In januari 2015 schreef mijn goede vriend en mede-SQL Server MVP Rob Farley over een nieuwe oplossing voor het probleem van het vinden van de mediaan in SQL Server-versies vóór 2012. Behalve dat het op zichzelf interessant is om te lezen, blijkt het ook een geweldig voorbeeld om te gebruiken om geavanceerde analyse van uitvoeringsplan te demonstreren en om subtiel gedrag van de query-optimizer en uitvoeringsengine te benadrukken.
Enkel mediaan
Hoewel het artikel van Rob specifiek gericht is op een gegroepeerde mediaanberekening, ga ik beginnen met het toepassen van zijn methode op een groot enkelvoudig mediaanberekeningsprobleem, omdat het de belangrijke kwesties het duidelijkst naar voren brengt. De voorbeeldgegevens komen opnieuw uit het originele artikel van Aaron Bertrand:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Het toepassen van de techniek van Rob Farley op dit probleem geeft de volgende code:
-- 5800ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f;
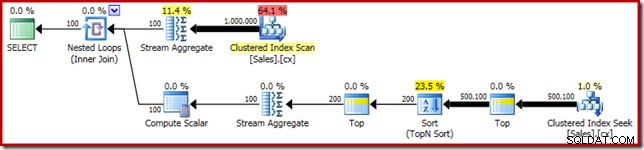
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Zoals gewoonlijk heb ik commentaar gegeven op het tellen van het aantal rijen in de tabel en dit vervangen door een constante om een bron van prestatievariantie te voorkomen. Het uitvoeringsplan voor de belangrijke query is als volgt:

Deze zoekopdracht duurt 5800ms op mijn testmachine.
De sorteerverspilling
De primaire oorzaak van deze slechte prestatie zou duidelijk moeten zijn als we naar het bovenstaande uitvoeringsplan kijken:de waarschuwing op de sorteeroperator laat zien dat een onvoldoende werkruimtegeheugentoelage een niveau 2 (multi-pass) overloop naar fysieke tempdb schijf:
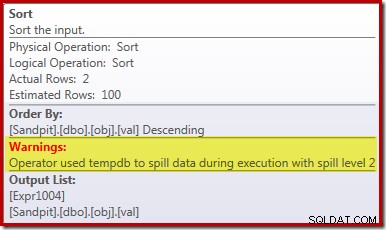
In versies van SQL Server vóór 2012 zou u afzonderlijk moeten controleren op sorteeroverloopgebeurtenissen om dit te zien. Hoe dan ook, de onvoldoende reservering van het sorteergeheugen wordt veroorzaakt door een kardinaliteitsschattingsfout, zoals het pre-uitvoering (geschatte) plan laat zien:

De schatting van de kardinaliteit van 100 rijen bij de invoer Sorteren is een (uiterst onnauwkeurige) schatting door de optimizer, vanwege de lokale variabele-expressie in de voorgaande Top-operator:

Merk op dat deze kardinaliteitsschattingsfout geen rij-doelprobleem is. Door traceringsvlag 4138 toe te passen, wordt het rijdoeleffect onder de eerste Top verwijderd, maar de schatting na Top blijft een schatting van 100 rijen (dus de geheugenreservering voor Sorteren zal nog steeds veel te klein zijn):

De waarde van de lokale variabele aangeven
Er zijn verschillende manieren waarop we dit kardinaliteitsschattingsprobleem kunnen oplossen. Een optie is om een hint te gebruiken om de optimizer informatie te geven over de waarde in de variabele:
-- 3250ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, OPTIMIZE FOR (@Count = 11000000)); -- NEW!
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Het gebruik van de hint verbetert de prestaties tot 3250ms vanaf 5800 ms. Het post-uitvoeringsplan laat zien dat de soort niet langer morst:

Hier zijn echter een paar nadelen aan verbonden. Ten eerste vereist dit nieuwe uitvoeringsplan een 388 MB geheugentoekenning - geheugen dat anders door de server zou kunnen worden gebruikt om plannen, indexen en gegevens in de cache op te slaan:
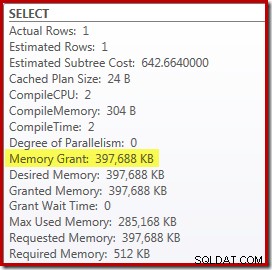
Ten tweede kan het moeilijk zijn om een goed nummer voor de hint te kiezen dat goed werkt voor alle toekomstige uitvoeringen, zonder onnodig geheugen te reserveren.
Merk ook op dat we een waarde voor de variabele moesten aangeven die 10% hoger is dan de werkelijke waarde van de variabele om de verspilling volledig te elimineren. Dit is niet ongebruikelijk, omdat het algemene sorteeralgoritme wat complexer is dan een eenvoudige in-place sortering. Het reserveren van geheugen dat gelijk is aan de grootte van de set die moet worden gesorteerd, zal niet altijd (of zelfs in het algemeen) voldoende zijn om lekkage tijdens runtime te voorkomen.
Insluiten en opnieuw compileren
Een andere optie is om te profiteren van de parameter Embedding Optimization die is ingeschakeld door een hercompilatiehint op queryniveau toe te voegen aan SQL Server 2008 SP1 CU5 of hoger. Met deze actie kan de optimizer de runtime-waarde van de variabele zien en dienovereenkomstig optimaliseren:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1, RECOMPILE);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Dit verbetert de uitvoeringstijd tot 3150ms – 100ms beter dan het gebruik van de OPTIMIZE FOR hint. De reden voor deze verdere kleine verbetering kan worden afgeleid uit het nieuwe post-uitvoeringsplan:

De uitdrukking (2 – @Count % 2) - zoals eerder te zien in de tweede Top-operator - kan nu worden ingeklapt tot een enkele bekende waarde. Een herschrijving na optimalisatie kan vervolgens de Top met de Sort combineren, wat resulteert in een enkele Top N Sort. Dit herschrijven was voorheen niet mogelijk omdat het samenvouwen van Top + Sort in een Top N Sort alleen werkt met een constante letterlijke Top-waarde (geen variabelen of parameters).
Het vervangen van de Top en Sort door een Top N Sort heeft een klein gunstig effect op de prestaties (100 ms hier), maar het elimineert ook bijna volledig de geheugenvereiste, omdat een Top N Sort alleen de N hoogste (of laagste) hoeft bij te houden. rijen, in plaats van de hele set. Als gevolg van deze wijziging in het algoritme blijkt uit het post-uitvoeringsplan voor deze query dat de minimale 1MB geheugen was gereserveerd voor de Top N Sort in dit plan, en slechts 16KB werd gebruikt tijdens runtime (onthoud, het volledige sorteerplan vereiste 388 MB):
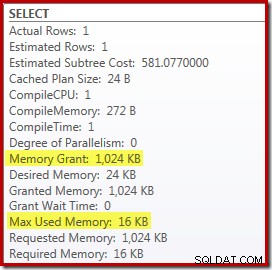
Hercompilatie vermijden
Het (voor de hand liggende) nadeel van het gebruik van de hercompileerquery-hint is dat het bij elke uitvoering een volledige compilatie vereist. In dit geval is de overhead vrij klein:ongeveer 1 ms CPU-tijd en 272 KB geheugen. Toch is er een manier om de query zo aan te passen dat we de voordelen van een Top N Sort krijgen zonder hints te gebruiken en zonder opnieuw te compileren.
Het idee komt voort uit de erkenning dat een maximum van twee rijen zijn vereist voor de uiteindelijke mediaanberekening. Het kan één rij zijn, of het kunnen er twee zijn tijdens runtime, maar het kan nooit meer zijn. Dit inzicht betekent dat we als volgt een logisch redundante Top (2) tussenstap aan de query kunnen toevoegen:
-- 3150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(0E + f.val)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2) -- NEW!
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); De nieuwe Top (met de allerbelangrijkste constante letterlijke) betekent dat het uiteindelijke uitvoeringsplan de gewenste Top N Sort-operator bevat zonder opnieuw te compileren:

De prestaties van dit uitvoeringsplan zijn ongewijzigd ten opzichte van de opnieuw gecompileerde versie op 3150ms en de geheugenvereiste is hetzelfde. Houd er echter rekening mee dat het gebrek aan inbedding van parameters betekent dat de kardinaliteitsschattingen onder de soort 100-rijen zijn (hoewel dat hier geen invloed heeft op de prestaties).
De belangrijkste conclusie in dit stadium is dat als je een Top N Sort met weinig geheugen wilt, je een constante literal moet gebruiken, of de optimizer een literal moet laten zien via de parameter embedding optimalisatie.
De Compute Scalar
Het elimineren van de 388MB geheugentoekenning (terwijl ook een prestatieverbetering van 100 ms wordt bereikt) is zeker de moeite waard, maar er is een veel grotere prestatiewinst beschikbaar. Het onwaarschijnlijke doel van deze laatste verbetering is de Compute Scalar net boven de Clustered Index Scan.
Deze Compute Scalar heeft betrekking op de uitdrukking (0E + f.val) opgenomen in de AVG aggregeren in de query. Voor het geval dat je er raar uitziet, dit is een vrij gebruikelijke truc voor het schrijven van query's (zoals vermenigvuldigen met 1,0) om rekenen met gehele getallen in de gemiddelde berekening te vermijden, maar het heeft enkele zeer belangrijke neveneffecten.
Er is hier een bepaalde reeks gebeurtenissen die we stap voor stap moeten volgen.
Merk eerst op dat 0E is een constante letterlijke nul, met een float data type. Om dit toe te voegen aan de integer column val, moet de query-processor de kolom converteren van integer naar float (in overeenstemming met de voorrangsregels van het gegevenstype). Een soortgelijk soort conversie zou nodig zijn als we ervoor hadden gekozen om de kolom met 1,0 te vermenigvuldigen (een letterlijke met een impliciet numeriek gegevenstype). Het belangrijkste punt is dat deze routinetruc een uitdrukking introduceert .
Nu probeert SQL Server over het algemeen expressies naar beneden te duwen de planboom zoveel mogelijk tijdens het samenstellen en optimaliseren. Dit wordt gedaan om verschillende redenen, waaronder om het matchen van expressies met berekende kolommen gemakkelijker te maken en om vereenvoudigingen te vergemakkelijken met behulp van informatie over beperkingen. Dit push-downbeleid verklaart waarom de Compute Scalar veel dichter bij het leaf-niveau van het plan lijkt dan de oorspronkelijke tekstuele positie van de expressie in de query doet vermoeden.
Een risico van het uitvoeren van deze push-down is dat de uitdrukking uiteindelijk vaker wordt berekend dan nodig is. De meeste plannen hebben een kleiner aantal rijen naarmate we hoger in de planstructuur komen, vanwege het effect van samenvoegingen, aggregatie en filters. Als u uitdrukkingen door de boomstructuur duwt, loopt u het risico die uitdrukkingen vaker te evalueren (d.w.z. in meer rijen) dan nodig is.
Om dit te ondervangen heeft SQL Server 2005 een optimalisatie geïntroduceerd waarbij Compute Scalars eenvoudig definiëren een uitdrukking, met het werk van het daadwerkelijk evalueren de uitdrukking uitgesteld totdat een latere operator in het plan het resultaat vraagt. Wanneer deze optimalisatie werkt zoals bedoeld, is het effect dat u alle voordelen krijgt van het naar beneden duwen van uitdrukkingen, terwijl u de uitdrukking nog steeds slechts zo vaak evalueert als werkelijk nodig is.
Wat al deze Compute Scalar-dingen betekenen
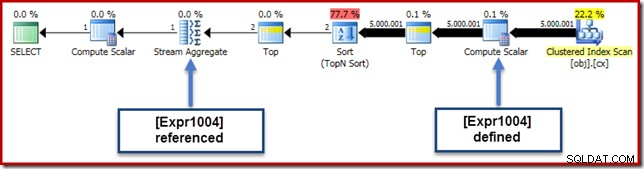
In ons lopende voorbeeld is de 0E + val uitdrukking was oorspronkelijk geassocieerd met de AVG aggregaat, dus we zouden het kunnen verwachten bij (of iets na) de Stream Aggregate. Deze uitdrukking is echter naar beneden geduwd de boom om een nieuwe Compute Scalar te worden net na de scan, met de uitdrukking gelabeld als [Expr1004].
Als we naar het uitvoeringsplan kijken, kunnen we zien dat naar [Expr1004] wordt verwezen door de Stream Aggregate (uittreksel van het tabblad Plan Explorer Expressions hieronder weergegeven):

Als alles gelijk is, wordt de evaluatie van uitdrukking [Expr1004] uitgesteld totdat het aggregaat die waarden nodig heeft voor het somdeel van de gemiddelde berekening. Aangezien het aggregaat slechts één of twee rijen kan tegenkomen, zou dit ertoe moeten leiden dat [Uitdr1004] slechts één of twee keer wordt geëvalueerd:
Helaas is dit niet helemaal hoe het hier werkt. Het probleem is de blokkerende sorteeroperator:
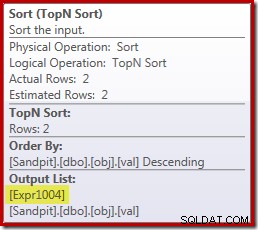
Dit dwingt evaluatie van [Uitdr1004] af, dus in plaats van dat het slechts een of twee keer wordt geëvalueerd bij de Stream Aggregate, betekent de Sortering dat we uiteindelijk de val converteren. kolom toe aan een float en er nul bij optellen 5.000,001 keer!
Een tijdelijke oplossing
Idealiter zou SQL Server hier wat slimmer in zijn, maar zo werkt het tegenwoordig niet. Er is geen vraaghint om te voorkomen dat expressies door de planboom worden geduwd, en we kunnen Compute Scalars ook niet forceren met een Plan Guide. Er is onvermijdelijk een traceervlag zonder papieren, maar daar kan ik in de huidige context niet verantwoordelijk over praten.
Dus, voor beter of slechter, dit laat ons achter met het zoeken naar een herschrijving van een query die voorkomt dat SQL Server de expressie scheidt van het aggregaat en deze naar beneden duwt voorbij de Sort, zonder het resultaat van de query te veranderen. Dit is niet zo eenvoudig als je zou denken, maar de (weliswaar enigszins vreemd uitziende) wijziging hieronder bereikt dit met behulp van een CASE uitdrukking op een niet-deterministische intrinsieke functie:
-- 2150ms
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
-- NEW!
Median = AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + f.val END)
FROM
(
SELECT TOP (2 - @Count % 2)
t.val
FROM
(
SELECT TOP (2)
z.val
FROM
(
SELECT TOP (@Count / 2 + 1)
z.val
FROM dbo.obj AS z
ORDER BY
z.val ASC
) AS z
ORDER BY z.val DESC
) AS t
ORDER BY
t.val DESC
) AS f
OPTION (MAXDOP 1);
SELECT RF = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Het uitvoeringsplan voor deze laatste vorm van de vraag wordt hieronder weergegeven:

Merk op dat er geen Compute Scalar meer verschijnt tussen de Clustered Index Scan en de Top. De 0E + val expressie wordt nu berekend bij de Stream Aggregate op maximaal twee rijen (in plaats van vijf miljoen!) en de prestaties nemen met nog eens 32% toe van 3150ms tot 2150ms als resultaat.
Dit is nog steeds niet zo goed te vergelijken met de prestaties van minder dan een seconde van de OFFSET en dynamische cursor mediaan-berekeningsoplossingen, maar het vertegenwoordigt nog steeds een zeer significante verbetering ten opzichte van de originele 5800ms voor deze methode op een grote single-mediaan probleemset.
De CASE-truc werkt natuurlijk niet gegarandeerd in de toekomst. De afhaalmaaltijd gaat niet zozeer over het gebruik van rare trucs voor het uitdrukken van hoofdletters, als wel over de mogelijke implicaties voor de prestaties van Compute Scalars. Als je dit soort dingen eenmaal weet, denk je misschien twee keer na voordat je vermenigvuldigt met 1,0 of float nul toevoegt aan een gemiddelde berekening.
Bijwerken: zie de eerste opmerking voor een goede oplossing van Robert Heinig die geen ongedocumenteerde bedrog vereist. Iets om in gedachten te houden wanneer u de volgende keer in de verleiding komt om een geheel getal te vermenigvuldigen met decimaal (of zwevend) één in een gemiddeld aggregaat.
Gegroepeerde mediaan
Voor de volledigheid, en om deze analyse nauwer te verbinden met het oorspronkelijke artikel van Rob, zullen we eindigen door dezelfde verbeteringen toe te passen op een gegroepeerde mediaanberekening. Door de kleinere setgroottes (per groep) zijn de effecten natuurlijk kleiner.
De gegroepeerde mediane voorbeeldgegevens (opnieuw zoals oorspronkelijk gemaakt door Aaron Bertrand) bestaan uit tienduizend rijen voor elk van honderd denkbeeldige verkopers:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount); Het rechtstreeks toepassen van de oplossing van Rob Farley geeft de volgende code, die wordt uitgevoerd in 560ms op mijn computer.
-- 560ms Original
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Het uitvoeringsplan vertoont duidelijke overeenkomsten met de enkele mediaan:
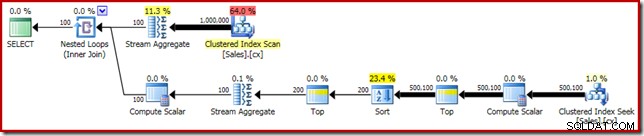
Onze eerste verbetering is om de Sort te vervangen door een Top N Sort, door een expliciete Top (2) toe te voegen. Dit verbetert de uitvoeringstijd enigszins van 560 ms naar 550 ms .
-- 550ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + f.Amount)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
-- NEW!
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Het uitvoeringsplan toont de Top N Sort zoals verwacht:
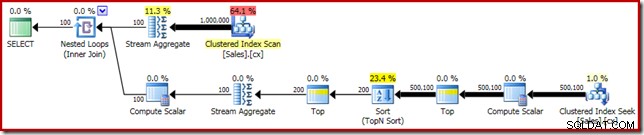
Ten slotte implementeren we de vreemd ogende CASE-expressie om de gepushte Compute Scalar-expressie te verwijderen. Dit verbetert de prestaties verder tot 450ms (een verbetering van 20% ten opzichte van het origineel):
-- 450ms
DECLARE @s datetime2 = SYSUTCDATETIME();
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT S.SalesPerson, COUNT_BIG(*) AS y
FROM dbo.Sales AS S
GROUP BY S.SalesPerson
) AS d
CROSS APPLY
(
-- NEW!
SELECT AVG(CASE WHEN GETDATE() >= {D '1753-01-01'} THEN 0E + Amount END)
FROM
(
SELECT TOP (2 - d.y % 2)
q.Amount
FROM
(
SELECT TOP (2) t.Amount
FROM
(
SELECT TOP (d.y / 2 + 1)
z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount ASC
) AS t
ORDER BY t.Amount DESC
) AS q
ORDER BY q.Amount DESC
) AS f
) AS w (Median)
OPTION (MAXDOP 1);
SELECT DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Het voltooide uitvoeringsplan is als volgt: