U werkt met een ontwikkelaar die trage prestaties meldt voor de volgende opgeslagen procedure-aanroep:
EXEC [dbo].[charge_by_date] '2/28/2013';
U vraagt welk probleem de ontwikkelaar ziet, maar de enige aanvullende informatie die u hoort, is dat het "langzaam werkt". Dus je springt op de SQL Server-instantie en kijkt naar de werkelijke uitvoeringsplan. U doet dit omdat u niet alleen geïnteresseerd bent in hoe het uitvoeringsplan eruitziet, maar ook in wat het geschatte versus werkelijke aantal rijen is voor het plan:
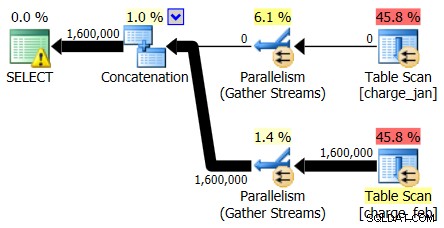
Als u eerst alleen naar de planoperators kijkt, ziet u een paar opmerkelijke details:
- Er staat een waarschuwing in de root-operator
- Er is een tabelscan voor beide tabellen waarnaar wordt verwezen op leaf-niveau (charge_jan en charge_feb) en je vraagt je af waarom dit allebei nog steeds stapels zijn en geen geclusterde indexen hebben
- Je ziet dat er alleen rijen door de tabel charge_feb stromen en niet door de tabel charge_jan
- Je ziet parallelle zones in het plan
Wat betreft de waarschuwing in de root-iterator, je zweeft eroverheen en ziet dat er indexwaarschuwingen ontbreken met een aanbeveling voor de volgende indexen:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
U vraagt de oorspronkelijke databaseontwikkelaar waarom er geen geclusterde index is en het antwoord is:"Ik weet het niet."
Als u het onderzoek voortzet voordat u wijzigingen aanbrengt, kijkt u naar het tabblad Plan Tree in SQL Sentry Plan Explorer en ziet u inderdaad dat er aanzienlijke scheeftrekkingen zijn tussen de geschatte en werkelijke rijen voor een van de tabellen:

Er lijken twee problemen te zijn:
- Een onderschatting voor rijen in de tabelscan van charge_jan
- Een overschatting voor rijen in de charge_feb tabelscan
Dus de kardinaliteitsschattingen zijn scheef, en je vraagt je af of dit te maken heeft met het snuiven van parameters. U besluit de gecompileerde waarde van de parameter te controleren en deze te vergelijken met de runtime-waarde van de parameter, die u kunt zien op het tabblad Parameters:

Er zijn inderdaad verschillen tussen de runtime-waarde en de gecompileerde waarde. U kopieert de database naar een prod-achtige testomgeving en test vervolgens de uitvoering van de opgeslagen procedure met de runtime-waarde van 28-2-2013 en daarna 01-03-2013.
De plannen van 28-2-2013 en 01-03-2013 hebben identieke vormen, maar verschillende feitelijke gegevensstromen. Het plan van 28-2-2013 en de schattingen van de kardinaliteit waren als volgt:
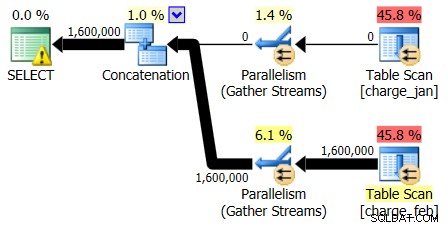

En hoewel het plan van 28-2-2013 geen kardinaliteitsschattingsprobleem vertoont, doet het plan van 01-01-2013 dat wel:
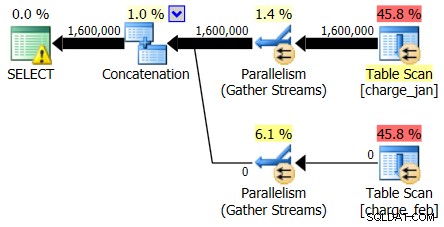

Dus het tweede plan toont dezelfde over- en onderschattingen, alleen omgekeerd van het oorspronkelijke plan waar je naar keek.
U besluit de voorgestelde indexen toe te voegen aan de prod-achtige testomgeving voor zowel de charge_jan- als charge_feb-tabellen en kijken of dat uberhaupt helpt. Als u de opgeslagen procedures uitvoert in de volgorde van januari / februari, ziet u de volgende nieuwe planvormen en bijbehorende kardinaliteitsschattingen:
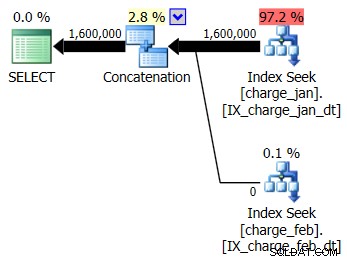

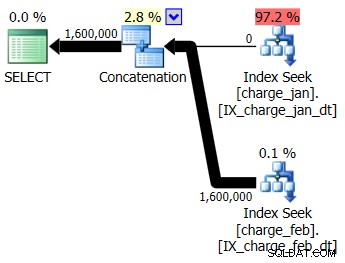

Het nieuwe plan maakt gebruik van een Index Seek-bewerking van elke tabel, maar je ziet nog steeds nul rijen die uit de ene tabel stromen en niet de andere, en je ziet nog steeds scheeftrekkingen van kardinaliteitsschattingen op basis van het snuiven van parameters wanneer de runtime-waarde zich in een andere maand bevindt dan het compileren tijdswaarde.
Uw team heeft het beleid om geen indexen toe te voegen zonder bewijs van voldoende voordeel en bijbehorende regressietests. U besluit voorlopig de niet-geclusterde indexen die u zojuist hebt gemaakt te verwijderen. Hoewel je de ontbrekende geclusterde niet meteen aanpakt index, u besluit er later voor te zorgen.
Op dit punt realiseert u zich dat u verder moet kijken naar de definitie van de opgeslagen procedure, die als volgt is:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Vervolgens kijk je naar de charge_view objectdefinitie:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
De weergavereferenties verwijzen naar kostengegevens die op datum in verschillende tabellen zijn onderverdeeld. En dan vraag je je af of de scheeftrekking van het tweede query-uitvoeringsplan kan worden voorkomen door de opgeslagen proceduredefinitie te wijzigen.
Misschien als de optimizer tijdens runtime weet wat de waarde is, zal het probleem met de kardinaliteitsschatting verdwijnen en de algehele prestaties verbeteren?
Je gaat door en herdefinieert de opgeslagen procedure-aanroep als volgt, en voegt een RECOMPILE-hint toe (in de wetenschap dat je ook hebt gehoord dat dit het CPU-gebruik kan verhogen, maar aangezien dit een testomgeving is, voel je je veilig om het eens te proberen):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Vervolgens voert u de opgeslagen procedure opnieuw uit met de waarde 1/31/2013 en vervolgens de waarde 2/28/2013.
De vorm van het plan blijft hetzelfde, maar nu is het probleem met de kardinaliteitsschatting verwijderd.
De kardinaliteitsschattingsgegevens van 1/31/2013 laten zien:

En de gegevens van de kardinaliteitsschatting van 28-2-2013 laten zien:

Dat maakt je even blij, maar dan realiseer je je dat de duur van de algehele query-uitvoering relatief hetzelfde lijkt als voorheen. Je begint te twijfelen of de ontwikkelaar blij zal zijn met je resultaten. Je hebt de scheefheid van de kardinaliteitsschatting opgelost, maar zonder de verwachte prestatieverbetering weet je niet zeker of je op een zinvolle manier hebt geholpen.
Op dit punt realiseert u zich dat het plan voor het uitvoeren van query's slechts een subset is van de informatie die u mogelijk nodig hebt, en dus breidt u uw verkenning verder uit door naar het tabblad Tabel I/O te kijken. U ziet de volgende uitvoer voor de uitvoering van 1/31/2013:

En voor de uitvoering van 28-2-2013 zie je vergelijkbare gegevens:

Op dat moment vraagt u zich af of de bewerkingen voor gegevenstoegang voor beide tabellen zijn nodig in elk plan. Als de optimizer weet dat je alleen januari-rijen nodig hebt, waarom zou je dan überhaupt februari openen en vice versa? U herinnert zich ook dat de query-optimizer geen garanties biedt dat er geen . zijn werkelijke rijen van de andere maanden in de "verkeerde" tabel, tenzij dergelijke garanties expliciet zijn gemaakt via beperkingen op de tabel zelf.
U controleert de tabeldefinities via sp_help voor elke tabel en u ziet geen beperkingen gedefinieerd voor beide tabellen.
Dus als test voeg je de volgende twee beperkingen toe:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
U voert de opgeslagen procedures opnieuw uit en ziet de volgende planvormen en kardinaliteitsschattingen.
1/31/2013 uitvoering:
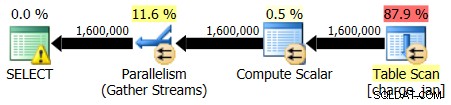

28-2-2013 uitvoering:


Als u nogmaals naar Tabel I/O kijkt, ziet u de volgende uitvoer voor de uitvoering van 1/31/2013:

En voor de uitvoering van 28-2-2013 zie je vergelijkbare gegevens, maar voor de tabel charge_feb:

Onthoud dat u de RECOMPILE nog steeds in de opgeslagen proceduredefinitie hebt, u probeert deze te verwijderen en te kijken of u hetzelfde effect ziet. Nadat u dit hebt gedaan, ziet u de terugkeer van de toegang met twee tabellen, maar zonder daadwerkelijke logische leesbewerkingen voor de tabel die geen rijen bevat (vergeleken met het oorspronkelijke plan zonder de beperkingen). De uitvoering van 1/31/2013 toonde bijvoorbeeld de volgende tabel I/O-uitvoer:

U besluit verder te gaan met het testen van de nieuwe CHECK-beperkingen en de RECOMPILE-oplossing, waarbij u de tabeltoegang volledig uit het plan (en de bijbehorende planoperators) verwijdert. Je bereidt jezelf ook voor op een debat over de geclusterde indexsleutel en een geschikte ondersteunende niet-geclusterde index die geschikt is voor een bredere reeks werklasten die momenteel toegang hebben tot de bijbehorende tabellen.