Eerder deze maand publiceerde ik een tip over iets waarvan we waarschijnlijk allemaal zouden willen dat we het niet hoefden te doen:sorteer of verwijder duplicaten van gescheiden tekenreeksen, meestal met door de gebruiker gedefinieerde functies (UDF's). Soms moet u de lijst (zonder de duplicaten) opnieuw samenstellen in alfabetische volgorde, en soms moet u de oorspronkelijke volgorde behouden (het kan bijvoorbeeld de lijst met sleutelkolommen in een slechte index zijn).
Voor mijn oplossing, die beide scenario's aanpakt, heb ik een getallentabel gebruikt, samen met een paar door de gebruiker gedefinieerde functies (UDF's) - één om de string te splitsen, de andere om hem opnieuw samen te stellen. Je kunt die tip hier zien:
- Duplicaten verwijderen uit strings in SQL Server
Natuurlijk zijn er meerdere manieren om dit probleem op te lossen; Ik gaf slechts één methode om te proberen als je vastzit aan die structuurgegevens. Red-Gate's @Phil_Factor volgde met een korte post waarin hij zijn aanpak liet zien, waarbij de functies en de getallentabel worden vermeden, en in plaats daarvan gekozen wordt voor inline XML-manipulatie. Hij zegt dat hij de voorkeur geeft aan zoekopdrachten met één instructie en het vermijden van zowel functies als rij-voor-rij verwerking:
- Gescheiden lijsten ontdubbelen in SQL Server
Toen plaatste een lezer, Steve Mangiameli, een looping-oplossing als commentaar op de tip. Zijn redenering was dat het gebruik van een getallentabel hem overdreven leek.
We zijn er alle drie niet in geslaagd om een aspect hiervan aan te pakken dat normaal gesproken heel belangrijk zal zijn als je de taak vaak genoeg of op een willekeurig schaalniveau uitvoert:prestaties .
Testen
Nieuwsgierig om te zien hoe goed de inline XML en looping-benaderingen zouden presteren in vergelijking met mijn op getallentabel gebaseerde oplossing, heb ik een fictieve tabel gemaakt om enkele tests uit te voeren; mijn doel was 5.000 rijen, met een gemiddelde tekenreekslengte van meer dan 250 tekens en ten minste 10 elementen in elke tekenreeks. Met een zeer korte cyclus van experimenten was ik in staat om iets te bereiken dat hier heel dicht in de buurt komt met de volgende code:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Dit leverde een tabel op met voorbeeldrijen die er als volgt uitzien (waarden afgekapt):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
De gegevens als geheel hadden het volgende profiel, dat goed genoeg zou moeten zijn om mogelijke prestatieproblemen aan het licht te brengen:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/
Merk op dat ik ben overgeschakeld naar varchar hier van nvarchar in het originele artikel, omdat de monsters die Phil en Steve hebben geleverd, ervan uitgingen dat varchar , tekenreeksen met een maximum van slechts 255 of 8000 tekens, scheidingstekens van één teken, enz. Ik heb mijn les op de harde manier geleerd, dat als je iemands functie gaat nemen en deze opneemt in prestatievergelijkingen, je zo weinig verandert als mogelijk – idealiter niets. In werkelijkheid zou ik altijd nvarchar . gebruiken en neem niets aan over de langst mogelijke reeks. In dit geval wist ik dat ik geen gegevens verloor omdat de langste string slechts 2.905 tekens is, en in deze database heb ik geen tabellen of kolommen die Unicode-tekens gebruiken.
Vervolgens heb ik mijn functies gemaakt (waarvoor een getallentabel nodig is). Een lezer zag een probleem in de functie in mijn tip, waarbij ik aannam dat het scheidingsteken altijd een enkel teken zou zijn, en corrigeerde dat hier. Ik heb ook zo ongeveer alles geconverteerd naar varchar(8000) om het speelveld te egaliseren in termen van snaartypes en lengtes.
DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Vervolgens heb ik een enkele, inline tabelwaardefunctie gemaakt die de twee bovenstaande functies combineerde, iets wat ik nu in het oorspronkelijke artikel had willen doen, om de scalaire functie helemaal te vermijden. (Hoewel waar dat niet alle scalaire functies zijn verschrikkelijk op schaal, er zijn maar weinig uitzonderingen.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO
Ik heb ook afzonderlijke versies van de inline TVF gemaakt die waren gewijd aan elk van de twee sorteerkeuzes, om de vluchtigheid van de CASE te voorkomen uitdrukking, maar het bleek helemaal geen dramatische impact te hebben.
Daarna heb ik Steve's twee functies gemaakt:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO
Daarna plaatste ik Phil's directe vragen in mijn testopstelling (merk op dat zijn vragen coderen voor < als < om ze te beschermen tegen XML-parseerfouten, maar ze coderen niet > of & – Ik heb tijdelijke aanduidingen toegevoegd voor het geval je moet waken voor strings die mogelijk die problematische tekens kunnen bevatten):
-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist);
De testopstelling bestond in feite uit die twee vragen, en ook de volgende functieaanroepen. Nadat ik had gevalideerd dat ze allemaal dezelfde gegevens hadden geretourneerd, doorspekte ik het script met DATEDIFF output en logde het in een tabel:
-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above En toen heb ik prestatietests uitgevoerd op twee verschillende systemen (een quad-core met 8 GB en een 8-core VM met 32 GB), en in elk geval op zowel SQL Server 2012 als SQL Server 2016 CTP 3.2 (13.0.900.73).
Resultaten
De resultaten die ik heb waargenomen, zijn samengevat in de volgende grafiek, die de duur in milliseconden van elk type zoekopdracht toont, gemiddeld over alfabetische en originele volgorde, de vier server-/versiecombinaties en een reeks van 15 uitvoeringen voor elke permutatie. Klik om te vergroten:
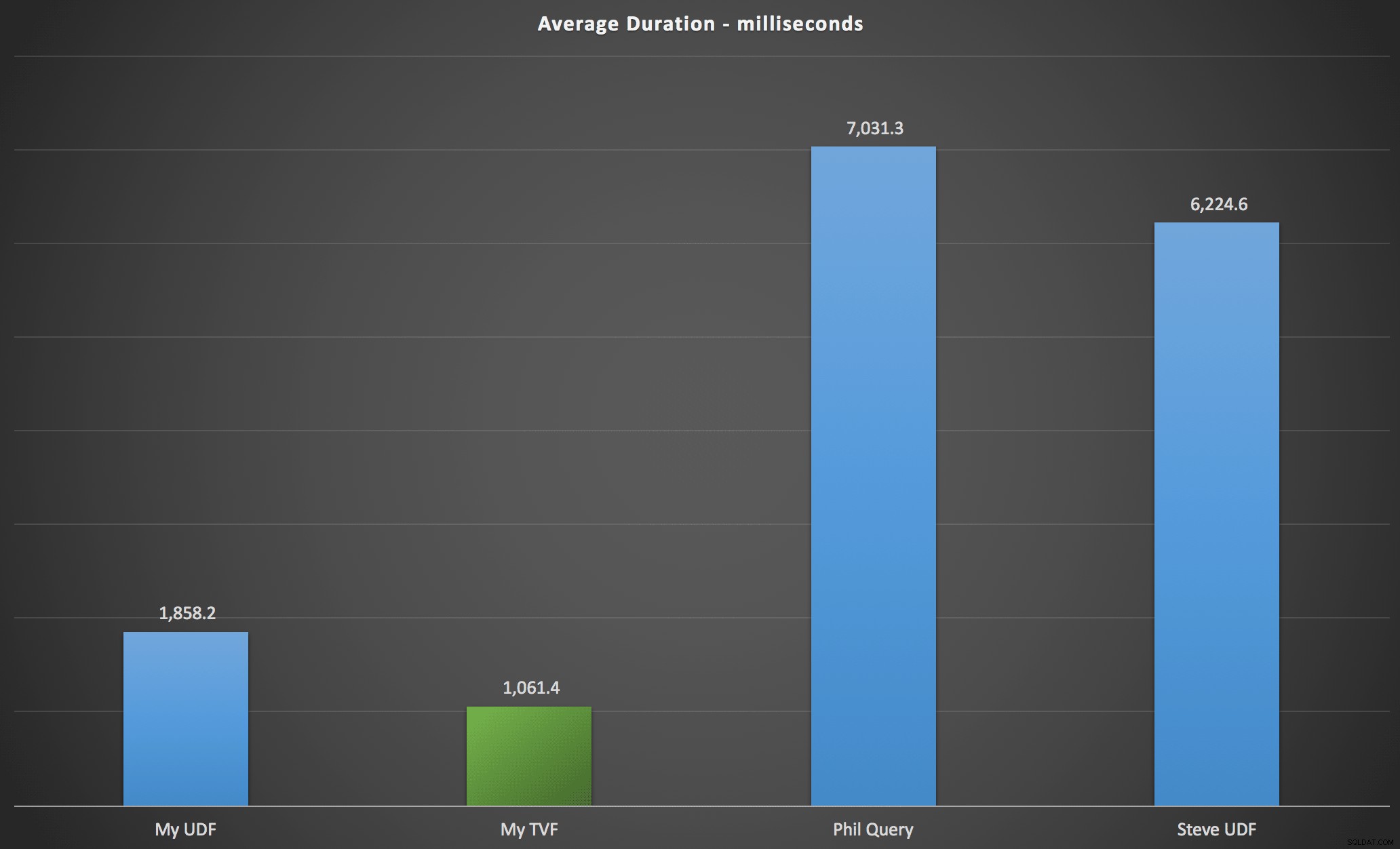
Dit toont aan dat de getallentabel, hoewel als over-engineered beschouwd, in feite de meest efficiënte oplossing opleverde (tenminste in termen van duur). Dit was natuurlijk beter met de enkele TVF die ik recentelijk heb geïmplementeerd dan met de geneste functies uit het oorspronkelijke artikel, maar beide oplossingen draaien rond de twee alternatieven.
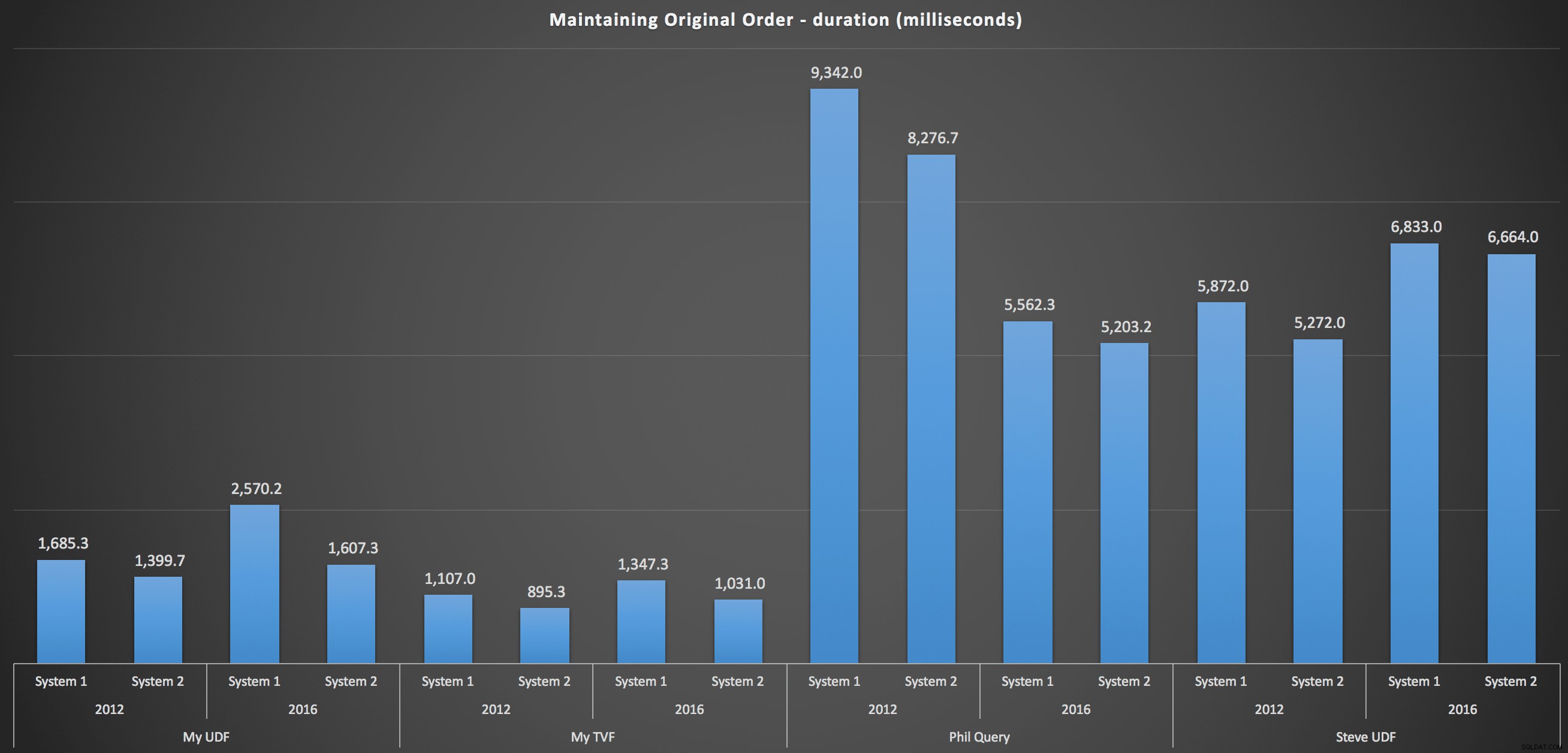
Om meer in detail te treden, zijn hier de uitsplitsingen voor elke machine, versie en querytype, om de oorspronkelijke volgorde te behouden:
...en voor het opnieuw samenstellen van de lijst in alfabetische volgorde:
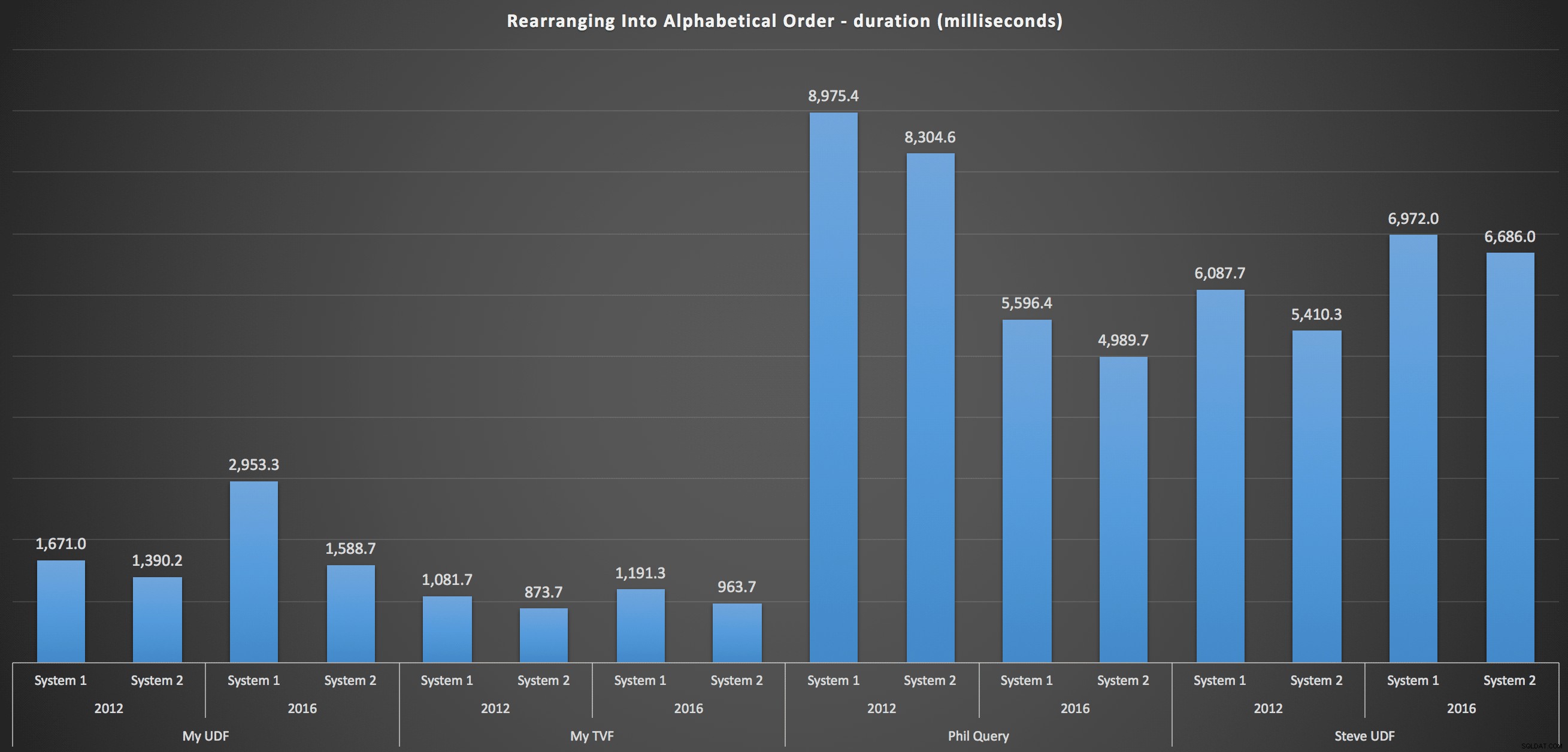
Hieruit blijkt dat de sorteerkeuze weinig invloed had op de uitkomst - beide grafieken zijn vrijwel identiek. En dat is logisch omdat, gezien de vorm van de invoergegevens, er geen index is die ik me kan voorstellen die het sorteren efficiënter zou maken - het is een iteratieve benadering, ongeacht hoe je het opdeelt of hoe je de gegevens retourneert. Maar het is duidelijk dat sommige iteratieve benaderingen over het algemeen slechter kunnen zijn dan andere, en het is niet noodzakelijk het gebruik van een UDF (of een tabel met getallen) die ze zo maakt.
Conclusie
Totdat we native split- en concatenatiefunctionaliteit in SQL Server hebben, gaan we allerlei niet-intuïtieve methoden gebruiken om de klus te klaren, inclusief door de gebruiker gedefinieerde functies. Als je met één string tegelijk werkt, zul je niet veel verschil zien. Maar naarmate uw gegevens toenemen, is het de moeite waard om verschillende benaderingen te testen (en ik suggereer geenszins dat de bovenstaande methoden de beste zijn die u zult vinden - ik heb bijvoorbeeld niet eens naar CLR gekeken, of andere T-SQL-benaderingen uit deze serie).