IRI levert nu ook fuzzy-zoekfuncties, zowel in de gratis database- en flat-file profilingtools, als als beschikbare veldfunctiebibliotheken in IRI CoSort, FieldShield en Voracity om de gegevenskwaliteit, beveiliging en MDM-mogelijkheden te verbeteren. Dit is de eerste in een reeks artikelen over IRI fuzzy-zoekoplossingen die betrekking hebben op hun toepassing op verbetering van de gegevenskwaliteit.
Inleiding
De waarachtigheid of betrouwbaarheid van gegevens van een van de grote 'V'-woorden (samen met volume, variëteit, snelheid en waarde) waar IRI et al over praten in de context van gegevens- en bedrijfsinformatiebeheer. Over het algemeen definieert IRI twijfelachtige gegevens als een of meer van deze kenmerken:
- Lage kwaliteit, omdat het inconsistent, onnauwkeurig of onvolledig is
- Ambigu (denk aan MDM), onnauwkeurig (ongestructureerd) of bedrieglijk (sociale media)
- Bevooroordeeld (enquêtevraag), luidruchtig (overbodig of vervuild) of abnormaal (uitbijters)
- Ongeldig om een andere reden (zijn de gegevens correct en nauwkeurig voor het beoogde gebruik?)
- Onveilig – bevat het PII of geheimen, en is dat goed gemaskeerd, omkeerbaar, enz.?
Dit artikel richt zich alleen op nieuwe fuzzy-zoekoplossingen voor het eerste probleem, gegevenskwaliteit. Andere artikelen in deze blog bespreken hoe IRI-software de andere vier waarheidsproblemen aanpakt; vraag om hulp om ze te vinden als je dat niet kunt.
Over vaag zoeken
Met fuzzy-zoekopdrachten worden woorden of woordgroepen (waarden) gevonden die lijken op, maar niet noodzakelijk identiek zijn aan andere woorden of woordgroepen (waarden). Dit type zoekopdracht heeft veel toepassingen, zoals het vinden van volgordefouten, spelfouten, getransponeerde tekens en andere die we later zullen bespreken.
Door vaag te zoeken naar woorden of woordgroepen bij benadering, kunnen gegevens worden gevonden die mogelijk een duplicaat zijn van eerder opgeslagen gegevens. Gebruikersinvoer of automatische correctie kan de gegevens echter op de een of andere manier hebben gewijzigd om de records onafhankelijk te laten lijken.
De rest van het artikel behandelt vier fuzzy-zoekfuncties die IRI nu ondersteunt, hoe u ze kunt gebruiken om uw gegevens te doorzoeken en die records terug te geven die de zoekwaarde benaderen.
1. Levenshtein
Het Levenshtein-algoritme werkt door twee woorden of woordgroepen te nemen en te tellen hoeveel bewerkingsstappen nodig zijn om het ene woord of de andere woordgroep om te zetten in een andere. Hoe minder stappen het duurt, hoe groter de kans dat het woord of de woordgroep overeenkomt. De stappen die de Levenshtein-functie kan nemen zijn:
- Invoeging van een teken in het woord of de woordgroep
- Verwijderen van een teken uit het woord of de woordgroep
- Vervanging van een teken in een woord of zin door een andere
Het volgende is een CoSort SortCL-programma (jobscript) dat laat zien hoe u de Levenshtein fuzzy-zoekfunctie gebruikt:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Er zijn twee delen die moeten worden gebruikt om de gewenste uitvoer te produceren.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Deze regel roept de functie fs_levenshtein aan en slaat het resultaat op in het veld FS_RESULT. De functie heeft twee invoerparameters:
- Het veld om de fuzzy search op uit te voeren (NAME in ons voorbeeld)
- De tekenreeks waarmee het invoerveld wordt vergeleken ('Barney Oakley' in ons voorbeeld).
/INCLUDE WHERE FS_RESULT GT 50
Deze regel vergelijkt het veld FS_RESULT en controleert of het groter is dan 50, waarna alleen records met een FS_RESULT van meer dan 50 worden uitgevoerd. Het volgende toont de uitvoer van ons voorbeeld.

Zoals de uitvoer laat zien, is dit type zoekopdracht nuttig voor het vinden van:
- Aaneengeschakelde namen
- Ruis
- Spelfouten
- Getransponeerde tekens
- Transcriptiefouten
- Typfouten
De Levenshtein-functie is dus ook handig voor het identificeren van veelvoorkomende fouten bij het invoeren van gegevens. Het duurt echter het langst om van de vier algoritmen uit te voeren, omdat elk teken in de ene tekenreeks wordt vergeleken met elk teken in de andere.
De dobbelsteencoëfficiënt, of dobbelsteenalgoritme, verdeelt woorden of zinsdelen in tekenparen, vergelijkt die paren en telt de overeenkomsten. Hoe meer overeenkomsten de woorden hebben, hoe groter de kans dat het woord zelf een overeenkomst is.
Het volgende SortCL-script demonstreert de fuzzy-zoekfunctie voor dobbelstenen.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Er zijn twee delen die moeten worden gebruikt om ons de gewenste output te geven.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Deze regel roept de functie fs_dice aan, en slaat het resultaat op in het veld FS_RESULT. De functie heeft twee invoerparameters:
- Het veld om de fuzzy search op uit te voeren (NAME in ons voorbeeld).
- De tekenreeks waarmee het invoerveld wordt vergeleken ('Robert Thomas Smith' in ons voorbeeld).
/INCLUDE WHERE FS_RESULT GT 50
Deze regel vergelijkt het veld FS_RESULT en controleert of het groter is dan 50, waarna alleen records met een FS_RESULT van meer dan 50 worden uitgevoerd. Het volgende toont de uitvoer van ons voorbeeld.
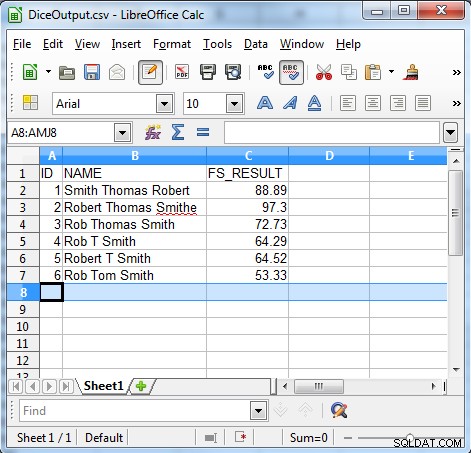
Zoals de uitvoer laat zien, is het algoritme voor de dobbelsteencoëfficiënt handig voor het vinden van inconsistente gegevens, zoals:
- Opeenvolgingsfouten
- Onvrijwillige correcties
- Bijnamen
- Initialen en bijnamen
- Onvoorspelbaar gebruik van initialen
- Lokalisatie
Het dobbelalgoritme is sneller dan de Levenshtein, maar kan minder nauwkeurig worden als er veel eenvoudige fouten zijn, zoals typefouten.
3. Metafoon en 4. Soundex
de Metaphone- en Soundex-algoritmen vergelijken woorden of woordgroepen op basis van hun fonetische geluiden. Soundex doet dit door het woord of de zin te lezen en naar individuele karakters te kijken, terwijl Metaphone zowel naar individuele karakters als naar karaktergroepen kijkt. Beiden geven vervolgens codes op basis van de spelling en uitspraak van het woord.
Het volgende SortCL-script demonstreert de zoekfuncties van Soundex en Metasphone:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
In elk geval zijn er drie delen die moeten worden gebruikt om ons de gewenste output te geven.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
De regel roept de functie aan en slaat het resultaat op in het veld RESULT. De functies hebben beide twee invoerparameters:
- Het veld om de fuzzy search op uit te voeren (NAME in ons voorbeeld)
- De xtring waarmee het invoerveld wordt vergeleken (“John” in ons voorbeeld)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Deze regel vergelijkt de velden SE_RESULT en MP_RESULT en controleert en retourneert de rij als een van beide groter is dan 0.
Soundex retourneert ofwel 100 voor een match, of 0 als het geen match is. Metaphone heeft meer specifieke resultaten en retourneert 100 voor een sterke match, 66 voor een normale match en 33 voor een kleine match.
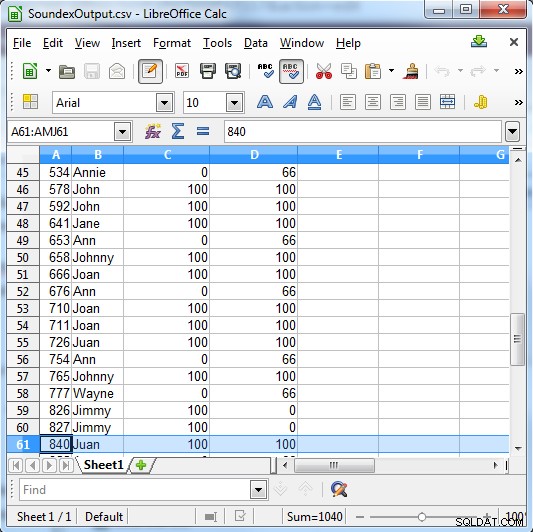
Kolom C toont de Soundex-resultaten. Column D toont de Metaphone-resultaten
Zoals de uitvoer laat zien, is dit type zoekopdracht nuttig voor het vinden van:
- Fonetische fouten
Geef feedback over dit artikel hieronder. Neem contact op met uw IRI-vertegenwoordiger als u deze functies wilt gebruiken. Zie ons volgende artikel over het gebruik van deze algoritmen in de wizard IRI Workbench-gegevensconsolidatie (kwaliteit).