Op de dag van vandaag plaatste ik bijna een jaar geleden mijn oplossing voor paginering in SQL Server, waarbij ik een CTE gebruikte om alleen de belangrijkste waarden voor de reeks rijen in kwestie te vinden, en vervolgens terugkwam van de CTE naar de brontabel om op te halen de andere kolommen voor alleen die "pagina" met rijen. Dit bleek het meest voordelig wanneer er een smalle index was die de door de gebruiker gevraagde volgorde ondersteunde, of wanneer de volgorde was gebaseerd op de clustersleutel, maar zelfs een beetje beter presteerde zonder een index om de vereiste sortering te ondersteunen.
Sindsdien heb ik me afgevraagd of ColumnStore-indexen (zowel geclusterd als niet-geclusterd) een van deze scenario's zouden kunnen helpen. TL;DR :Op basis van dit geïsoleerde experiment is het antwoord op de titel van dit bericht een volmondig NEE . Als je de testopstelling, code, uitvoeringsplannen of grafieken niet wilt zien, ga dan gerust naar mijn samenvatting, waarbij je er rekening mee moet houden dat mijn analyse is gebaseerd op een zeer specifieke use-case.
Instellen
Op een nieuwe VM met SQL Server 2016 CTP 3.2 (13.0.900.73) geïnstalleerd, doorliep ik ongeveer dezelfde setup als voorheen, alleen deze keer met drie tabellen. Ten eerste een traditionele tabel met een smalle clustersleutel en meerdere ondersteunende indexen:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Vervolgens een tabel met een geclusterde ColumnStore-index:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
En tot slot een tabel met een niet-geclusterde ColumnStore-index die alle kolommen dekt:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Merk op dat ik voor beide tabellen met ColumnStore-indexen de index heb weggelaten die snellere zoekopdrachten op de "Telefoonboek" sortering (achternaam, voornaam) zou ondersteunen.
Testgegevens
Vervolgens heb ik de eerste tabel gevuld met 1.000.000 willekeurige rijen, gebaseerd op een script dat ik opnieuw heb gebruikt uit eerdere berichten:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Daarna gebruikte ik die tabel om de andere twee te vullen met exact dezelfde gegevens, en herbouwde ik alle indexen:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
De totale grootte van elke tafel:
| Tabel | Gereserveerd | Gegevens | Index |
|---|---|---|---|
| Klanten | 463.200 KB | 154.344 KB | 308.576 KB |
| Customers_CCI | 117.280 KB | 30,288 KB | 86.536 KB |
| Customers_NCCI | 349.480 KB | 154.344 KB | 194.976 KB |
En het aantal rijen / pagina's van de relevante indexen (de unieke index op e-mail was er meer voor mij om op mijn eigen script voor het genereren van gegevens te passen dan iets anders):
| Tabel | Index | Rijen | Pagina's |
|---|---|---|---|
| Klanten | PK_Klanten | 1.000.000 | 19.377 |
| Klanten | PhoneBook_Customers | 1.000.000 | 17.209 |
| Klanten | Active_Customers | 808.012 | 13.977 |
| Customers_CCI | PK_CustomersCCI | 1.000.000 | 2.737 |
| Customers_CCI | Customers_CCI | 1.000.000 | 3.826 |
| Customers_NCCI | PK_CustomersNCCI | 1.000.000 | 19.377 |
| Customers_NCCI | Customers_NCCI | 1.000.000 | 16.971 |
Procedures
Vervolgens, om te zien of de ColumnStore-indexen zouden binnendringen en een van de scenario's beter zouden maken, voerde ik dezelfde reeks query's uit als voorheen, maar nu tegen alle drie de tabellen. Ik werd op zijn minst een beetje slimmer en maakte twee opgeslagen procedures met dynamische SQL om de tabelbron en sorteervolgorde te accepteren. (Ik ben goed op de hoogte van SQL-injectie; dit is niet wat ik in productie zou doen als deze strings van een eindgebruiker zouden komen, dus vat het alsjeblieft niet op als een aanbeveling om dit te doen. Ik vertrouw mezelf net genoeg in mijn afgesloten omgeving dat het geen probleem is voor deze tests.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Daarna heb ik wat meer dynamische SQL gemaakt om alle combinaties van aanroepen te genereren die ik zou moeten doen om zowel de oude als de nieuwe opgeslagen procedures aan te roepen, in alle drie de gewenste sorteervolgorden en op verschillende paginanummers (om te simuleren dat een pagina aan het begin, midden en einde van de sorteervolgorde). Zodat ik PRINT . kan kopiëren uitvoer en plak het in SQL Sentry Plan Explorer om runtime-statistieken te krijgen, ik heb deze batch twee keer uitgevoerd, een keer met de procedures CTE met P_Old , en dan opnieuw met P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Dit leverde een dergelijke uitvoer op (36 aanroepen in totaal voor de oude methode (P_Old ), en 36 oproepen voor de nieuwe methode (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Ik weet het, dit is allemaal erg omslachtig; we komen snel bij de clou, dat beloof ik.
Resultaten
Ik nam die twee sets van 36 statements en startte twee nieuwe sessies in Plan Explorer, waarbij ik elke set meerdere keren uitvoerde om ervoor te zorgen dat we gegevens uit een warme cache kregen en gemiddelden namen (ik kon ook koude en warme cache vergelijken, maar ik denk dat er zijn genoeg variabelen hier).
Ik kan je meteen een paar simpele feiten vertellen zonder je zelfs maar ondersteunende grafieken of plannen te tonen:
- In geen enkel scenario versloeg de "oude" methode de nieuwe CTE-methode Ik promootte in mijn vorige bericht, ongeacht het type indexen dat aanwezig was. Dus dat maakt het gemakkelijk om vrijwel de helft van de resultaten te negeren, althans in termen van duur (dat is de enige statistiek waar eindgebruikers het meest om geven).
- Geen enkele ColumnStore-index deed het goed bij het bladeren naar het einde van het resultaat – ze leverden alleen in het begin voordelen op, en slechts in een paar gevallen.
- Bij sorteren op de primaire sleutel (geclusterd of niet), de aanwezigheid van ColumnStore-indexen hielp niet – nogmaals, qua duur.
Laten we, nu die samenvattingen uit de weg zijn, eens kijken naar een paar dwarsdoorsneden van de duurgegevens. Eerst de resultaten van de zoekopdracht gesorteerd op voornaam aflopend, dan e-mail, zonder hoop een bestaande index te gebruiken om te sorteren. Zoals je in de grafiek kunt zien, waren de prestaties inconsistent - bij lagere paginanummers deed de niet-geclusterde ColumnStore het het beste; bij hogere paginanummers won de traditionele index altijd:
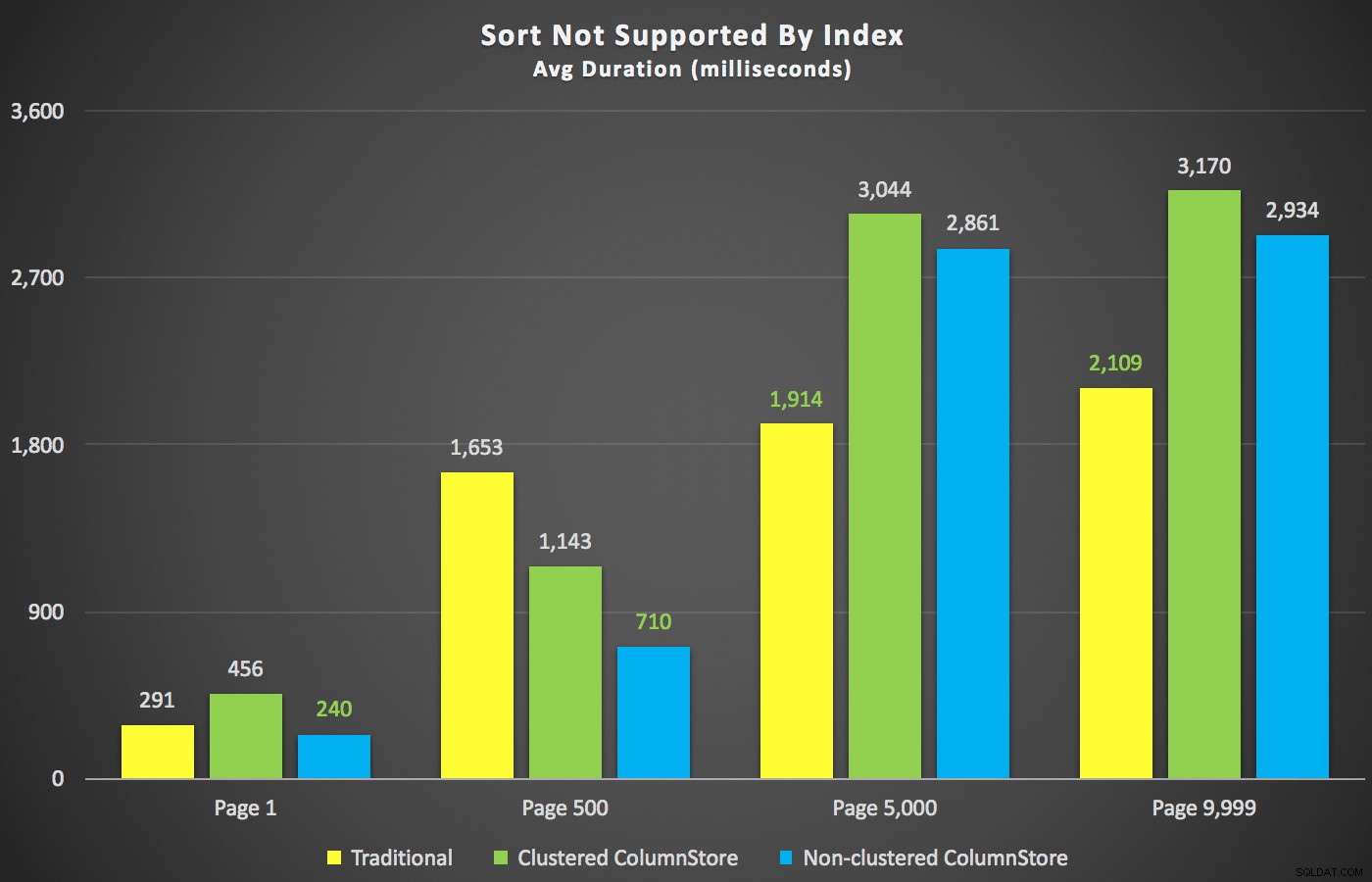 Duur (milliseconden) voor verschillende paginanummers en verschillende indextypen
Duur (milliseconden) voor verschillende paginanummers en verschillende indextypen
En dan de drie plannen die de drie verschillende soorten indexen vertegenwoordigen (met grijswaarden toegevoegd door Photoshop om de belangrijkste verschillen tussen de plannen te benadrukken):
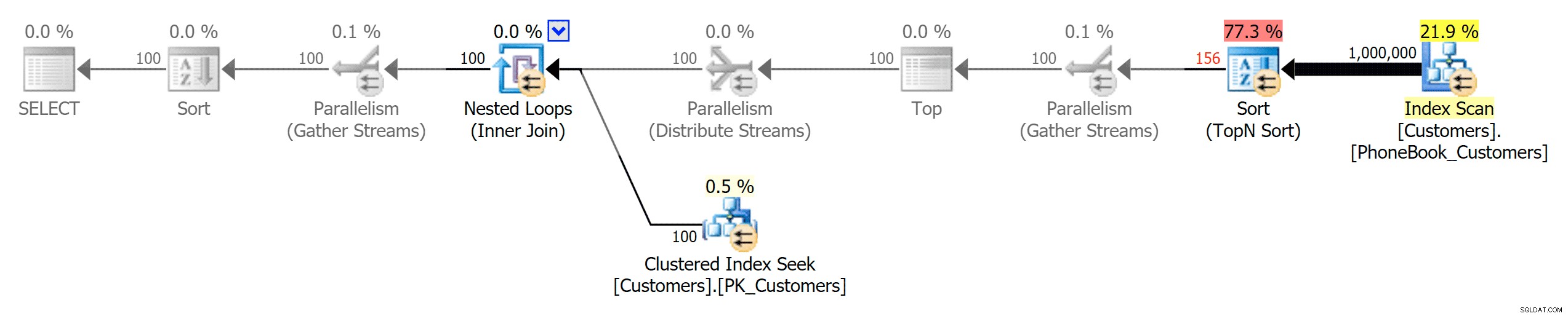 Plan voor traditionele index
Plan voor traditionele index
 Plan voor geclusterde ColumnStore-index
Plan voor geclusterde ColumnStore-index
 Plan voor niet-geclusterde ColumnStore-index
Plan voor niet-geclusterde ColumnStore-index
Een scenario waarin ik meer geïnteresseerd was, zelfs voordat ik begon met testen, was de sorteerbenadering van het telefoonboek (achternaam, voornaam). In dit geval waren de ColumnStore-indexen eigenlijk behoorlijk nadelig voor de prestaties van het resultaat:
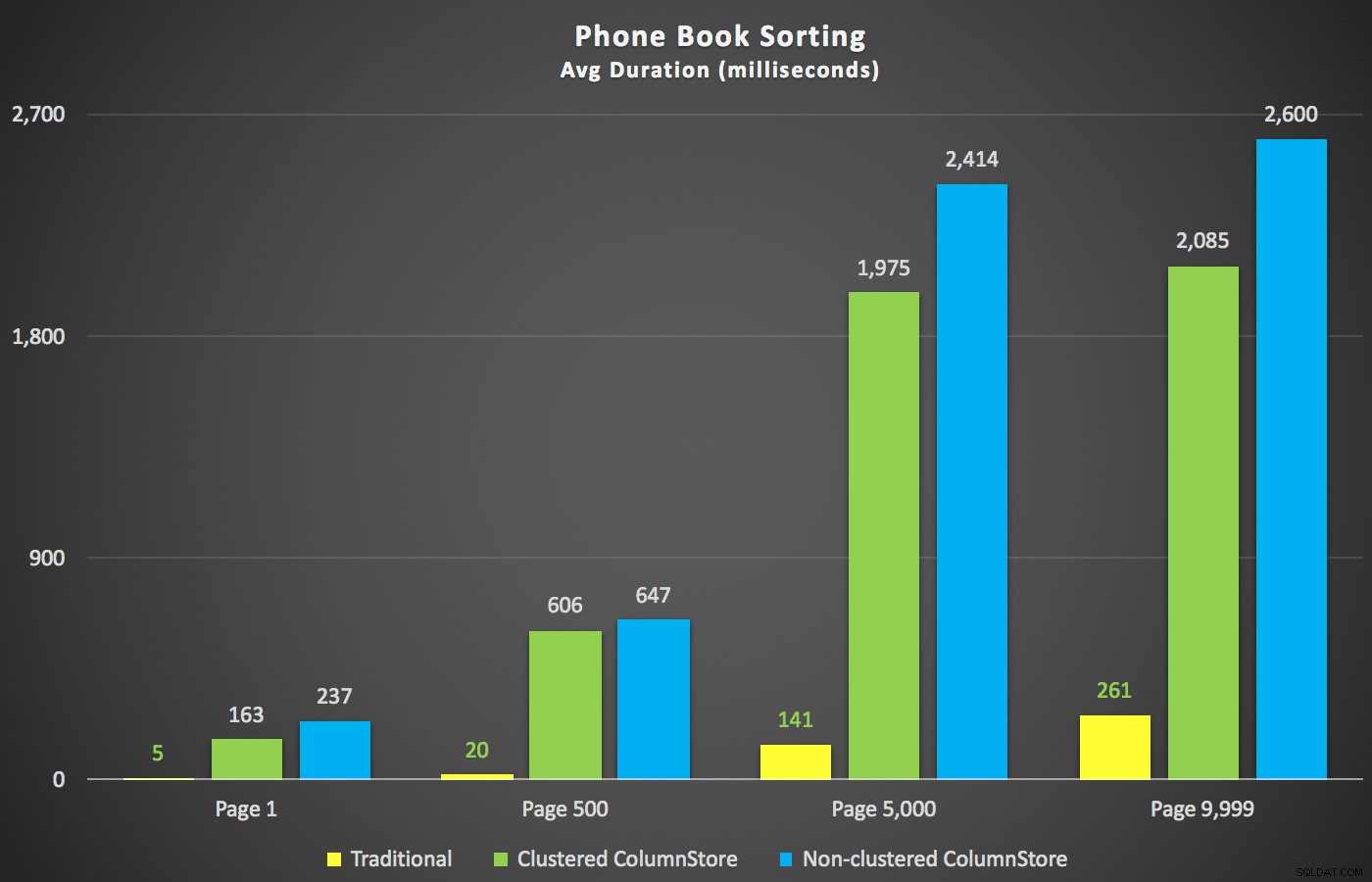
De ColumnStore-abonnementen hier zijn bijna spiegelbeelden van de twee ColumnStore-abonnementen die hierboven zijn weergegeven voor de niet-ondersteunde sortering. De reden is in beide gevallen hetzelfde:dure scans of sorteringen door het ontbreken van een sorteerondersteunende index.
Dus vervolgens maakte ik ondersteunende "PhoneBook"-indexen op de tafels met de ColumnStore-indexen, om te zien of ik in een van die scenario's een ander plan en/of snellere uitvoeringstijden kon overhalen. Ik heb deze twee indexen gemaakt en vervolgens opnieuw opgebouwd:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Dit waren de nieuwe looptijden:
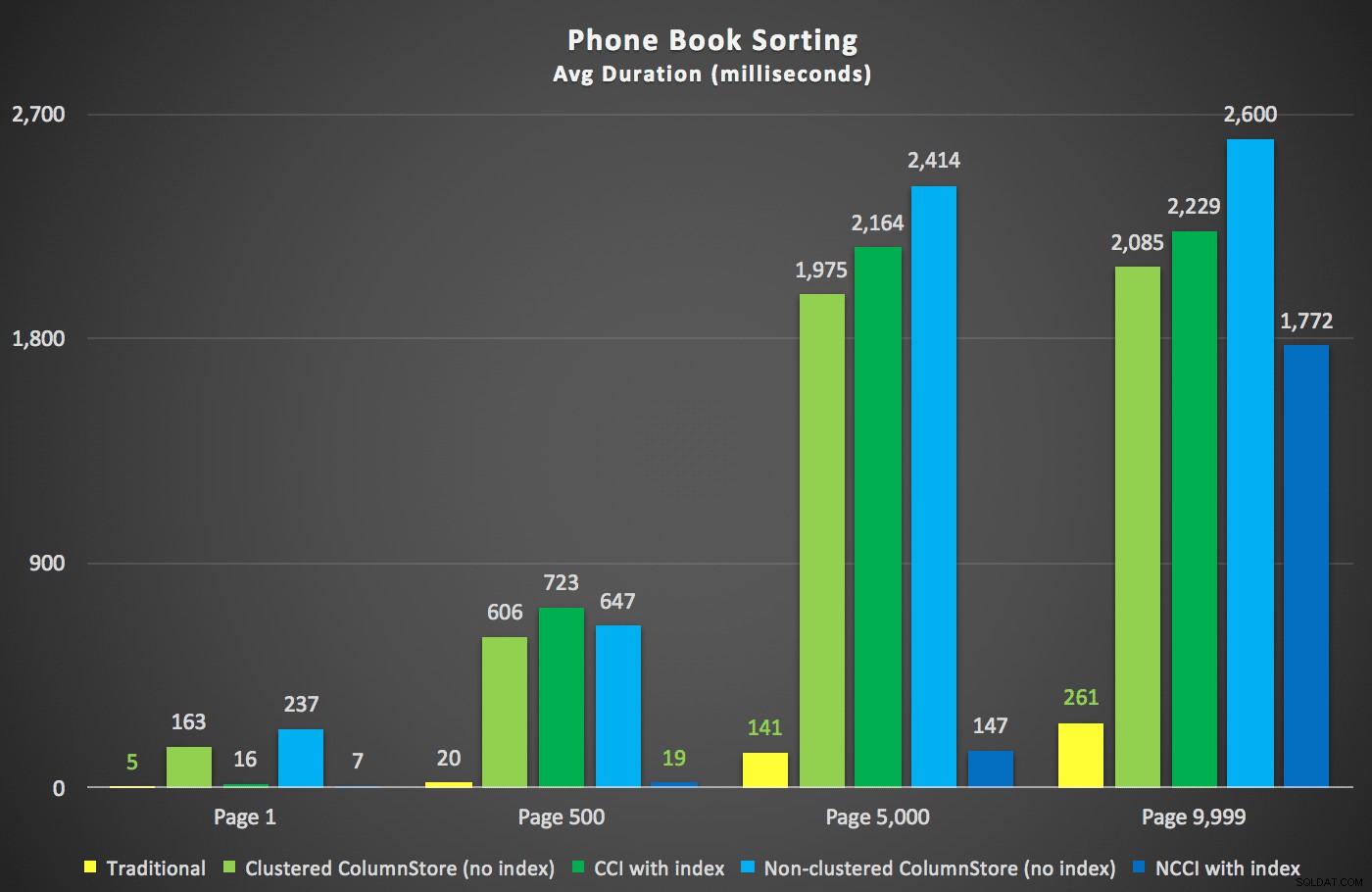
Het meest interessante hier is dat nu de pagingquery tegen de tabel met de niet-geclusterde ColumnStore-index gelijke tred lijkt te houden met de traditionele index, totdat we voorbij het midden van de tabel komen. Als we naar de plannen kijken, zien we dat op pagina 5.000 een traditionele indexscan wordt gebruikt en dat de ColumnStore-index volledig wordt genegeerd:
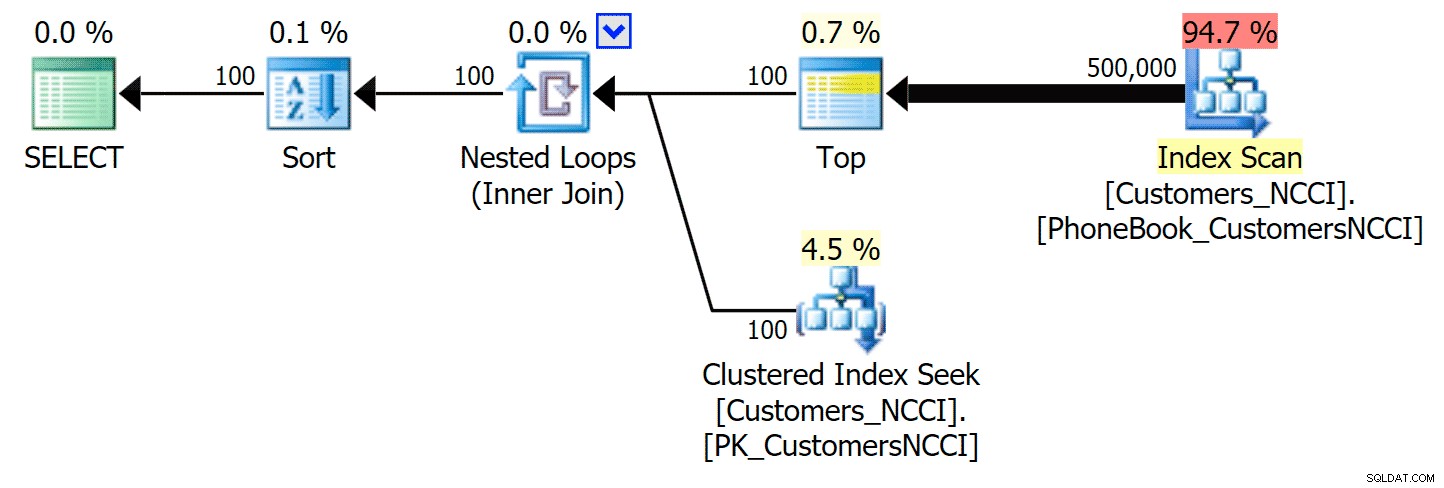 Telefoonboekabonnement negeert de niet-geclusterde ColumnStore-index
Telefoonboekabonnement negeert de niet-geclusterde ColumnStore-index
Maar ergens tussen het middelpunt van 5.000 pagina's en het "einde" van de tabel op 9.999 pagina's, heeft de optimizer een soort kantelpunt bereikt en kiest - voor exact dezelfde zoekopdracht - er nu voor om de niet-geclusterde ColumnStore-index te scannen :
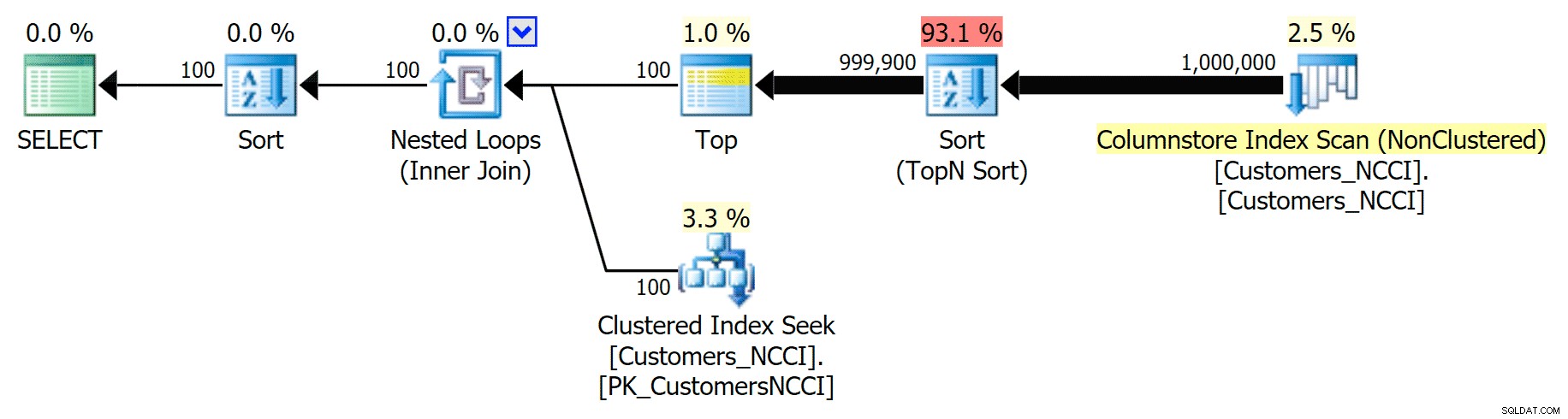 Telefoonboekplan 'tips' en gebruikt de ColumnStore-index
Telefoonboekplan 'tips' en gebruikt de ColumnStore-index
Dit blijkt een niet zo geweldige beslissing van de optimizer, voornamelijk vanwege de kosten van de sorteeroperatie. U kunt zien hoeveel beter de duur wordt als u een hint geeft op de reguliere index:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Dit levert het volgende plan op, bijna identiek aan het eerste plan hierboven (iets hogere kosten voor de scan, simpelweg omdat er meer output is):
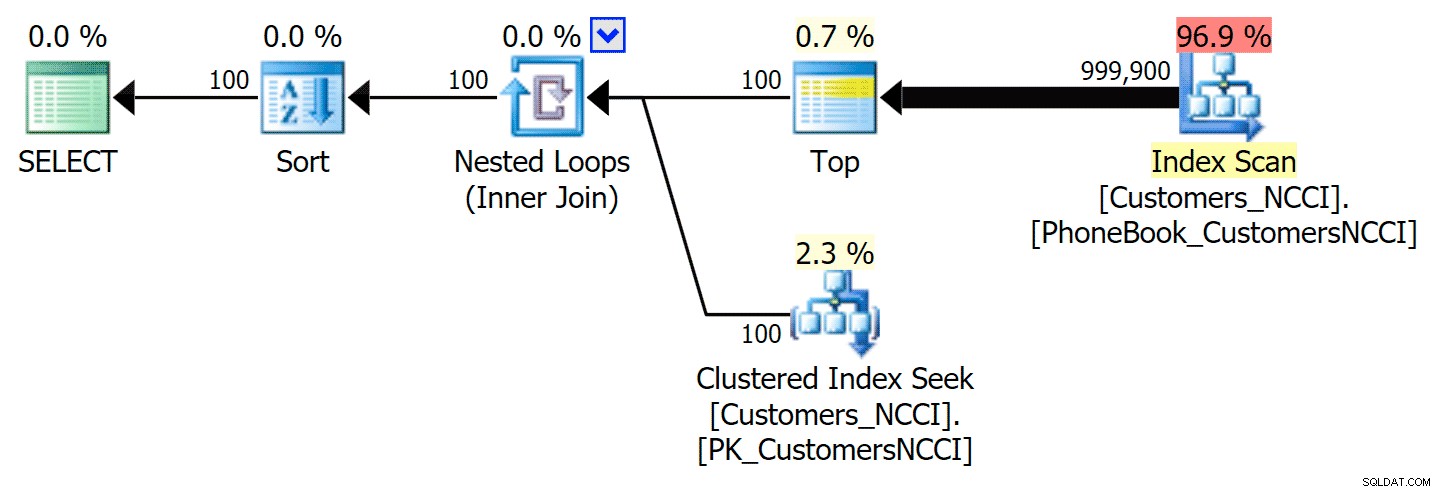 Telefoonboekabonnement met hintindex
Telefoonboekabonnement met hintindex
U kunt hetzelfde bereiken met OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) in plaats van de expliciete indexhint. Houd er rekening mee dat dit hetzelfde is als het niet hebben van de ColumnStore-index daar in de eerste plaats.
Conclusie
Hoewel er hierboven een aantal randgevallen zijn waar een ColumnStore-index (nauwelijks) vruchten afwerpt, lijkt het mij niet dat ze geschikt zijn voor dit specifieke pagineringsscenario. Ik denk dat vooral, hoewel ColumnStore door compressie aanzienlijke ruimtebesparingen laat zien, de runtime-prestaties niet fantastisch zijn vanwege de sorteervereisten (hoewel geschat wordt dat deze soorten in batchmodus worden uitgevoerd, een nieuwe optimalisatie voor SQL Server 2016).
Over het algemeen zou dit veel meer tijd kunnen besteden aan onderzoek en testen; bij het meeliften op eerdere artikelen, wilde ik zo min mogelijk veranderen. Ik zou bijvoorbeeld graag dat omslagpunt vinden, en ik zou ook willen erkennen dat dit niet echt grootschalige tests zijn (vanwege de VM-grootte en geheugenbeperkingen), en dat ik je liet raden over veel van de runtime-statistieken (meestal kortheidshalve, maar ik weet niet of een grafiek met uitlezingen die niet altijd evenredig zijn aan de duur u dat echt zou vertellen). Deze tests gaan ook uit van de luxe van SSD's, voldoende geheugen, een altijd warme cache en een omgeving voor één gebruiker. Ik zou heel graag een grotere reeks tests willen uitvoeren tegen meer gegevens, op grotere servers met langzamere schijven en instanties met minder geheugen, en al die tijd met gesimuleerde gelijktijdigheid.
Dat gezegd hebbende, zou dit ook gewoon een scenario kunnen zijn dat ColumnStore in de eerste plaats niet is ontworpen om te helpen oplossen, omdat de onderliggende oplossing met traditionele indexen al behoorlijk efficiënt is in het uittrekken van een smalle reeks rijen - niet bepaald het stuurhuis van ColumnStore. Misschien is een andere variabele om aan de matrix toe te voegen de paginagrootte - alle bovenstaande tests trekken 100 rijen tegelijk, maar wat als we achter 10.000 of 100.000 rijen per keer zitten, ongeacht hoe groot de onderliggende tabel is?
Heeft u een situatie waarin uw OLTP-werklast werd verbeterd door simpelweg ColumnStore-indexen toe te voegen? Ik weet dat ze zijn ontworpen voor workloads in datawarehouse-stijl, maar als u elders voordelen heeft gezien, hoor ik graag uw scenario en kijk of ik onderscheidende factoren in mijn testopstelling kan opnemen.