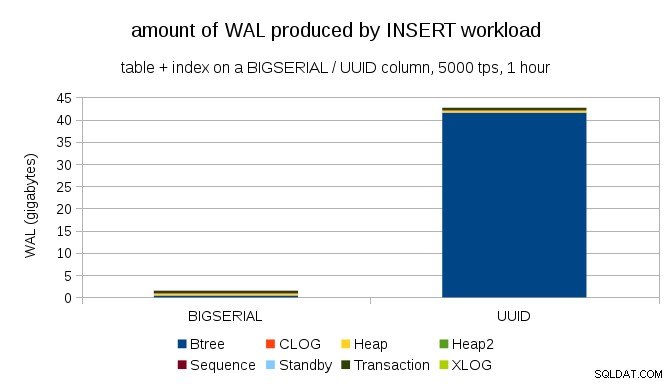
Dit toont de hoeveelheid WAL die is geproduceerd tijdens een benchmark van 1 uur, teruggebracht tot 5000 inserts per seconde. Met BIGSERIAL primaire sleutel levert dit ~2GB aan WAL op, terwijl met UUID het is meer dan 40 GB. Dat is een behoorlijk groot verschil, en het is duidelijk dat het grootste deel van de WAL wordt geassocieerd met het indexeren van de primaire sleutel. Laten we eens kijken als typen WAL-records.
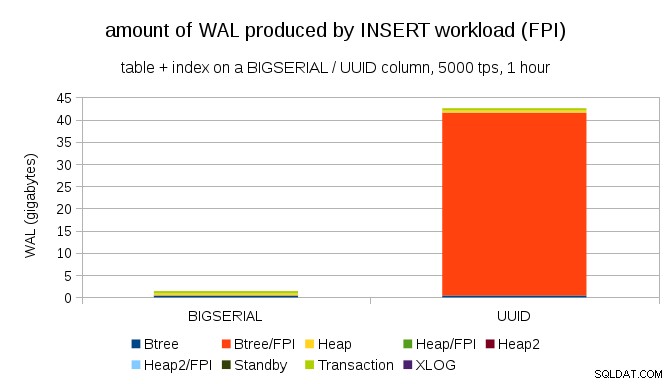
Het is duidelijk dat de overgrote meerderheid van de records paginagrote afbeeldingen (FPI) zijn, d.w.z. het resultaat van paginagrote schrijfacties. Maar waarom gebeurt dit?
Dit komt natuurlijk door de inherente UUID willekeurigheid. Met BIGSERIAL new zijn opeenvolgend, en worden dus ingevoegd in dezelfde bladpagina's in de btree-index. Omdat alleen de eerste wijziging aan een pagina het schrijven van de volledige pagina activeert, is slechts een klein deel van de WAL-records FPI's. Met UUID het is natuurlijk een heel ander geval - de waarden zijn helemaal niet opeenvolgend, in feite zal elke invoeging waarschijnlijk een volledig nieuwe bladindexbladpagina raken (ervan uitgaande dat de index groot genoeg is).
De database kan niet veel doen - de werklast is gewoon willekeurig van aard, wat leidt tot veel schrijfacties over de volledige pagina.
Het is niet moeilijk om vergelijkbare schrijfversterking te krijgen, zelfs met BIGSERIAL sleutels natuurlijk. Het vereist alleen een andere werklast – bijvoorbeeld met UPDATE werklast, het willekeurig bijwerken van records met uniforme verdeling, de grafiek ziet er als volgt uit:
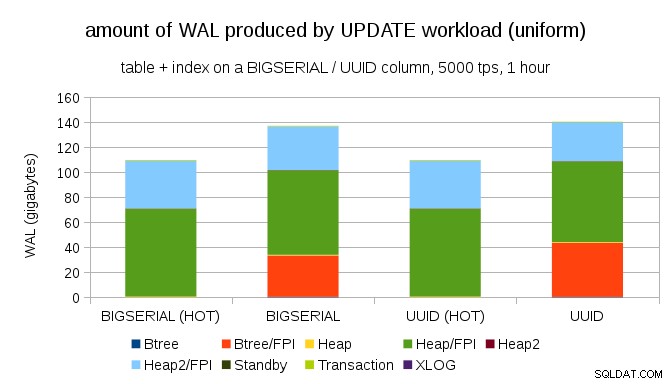
Plots zijn de verschillen tussen gegevenstypen verdwenen - de toegang is in beide gevallen willekeurig, wat resulteert in bijna exact dezelfde hoeveelheid geproduceerde WAL. Een ander verschil is dat het grootste deel van de WAL wordt geassocieerd met "heap", d.w.z. tabellen, en niet met indexen. De "HOT"-cases zijn ontworpen om HOT UPDATE-optimalisatie mogelijk te maken (d.w.z. updaten zonder een index aan te raken), wat vrijwel al het indexgerelateerde WAL-verkeer elimineert.
Maar je zou kunnen stellen dat de meeste applicaties niet de hele dataset bijwerken. Gewoonlijk is slechts een kleine subset van gegevens "actief" - mensen hebben alleen toegang tot berichten van de laatste paar dagen op een discussieforum, onopgeloste bestellingen in een e-shop, enz. Hoe verandert dat de resultaten?
Gelukkig ondersteunt pgbench niet-uniforme distributies, en bijvoorbeeld met exponentiële distributie die ongeveer 25% van de tijd 1% subset van gegevens raakt, ziet de grafiek er als volgt uit:
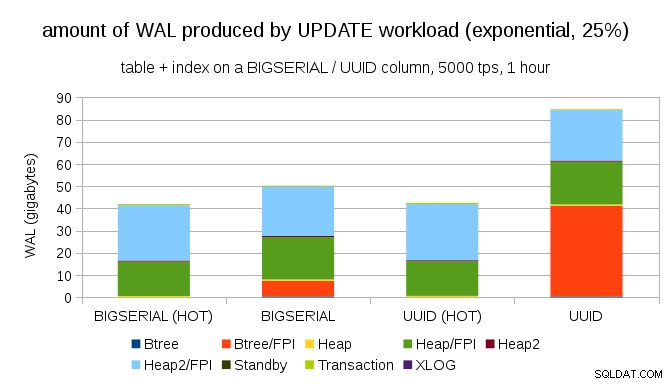
En na de verdeling nog schever te hebben gemaakt en de 1% subset ~75% van de tijd aan te raken:
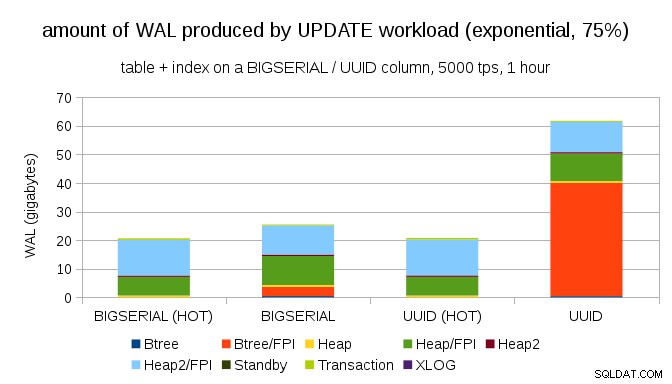
Dit toont nogmaals aan hoe groot het verschil kan zijn tussen de keuze van datatypes, en ook hoe belangrijk het is om af te stemmen op HOT-updates.
8kB en 4kB pagina's
Een interessante vraag is hoeveel WAL-verkeer we zouden kunnen besparen door kleinere pagina's in PostgreSQL te gebruiken (waarvoor een aangepast pakket moet worden samengesteld). In het beste geval kan het tot 50% WAL besparen, dankzij het loggen van slechts 4 kB in plaats van 8 kB pagina's. Voor de werklast met uniform verdeelde UPDATEs ziet het er als volgt uit:
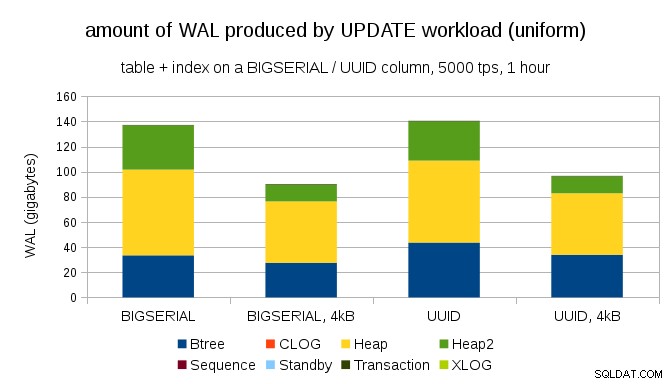
De besparing is dus niet precies 50%, maar de reductie van ~140GB naar ~90GB is nog steeds behoorlijk aanzienlijk.
Hebben we nog paginagrote schrijfacties nodig?
Het lijkt misschien belachelijk na het uitleggen van het gevaar van gedeeltelijk schrijven, maar misschien is het uitschakelen van het schrijven van volledige pagina's een haalbare optie, althans in sommige gevallen.
Ten eerste vraag ik me af of moderne Linux-bestandssystemen nog steeds kwetsbaar zijn voor gedeeltelijke schrijfacties? De parameter is geïntroduceerd in PostgreSQL 8.1, uitgebracht in 2005, dus misschien maken enkele van de vele verbeteringen aan het bestandssysteem die sindsdien zijn geïntroduceerd dit geen probleem. Waarschijnlijk niet universeel voor willekeurige workloads, maar misschien zou het voldoende zijn om uit te gaan van een extra voorwaarde (bijvoorbeeld het gebruik van een paginagrootte van 4 kB in PostgreSQL). Bovendien overschrijft PostgreSQL nooit slechts een subset van de 8kB-pagina - de hele pagina wordt altijd weggeschreven.
Ik heb onlangs veel tests gedaan om een gedeeltelijke schrijfactie te activeren, en het is me nog niet gelukt om een enkel geval te veroorzaken. Dat is natuurlijk niet echt een bewijs dat het probleem niet bestaat. Maar zelfs als het nog steeds een probleem is, kunnen gegevenscontrolesommen voldoende bescherming bieden (het lost het probleem niet op, maar laat u in ieder geval weten dat er een kapotte pagina is).
Ten tweede vertrouwen veel systemen tegenwoordig op replica's van streaming-replicatie - in plaats van te wachten tot de server opnieuw is opgestart na een hardwareprobleem (wat behoorlijk lang kan duren) en dan meer tijd te besteden aan het uitvoeren van herstel, schakelen de systemen gewoon over naar een hot-standby. Als de database op de mislukte primaire wordt verwijderd (en vervolgens wordt gekloond van de nieuwe primaire), zijn gedeeltelijke schrijfacties geen probleem.
Maar ik denk dat als we dat gaan aanbevelen, "Ik weet niet hoe de gegevens zijn beschadigd, ik heb zojuist full_page_writes=uit op de systemen gezet!" zou een van de meest voorkomende zinnen worden vlak voor de dood voor DBA's (samen met de "Ik heb deze slang op reddit gezien, hij is niet giftig.").
Samenvatting
U kunt niet veel doen om paginagrote schrijfacties direct af te stemmen. Voor de meeste workloads vinden de meeste paginagrote schrijfacties plaats direct na een controlepunt en verdwijnen ze vervolgens tot het volgende controlepunt. Het is dus belangrijk om checkpoints zo af te stemmen dat ze niet te vaak voorkomen.
Sommige beslissingen op applicatieniveau kunnen de willekeurigheid van schrijfacties naar tabellen en indexen vergroten. UUID-waarden zijn bijvoorbeeld inherent willekeurig, waardoor zelfs een eenvoudige INSERT-workload wordt omgezet in willekeurige indexupdates. Het schema dat in de voorbeelden werd gebruikt was nogal triviaal - in de praktijk zullen er secundaire indexen, externe sleutels enz. zijn. Maar het intern gebruiken van BIGSERIAL primaire sleutels (en het behouden van de UUID als surrogaatsleutels) zou de schrijfversterking in ieder geval verminderen.
Ik ben erg geïnteresseerd in een discussie over de noodzaak van volledige pagina's schrijven op huidige kernels/bestandssystemen. Helaas heb ik niet veel bronnen gevonden, dus als je relevante informatie hebt, laat het me dan weten.