[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]
De MERGE statement (geïntroduceerd in SQL Server 2008) stelt ons in staat om een combinatie van INSERT . uit te voeren , UPDATE , en DELETE bewerkingen met een enkele verklaring. De Halloween-beveiligingsproblemen voor MERGE zijn meestal een combinatie van de vereisten van de individuele bewerkingen, maar er zijn enkele belangrijke verschillen en een aantal interessante optimalisaties die alleen van toepassing zijn op MERGE .
Het Halloween-probleem vermijden met MERGE
We beginnen opnieuw met het voorbeeld van Demo en Staging uit deel twee:
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
CREATE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey);
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
);
Zoals u zich wellicht herinnert, werd dit voorbeeld gebruikt om aan te tonen dat een INSERT vereist Halloween-bescherming wanneer er ook naar de invoegdoeltabel wordt verwezen in de SELECT deel van de zoekopdracht (de EXISTS clausule in dit geval). Het juiste gedrag voor de INSERT bovenstaande verklaring is om te proberen beide . toe te voegen 1234 waarden, en als gevolg daarvan mislukken met een PRIMARY KEY overtreding. Zonder fasescheiding, de INSERT zou ten onrechte één waarde toevoegen, zonder dat er een fout werd gegenereerd.
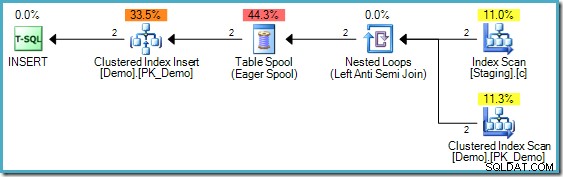
Het INSERT-uitvoeringsplan
De bovenstaande code heeft één verschil met die in deel twee; een niet-geclusterde index op de Staging-tabel is toegevoegd. De INSERT uitvoeringsplan nog vereist echter Halloween-bescherming:
Het MERGE-uitvoeringsplan
Probeer nu dezelfde logische invoeging uitgedrukt met MERGE syntaxis:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED BY TARGET THEN
INSERT (SomeKey)
VALUES (s.SomeKey);
Als u niet bekend bent met de syntaxis, is de logica die er is om rijen in de Staging- en Demo-tabellen te vergelijken op de SomeKey-waarde, en als er geen overeenkomende rij wordt gevonden in de doeltabel (Demo), voegen we een nieuwe rij in. Dit heeft precies dezelfde semantiek als de vorige INSERT...WHERE NOT EXISTS code natuurlijk. Het uitvoeringsplan is echter heel anders:
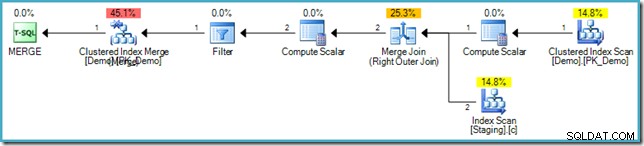
Let op het ontbreken van een Eager Table Spool in dit plan. Desondanks geeft de query nog steeds de juiste foutmelding. Het lijkt erop dat SQL Server een manier heeft gevonden om de MERGE . uit te voeren plan iteratief met inachtneming van de logische fasescheiding vereist door de SQL-standaard.
De gatenvullende optimalisatie
In de juiste omstandigheden kan de SQL Server-optimizer herkennen dat de MERGE statement is vullend , wat gewoon een andere manier is om te zeggen dat de instructie alleen rijen toevoegt waar er een bestaand gat is in de sleutel van de doeltabel.
Om deze optimalisatie toe te passen, worden de waarden gebruikt in de WHEN NOT MATCHED BY TARGET clausule moet precies overeenkomen met de ON onderdeel van de USING clausule. De doeltabel moet ook een unieke sleutel hebben (een vereiste waaraan wordt voldaan door de PRIMARY KEY in het onderhavige geval). Waar aan deze vereisten wordt voldaan, wordt de MERGE verklaring vereist geen bescherming tegen het Halloween-probleem.
Natuurlijk, de MERGE statement is logisch niet meer of minder gatvullend dan de originele INSERT...WHERE NOT EXISTS syntaxis. Het verschil is dat de optimizer volledige controle heeft over het implementeren van de MERGE statement, terwijl de INSERT syntaxis zou vereisen dat het redeneert over de bredere semantiek van de query. Een mens kan gemakkelijk zien dat de INSERT is ook gatenvullend, maar de optimizer denkt niet op dezelfde manier over dingen als wij.
Ter illustratie van de exacte overeenkomst vereiste die ik noemde, overweeg dan de volgende query-syntaxis, die niet . doet profiteren van de gatvullende optimalisatie. Het resultaat is volledige Halloween-bescherming door een Eager Table Spool:
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey * 1);

Het enige verschil is de vermenigvuldiging met één in de VALUES clausule - iets dat de logica van de zoekopdracht niet verandert, maar dat voldoende is om te voorkomen dat de gatenvullende optimalisatie wordt toegepast.
Gaten vullen met geneste lussen
In het vorige voorbeeld koos de optimizer ervoor om de tabellen samen te voegen met behulp van een Merge-join. De gatenvullende optimalisatie kan ook worden toegepast waar een Nested Loops-join is gekozen, maar dit vereist een extra uniciteitsgarantie op de brontabel en een indexzoekopdracht aan de binnenkant van de join. Om dit in actie te zien, kunnen we de bestaande staginggegevens wissen, uniciteit toevoegen aan de niet-geclusterde index en de MERGE proberen nogmaals:
-- Remove existing duplicate rows
TRUNCATE TABLE dbo.Staging;
-- Convert index to unique
CREATE UNIQUE NONCLUSTERED INDEX c
ON dbo.Staging (SomeKey)
WITH (DROP_EXISTING = ON);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(5678);
-- Hole-filling merge
MERGE dbo.Demo AS d
USING dbo.Staging AS s ON
s.SomeKey = d.SomeKey
WHEN NOT MATCHED THEN
INSERT (SomeKey)
VALUES (s.SomeKey); Het resulterende uitvoeringsplan gebruikt opnieuw de gatenvullende optimalisatie om Halloween-bescherming te vermijden, met behulp van een geneste lus-join en een innerlijke zoekactie in de doeltabel:
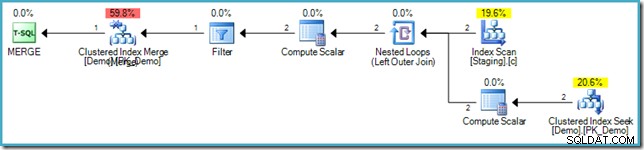
Onnodige indexdoorgangen vermijden
Waar de gatenvullende optimalisatie van toepassing is, kan de motor ook een verdere optimalisatie toepassen. Het kan de huidige indexpositie onthouden tijdens lezing de doeltabel (één rij tegelijk verwerken, onthoud) en hergebruik die informatie bij het uitvoeren van de invoeging, in plaats van door de b-boom te zoeken om de invoeglocatie te vinden. De redenering is dat de huidige leespositie zeer waarschijnlijk op dezelfde pagina staat waar de nieuwe rij moet worden ingevoegd. Controleren of de rij inderdaad op deze pagina thuishoort, gaat erg snel, omdat het alleen de laagste en hoogste toetsen betreft die daar momenteel zijn opgeslagen.
De combinatie van het elimineren van de Eager Table Spool en het opslaan van een indexnavigatie per rij kan een aanzienlijk voordeel opleveren bij OLTP-workloads, op voorwaarde dat het uitvoeringsplan wordt opgehaald uit de cache. De compilatiekosten voor MERGE instructies is eerder hoger dan voor INSERT , UPDATE en DELETE , dus hergebruik van plannen is een belangrijke overweging. Het is ook handig om ervoor te zorgen dat pagina's voldoende vrije ruimte hebben voor nieuwe rijen, om paginasplitsingen te voorkomen. Dit wordt meestal bereikt door normaal indexonderhoud en de toewijzing van een geschikte FILLFACTOR .
Ik noem OLTP-workloads, die doorgaans een groot aantal relatief kleine wijzigingen bevatten, omdat de MERGE optimalisaties zijn mogelijk geen goede keuze wanneer een groot aantal rijen per instructie wordt verwerkt. Andere optimalisaties zoals minimaal gelogde INSERTs kan momenteel niet worden gecombineerd met het vullen van gaten. Zoals altijd moeten de prestatiekenmerken worden gebenchmarkt om ervoor te zorgen dat de verwachte voordelen worden gerealiseerd.
De gatenvullende optimalisatie voor MERGE invoegingen kunnen worden gecombineerd met updates en verwijderingen met behulp van extra MERGE clausules; elke gegevensveranderende operatie wordt afzonderlijk beoordeeld voor het Halloween-probleem.
De deelname vermijden
De uiteindelijke optimalisatie die we zullen bekijken, kan worden toegepast waar de MERGE statement bevat update- en delete-bewerkingen, evenals een gatvullende insert, en de doeltabel heeft een unieke geclusterde index. Het volgende voorbeeld toont een algemene MERGE patroon waarbij niet-overeenkomende rijen worden ingevoegd en overeenkomende rijen worden bijgewerkt of verwijderd, afhankelijk van een aanvullende voorwaarde:
CREATE TABLE #T
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_T
PRIMARY KEY (col1)
);
CREATE TABLE #S
(
col1 integer NOT NULL,
col2 integer NOT NULL,
CONSTRAINT PK_S
PRIMARY KEY (col1)
);
INSERT #T
(col1, col2)
VALUES
(1, 50),
(3, 90);
INSERT #S
(col1, col2)
VALUES
(1, 40),
(2, 80),
(3, 90);
De MERGE verklaring die nodig is om alle vereiste wijzigingen aan te brengen, is opmerkelijk compact:
MERGE #T AS t USING #S AS s ON t.col1 = s.col1 WHEN NOT MATCHED THEN INSERT VALUES (s.col1, s.col2) WHEN MATCHED AND t.col2 - s.col2 = 0 THEN DELETE WHEN MATCHED THEN UPDATE SET t.col2 -= s.col2;
Het uitvoeringsplan is nogal verrassend:

Geen Halloween-bescherming, geen verbinding tussen de bron- en doeltabellen, en het komt niet vaak voor dat u een operator voor geclusterde index invoegen ziet, gevolgd door een geclusterde index samenvoegen naar dezelfde tabel. Dit is een andere optimalisatie gericht op OLTP-workloads met veel hergebruik van plannen en geschikte indexering.
Het idee is om een rij uit de brontabel te lezen en deze onmiddellijk in het doel in te voegen. Als een toetsovertreding het gevolg is, wordt de fout onderdrukt, de operator Invoegen voert de conflicterende rij uit die hij heeft gevonden en die rij wordt vervolgens verwerkt voor een update- of verwijderingsbewerking met behulp van de operator Plan samenvoegen zoals normaal.
Als de oorspronkelijke invoeging slaagt (zonder een sleutelovertreding), gaat de verwerking verder met de volgende rij van de bron (de operator Samenvoegen verwerkt alleen updates en verwijderingen). Deze optimalisatie komt voornamelijk ten goede aan MERGE query's waarbij de meeste bronrijen resulteren in een insert. Nogmaals, zorgvuldige benchmarking is vereist om ervoor te zorgen dat de prestaties beter zijn dan het gebruik van afzonderlijke verklaringen.
Samenvatting
De MERGE statement biedt verschillende unieke optimalisatiemogelijkheden. In de juiste omstandigheden kan het de noodzaak vermijden om expliciete Halloween-bescherming toe te voegen in vergelijking met een gelijkwaardige INSERT bewerking, of misschien zelfs een combinatie van INSERT , UPDATE , en DELETE verklaringen. Extra MERGE -specifieke optimalisaties kunnen de index b-tree traversal vermijden die gewoonlijk nodig is om de invoegpositie voor een nieuwe rij te lokaliseren, en kunnen ook de noodzaak vermijden om de bron- en doeltabellen volledig samen te voegen.
In het laatste deel van deze serie zullen we bekijken hoe de query-optimizer redeneert over de noodzaak van Halloween-bescherming, en wat meer trucs identificeren die het kan gebruiken om te voorkomen dat Eager Table Spools moet worden toegevoegd aan uitvoeringsplannen die gegevens wijzigen.
[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]