Zoals we onlangs hebben aangekondigd, heeft ClusterControl 1.7.4 een nieuwe functie genaamd Cluster-naar-Cluster-replicatie. Hiermee kunt u een replicatie tussen twee autonome clusters laten draaien. Voor meer gedetailleerde informatie verwijzen wij u naar de bovengenoemde aankondiging.
We zullen bekijken hoe we deze nieuwe functie kunnen gebruiken voor een bestaand PostgreSQL-cluster. Voor deze taak gaan we ervan uit dat u ClusterControl hebt geïnstalleerd en dat het hoofdcluster ermee is geïmplementeerd.
Vereisten voor het hoofdcluster
Er zijn enkele vereisten voor het hoofdcluster om het te laten werken:
- PostgreSQL 9.6 of hoger.
- Er moet een PostgreSQL-server zijn met de ClusterControl-rol 'Master'.
- Bij het instellen van het slavecluster moeten de beheerdersreferenties identiek zijn aan het mastercluster.
Het hoofdcluster voorbereiden
Het hoofdcluster moet aan de bovengenoemde vereisten voldoen.
Over de eerste vereiste:zorg ervoor dat u de juiste PostgreSQL-versie gebruikt in het Master Cluster en kies hetzelfde voor het Slave Cluster.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitAls u de masterrol aan een specifiek knooppunt moet toewijzen, kunt u dit doen vanuit de gebruikersinterface van ClusterControl. Ga naar ClusterControl -> Selecteer Master Cluster -> Nodes -> Selecteer de Node -> Node Actions -> Promoot Slave.
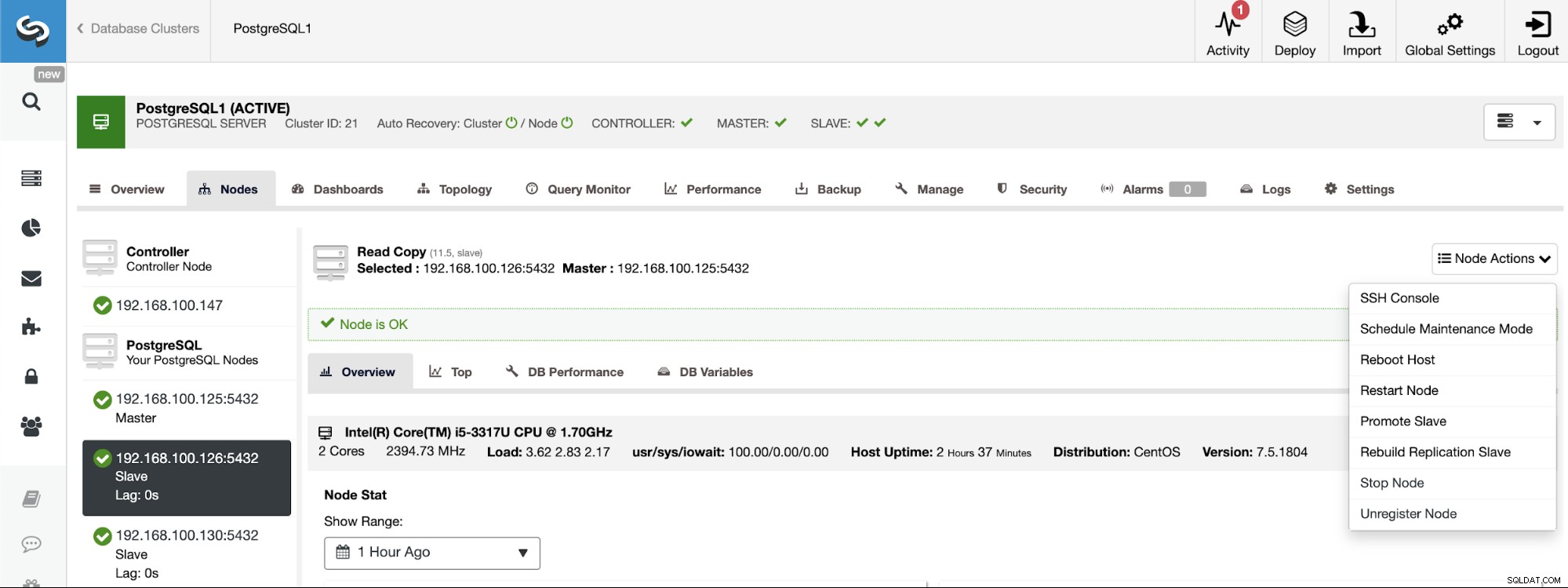
En tot slot, tijdens het maken van de Slave Cluster, moet u dezelfde beheerder gebruiken referenties die u momenteel in het hoofdcluster gebruikt. In het volgende gedeelte ziet u waar u het kunt toevoegen.
Het slavecluster maken vanuit de ClusterControl-gebruikersinterface
Als u een nieuw slavecluster wilt maken, gaat u naar ClusterControl -> Cluster selecteren -> Clusteracties -> Slavecluster maken.
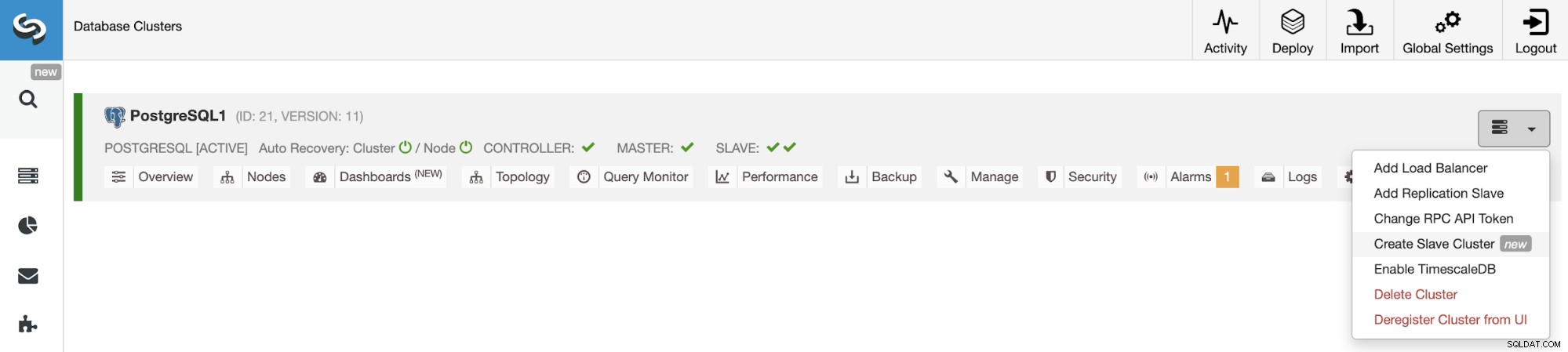
Het slavecluster wordt gemaakt door gegevens uit het huidige mastercluster te streamen.
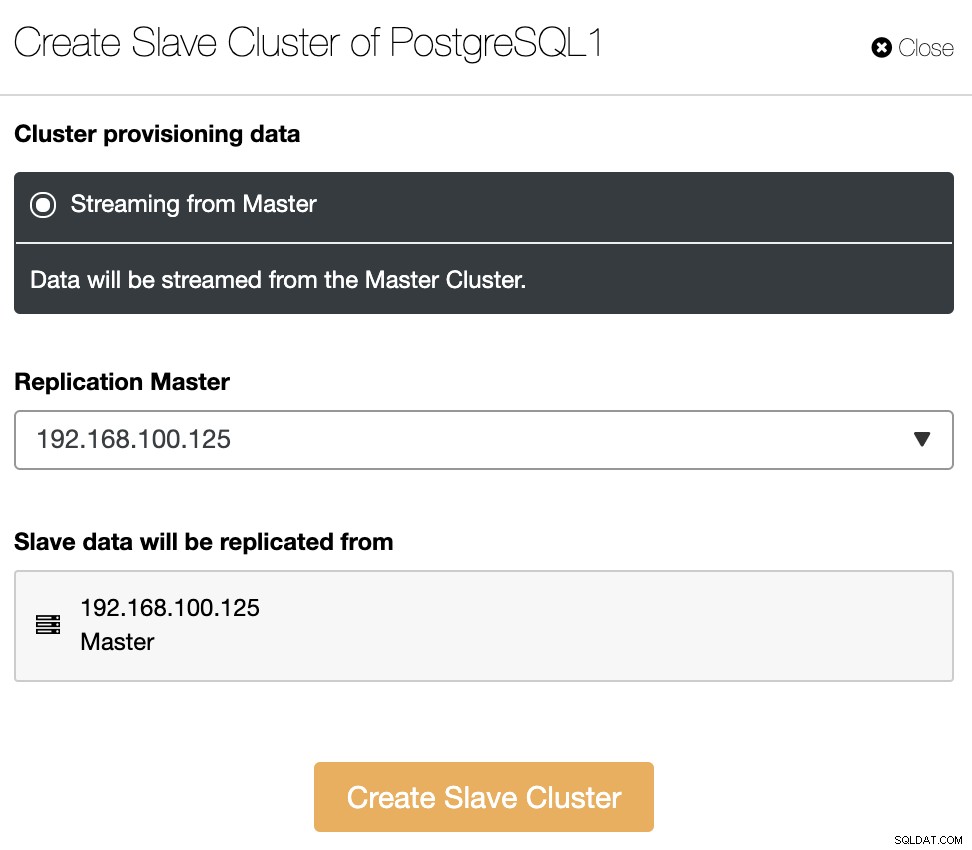
In deze sectie moet u ook het hoofdknooppunt van het huidige cluster kiezen van waaruit de gegevens worden gerepliceerd.
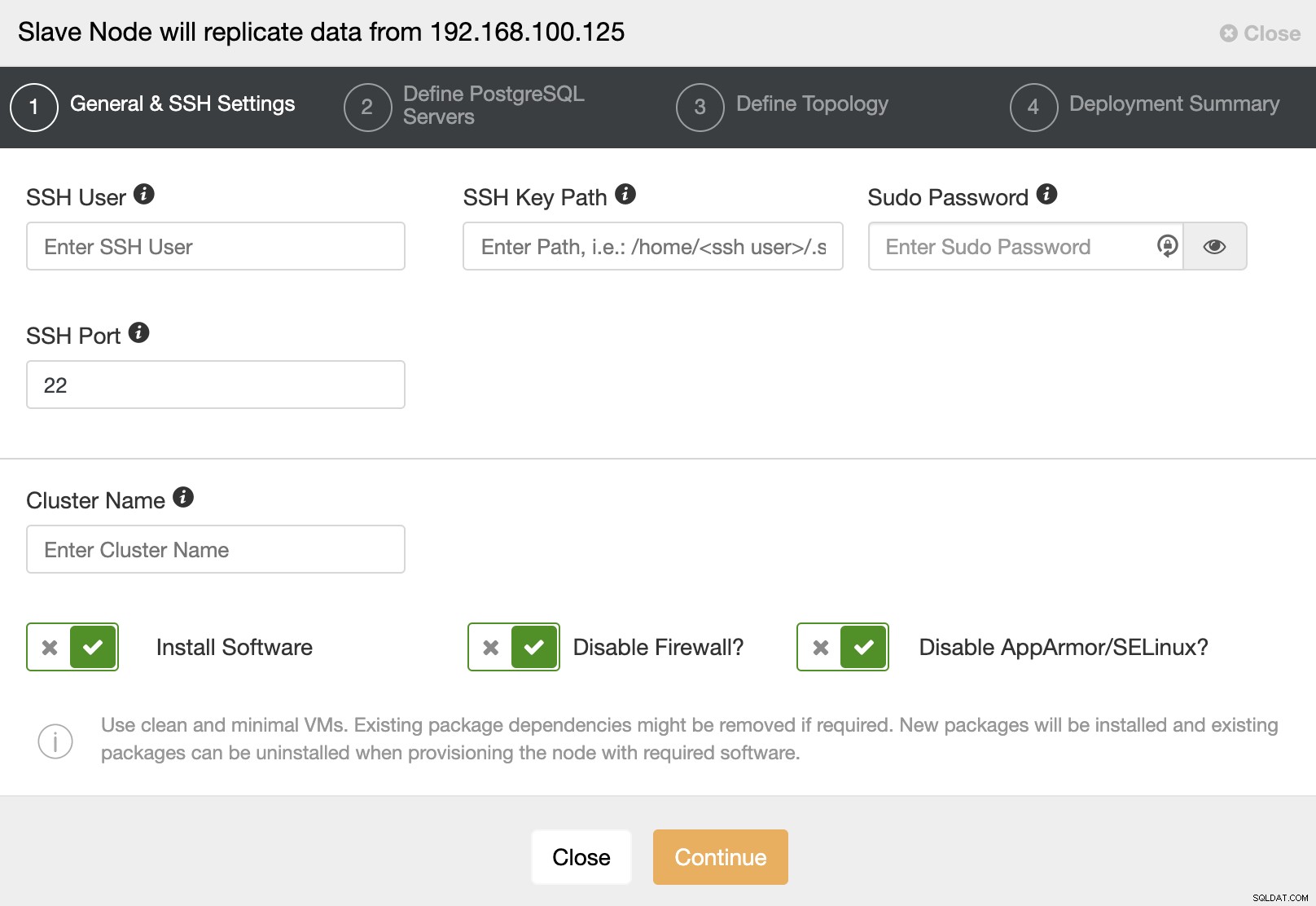
Als u naar de volgende stap gaat, moet u Gebruiker, Sleutel of Wachtwoord en poort om via SSH verbinding te maken met uw servers. U heeft ook een naam nodig voor uw Slave Cluster en als u wilt dat ClusterControl de bijbehorende software en configuraties voor u installeert.
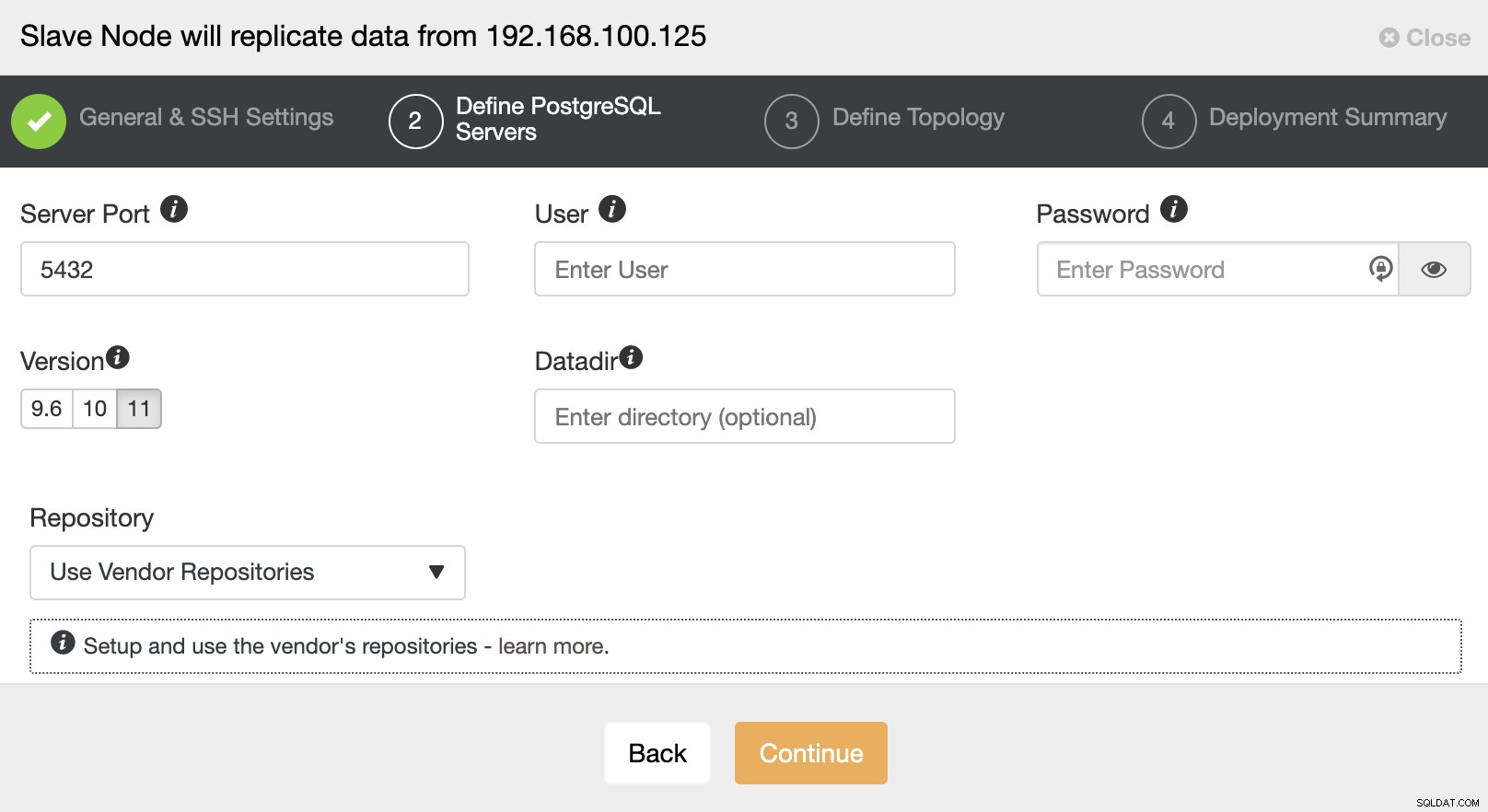
Na het instellen van de SSH-toegangsinformatie, moet u de databaseversie definiëren, datadir, poort en beheerdersreferenties. Aangezien het streaming-replicatie zal gebruiken, moet u ervoor zorgen dat u dezelfde databaseversie gebruikt, en zoals we eerder vermeldden, moeten de referenties dezelfde zijn die door het hoofdcluster worden gebruikt. Je kunt ook aangeven welke repository je wilt gebruiken.
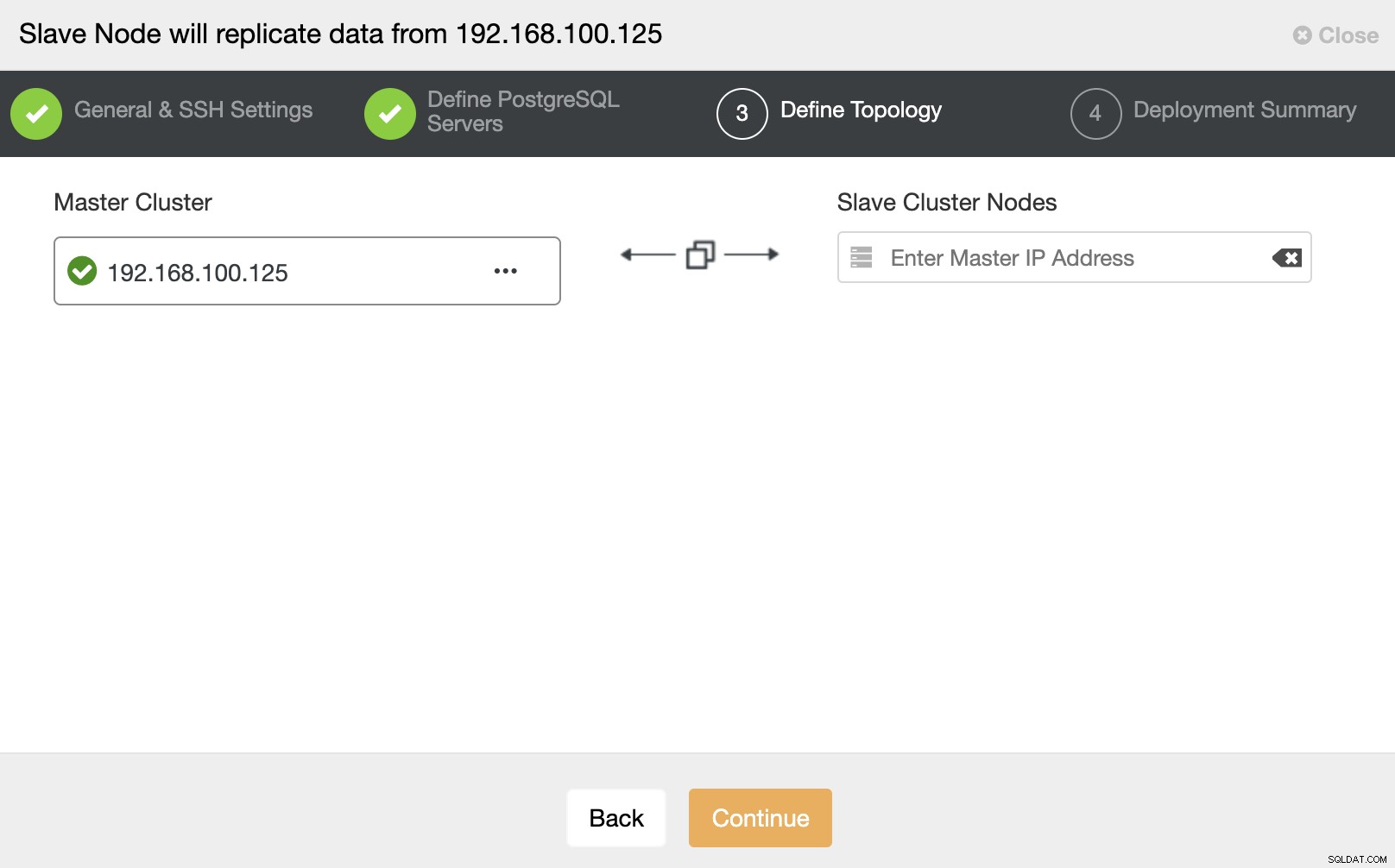
In deze stap moet u de server toevoegen aan het nieuwe Slave-cluster . Voor deze taak kunt u zowel het IP-adres als de hostnaam van het databaseknooppunt invoeren.
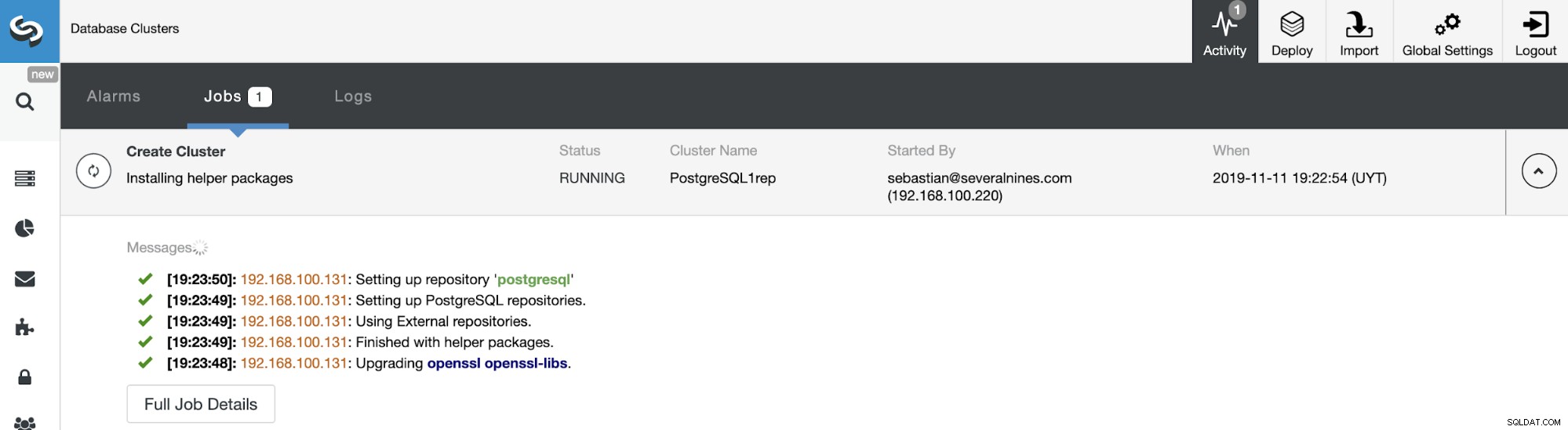
U kunt de status van het maken van uw nieuwe Slave Cluster volgen vanaf de ClusterControl activiteitenmonitor. Zodra de taak is voltooid, kunt u het cluster zien in het hoofdscherm van ClusterControl.
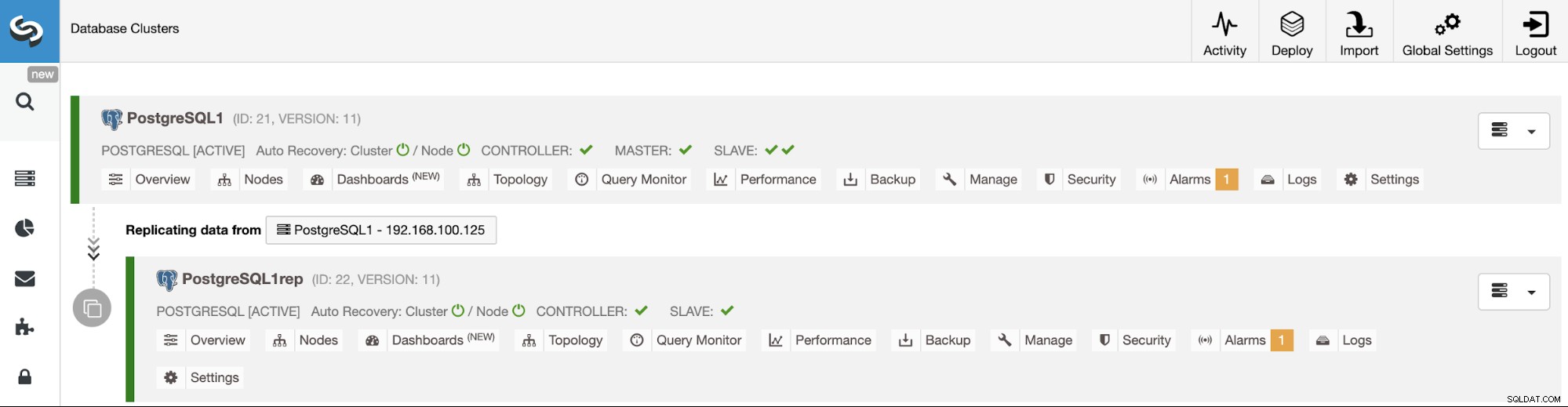
Cluster-naar-cluster-replicatie beheren met de ClusterControl-gebruikersinterface
Nu uw Cluster-naar-Cluster-replicatie actief is, kunt u verschillende acties uitvoeren op deze topologie met ClusterControl.
Een slavencluster opnieuw opbouwen
Om een Slave Cluster opnieuw op te bouwen, gaat u naar ClusterControl -> Selecteer Slave Cluster -> Knooppunten -> Kies de Node die is verbonden met de Master Cluster -> Knooppuntacties -> Rebuild Replication Slave.
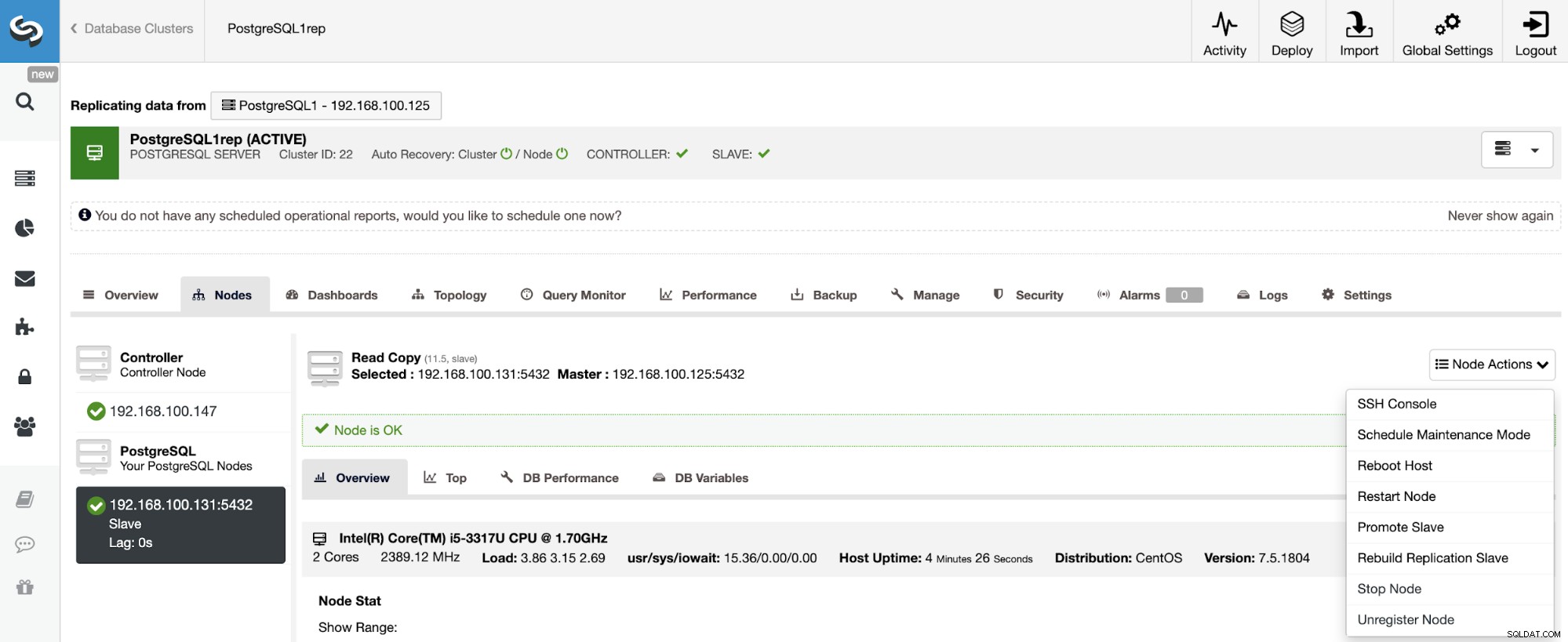
ClusterControl voert de volgende stappen uit:
- PostgreSQL-server stoppen
- Verwijder inhoud uit de datadir
- Stream een back-up van de Master naar de Slave met pg_basebackup
- Start de slaaf
Stop/Start replicatieslave
De stop-en-start-replicatie in PostgreSQL betekent pauzeren en hervatten, maar we gebruiken deze termen om consistent te zijn met andere databasetechnologieën die we ondersteunen.
Deze functie is binnenkort beschikbaar voor gebruik vanuit de gebruikersinterface van ClusterControl. Deze actie gebruikt de functies pg_wal_replay_pause en pg_wal_replay_resume PostgreSQL om deze taak uit te voeren.
Ondertussen kunt u een tijdelijke oplossing gebruiken om de replicatieslave op een eenvoudige manier te stoppen en te starten met het stoppen en starten van het databaseknooppunt met ClusterControl.
Ga naar ClusterControl -> Selecteer Slave-cluster -> Knooppunten -> Kies de Knooppunt -> Knooppuntacties -> Knooppunt stoppen/knooppunt starten. Deze actie zal de databaseservice direct stoppen/starten.
Cluster-naar-cluster-replicatie beheren met de ClusterControl CLI
In het vorige gedeelte hebt u kunnen zien hoe u een Cluster-naar-Cluster-replicatie kunt beheren met behulp van de ClusterControl-gebruikersinterface. Laten we nu eens kijken hoe we dit kunnen doen met behulp van de opdrachtregel.
Opmerking:zoals we aan het begin van deze blog vermeldden, gaan we ervan uit dat je ClusterControl hebt geïnstalleerd en dat het hoofdcluster ermee is geïmplementeerd.
Maak het slavencluster
Laten we eerst een voorbeeldopdracht bekijken om een slavecluster te maken met behulp van de ClusterControl CLI:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logNu heb je je maak-slave-proces aan de gang, laten we elke gebruikte parameter bekijken:
- Cluster:om clusters op te sommen en te manipuleren.
- Maken:maak en installeer een nieuw cluster.
- Clusternaam:de naam van het nieuwe slavencluster.
- Clustertype:het type cluster dat moet worden geïnstalleerd.
- Provider-versie:de softwareversie.
- Knooppunten:lijst met de nieuwe knooppunten in het slavecluster.
- Os-user:de gebruikersnaam voor de SSH-commando's.
- Os-key-file:het sleutelbestand dat moet worden gebruikt voor SSH-verbinding.
- Db-admin:de gebruikersnaam van de databasebeheerder.
- Db-admin-passwd:Het wachtwoord voor de databasebeheerder.
- Remote-cluster-id:hoofdcluster-ID voor de cluster-naar-cluster-replicatie.
- Log:wacht en volg taakberichten.
Als u de vlag --log gebruikt, kunt u de logboeken in realtime bekijken:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Een slavencluster opnieuw opbouwen
U kunt een slavecluster opnieuw opbouwen met de volgende opdracht:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logDe parameters zijn:
- Replicatie:voor het bewaken en controleren van gegevensreplicatie.
- Stage:een replicatieslave uitvoeren/opnieuw bouwen.
- Master:de replicatiemaster in de mastercluster.
- Slaaf:de replicatieslave in het slavecluster.
- Cluster-id:de slave-cluster-ID.
- Remote-cluster-id:de hoofdcluster-ID.
- Log:wacht en volg taakberichten.
Het takenlogboek zou er ongeveer zo uit moeten zien:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Stop/Start replicatieslave
Zoals we in de UI-sectie vermeldden, betekent de stop-en-start-replicatie in PostgreSQL pauzeren en hervatten, maar we gebruiken deze termen om het parallellisme met andere technologieën te behouden.
U kunt op deze manier stoppen om de gegevens van het hoofdcluster te repliceren:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logJe ziet dit:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().En nu kun je het opnieuw beginnen:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logDus je zult zien:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Laten we nu eens kijken naar de gebruikte parameters.
- Replicatie:voor het bewaken en controleren van gegevensreplicatie.
- Stop/Start:om de slave te laten stoppen/starten met repliceren.
- Slaaf:het replicatie-slaveknooppunt.
- Cluster-id:de ID van het cluster waarin het slave-knooppunt zich bevindt.
- Log:wacht en volg taakberichten.
Conclusie
Met deze nieuwe ClusterControl-functie kunt u snel replicatie tussen verschillende PostgreSQL-clusters opzetten en de installatie op een gemakkelijke en vriendelijke manier beheren. Het ontwikkelteam van verschillendenines werkt aan het verbeteren van deze functie, dus alle ideeën of suggesties zijn zeer welkom.