Als we kijken naar de prestaties van query's, zijn er veel geweldige informatiebronnen binnen SQL Server, en een van mijn favorieten is het queryplan zelf. In de laatste verschillende releases, met name te beginnen met SQL Server 2012, heeft elke nieuwe versie meer details in de uitvoeringsplannen opgenomen. Hoewel de lijst met verbeteringen blijft groeien, zijn hier een paar kenmerken die ik waardevol heb gevonden:
- NietParallelPlanReason (SQL Server 2012)
- Residuele predicaat pushdown-diagnose (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- tempdb-lekdiagnose (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Trace-vlaggen ingeschakeld (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Statistieken voor de uitvoering van query's van de operator (SQL Server 2014 SP2, SQL Server 2016)
- Maximum geheugen ingeschakeld voor een enkele query (SQL Server 2014 SP2, SQL Server 2016 SP1)
Om te zien wat er voor elke versie van SQL Server bestaat, gaat u naar de Showplan Schema-pagina, waar u het schema voor elke versie sinds SQL Server 2005 kunt vinden.
Hoezeer ik ook van al deze extra gegevens hou, het is belangrijk op te merken dat sommige informatie relevanter is voor een daadwerkelijk uitvoeringsplan, dan voor een geschat plan (bijv. tempdb-morsinformatie). Sommige dagen kunnen we het daadwerkelijke plan vastleggen en gebruiken voor het oplossen van problemen, andere keren moeten we het geschatte plan gebruiken. Heel vaak halen we dat geschatte plan - het plan dat mogelijk is gebruikt voor problematische uitvoeringen - uit de plancache van SQL Server. En het trekken van individuele plannen is geschikt bij het afstemmen van een specifieke query of set of query's. Maar hoe zit het als u ideeën wilt hebben over waar u uw afstemmingsinspanningen in termen van patronen op kunt richten?
De cache van het SQL Server-plan is een geweldige bron van informatie als het gaat om het afstemmen van prestaties, en dan bedoel ik niet alleen het oplossen van problemen en proberen te begrijpen wat er in een systeem draait. In dit geval heb ik het over het ontginnen van informatie uit de plannen zelf, die te vinden zijn in sys.dm_exec_query_plan, opgeslagen als XML in de kolom query_plan.
Wanneer u deze gegevens combineert met informatie uit sys.dm_exec_sql_text (zodat u gemakkelijk de tekst van de query kunt bekijken) en sys.dm_exec_query_stats (uitvoeringsstatistieken), kunt u plotseling beginnen te zoeken naar niet alleen die query's die het zwaarst wegen of worden uitgevoerd het vaakst, maar die plannen die een bepaald join-type of indexscan bevatten, of die met de hoogste kosten. Dit wordt gewoonlijk het minen van de plancache genoemd, en er zijn verschillende blogposts die vertellen hoe je dit kunt doen. Mijn collega, Jonathan Kehayias, zegt dat hij een hekel heeft aan het schrijven van XML, maar hij heeft verschillende berichten met vragen over het ontginnen van de plancache:
- Afstemming 'kostendrempel voor parallellisme' uit de Plan Cache
- Impliciete kolomconversies vinden in de plancache
- Zoeken welke zoekopdrachten in de plancache een specifieke index gebruiken
- In de SQL-plancache graven:ontbrekende indexen vinden
- Sleutelzoekopdrachten vinden in de plancache
Als je nog nooit hebt onderzocht wat er in je plancache staat, zijn de vragen in deze berichten een goed begin. De plancache heeft echter zijn beperkingen. Het is bijvoorbeeld mogelijk om een query uit te voeren en het plan niet in de cache te laten gaan. Als u bijvoorbeeld de optie Optimaliseren voor adhoc-workloads hebt ingeschakeld, wordt bij de eerste uitvoering de gecompileerde planstub opgeslagen in de plancache, niet het volledige gecompileerde plan. Maar de grootste uitdaging is dat de plancache tijdelijk is. Er zijn veel gebeurtenissen in SQL Server die de plancache volledig kunnen wissen of voor een database kunnen wissen, en plannen kunnen uit de cache raken als ze niet worden gebruikt, of worden verwijderd na een hercompilatie. Om dit te bestrijden, moet u meestal de plancache regelmatig opvragen of de inhoud op een geplande basis in een tabel opnemen.
Dit verandert in SQL Server 2016 met Query Store.
Wanneer een gebruikersdatabase Query Store heeft ingeschakeld, worden de tekst en plannen voor query's die op die database worden uitgevoerd, vastgelegd en bewaard in interne tabellen. In plaats van een tijdelijk beeld van wat er momenteel wordt uitgevoerd, hebben we een langetermijnbeeld van wat eerder is uitgevoerd. De hoeveelheid gegevens die wordt bewaard, wordt bepaald door de instelling CLEANUP_POLICY, die standaard is ingesteld op 30 dagen. Vergeleken met een plancache die slechts een paar uur aan query-uitvoering kan vertegenwoordigen, is de Query Store-gegevens een spelwisselaar.
Overweeg een scenario waarin u een indexanalyse uitvoert - u hebt enkele indexen die niet worden gebruikt en u hebt enkele aanbevelingen van de ontbrekende index-DMV's. De ontbrekende index-DMV's bieden geen details over de query die de ontbrekende indexaanbeveling heeft gegenereerd. U kunt de plancache doorzoeken met behulp van de query uit Jonathan's Finding Missing Indexes-bericht. Als ik dat uitvoer op mijn lokale SQL Server-instantie, krijg ik een paar rijen uitvoer met betrekking tot enkele query's die ik eerder heb uitgevoerd.

Ik kan het plan openen in Plan Explorer en ik zie dat er een waarschuwing is op de SELECT-operator, die voor de ontbrekende index is:
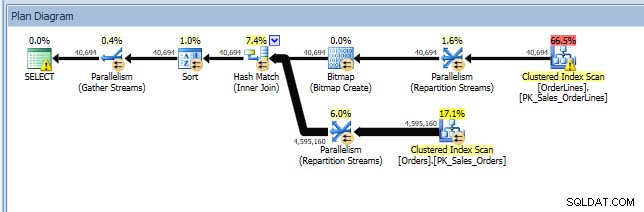
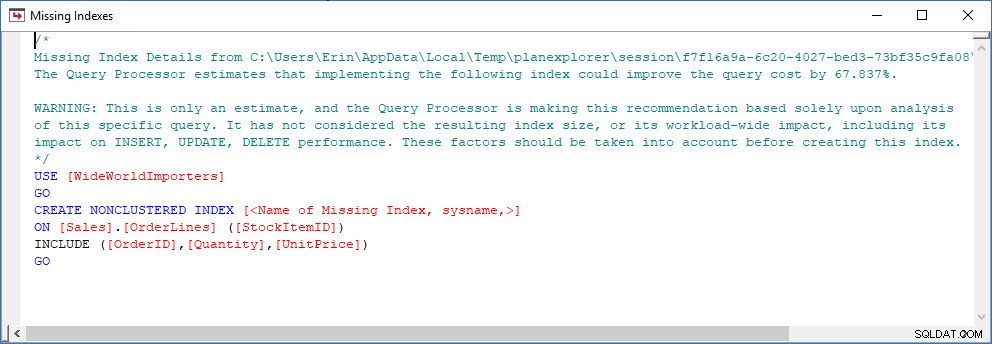
Dit is een goed begin, maar nogmaals, mijn output hangt af van wat zich in de cache bevindt. Ik kan de query van Jonathan aannemen en wijzigen voor Query Store en deze vervolgens uitvoeren op mijn demo WideWorldImporters-database:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
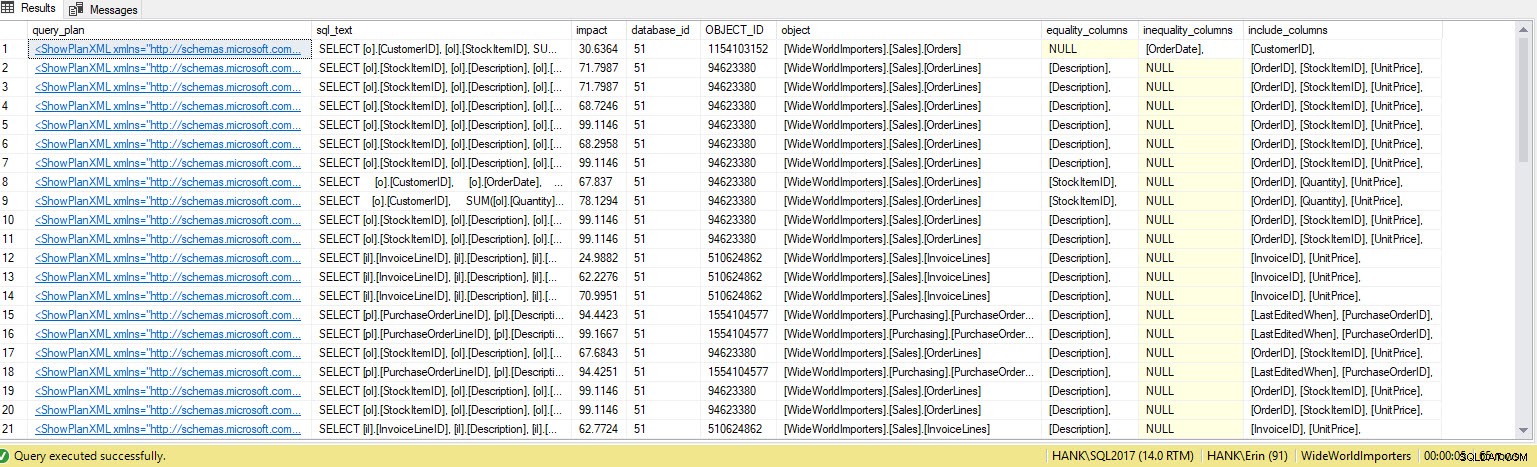
Ik krijg veel meer rijen in de uitvoer. Nogmaals, de Query Store-gegevens vertegenwoordigen een grotere weergave van query's die op het systeem zijn uitgevoerd, en het gebruik van deze gegevens geeft ons een uitgebreide methode om niet alleen te bepalen welke indexen ontbreken, maar ook welke query's die indexen zouden ondersteunen. Vanaf hier kunnen we dieper in Query Store graven en kijken naar prestatiestatistieken en uitvoeringsfrequentie om de impact van het maken van de index te begrijpen en te beslissen of de query vaak genoeg wordt uitgevoerd om de index te rechtvaardigen.
Als u Query Store niet gebruikt, maar wel SentryOne, kunt u dezelfde informatie uit de SentryOne-database halen. Het queryplan wordt opgeslagen in de dbo.PerformanceAnalysisPlan-tabel in een gecomprimeerde indeling, dus de query die we gebruiken is een soortgelijke variatie als die hierboven, maar u zult merken dat de DECOMPRESS-functie ook wordt gebruikt:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Op één SentryOne-systeem had ik de volgende uitvoer (en natuurlijk zal het klikken op een van de query_plan-waarden het grafische plan openen):

Een aantal voordelen die SentryOne biedt ten opzichte van Query Store is dat u dit type verzameling niet per database hoeft aan te zetten, en dat de bewaakte database de opslagvereisten niet hoeft te ondersteunen, aangezien alle gegevens in de repository worden opgeslagen. U kunt deze informatie ook vastleggen in alle ondersteunde versies van SQL Server, niet alleen die welke Query Store ondersteunen. Houd er echter rekening mee dat SentryOne alleen query's verzamelt die drempels overschrijden, zoals duur en leesbewerkingen. U kunt deze standaarddrempels aanpassen, maar het is een item om op te letten bij het minen van de SentryOne-database:mogelijk worden niet alle query's verzameld. Bovendien is de DECOMPRESS-functie pas beschikbaar in SQL Server 2016; voor oudere versies van SQL Server wilt u ofwel:
- Maak een back-up van de SentryOne-database en herstel deze op SQL Server 2016 of hoger om de query's uit te voeren;
- bcp de gegevens uit de dbo.PerformanceAnalysisPlan-tabel en importeer deze in een nieuwe tabel op een SQL Server 2016-instantie;
- de SentryOne-database opvragen via een gekoppelde server vanuit een SQL Server 2016-instantie; of,
- zoek de database op vanuit de applicatiecode die na het decomprimeren op specifieke dingen kan parseren.
Met SentryOne heb je de mogelijkheid om niet alleen de plancache te ontginnen, maar ook de gegevens die in de SentryOne-repository worden bewaard. Als u SQL Server 2016 of hoger gebruikt en Query Store hebt ingeschakeld, kunt u deze informatie ook vinden in sys.query_store_plan . U bent niet beperkt tot alleen dit voorbeeld van het vinden van ontbrekende indexen; alle query's van Jonathan's andere plancacheposts kunnen worden aangepast om te worden gebruikt om gegevens uit SentryOne of uit Query Store te ontginnen. Verder, als u bekend genoeg bent met XQuery (of bereid bent om het te leren), kunt u het Showplan Schema gebruiken om erachter te komen hoe u het plan kunt ontleden om de gewenste informatie te vinden. Dit geeft u de mogelijkheid om patronen en antipatronen in uw queryplannen te vinden die uw team kan oplossen voordat ze een probleem worden.