Er zijn veel discussies geweest over In-Memory OLTP (de functie die voorheen bekend stond als "Hekaton") en hoe het kan helpen bij zeer specifieke, grote werklasten. Midden in een ander gesprek viel me iets op in de CREATE TYPE documentatie voor SQL Server 2014 waardoor ik dacht dat er een meer algemeen gebruiksscenario is:

Relatief stille en onbekende toevoegingen aan de CREATE TYPE-documentatie
Op basis van het syntaxisdiagram lijkt het erop dat tabelwaardeparameters (TVP's) voor het geheugen kunnen worden geoptimaliseerd, net zoals permanente tabellen dat kunnen. En daarmee begonnen de wielen meteen te draaien.
Eén ding waarvoor ik TVP's heb gebruikt, is om klanten te helpen dure methoden voor het splitsen van strings in T-SQL of CLR te elimineren (zie de achtergrond in eerdere berichten hier, hier en hier). In mijn tests presteerde het gebruik van een gewone TVP aanzienlijk beter dan equivalente patronen met behulp van CLR- of T-SQL-splitsingsfuncties (25-50%). Logischerwijs vroeg ik me af:zou er prestatiewinst zijn met een voor geheugen geoptimaliseerd TVP?
Er is enige ongerustheid over In-Memory OLTP in het algemeen, omdat er veel beperkingen en hiaten in functies zijn, je een aparte bestandsgroep nodig hebt voor voor geheugen geoptimaliseerde gegevens, je hele tabellen moet verplaatsen naar voor geheugen geoptimaliseerd, en het beste voordeel is meestal bereikt door ook native gecompileerde opgeslagen procedures te maken (die hun eigen beperkingen hebben). Zoals ik zal aantonen, ervan uitgaande dat uw tabeltype eenvoudige gegevensstructuren bevat (die bijvoorbeeld een reeks gehele getallen of tekenreeksen vertegenwoordigen), elimineert het gebruik van deze technologie alleen voor TVP's sommige van deze problemen.
De Test
U hebt nog steeds een voor geheugen geoptimaliseerde bestandsgroep nodig, zelfs als u geen permanente, voor het geheugen geoptimaliseerde tabellen gaat maken. Laten we dus een nieuwe database maken met de juiste structuur:
DATABASE MAKEN xtp;GOALTER DATABASE xtp BESTANDSGROEP TOEVOEGEN xtp BEVAT MEMORY_OPTIMIZED_DATA;GOALTER DATABASE xtp BESTAND TOEVOEGEN (name='xtpmod', bestandsnaam='c:\...\xtp.mod') SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT =AAN;GO
Nu kunnen we een normaal tabeltype maken, zoals we vandaag zouden doen, en een voor geheugen geoptimaliseerd tabeltype met een niet-geclusterde hash-index en een bucket-telling die ik uit de lucht heb gehaald (meer informatie over het berekenen van geheugenvereisten en bucket-telling in de echte wereld hier):
GEBRUIK xtp;GO MAAK TYPE dbo.ClassicTVP ALS TABEL (item INT PRIMARY KEY); MAAK TYPE dbo.InMemoryTVP ALS TABEL (item INT NIET NULL PRIMAIRE SLEUTEL NIET-GECLUSTERD HASH MET (BUCKET_COUNT =256)) MET (MEMORY_OPTIMIZED =AAN);
Als u dit probeert in een database die geen voor geheugen geoptimaliseerde bestandsgroep heeft, krijgt u deze foutmelding, net zoals u zou doen als u een normale voor geheugen geoptimaliseerde tabel zou maken:
Msg 41337, Level 16, State 0, Line 9De MEMORY_OPTIMIZED_DATA bestandsgroep bestaat niet of is leeg. Voor geheugen geoptimaliseerde tabellen kunnen pas voor een database worden gemaakt als deze één MEMORY_OPTIMIZED_DATA bestandsgroep heeft die niet leeg is.
Om een query te testen tegen een normale, niet voor het geheugen geoptimaliseerde tabel, heb ik eenvoudig wat gegevens in een nieuwe tabel uit de AdventureWorks2012-voorbeelddatabase gehaald met behulp van SELECT INTO om al die vervelende beperkingen, indexen en uitgebreide eigenschappen te negeren, maakte ik vervolgens een geclusterde index op de kolom waarvan ik wist dat ik zou zoeken (ProductID ):
SELECTEER * INTO dbo.Products VANAF AdventureWorks2012.Production.Product; -- 504 rijen MAAK UNIEKE GECLUSTERDE INDEX p OP dbo.Products(ProductID);
Vervolgens heb ik vier opgeslagen procedures gemaakt:twee voor elk tabeltype; elk met behulp van EXISTS en JOIN benaderingen (meestal vind ik het leuk om beide te onderzoeken, ook al geef ik de voorkeur aan EXISTS; later zul je zien waarom ik mijn testen niet wilde beperken tot slechts EXISTS ). In dit geval wijs ik alleen een willekeurige rij toe aan een variabele, zodat ik hoge uitvoeringen kan observeren zonder met resultatensets en andere output en overhead te werken:
-- Old-school TVP met EXISTS:CREATE PROCEDURE dbo.ClassicTVP_Exists @Classic dbo.ClassicTVP READONLYASBEGIN STEL NOCOUNT IN; DECLARE @naam NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p WHERE EXISTS (SELECT 1 FROM @Classic AS t WHERE t.Item =p.ProductID);ENDGO -- In-Memory TVP met EXISTS:CREATE PROCEDURE dbo.InMemoryTVP_Exists @InMemory dbo.InMemoryTVP ALLEEN LEZENASBEGIN STEL NOCOUNT IN; DECLARE @naam NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p WHERE EXISTS (SELECT 1 FROM @InMemory AS t WHERE t.Item =p.ProductID);ENDGO -- Old-school TVP met een JOIN:CREATE PROCEDURE dbo.ClassicTVP_Join @ Klassiek dbo.KlassiekTVP ALLEEN LEZENASBEGIN SET NOCOUNT ON; DECLARE @naam NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p INNER JOIN @Classic AS t ON t.Item =p.ProductID;ENDGO -- In-Memory TVP met een JOIN:CREATE PROCEDURE dbo.InMemoryTVP_Join @InMemory dbo.InMemoryTVP READONLYASBEGINA STEL GEEN AANTAL IN; DECLARE @naam NVARCHAR(50); SELECT @name =p.Name FROM dbo.Products AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;ENDGO
Vervolgens moest ik het soort query simuleren dat typisch tegen dit type tabel komt en in de eerste plaats een TVP of vergelijkbaar patroon vereist. Stel je een formulier voor met een vervolgkeuzelijst of een reeks selectievakjes met een lijst met producten, en de gebruiker kan de 20 of 50 of 200 selecteren die ze willen vergelijken, een lijst maken, wat heb je. De waarden zullen niet in een mooie aaneengesloten set zitten; ze zullen meestal overal verspreid zijn (als het een voorspelbaar aaneengesloten bereik was, zou de zoekopdracht veel eenvoudiger zijn:begin- en eindwaarden). Dus ik koos gewoon een willekeurige 20 waarden uit de tabel (probeerde onder, laten we zeggen, 5% van de tabelgrootte te blijven), willekeurig geordend. Een gemakkelijke manier om een herbruikbare VALUES . te bouwen clausule als deze is als volgt:
DECLARE @x VARCHAR(4000) =''; SELECTEER TOP (20) @x +='(' + RTRIM(ProductID) + '),' UIT dbo.Producten BESTELLEN DOOR NEWID(); SELECT @x; De resultaten (de jouwe zal vrijwel zeker variëren):
(725),(524),(357),(405),(477),(821),(323),(526),(952),(473),(442),(450),(735 ),(441),(409),(454),(780),(966),(988),(512),
In tegenstelling tot een directe INSERT...SELECT , dit maakt het vrij eenvoudig om die uitvoer te manipuleren in een herbruikbare instructie om onze TVP's herhaaldelijk te vullen met dezelfde waarden en gedurende meerdere testiteraties:
STEL NOCOUNT IN; VERKLAREN @ClassicTVP dbo.ClassicTVP;VERKLAREN @InMemoryTVP dbo.InMemoryTVP; INSERT @ClassicTVP(Item) VALUES (725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); INSERT @InMemoryTVP(Item) VALUES (725), (524), (357), (405), (477), (821), (323), (526), (952), (473), (442) ,(450),(735),(441),(409),(454),(780),(966),(988),(512); EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP;EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP;EXEC dbo.InMemoryTVP_Join @InMemory =@;Als we deze batch uitvoeren met SQL Sentry Plan Explorer, laten de resulterende plannen een groot verschil zien:de in-memory TVP kan een geneste loops-join en 20 single-row geclusterde index-zoekopdrachten gebruiken, versus een merge-join die 502 rijen per een geclusterde indexscan voor de klassieke TVP. En in dit geval leverden EXISTS en JOIN identieke plannen op. Dit kan een fooi geven met een veel hoger aantal waarden, maar laten we doorgaan met de veronderstelling dat het aantal waarden minder dan 5% van de tabelgrootte zal zijn:
Plannen voor klassieke en in-memory TVP's
Tooltips voor scan/seek-operators, met de nadruk op grote verschillen – Klassiek links, In- Geheugen rechts
Wat betekent dit nu op schaal? Laten we elke showplan-verzameling uitschakelen en het testscript enigszins wijzigen om elke procedure 100.000 keer uit te voeren, waarbij de cumulatieve runtime handmatig wordt vastgelegd:
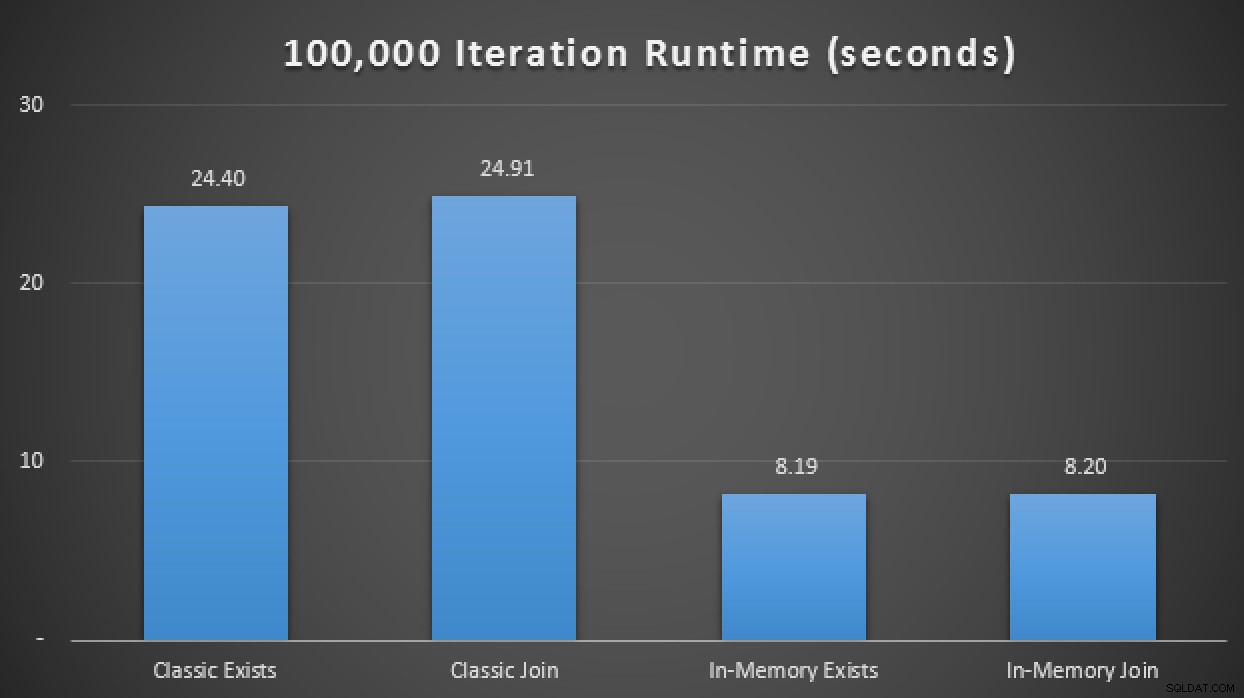
VERKLAREN @i TINYINT =1, @j INT =1; WHILE @i <=4BEGIN SELECTEER SYSDATETIME(); WHILE @j <=100000 BEGIN IF @i =1 BEGIN EXEC dbo.ClassicTVP_Exists @Classic =@ClassicTVP; END IF @i =2 BEGIN EXEC dbo.InMemoryTVP_Exists @InMemory =@InMemoryTVP; END IF @i =3 BEGIN EXEC dbo.ClassicTVP_Join @Classic =@ClassicTVP; END IF @i =4 BEGIN EXEC dbo.InMemoryTVP_Join @InMemory =@InMemoryTVP; EINDE INSTELLEN @j +=1; END SELECT @i +=1, @j =1;END SELECT SYSDATETIME();In de resultaten, gemiddeld over 10 runs, zien we dat, in deze beperkte testcase, het gebruik van een voor geheugen geoptimaliseerd tabeltype een ruwweg 3x verbetering opleverde ten opzichte van misschien wel de meest kritische prestatiestatistiek in OLTP (runtimeduur):
Runtime-resultaten die een 3x verbetering laten zien met In-Memory TVP'sIn-Memory + In-Memory + In-Memory:In-Memory Inception
Nu we hebben gezien wat we kunnen doen door simpelweg ons normale tabeltype te veranderen in een voor geheugen geoptimaliseerd tabeltype, laten we eens kijken of we meer prestaties uit hetzelfde querypatroon kunnen halen wanneer we de trifecta toepassen:een in-memory tabel, met behulp van een native gecompileerde, voor het geheugen geoptimaliseerde opgeslagen procedure, die een tabeltabel in het geheugen accepteert als een tabelwaardeparameter.
Eerst moeten we een nieuwe kopie van de tabel maken en deze vullen vanuit de lokale tabel die we al hebben gemaakt:
CREATE TABLE dbo.Products_InMemory( ProductID INT NOT NULL, Name NVARCHAR(50) NOT NULL, ProductNumber NVARCHAR(25) NOT NULL, MakeFlag BIT NOT NULL, FinishedGoodsFlag BIT NULL, Color NVARCHAR (15) NULL, SafetyStockLevel SMALLINT NOT NULL , ReorderPoint SMALLINT NIET NULL, StandardCost MONEY NOT NULL, ListPrice MONEY NOT NULL, [Size] NVARCHAR(5) NULL, SizeUnitMeasureCode NCHAR(3) NULL, WeightUnitMeasureCode NCHAR(3) NULL, [Weight] DECIMAL(8, 2) NULL, DaysToManufacture INT NOT NULL, ProductLine NCHAR(2) NULL, [Klasse] NCHAR(2) NULL, Style NCHAR(2) NULL, ProductSubcategoryID INT NULL, ProductModelID INT NULL, Se llStartDate DATETIME NOT NULL, SellEndDate DATETIME NULL, DiscontinuedDate DATETIME NULL, rowguid UNIQUEIDENTIFIER NULL, ModifiedDate DATETIME NULL, PRIMAIRE SLEUTEL NIET-GECLUSTERDE HASH (ProductID) MET (BUCKET_COUNT =256)) MET (GEHEUGEN_OPTIMALISATIE =AAN); INSERT dbo.Products_InMemory SELECTEER * VAN dbo.Products;Vervolgens maken we een native gecompileerde opgeslagen procedure die ons bestaande, voor geheugen geoptimaliseerde tabeltype als TVP gebruikt:
PROCEDURE MAKEN dbo.InMemoryProcedure @InMemory dbo.InMemoryTVP ALLEEN LEZEN MET NATIVE_COMPILATION, SCHEMABINDING, UITVOEREN ALS EIGENAAR ALS BEGIN ATOMIC MET (TRANSACTIE ISOLATIENIVEAU =MOMENTOPNAME', TAAL =N'); DECLARE @Name NVARCHAR(50); SELECT @Name =Name FROM dbo.Products_InMemory AS p INNER JOIN @InMemory AS t ON t.Item =p.ProductID;END GOEen paar kanttekeningen. We kunnen geen normaal, niet voor het geheugen geoptimaliseerd tabeltype gebruiken als parameter voor een native gecompileerde opgeslagen procedure. Als we het proberen, krijgen we:
Msg 41323, Level 16, State 1, Procedure InMemoryProcedure
Het tabeltype 'dbo.ClassicTVP' is geen voor geheugen geoptimaliseerd tabeltype en kan niet worden gebruikt in een native gecompileerde opgeslagen procedure.Ook kunnen we de
Msg 12311, Level 16, State 37, Procedure NativeCompiled_ExistsEXISTS. niet gebruiken patroon hier ofwel; als we het proberen, krijgen we:
Subquery's (query's genest in een andere query) worden niet ondersteund met native gecompileerde opgeslagen procedures.Er zijn veel andere kanttekeningen en beperkingen met In-Memory OLTP en native gecompileerde opgeslagen procedures, ik wilde alleen een paar dingen delen die duidelijk lijken te ontbreken bij het testen.
Dus toen ik deze nieuwe native gecompileerde opgeslagen procedure aan de bovenstaande testmatrix toevoegde, ontdekte ik dat het - nogmaals, gemiddeld over 10 runs - de 100.000 iteraties in slechts 1,25 seconden uitvoerde. Dit vertegenwoordigt een verbetering van ongeveer 20x ten opzichte van reguliere TVP's en een verbetering van 6-7x ten opzichte van in-memory TVP's die traditionele tabellen en procedures gebruiken:
Runtime-resultaten met tot 20x verbetering met rondom in-MemoryConclusie
Als u nu TVP's gebruikt of patronen gebruikt die door TVP's kunnen worden vervangen, moet u absoluut overwegen om voor geheugen geoptimaliseerde TVP's toe te voegen aan uw testplannen, maar houd er rekening mee dat u mogelijk niet dezelfde verbeteringen in uw scenario ziet. (En natuurlijk in gedachten houdend dat TVP's in het algemeen veel voorbehouden en beperkingen hebben, en ze zijn ook niet geschikt voor alle scenario's. Erland Sommarskog heeft hier een geweldig artikel over de TVP's van vandaag.)
In feite zie je misschien dat er aan de onderkant van volume en gelijktijdigheid geen verschil is - maar test het alsjeblieft op realistische schaal. Dit was een zeer eenvoudige en gekunstelde test op een moderne laptop met een enkele SSD, maar als je het hebt over echt volume en/of spinny mechanische schijven, kunnen deze prestatiekenmerken veel zwaarder wegen. Er komt een vervolg met enkele demonstraties over grotere gegevensformaten.