Hoge beschikbaarheid is een vereiste voor zowat elk bedrijf over de hele wereld dat PostgreSQL gebruikt. Het is algemeen bekend dat PostgreSQL Streaming Replication als replicatiemethode gebruikt. PostgreSQL-streamingreplicatie is standaard asynchroon, dus het is mogelijk dat sommige transacties worden vastgelegd in het primaire knooppunt die nog niet zijn gerepliceerd naar de standby-server. Dit betekent dat er een kans bestaat op mogelijk gegevensverlies.
Deze vertraging in het commit-proces wordt verondersteld erg klein te zijn... als de standby-server krachtig genoeg is om de belasting bij te houden. Als dit kleine risico op gegevensverlies niet acceptabel is in het bedrijf, kunt u ook synchrone replicatie gebruiken in plaats van de standaard.
Bij synchrone replicatie wacht elke vastlegging van een schrijftransactie tot de bevestiging dat de vastlegging is geschreven naar het vooruitschrijflogboek op schijf van zowel de primaire als de stand-byserver.
Deze methode minimaliseert de kans op gegevensverlies. Om gegevensverlies te laten optreden, moeten zowel de primaire als de stand-by tegelijkertijd uitvallen.
Het nadeel van deze methode is hetzelfde voor alle synchrone methodes, aangezien bij deze methode de responstijd voor elke schrijftransactie toeneemt. Dit is te wijten aan de noodzaak om te wachten tot alle bevestigingen dat de transactie is gepleegd. Gelukkig worden alleen-lezen transacties hierdoor niet beïnvloed, maar; alleen de schrijftransacties.
In deze blog laat je zien hoe je een PostgreSQL-cluster helemaal opnieuw installeert en de asynchrone replicatie (standaard) converteert naar een synchrone. Ik zal u ook laten zien hoe u een rollback kunt doen als de reactietijd niet acceptabel is, omdat u gemakkelijk terug kunt gaan naar de vorige status. U zult zien hoe u een PostgreSQL synchrone replicatie eenvoudig kunt implementeren, configureren en bewaken met ClusterControl met slechts één tool voor het hele proces.
Een PostgreSQL-cluster installeren
Laten we beginnen met het installeren en configureren van een asynchrone PostgreSQL-replicatie, dat is de gebruikelijke replicatiemodus die wordt gebruikt in een PostgreSQL-cluster. We gebruiken PostgreSQL 11 op CentOS 7.
PostgreSQL-installatie
Als je de officiële installatiehandleiding van PostgreSQL volgt, is deze taak vrij eenvoudig.
Installeer eerst de repository:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmInstalleer de PostgreSQL-client- en serverpakketten:
$ yum install postgresql11 postgresql11-serverInitialiseer de database:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11Op het standby-knooppunt kunt u de laatste opdracht vermijden (start de databaseservice), omdat u een binaire back-up herstelt om de streamingreplicatie te maken.
Laten we nu eens kijken naar de configuratie die vereist is voor een asynchrone PostgreSQL-replicatie.
Asynchrone PostgreSQL-replicatie configureren
Instelling primair knooppunt
In het primaire PostgreSQL-knooppunt moet u de volgende basisconfiguratie gebruiken om een asynchrone replicatie te maken. De bestanden die worden gewijzigd zijn postgresql.conf en pg_hba.conf. Over het algemeen bevinden ze zich in de datadirectory (/var/lib/pgsql/11/data/) maar u kunt het aan de databasekant bevestigen:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Wijzig of voeg de volgende parameters toe in het postgresql.conf configuratiebestand.
Hier moet je het (de) IP-adres(sen) toevoegen waar je naar wilt luisteren. De standaardwaarde is 'localhost' en voor dit voorbeeld gebruiken we '*' voor alle IP-adressen in de server.
listen_addresses = '*' Stel de serverpoort in waarop u wilt luisteren. Standaard 5432.
port = 5432 Bepaal hoeveel informatie naar de WAL's wordt geschreven. De mogelijke waarden zijn minimaal, replica of logisch. De hot_standby-waarde wordt toegewezen aan replica en wordt gebruikt om de compatibiliteit met eerdere versies te behouden.
wal_level = hot_standby Stel het maximale aantal walsender-processen in, die de verbinding met een standby-server beheren.
max_wal_senders = 16Stel het minimum aantal WAL-bestanden in dat in de pg_wal-directory moet worden bewaard.
wal_keep_segments = 32Het wijzigen van deze parameters vereist een herstart van de databaseservice.
$ systemctl restart postgresql-11Pg_hba.conf
Wijzig of voeg de volgende parameters toe in het pg_hba.conf configuratiebestand.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Zoals je kunt zien, moet je hier de gebruikerstoegangsrechten toevoegen. De eerste kolom is het verbindingstype, dat host of lokaal kan zijn. Vervolgens moet u de database (replicatie), de gebruiker, het bron-IP-adres en de authenticatiemethode specificeren. Voor het wijzigen van dit bestand moet de databaseservice opnieuw worden geladen.
$ systemctl reload postgresql-11Je moet deze configuratie toevoegen aan zowel de primaire als de standby-knooppunten, omdat je deze nodig hebt als het standby-knooppunt wordt gepromoveerd tot master in geval van storing.
Nu moet u een replicatiegebruiker maken.
Replicatierol
De ROL (gebruiker) moet REPLICATIE-rechten hebben om deze in de streamingreplicatie te gebruiken.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLENa het configureren van de bijbehorende bestanden en het maken van de gebruiker, moet u een consistente back-up maken vanaf het primaire knooppunt en deze herstellen op het stand-by-knooppunt.
Stand-by knooppunt instellen
Ga op de standby-node naar de /var/lib/pgsql/11/ directory en verplaats of verwijder de huidige datadir:
$ cd /var/lib/pgsql/11/
$ mv data data.bkVoer vervolgens de opdracht pg_basebackup uit om de huidige primaire datadir op te halen en wijs de juiste eigenaar toe (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataNu moet u de volgende basisconfiguratie gebruiken om een asynchrone replicatie te maken. Het bestand dat wordt gewijzigd is postgresql.conf en u moet een nieuw recovery.conf-bestand maken. Beide bevinden zich in /var/lib/pgsql/11/.
Herstel.conf
Geef aan dat deze server een standby-server zal zijn. Als het is ingeschakeld, gaat de server verder met herstellen door nieuwe WAL-segmenten op te halen wanneer het einde van de gearchiveerde WAL is bereikt.
standby_mode = 'on'Geef een verbindingsreeks op die moet worden gebruikt voor de standby-server om verbinding te maken met het primaire knooppunt.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Geef het herstel op in een bepaalde tijdlijn. De standaardinstelling is om te herstellen langs dezelfde tijdlijn die actueel was toen de basisback-up werd gemaakt. Als u dit instelt op "laatste" herstelt u naar de laatste tijdlijn die in het archief is gevonden.
recovery_target_timeline = 'latest'Geef een triggerbestand op waarvan de aanwezigheid het herstel in de stand-by beëindigt.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Wijzig of voeg de volgende parameters toe in het postgresql.conf configuratiebestand.
Bepaal hoeveel informatie naar de WAL's wordt geschreven. De mogelijke waarden zijn minimaal, replica of logisch. De hot_standby-waarde wordt toegewezen aan replica en wordt gebruikt om de compatibiliteit met eerdere versies te behouden. Het wijzigen van deze waarde vereist een herstart van de service.
wal_level = hot_standbySta de zoekopdrachten toe tijdens herstel. Het wijzigen van deze waarde vereist een herstart van de service.
hot_standby = onStandby-knooppunt starten
Nu heb je alle vereiste configuratie, je hoeft alleen maar de databaseservice te starten op het standby-knooppunt.
$ systemctl start postgresql-11En controleer de database logs in /var/lib/pgsql/11/data/log/. Je zou zoiets als dit moeten hebben:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1U kunt ook de replicatiestatus in het primaire knooppunt controleren door de volgende query uit te voeren:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Zoals je kunt zien, gebruiken we een asynchrone replicatie.
Asynchrone PostgreSQL-replicatie converteren naar synchrone replicatie
Nu is het tijd om deze asynchrone replicatie om te zetten in een gesynchroniseerde, en hiervoor moet u zowel het primaire als het standby-knooppunt configureren.
Primair knooppunt
In het primaire PostgreSQL-knooppunt moet u deze basisconfiguratie gebruiken naast de vorige asynchrone configuratie.
Postgresql.conf
Geef een lijst op met standby-servers die synchrone replicatie kunnen ondersteunen. Deze stand-by-servernaam is de instelling voor de toepassingsnaam in het bestand recovery.conf van de stand-by.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Specificeert of transactie-commit wacht tot WAL-records naar schijf zijn geschreven voordat de opdracht een "succes"-indicatie naar de client retourneert. De geldige waarden zijn aan, remote_apply, remote_write, local en off. De standaardwaarde is ingeschakeld.
synchronous_commit = onStand-by-knooppunt instellen
In het PostgreSQL-standbyknooppunt moet u het bestand recovery.conf wijzigen door de 'application_name-waarde toe te voegen aan de parameter primary_conninfo.
Herstel.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Herstart de databaseservice in zowel de primaire als in de standby-knooppunten:
$ service postgresql-11 restartNu zou u uw sync streaming-replicatie in gebruik moeten hebben:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Terugdraaien van synchrone naar asynchrone PostgreSQL-replicatie
Als u terug moet naar asynchrone PostgreSQL-replicatie, hoeft u alleen maar de wijzigingen terug te draaien die zijn uitgevoerd in het postgresql.conf-bestand op het primaire knooppunt:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onEn herstart de databaseservice.
$ service postgresql-11 restartDus nu zou je weer asynchrone replicatie moeten hebben.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Een PostgreSQL synchrone replicatie implementeren met ClusterControl
Met ClusterControl kunt u de implementatie-, configuratie- en bewakingstaken alles-in-één vanuit dezelfde taak uitvoeren en kunt u deze vanuit dezelfde gebruikersinterface beheren.
We gaan ervan uit dat ClusterControl is geïnstalleerd en dat het via SSH toegang heeft tot de databaseknooppunten. Raadpleeg onze officiële documentatie voor meer informatie over het configureren van de ClusterControl-toegang.
Ga naar ClusterControl en gebruik de optie "Deploy" om een nieuw PostgreSQL-cluster te maken.
Als u PostgreSQL selecteert, moet u Gebruiker, Sleutel of Wachtwoord opgeven en een poort om via SSH verbinding te maken met onze servers. Je hebt ook een naam nodig voor je nieuwe cluster en als je wilt dat ClusterControl de bijbehorende software en configuraties voor je installeert.
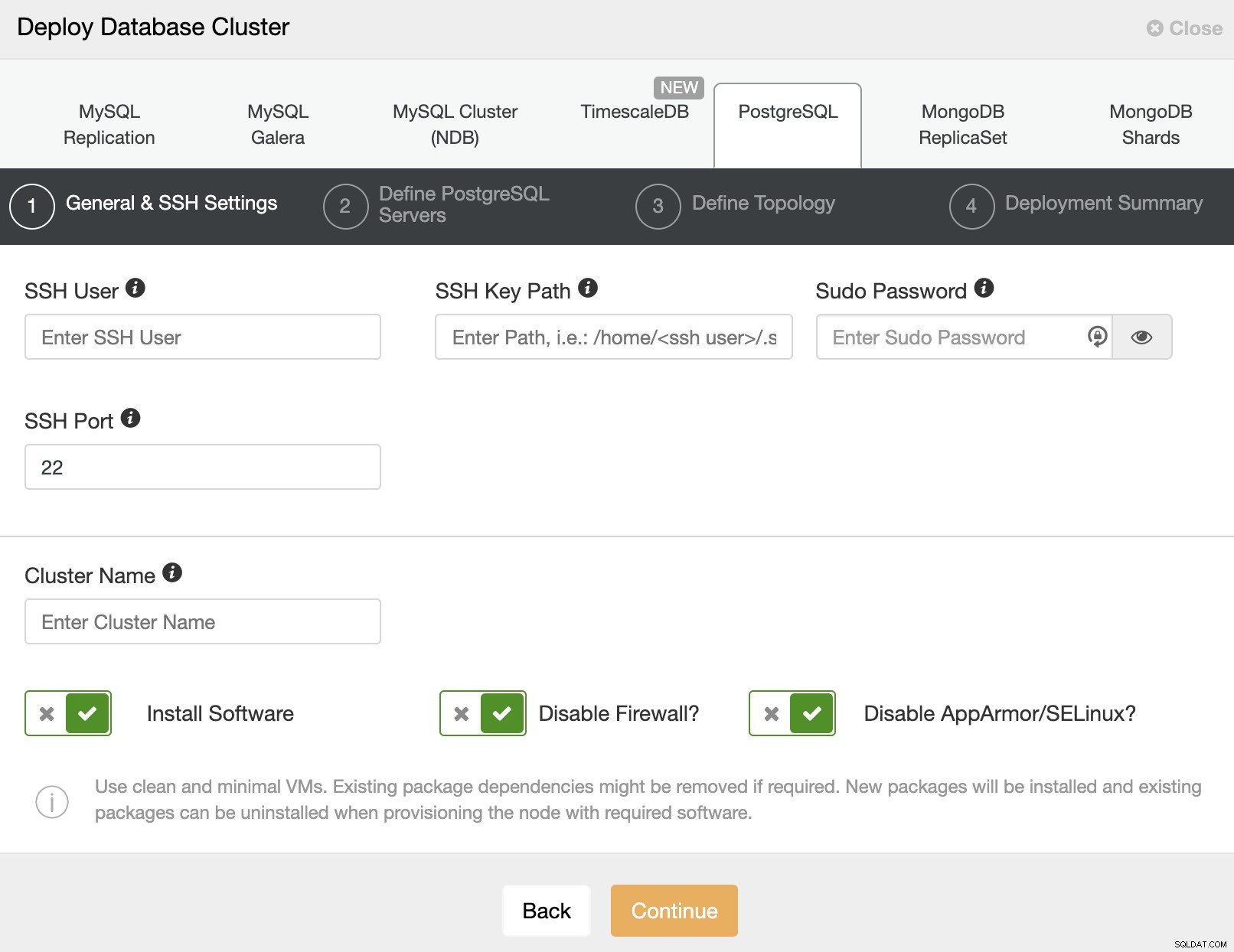
Na het instellen van de SSH-toegangsinformatie, moet u de gegevens invoeren om toegang te krijgen uw databank. Je kunt ook aangeven welke repository je wilt gebruiken.
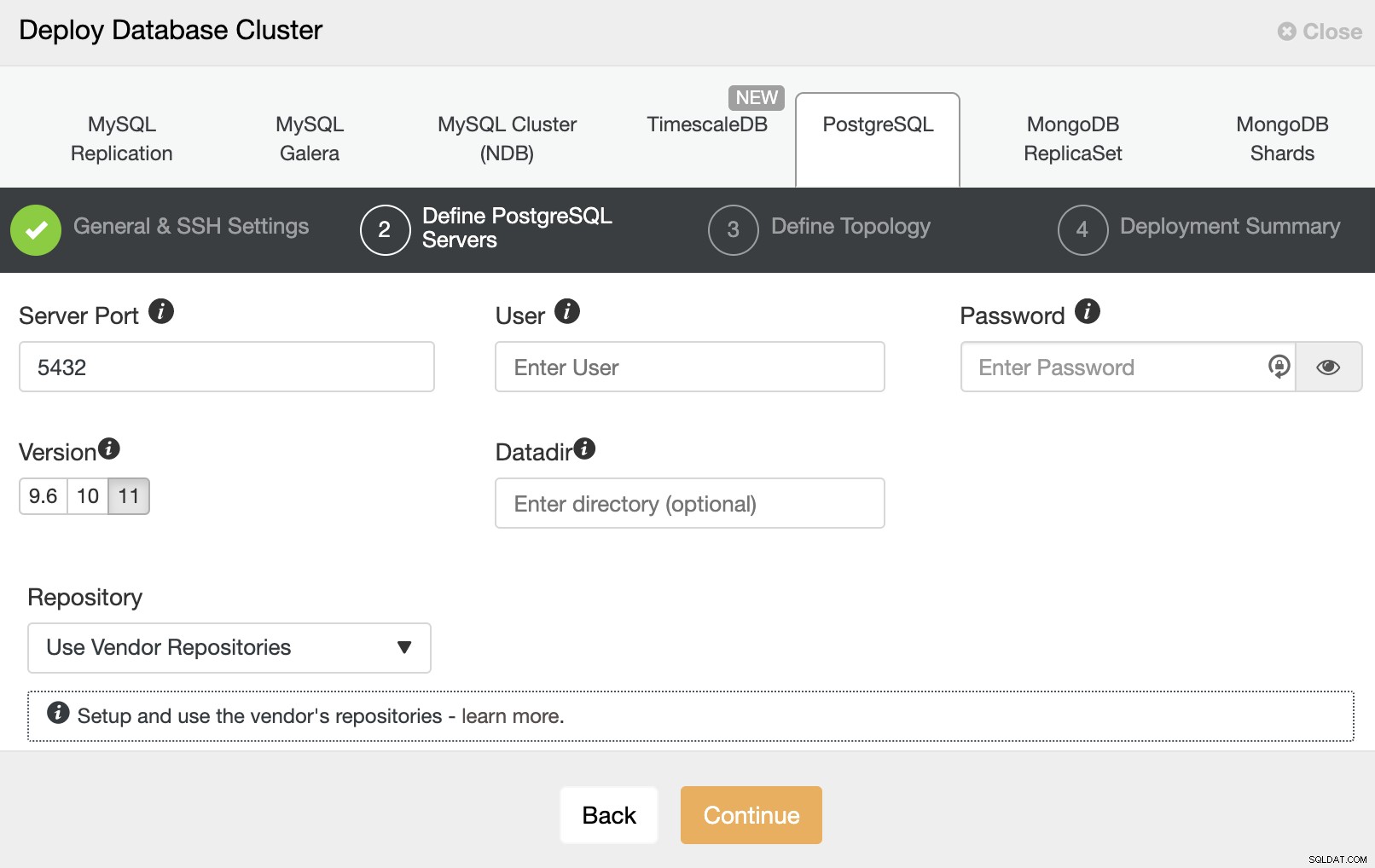
In de volgende stap moet u uw servers toevoegen aan het cluster dat je gaat creëren. Bij het toevoegen van uw servers kunt u IP of hostnaam invoeren.
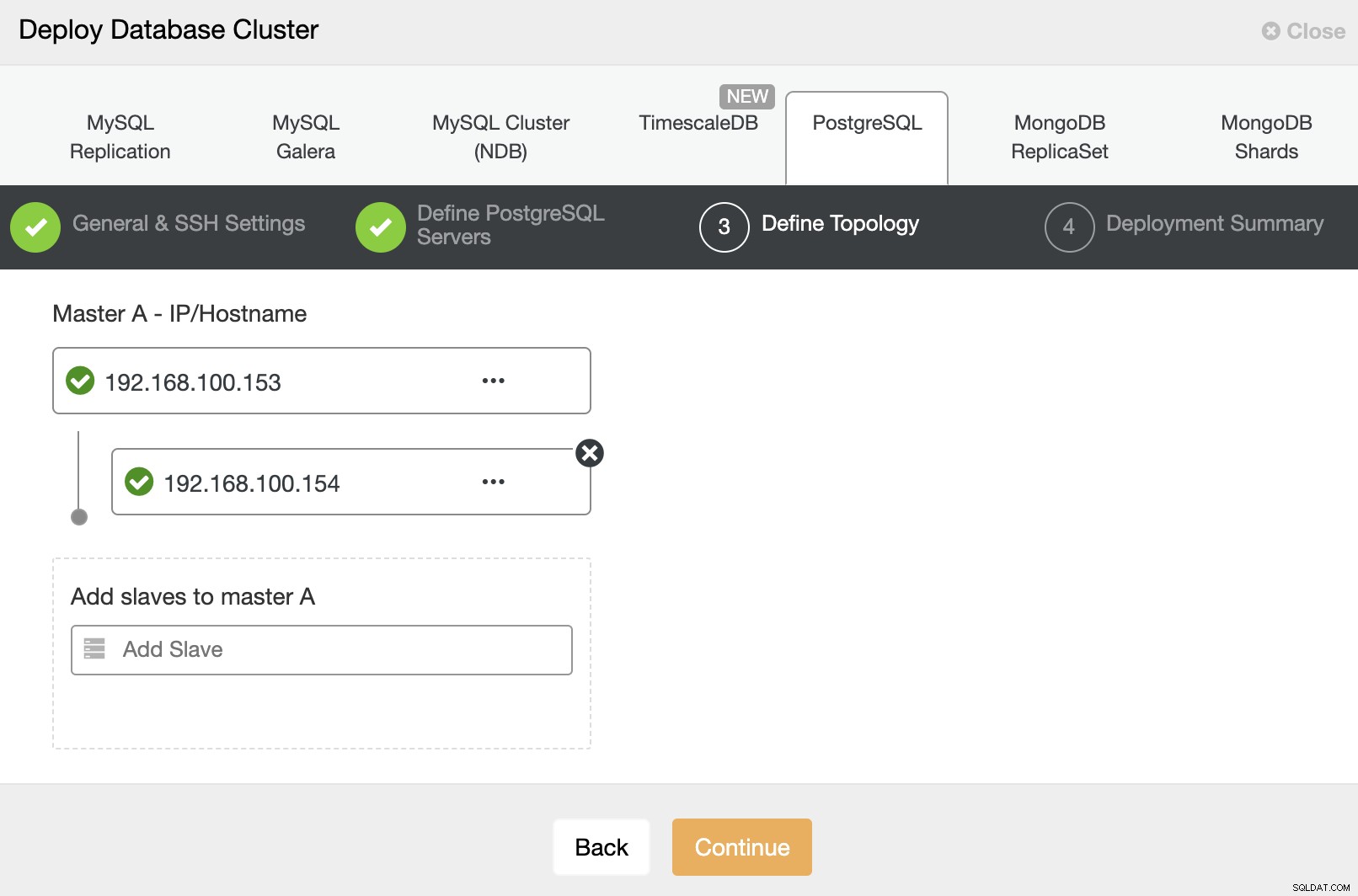
En tot slot, in de laatste stap, kunt u de replicatiemethode kiezen, wat asynchrone of synchrone replicatie kan zijn.
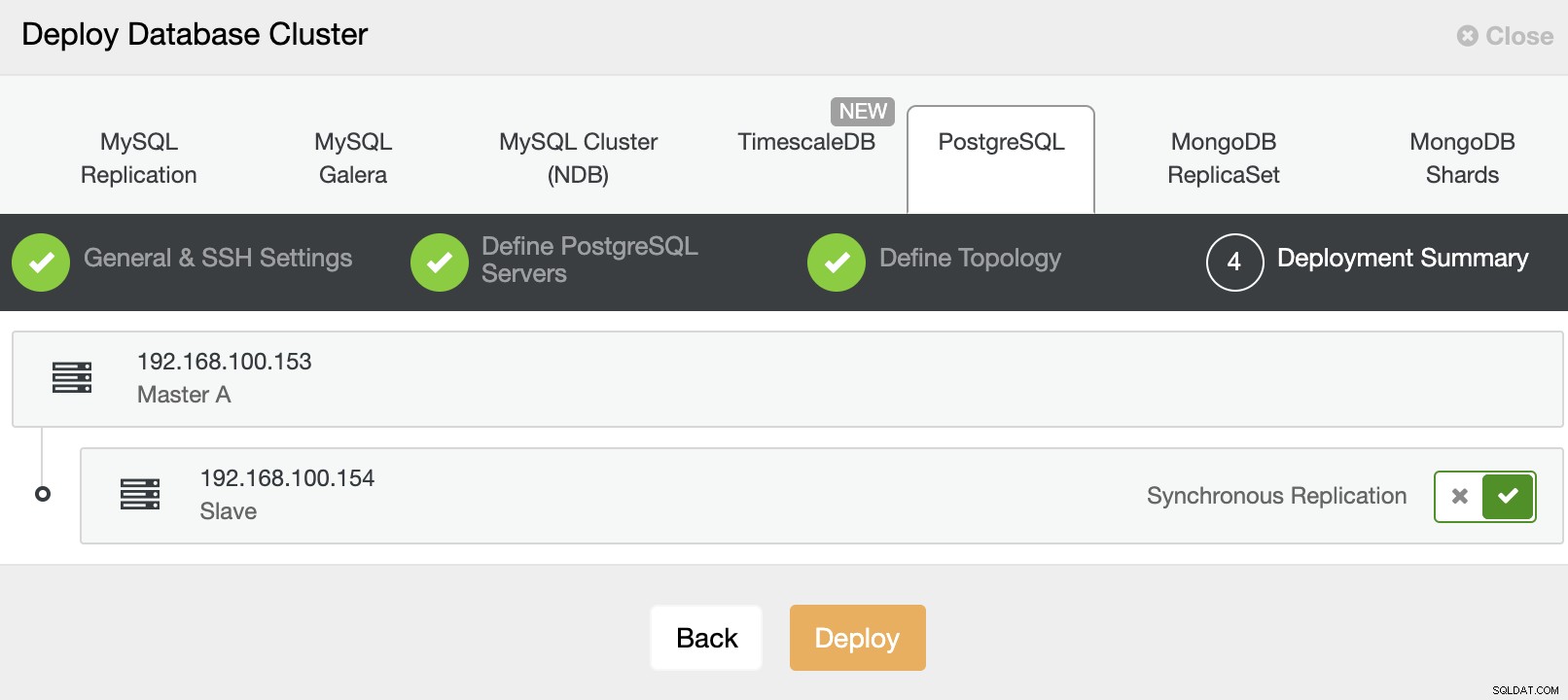
Dat is het. U kunt de taakstatus volgen in het gedeelte ClusterControl-activiteit.
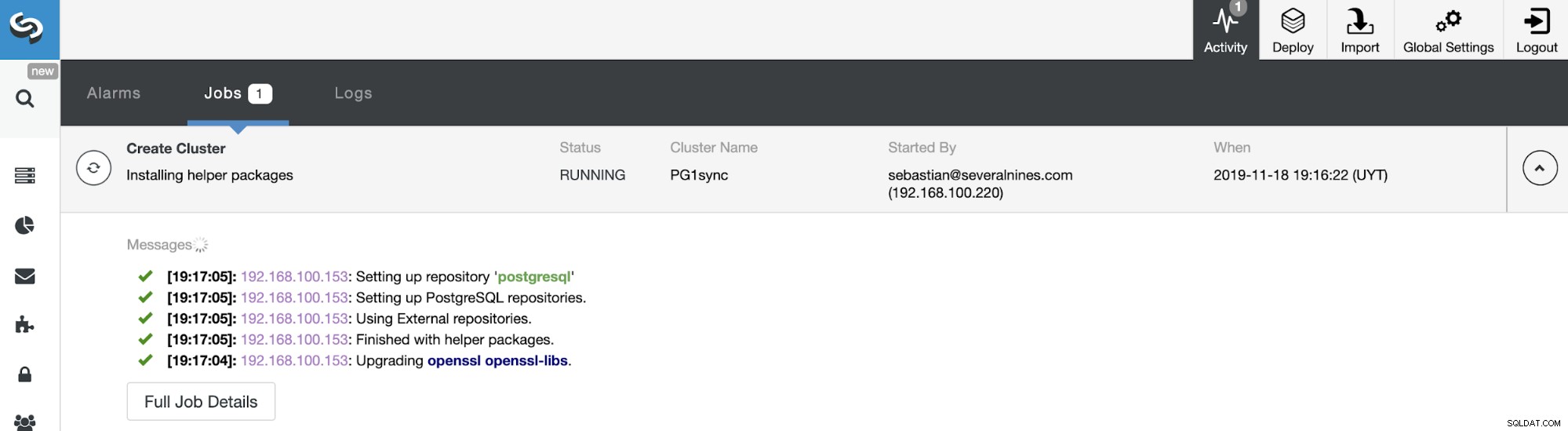
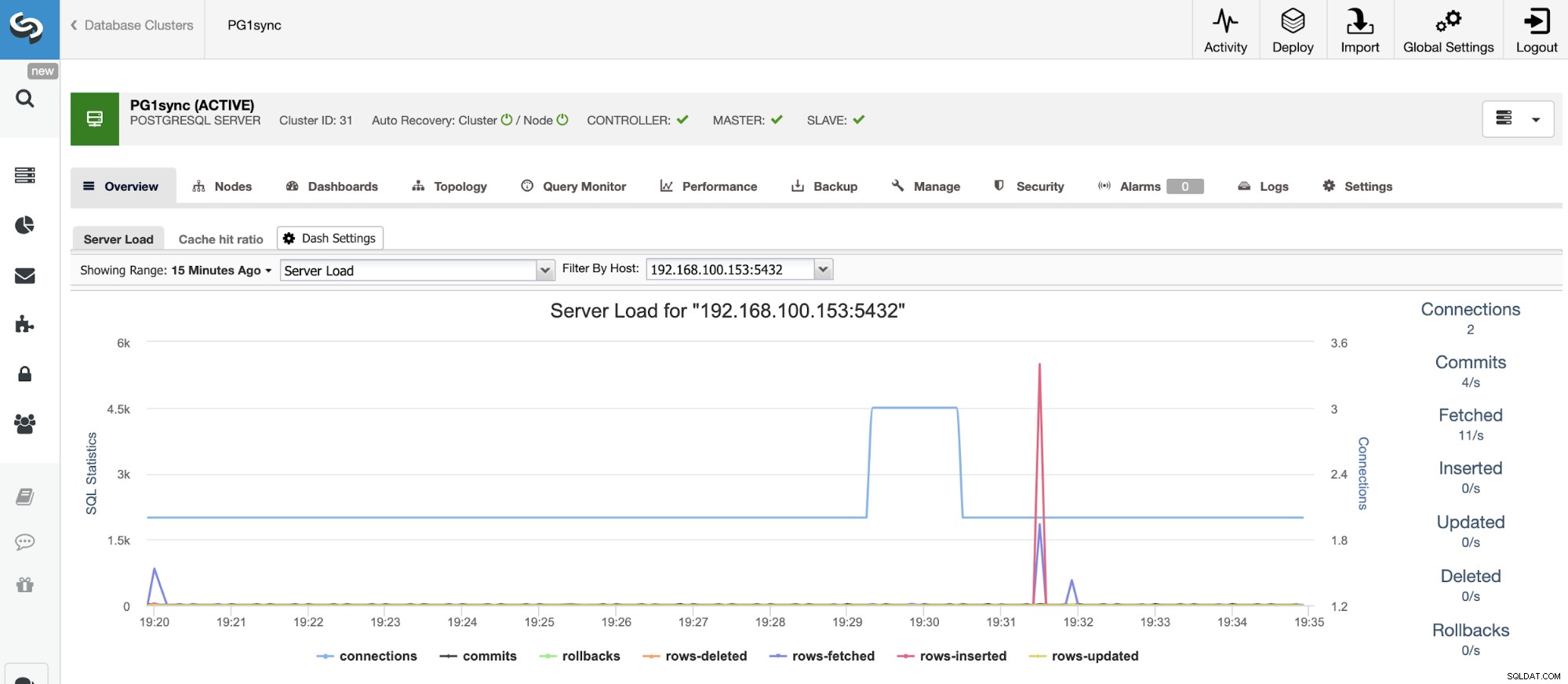
En wanneer deze taak is voltooid, hebt u uw synchrone PostgreSQL-cluster geïnstalleerd, geconfigureerd en gecontroleerd door ClusterControl.
Conclusie
Zoals we aan het begin van deze blog vermeldden, is hoge beschikbaarheid een vereiste voor alle bedrijven, dus u moet de beschikbare opties kennen om dit te bereiken voor elke gebruikte technologie. Voor PostgreSQL kunt u synchrone streaming-replicatie gebruiken als de veiligste manier om het te implementeren, maar deze methode werkt niet voor alle omgevingen en workloads.
Wees voorzichtig met de latentie die wordt gegenereerd door te wachten op de bevestiging van elke transactie die een probleem zou kunnen zijn in plaats van een oplossing met hoge beschikbaarheid.