Wanneer u nauw betrokken bent bij het oplossen van een probleem in SQL Server, merkt u soms dat u de exacte volgorde wilt weten waarin query's zijn uitgevoerd. Ik zie dit bij meer gecompliceerde opgeslagen procedures die lagen van logica bevatten, of in scenario's met veel overbodige code. Extended Events is hier een natuurlijke keuze, omdat het doorgaans wordt gebruikt om informatie over het uitvoeren van query's vast te leggen. Je kunt vaak session_id en het tijdstempel gebruiken om de volgorde van gebeurtenissen te begrijpen, maar er is een sessie-optie voor XE die nog betrouwbaarder is:Volg causaliteit.
Wanneer u Causaliteit traceren voor een sessie inschakelt, voegt het een GUID en volgnummer toe aan elke gebeurtenis, die u vervolgens kunt gebruiken om de volgorde waarin gebeurtenissen plaatsvonden te doorlopen. De overhead is minimaal en het kan een aanzienlijke tijdbesparing opleveren in veel scenario's voor het oplossen van problemen.
Instellen
Met behulp van de WideWorldImporters-database maken we een opgeslagen procedure om te gebruiken:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Dan maken we een evenementsessie:
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); We gaan ook ad-hocquery's uitvoeren, dus we leggen zowel sp_statement_completed (instructies voltooid binnen een opgeslagen procedure) als sql_statement_completed ( voltooide instructies die niet binnen een opgeslagen procedure vallen) vast. Merk op dat de TRACK_CAUSALITY-optie voor de sessie is ingesteld op AAN. Nogmaals, deze instelling is specifiek voor de gebeurtenissessie en moet worden ingeschakeld voordat deze wordt gestart. U kunt de instelling niet direct inschakelen, zoals u gebeurtenissen en doelen kunt toevoegen of verwijderen terwijl de sessie loopt.
Om de gebeurtenissessie via de gebruikersinterface te starten, klikt u er met de rechtermuisknop op en selecteert u Sessie starten.
Testen
Binnen Management Studio voeren we de volgende code uit:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Dit is onze XE-uitvoer:

Merk op dat de eerste uitgevoerde query, die is gemarkeerd, SELECT @@SPID is, en een GUID heeft van FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. We hebben deze query niet uitgevoerd, het gebeurde op de achtergrond, en hoewel de XE-sessie is ingesteld om systeemquery's uit te filteren, wordt deze - om welke reden dan ook - nog steeds vastgelegd.
De volgende vier regels vertegenwoordigen de code die we daadwerkelijk hebben uitgevoerd. Er zijn de twee query's van de opgeslagen procedure, de opgeslagen procedure zelf en dan onze ad-hocquery. Ze hebben allemaal dezelfde GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. Naast de GUID staat de sequentie-id (seq), en de zoekopdrachten zijn genummerd van één tot en met vier.
In ons voorbeeld hebben we GO niet gebruikt om de overzichten in verschillende batches te verdelen. Merk op hoe de uitvoer verandert als we dat doen:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO

We hebben nog steeds hetzelfde aantal rijen in totaal, maar nu hebben we drie GUID's. Een voor de SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), een voor de drie query's die de opgeslagen procedure vertegenwoordigen (F962B9A4-0665-4802-9E6C-B217634D8787), en een voor de ad-hocquery (5DD6A5FE -9702-4DE5-8467-8D7CF55B5D80).
Dit is wat u waarschijnlijk zult zien als u naar gegevens uit uw applicatie kijkt, maar het hangt af van hoe de applicatie werkt. Als het verbindingspooling gebruikt en verbindingen regelmatig opnieuw worden ingesteld (wat wordt verwacht), heeft elke verbinding zijn eigen GUID.
U kunt dit opnieuw maken met behulp van de onderstaande PowerShell-voorbeeldcode:
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Hier is een voorbeeld van de uitvoer van uitgebreide gebeurtenissen nadat de code een tijdje is uitgevoerd:

Er zijn vier verschillende GUID's voor onze vijf verklaringen, en als je naar de bovenstaande code kijkt, zie je dat er vier verschillende verbindingen zijn gemaakt. Als u de gebeurtenissessie wijzigt om de gebeurtenis rpc_completed op te nemen, kunt u items zien met exec sp_reset_connection.
Uw XE-uitvoer is afhankelijk van uw code en uw toepassing; Ik zei in eerste instantie dat dit handig was bij het oplossen van complexere opgeslagen procedures. Beschouw het volgende voorbeeld:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Hier hebben we twee opgeslagen procedures, usp_TransctionInfo en usp_GetFullCustomerInfo, die worden aangeroepen door een andere opgeslagen procedure, usp_GetCustomerData. Het is niet ongebruikelijk om dit te zien, of zelfs extra niveaus van nesting met opgeslagen procedures te zien. Als we usp_GetCustomerData uitvoeren vanuit Management Studio, zien we het volgende:
EXEC [Sales].[usp_GetCustomerData] 981;

Hier vonden alle uitvoeringen plaats op dezelfde GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, en we kunnen de volgorde van query-uitvoering van één tot acht zien met behulp van de seq-kolom. In gevallen waarin meerdere opgeslagen procedures worden aangeroepen, is het niet ongebruikelijk dat de waarde van de reeks-ID in de honderden of duizenden loopt.
Tot slot, in het geval dat u naar de uitvoering van de query kijkt en u heeft Causaliteit bijhouden opgenomen en u vindt een query die slecht presteert - omdat u de uitvoer sorteerde op basis van duur of een andere statistiek, moet u er rekening mee houden dat u de andere kunt vinden zoekopdrachten door te groeperen op de GUID:
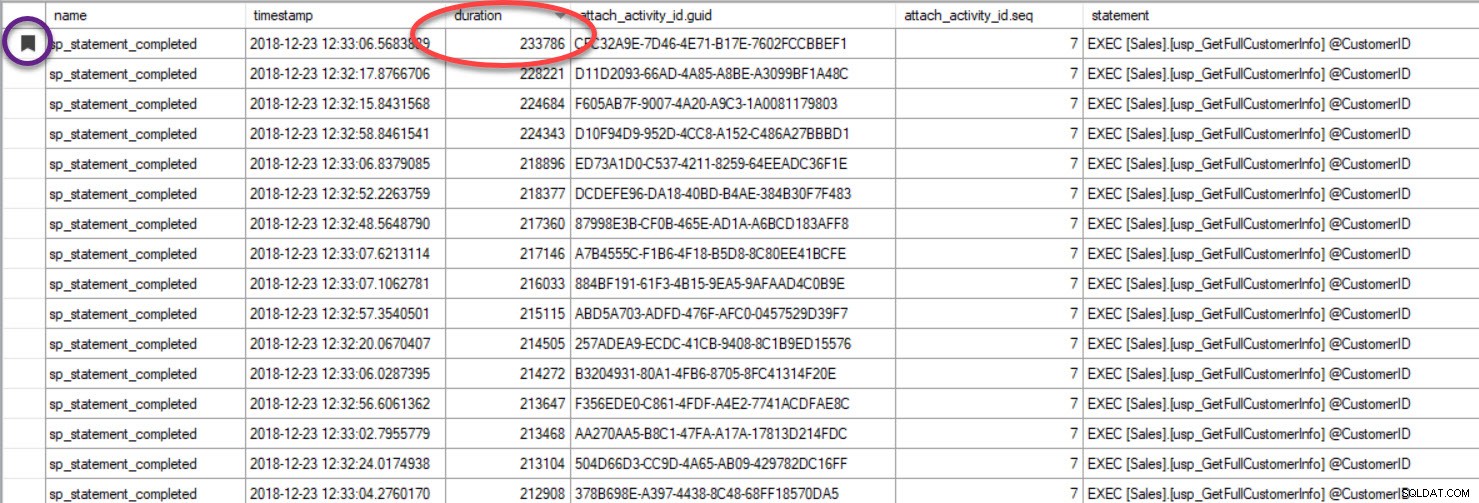
De uitvoer is gesorteerd op duur (hoogste waarde rood omcirkeld) en ik heb er een bladwijzer van gemaakt (in paars) met de knop Bladwijzer wisselen. Als we de andere zoekopdrachten voor de GUID willen zien, groepeer dan op GUID (klik met de rechtermuisknop op de kolomnaam bovenaan en selecteer Groeperen op deze kolom) en gebruik vervolgens de knop Volgende bladwijzer om terug te gaan naar onze zoekopdracht:
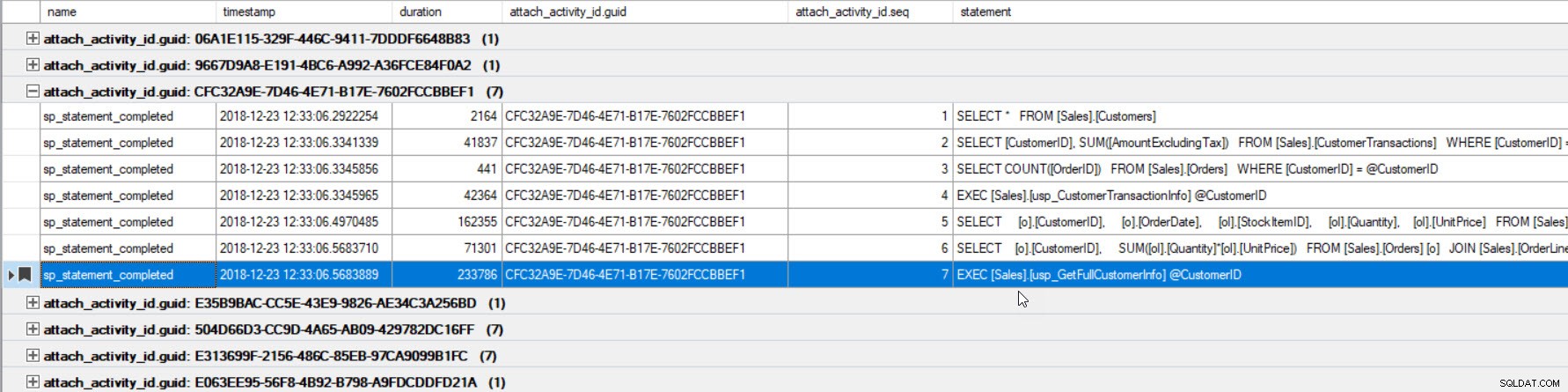
Nu kunnen we alle query's zien die zijn uitgevoerd binnen dezelfde verbinding en in de uitgevoerde volgorde.
Conclusie
De optie Causaliteit traceren kan enorm handig zijn bij het oplossen van problemen met de prestaties van query's en het proberen de volgorde van gebeurtenissen binnen SQL Server te begrijpen. Het is ook handig bij het opzetten van een evenementsessie die het pair_matching-doel gebruikt, om ervoor te zorgen dat je matcht op het juiste veld/de juiste actie en het juiste niet-overeenkomende evenement vindt. Nogmaals, dit is een instelling op sessieniveau, dus deze moet worden toegepast voordat u de gebeurtenissessie start. Voor een sessie die loopt, stop de gebeurtenissessie, schakel de optie in en start deze opnieuw.