[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]
Het Halloween-probleem kan een aantal belangrijke effecten hebben op uitvoeringsplannen. In dit laatste deel van de serie kijken we naar de trucs die de optimizer kan gebruiken om het Halloween-probleem te vermijden bij het opstellen van plannen voor zoekopdrachten die gegevens toevoegen, wijzigen of verwijderen.
Achtergrond
In de loop der jaren zijn er een aantal benaderingen geprobeerd om het Halloween-probleem te vermijden. Een vroege techniek was om eenvoudigweg geen uitvoeringsplannen te maken waarbij werd gelezen van en geschreven naar sleutels van dezelfde index. Dit was niet erg succesvol vanuit prestatieoogpunt, niet in het minst omdat het vaak betekende dat de basistabel moest worden gescand in plaats van een selectieve niet-geclusterde index te gebruiken om de rijen te lokaliseren die moesten worden gewijzigd.
Een tweede benadering was om de lees- en schrijffase van een update-query volledig te scheiden, door eerst alle rijen te lokaliseren die in aanmerking komen voor de wijziging, ze ergens op te slaan en pas daarna te beginnen met het uitvoeren van de wijzigingen. In SQL Server is deze volledige fasescheiding wordt bereikt door de inmiddels bekende Eager Table Spool aan de invoerzijde van de update-operator te plaatsen:
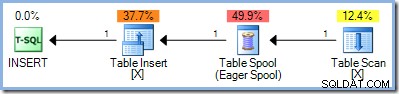
De spoel leest alle rijen van zijn invoer en slaat ze op in een verborgen tempdb werktafel. De pagina's van deze werktabel kunnen in het geheugen blijven, of ze hebben fysieke schijfruimte nodig als de reeks rijen groot is, of als de server onder geheugendruk staat.
Volledige fasescheiding kan niet ideaal zijn, omdat we over het algemeen zoveel mogelijk van het plan als een pijplijn willen uitvoeren, waarbij elke rij volledig is verwerkt voordat we naar de volgende gaan. Pipelining heeft veel voordelen, waaronder het vermijden van tijdelijke opslag en het slechts één keer aanraken van elke rij.
De SQL Server Optimizer
SQL Server gaat veel verder dan de twee technieken die tot nu toe zijn beschreven, hoewel het natuurlijk beide als opties bevat. De query-optimizer van SQL Server detecteert query's waarvoor Halloween-bescherming is vereist, bepaalt hoeveel bescherming is vereist en maakt gebruik van op kosten gebaseerde analyse om de goedkoopste methode te vinden om die bescherming te bieden.
De gemakkelijkste manier om dit aspect van het Halloween-probleem te begrijpen, is door naar enkele voorbeelden te kijken. In de volgende secties is het de taak om een reeks getallen aan een bestaande tabel toe te voegen, maar alleen getallen die nog niet bestaan:
CREATE TABLE dbo.Test
(
pk integer NOT NULL,
CONSTRAINT PK_Test
PRIMARY KEY CLUSTERED (pk)
); 5 rijen
Het eerste voorbeeld verwerkt een reeks getallen van 1 tot en met 5:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 5
AND NOT EXISTS
(
SELECT NULL
FROM dbo.Test AS t
WHERE t.pk = Num.n
); Aangezien deze query leest van en schrijft naar de sleutels van dezelfde index in de testtabel, vereist het uitvoeringsplan Halloween Protection. In dit geval gebruikt de optimizer volledige fasescheiding met behulp van een Eager Table Spool:
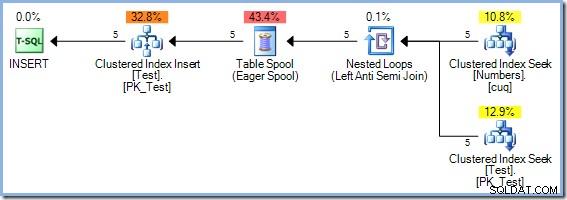
50 rijen
Met nu vijf rijen in de testtabel, voeren we dezelfde query opnieuw uit, waarbij de WHERE . wordt gewijzigd clausule om de getallen te verwerken van 1 tot en met 50 :
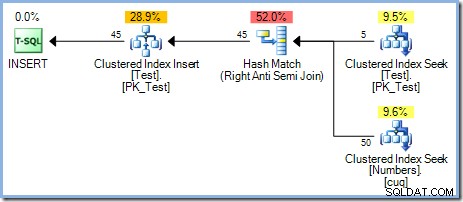
Dit plan biedt de juiste bescherming tegen het Halloween-probleem, maar heeft geen Eager Table Spool. De optimizer herkent dat de Hash Match join-operator zijn build-invoer blokkeert; alle rijen worden ingelezen in een hashtabel voordat de operator het matchproces start met behulp van rijen van de probe-invoer. Als gevolg hiervan biedt dit plan natuurlijk fasescheiding (alleen voor de testtabel) zonder dat een spoel nodig is.
De optimizer koos om kostengerelateerde redenen een Hash Match-deelnameplan boven de Nested Loops-join die in het 5-rijenplan wordt gezien. Het Hash Match-abonnement met 50 rijen kost in totaal 0.0347345 eenheden. We kunnen het eerder gebruikte Nested Loops-plan forceren met een hint om te zien waarom de optimizer geen geneste loops heeft gekozen:
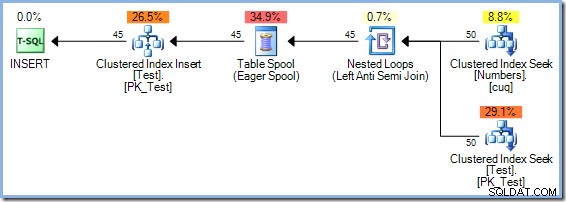
Dit abonnement kost naar schatting 0.0379063 eenheden inclusief de spoel, iets meer dan het Hash Match-plan.
500 rijen
Met 50 rijen nu in de testtabel, vergroten we het bereik van getallen verder naar 500 :
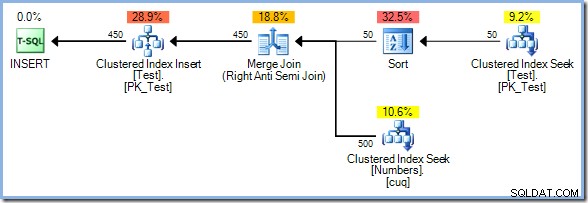
Deze keer kiest de optimizer een Merge Join, en opnieuw is er geen Eager Table Spool. De sorteeroperator zorgt in dit plan voor de nodige fasescheiding. Het verbruikt zijn invoer volledig voordat de eerste rij wordt geretourneerd (de sortering kan niet weten welke rij eerst sorteert totdat alle rijen zijn gezien). De optimizer heeft besloten dat het sorteren van 50 rijen uit de testtabel zouden goedkoper zijn dan het gretig spoolen van 450 rijen net voor de update-operator.
Het plan Sorteren plus samenvoegen heeft een geschatte kostprijs van 0,0362708 eenheden. De alternatieven voor het Hash Match- en Nested Loops-plan komen uit op 0.0385677 eenheden en 0.112433 eenheden respectievelijk.
Iets vreemds aan de Sort
Als je deze voorbeelden voor jezelf hebt uitgevoerd, is je misschien iets vreemds opgevallen aan dat laatste voorbeeld, vooral als je de tooltips van Plan Explorer voor de Testtabel Seek and the Sort hebt bekeken:
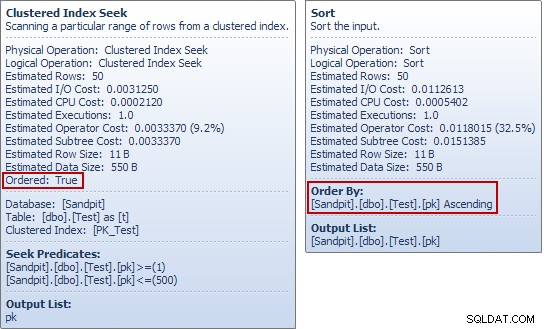
The Seek produceert een besteld stream van pk waarden, dus wat heeft het voor zin om direct daarna op dezelfde kolom te sorteren? Om die (zeer redelijke) vraag te beantwoorden, beginnen we met alleen de SELECT gedeelte van de INSERT vraag:
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
ORDER BY
Num.n;
Deze query levert het onderstaande uitvoeringsplan op (met of zonder de ORDER BY Ik heb toegevoegd om bepaalde technische bezwaren die je zou kunnen hebben aan te pakken):
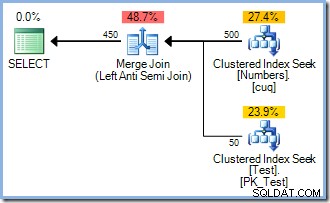
Let op het ontbreken van een sorteeroperator. Dus waarom heeft de INSERT plan omvatten een Sorteren? Gewoon om het Halloween-probleem te vermijden. De optimizer was van mening dat het uitvoeren van een redundante sortering (met ingebouwde fasescheiding) was de goedkoopste manier om de query uit te voeren en correcte resultaten te garanderen. Slim.
Halloween beschermingsniveaus en eigenschappen
De SQL Server-optimizer heeft specifieke functies die het mogelijk maken om te redeneren over het niveau van Halloween Protection (HP) dat op elk punt in het queryplan vereist is, en het gedetailleerde effect dat elke operator heeft. Deze extra functies zijn opgenomen in hetzelfde eigenschappenraamwerk dat de optimizer gebruikt om honderden andere belangrijke stukjes informatie bij te houden tijdens zijn zoekactiviteiten.
Elke operator heeft een vereiste HP eigendom en een geleverd HP eigendom. De vereiste eigenschap geeft het niveau van HP aan dat op dat punt in de boomstructuur nodig is voor correcte resultaten. De geleverde eigenschap weerspiegelt de HP geleverd door de huidige operator en de cumulatieve HP-effecten geleverd door de substructuur.
De optimizer bevat logica om te bepalen hoe elke fysieke operator (bijvoorbeeld een Compute Scalar) het HP-niveau beïnvloedt. Door een breed scala aan planalternatieven te onderzoeken en plannen te verwerpen waarbij de geleverde HP minder is dan de vereiste HP bij de update-operator, heeft de optimizer een flexibele manier om correcte, efficiënte plannen te vinden waarvoor niet altijd een Eager Table Spool nodig is.
Wijzigingen plannen voor Halloween-bescherming
We zagen dat de optimizer een redundante sortering voor Halloween-bescherming toevoegt in het vorige Merge Join-voorbeeld. Hoe weten we zeker dat dit efficiënter is dan een simpele Eager Table Spool? En hoe kunnen we weten welke functies van een updateplan er alleen zijn voor Halloween-bescherming?
Beide vragen kunnen beantwoord worden (uiteraard in een testomgeving) met de ongedocumenteerde traceringsvlag 8692 , waardoor de optimizer wordt gedwongen een Eager Table Spool te gebruiken voor Halloween-bescherming. Bedenk dat het plan Samenvoegen met de redundante sortering geschatte kosten had van 0,0362708 magische optimalisatie-eenheden. We kunnen dat vergelijken met het Eager Table Spool-alternatief door de query opnieuw te compileren met traceringsvlag 8692 ingeschakeld:
INSERT dbo.Test (pk)
SELECT Num.n
FROM dbo.Numbers AS Num
WHERE
Num.n BETWEEN 1 AND 500
AND NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t
WHERE t.pk = Num.n
)
OPTION (QUERYTRACEON 8692);
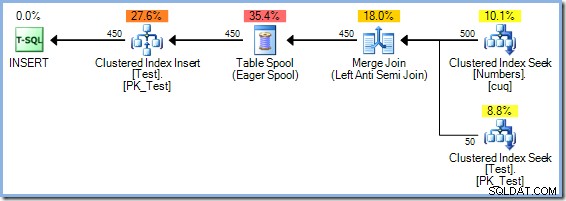
Het Eager Spool-abonnement kost naar schatting 0.0378719 eenheden (van 0,0362708 met de redundante soort). De hier getoonde kostenverschillen zijn niet erg significant vanwege de triviale aard van de taak en de kleine omvang van de rijen. Real-world update-query's met complexe bomen en grotere rijen produceren vaak plannen die veel efficiënter zijn dankzij het vermogen van de SQL Server-optimizer om diep na te denken over Halloween-bescherming.
Andere niet-spool opties
Het optimaal positioneren van een blokkerende operator binnen een plan is niet de enige strategie voor de optimizer om de kosten van het bieden van bescherming tegen het Halloween-probleem te minimaliseren. Het kan ook redeneren over het waardebereik dat wordt verwerkt, zoals het volgende voorbeeld laat zien:
CREATE TABLE #Test
(
pk integer IDENTITY PRIMARY KEY,
some_value integer
);
CREATE INDEX i ON #Test (some_value);
-- Pretend the table has lots of data in it
UPDATE STATISTICS #Test
WITH ROWCOUNT = 123456, PAGECOUNT = 1234;
UPDATE #Test
SET some_value = 10
WHERE some_value = 5; Het uitvoeringsplan laat zien dat Halloween-bescherming niet nodig is, ondanks het feit dat we de sleutels van een gemeenschappelijke index lezen en bijwerken:
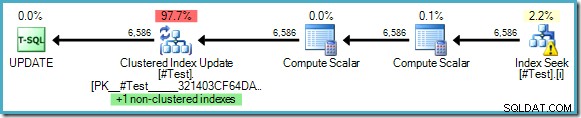
De optimizer kan zien dat het veranderen van 'some_value' van 5 naar 10 er nooit voor kan zorgen dat een bijgewerkte rij een tweede keer wordt gezien door de Index Seek (die alleen zoekt naar rijen waar some_value 5 is). Deze redenering is alleen mogelijk wanneer letterlijke waarden worden gebruikt in de query, of waar de query OPTION (RECOMPILE) specificeert , waardoor de optimizer de waarden van de parameters kan opsnuiven voor een eenmalig uitvoeringsplan.
Zelfs met letterlijke waarden in de query kan de optimizer deze logica niet toepassen als de databaseoptie FORCED PARAMETERIZATION is ON . In dat geval worden de letterlijke waarden in de query vervangen door parameters en kan de optimizer er niet meer zeker van zijn dat Halloween Protection niet vereist is (of niet vereist zal zijn wanneer het plan opnieuw wordt gebruikt met andere parameterwaarden):

Voor het geval je je afvraagt wat er gebeurt als FORCED PARAMETERIZATION is ingeschakeld en de zoekopdracht specificeert OPTION (RECOMPILE) , is het antwoord dat de optimizer een plan opstelt voor de gesnoven waarden, en dus de optimalisatie kan toepassen. Zoals altijd met OPTION (RECOMPILE) , wordt het queryplan met specifieke waarde niet in de cache opgeslagen voor hergebruik.
Boven
Dit laatste voorbeeld laat zien hoe de Top operator kan Halloween-bescherming overbodig maken:
UPDATE TOP (1) t SET some_value += 1 FROM #Test AS t WHERE some_value <= 10;

Er is geen bescherming vereist omdat we slechts één rij bijwerken. De bijgewerkte waarde kan niet worden gevonden door de Index Seek, omdat de verwerkingspijplijn stopt zodra de eerste rij is bijgewerkt. Nogmaals, deze optimalisatie kan alleen worden toegepast als een constante letterlijke waarde wordt gebruikt in de TOP , of als een variabele die de waarde '1' retourneert, wordt gesnoven met OPTION (RECOMPILE) .
Als we de TOP (1) . wijzigen in de zoekopdracht naar een TOP (2) , kiest de optimizer een Clustered Index Scan in plaats van de Index Seek:

We werken de sleutels van de geclusterde index niet bij, dus dit plan vereist geen Halloween Protection. Het gebruik van de niet-geclusterde index forceren met een hint in de TOP (2) query maakt de kosten van de bescherming duidelijk:

De optimizer schatte dat de Clustered Index Scan goedkoper zou zijn dan dit plan (met zijn extra Halloween-bescherming).
Kansen en eindpunten
Er zijn nog een paar andere punten die ik wil maken over Halloween-bescherming die tot nu toe geen natuurlijke plaats in de serie hebben gevonden. De eerste is de kwestie van Halloween-bescherming wanneer een isolatieniveau voor rijversies in gebruik is.
Rijversiebeheer
SQL Server biedt twee isolatieniveaus, READ COMMITTED SNAPSHOT en SNAPSHOT ISOLATION die een versiearchief gebruiken in tempdb om een consistent overzicht van de database op statement- of transactieniveau te bieden. SQL Server zou Halloween-bescherming volledig kunnen vermijden onder deze isolatieniveaus, omdat de versieopslag gegevens kan leveren die niet zijn beïnvloed door eventuele wijzigingen die de momenteel uitgevoerde instructie tot nu toe mogelijk heeft gemaakt. Dit idee is momenteel niet geïmplementeerd in een vrijgegeven versie van SQL Server, hoewel Microsoft een patent heeft ingediend waarin wordt beschreven hoe dit zou werken, dus misschien zal een toekomstige versie deze technologie bevatten.
Heel veel en doorgestuurde records
Als u bekend bent met de interne structuur van heapstructuren, vraagt u zich misschien af of een bepaald Halloween-probleem kan optreden wanneer doorgestuurde records worden gegenereerd in een heaptabel. Als dit nieuw voor u is, wordt een heaprecord doorgestuurd als een bestaande rij zodanig wordt bijgewerkt dat deze niet meer op de oorspronkelijke gegevenspagina past. De engine laat een doorstuurstrookje achter en verplaatst het uitgevouwen record naar een andere pagina.
Er kan een probleem optreden als een plan met een heapscan een record bijwerkt zodat het wordt doorgestuurd. De heapscan kan de rij opnieuw tegenkomen wanneer de scanpositie de pagina met het doorgestuurde record bereikt. In SQL Server wordt dit probleem vermeden omdat de Storage Engine garandeert dat forwarding-pointers altijd onmiddellijk worden gevolgd. Als de scan een record tegenkomt dat is doorgestuurd, wordt dit genegeerd. Met deze beveiliging hoeft de query-optimizer zich geen zorgen te maken over dit scenario.
SCHEMABINDING en T-SQL scalaire functies
Er zijn maar weinig gevallen waarin het gebruik van een scalaire T-SQL-functie een goed idee is, maar als u er een moet gebruiken, moet u zich bewust zijn van een belangrijk effect dat dit kan hebben met betrekking tot Halloween-bescherming. Tenzij een scalaire functie wordt gedeclareerd met de SCHEMABINDING optie, gaat SQL Server ervan uit dat de functie toegang heeft tot tabellen. Beschouw ter illustratie de eenvoudige scalaire T-SQL-functie hieronder:
CREATE FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
AS
BEGIN
RETURN @value;
END;
Deze functie heeft geen toegang tot tabellen; in feite doet het niets anders dan de parameterwaarde die eraan is doorgegeven teruggeven. Kijk nu naar de volgende INSERT vraag:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT p.ProductID FROM AdventureWorks2012.Production.Product AS p;
Het uitvoeringsplan is precies zoals we zouden verwachten, zonder dat Halloween-bescherming nodig is:
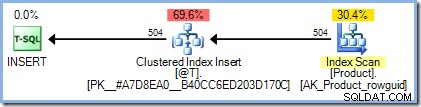
Het toevoegen van onze niets-doen-functie heeft echter een dramatisch effect:
DECLARE @T AS TABLE (ProductID integer PRIMARY KEY); INSERT @T (ProductID) SELECT dbo.ReturnInput(p.ProductID) FROM AdventureWorks2012.Production.Product AS p;

Het uitvoeringsplan bevat nu een Eager Table Spool voor Halloween Protection. SQL Server gaat ervan uit dat de functie toegang heeft tot gegevens, waaronder mogelijk opnieuw lezen uit de producttabel. Zoals u zich wellicht herinnert, is een INSERT plan dat een verwijzing naar de doeltabel aan de leeszijde van het plan bevat, vereist volledige Halloween-bescherming, en voor zover de optimizer weet, kan dat hier het geval zijn.
De SCHEMABINDING . toevoegen optie voor de functiedefinitie betekent dat SQL Server de hoofdtekst van de functie onderzoekt om te bepalen tot welke tabellen het toegang heeft. Het vindt dergelijke toegang niet en voegt dus geen Halloween-bescherming toe:
ALTER FUNCTION dbo.ReturnInput
(
@value integer
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
RETURN @value;
END;
GO
DECLARE @T AS TABLE (ProductID int PRIMARY KEY);
INSERT @T (ProductID)
SELECT p.ProductID
FROM AdventureWorks2012.Production.Product AS p;
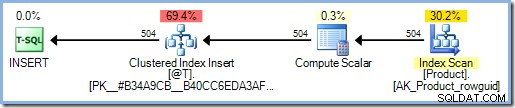
Dit probleem met de scalaire functies van T-SQL is van invloed op alle updatequery's - INSERT , UPDATE , DELETE , en MERGE . Weten wanneer je dit probleem bereikt, wordt moeilijker gemaakt omdat onnodige Halloween-bescherming niet altijd wordt weergegeven als een extra Eager Table Spool, en scalaire functieaanroepen kunnen bijvoorbeeld verborgen zijn in views of berekende kolomdefinities.
[ Deel 1 | Deel 2 | Deel 3 | Deel 4 ]